При просмотре последних опубликованных статей вы можете заметить в названиях слово «MoE». Что же означает это «MoE» и почему его так часто используют сейчас? В этом наглядном руководстве мы подробно рассмотрим этот важный компонент с более чем 50 иллюстрациями: Смесь Экспертов (MoE)!

Введение
В этом руководстве обсуждается применение двух основных компонентов MoE — экспертов и маршрутизаторов — в типичной архитектуре на основе LLM.
Что такое модель «Смешанные Эксперты»?
Метод «Смешанные Эксперты» (MoE) позволяет улучшить качество обучения моделей на основе LLM за счет использования нескольких различных подмоделей (или «экспертов»).
Основные компоненты MoE:
-
Эксперты:
-
Каждый слой FFNN теперь имеет набор «экспертов», которых можно выбрать.
-
Эти «эксперты» зачастую сами являются нейронными сетями прямого распространения (FFNN).
-
-
Маршрутизатор или сеть шлюзов:
-
Решает, какие токены отправлять тем или иным экспертам.
-
На каждом уровне LLM с MoE мы можем найти некоторых (относительно специализированных) экспертов:

Обратите внимание, что эти «эксперты» не являются узкоспециализированными специалистами в конкретной области, как эксперты по «психологии» или «биологии» в области гуманитарных наук. На самом деле они усваивают больше синтаксической информации на лексическом уровне и отлично справляются с обработкой определенных токенов в определенных контекстах:

Маршрутизатор (или сеть шлюзов) отвечает за выбор наиболее подходящего эксперта для каждого входа:

Каждый эксперт не является полноценным LLM, а лишь частью подмодели в архитектуре LLM.
Роль экспертов
Чтобы понять, что имеют в виду эксперты и как они работают, сначала нужно понять, что заменяет MoE: плотные слои.
(1) Плотные слои
Модель «Смесь Экспертов» (MoE) изначально возникла из относительно базовой функции в больших языковых моделях (LLM), а именно нейронной сети прямого распространения (FFNN).
В стандартной архитектуре Transformer, работающей только с декодированием, FFNN обычно применяются после нормализации слоев:

FFNN позволяет модели использовать контекстную информацию, генерируемую механизмом внимания, и дополнительно преобразовывать эту информацию для фиксации более сложных взаимосвязей в данных.
Однако размер FFNN быстро растет. Чтобы изучить эти сложные взаимосвязи, ему обычно необходимо расширить получаемые входные данные:

(2) Редкие слои
В традиционном Transformer FFNN (Feedforward Neural Network) называется плотной моделью, поскольку все её параметры (включая веса и смещения) активированы. Все параметры используются для вычисления выходных данных, и ни одна часть не отбрасывается.
Если внимательно рассмотреть плотную модель, то можно увидеть, что входные данные в той или иной степени активируют все параметры:

Напротив, разреженные модели активируют только подмножество общих параметров, что тесно связано с моделью смеси экспертов (MoE).
Чтобы проиллюстрировать это, мы можем разложить плотную модель на несколько частей (называемых экспертами) и переобучить её.
Затем одновременно активируются только некоторые эксперты:

Основная идея заключается в том, что каждый эксперт в ходе обучения усваивает различную информацию. При рассуждениях используются только конкретные эксперты, наиболее соответствующие поставленной задаче.
Столкнувшись с проблемой, мы можем выбрать эксперта, наиболее подходящего для решения задачи:

(3) Что узнали эксперты?
Как мы уже видели, информация, полученная экспертом, более детализирована, чем информация обо всей предметной области. Поэтому иногда называть их «экспертами» может быть некорректно.

Однако эксперты в модели декодера, похоже, не демонстрируют такой же тип специализации. Это не означает, что все эксперты равны.
Хорошим примером этого является статья Mixtral 8x7B, где каждый токен раскрашивается первым выбранным им экспертом.

Эта визуализация также показывает, что эксперты склонны больше концентрироваться на синтаксисе, а не на содержании, специфичном для конкретной области.
Таким образом, хотя эксперты по декодеру, по-видимому, не имеют определенной специализации, они ведут себя более последовательно с определенными типами токенов.
(4) Экспертная архитектура
Хотя полезно визуализировать экспертов как плотные модели со скрытыми слоями, разделенными на части, в действительности они сами часто представляют собой полноценные FFNN.

Поскольку большинство LLM имеют несколько блоков декодера, заданный текст проходит через нескольких экспертов, прежде чем будет сгенерирован:

Эксперты, выбранные для разных токенов, могут быть разными, что приводит к выбору разных «путей»:

Если мы обновим визуализацию блока декодера, то теперь он будет содержать несколько FFNN (по одной для каждого «эксперта»):
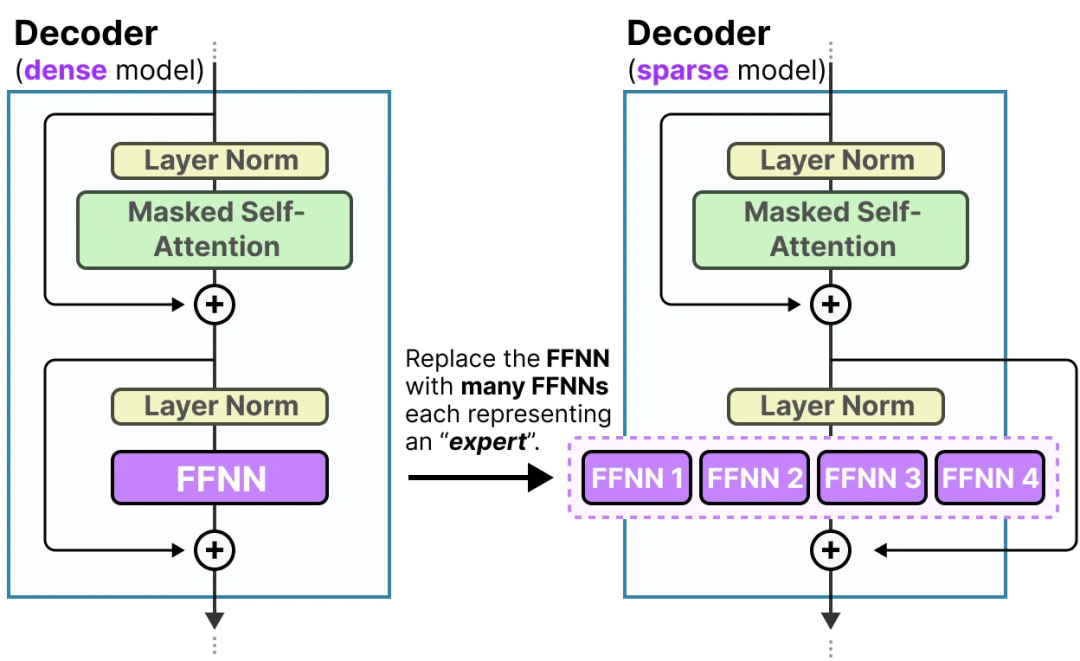
Блок декодера теперь содержит несколько FFNN (т. е. «экспертов»), которые можно использовать во время вывода.
Механизм маршрутизации
Теперь, когда у нас есть набор экспертов, как модель узнает, каких экспертов использовать?
Перед экспертами добавляется маршрутизатор (также называемый сетью шлюзов), который обучен выбирать эксперта, который должен быть выбран для каждого токена.
(1) Маршрутизатор
Маршрутизатор (или сеть шлюзов) сам по себе также является FFNN, которая выбирает эксперта на основе определенных входных данных.
Маршрутизатор выводит значения вероятностей и использует эти вероятности для выбора наиболее подходящего эксперта:

Экспертный слой возвращает выходные данные выбранного эксперта и умножает их на значение гейта (вероятность выбора).
Маршрутизаторы и эксперты (лишь немногие из них) вместе образуют уровень MoE:

Существует два типа слоев MoE: разреженная смесь экспертов и плотная смесь экспертов.
Оба варианта используют маршрутизаторы для выбора экспертов, но разреженный MoE выбирает только нескольких экспертов, тогда как плотный MoE выбирает всех экспертов, но может выбирать их в разных распределениях.

Например, столкнувшись с набором токенов, MoE распределит эти токены среди всех экспертов, в то время как разреженный MoE выберет только нескольких экспертов.
В современных LLM, когда вы видите «MoE», это обычно относится к разреженным моделям MoE, поскольку разреженные модели позволяют использовать частичных экспертов, тем самым сокращая вычислительные затраты, что является важной особенностью для LLM.
(2) Отбор экспертов
Сеть управления, пожалуй, является наиболее важным компонентом MoE, поскольку она определяет не только, каких экспертов выбирать на этапе вывода, но и выбор на этапе обучения.
В самой простой форме мы умножаем входные данные (x) на матрицу весов маршрутизатора (W):

Затем мы применяем операцию SoftMax к выходным данным, чтобы создать распределение вероятностей G(x) для каждого эксперта:
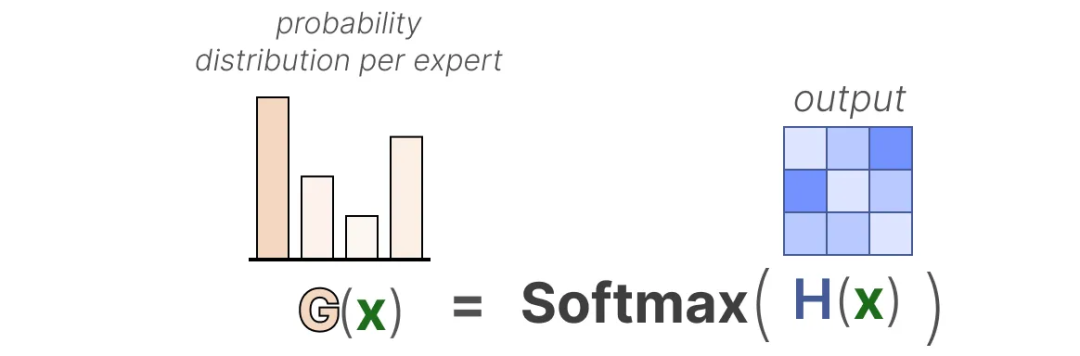
Маршрутизатор использует это распределение вероятностей для выбора наиболее подходящего эксперта для заданных входных данных.
Наконец, мы умножаем вывод каждого маршрутизатора на вывод соответствующего выбранного эксперта и складываем результаты:

Давайте соберем все вместе и рассмотрим, как входные данные проходят через маршрутизатор и экспертов:

(3) Сложность маршрутизации
Однако эта простая функция часто приводит к тому, что маршрутизатор всегда выбирает одного и того же эксперта, поскольку некоторые эксперты могут обучаться быстрее других:

Это привело бы не только к неравномерному распределению отбора экспертов, но и к тому, что некоторые эксперты оказались бы практически неподготовленными. Это вызывает проблемы во время обучения и вывода.
Поэтому мы хотим использовать каждого эксперта с одинаковой важностью во время обучения и вывода, что называется балансировкой нагрузки. Частично это делается для того, чтобы предотвратить переобучение модели на одном и том же наборе экспертов.
Балансировка нагрузки и оптимизация
Чтобы сбалансировать важность экспертов, нам необходимо сосредоточиться на маршрутизаторе, поскольку это основной компонент, определяющий, какие эксперты выбираются в данный момент.
(1) KeepTopK
Одним из способов балансировки нагрузки маршрутизаторов является использование простой политики масштабирования под названием KeepTopK.
Вводя обучаемый (гауссовский) шум, мы можем предотвратить выбор одного и того же эксперта:

Затем веса всех экспертов, за исключением первых k экспертов (например, 2), которых мы хотим активировать, устанавливаются на -∞:

Если эти веса установлены на -∞, выходная вероятность после операции SoftMax становится равной 0:

Следует отметить, что KeepTopK можно реализовать и без использования дополнительного шума.
Стратегия выбора токенов
Стратегия KeepTopK направляет каждый токен нескольким выбранным экспертам.
Такой подход называется выбором токена и позволяет направить заданный токен эксперту (маршрутизация топ-1):

Или направить нескольким экспертам (маршрутизация top-k):

Главное преимущество этой стратегии заключается в том, что она взвешивает вклады отдельных экспертов и объединяет их.
Вспомогательные потери
Для достижения равномерного распределения экспертов во время обучения к обычным потерям сети добавляются вспомогательные потери (также называемые потерями балансировки нагрузки).
Вспомогательная потеря добавляет ограничение, которое заставляет экспертов иметь одинаковую значимость в процессе обучения.
Первый компонент вспомогательного убытка представляет собой сумму значений маршрутизации каждого эксперта по всей партии:

Это дает нам оценку важности для каждого эксперта, т. е. вероятность выбора данного эксперта независимо от входных данных.
Мы можем использовать эти оценки важности для расчета коэффициента вариации (CV), который представляет собой степень различия между оценками важности разных экспертов.

Например, если различия между оценками важности велики, то значение CV будет высоким:

Напротив, если все эксперты имеют схожие оценки, значение CV будет низким (чего мы и ожидаем):

Используя эту оценку CV, мы можем обновить вспомогательные потери во время обучения, чтобы минимизировать оценку CV (тем самым придав каждому эксперту одинаковую важность):

Наконец, вспомогательный убыток будет использоваться как независимый член убытка для участия в оптимизации обучения.
(2) Экспертные возможности
Дисбаланс экспертов отражается не только в выбранных экспертах, но и в распределении токенов, выделенных этим экспертам.
Например, если входные токены распределяются непропорционально среди определенных экспертов, это может привести к недообучению некоторых экспертов:

Здесь нам нужно учитывать не только то, какие эксперты привлекаются, но и то, как часто эти эксперты привлекаются.
Решением этой проблемы является ограничение количества токенов, которые может обрабатывать каждый эксперт, а именно пропускной способности эксперта.
Когда эксперт достигает своего лимита, излишки токенов будут переданы следующему эксперту:

Если оба эксперта достигли своей емкости, токен не будет обработан ни одним экспертом, а будет передан непосредственно на следующий уровень. Такая ситуация называется переполнением токена.

(3) Использование трансформера-переключателя для упрощения MoE
Первой моделью MoE на основе трансформера, которая решает проблемы нестабильности обучения MoE, такие как балансировка нагрузки, является Switch Transformer. Техннология переключателя повышает стабильность обучения за счет упрощения архитектуры и процесса обучения.
Коммутационный слой
Switch Transformer — это модель T5 (структура кодер-декодер), которая заменяет традиционный слой FFNN на коммутационный слой.
Уровень коммутации представляет собой разреженный уровень MoE, который выбирает одного эксперта (маршрутизация топ-1) для каждого токена.

Маршрутизатор не использует специальный метод для выбора эксперта, а просто берет softmax результата умножения входных данных на вес эксперта (так же, как и в предыдущем методе).

Коэффициент мощности
Коэффициент мощности — важный параметр, определяющий количество токенов, с которыми может работать каждый эксперт. Трансформер-переключатель расширяет эту концепцию, вводя коэффициент мощности, который напрямую влияет на пропускную способность эксперта.

Компоненты экспертного потенциала довольно просты:

Если мы увеличим коэффициент мощности, каждый специалист сможет обрабатывать больше токенов.

Однако если коэффициент мощности слишком велик, вычислительные ресурсы будут расходоваться впустую. Напротив, если коэффициент мощности слишком мал, производительность модели ухудшится из-за переполнения токенов.
Вспомогательные потери
Чтобы еще больше предотвратить выбрасывание токенов, Switch Transformer вводит упрощенную версию вспомогательной потери.
В упрощенной версии вспомогательного лосса коэффициент вариации больше не рассчитывается, но количество назначенных токенов сравнивается взвешенно с вероятностью маршрутизации каждого эксперта:

Поскольку цель состоит в том, чтобы равномерно распределить токены среди N экспертов, мы хотим, чтобы значения векторов P и f были равны 1/N.
α — гиперпараметр, используемый для точной настройки важности этой потери во время обучения. Слишком большое значение повлияет на основную функцию потерь, тогда как слишком малое значение не позволит эффективно выполнять балансировку нагрузки.
Смесь моделей экспертов в моделировании видения
MoE не ограничивается языковыми моделями. Модели машинного зрения, такие как ViT, используют архитектуру Transformer и, следовательно, могут также использовать MoE.
Кратко напомним, что ViT (Vision Transformer) — это архитектура, которая разбивает изображение на несколько блоков и обрабатывает их как токены.
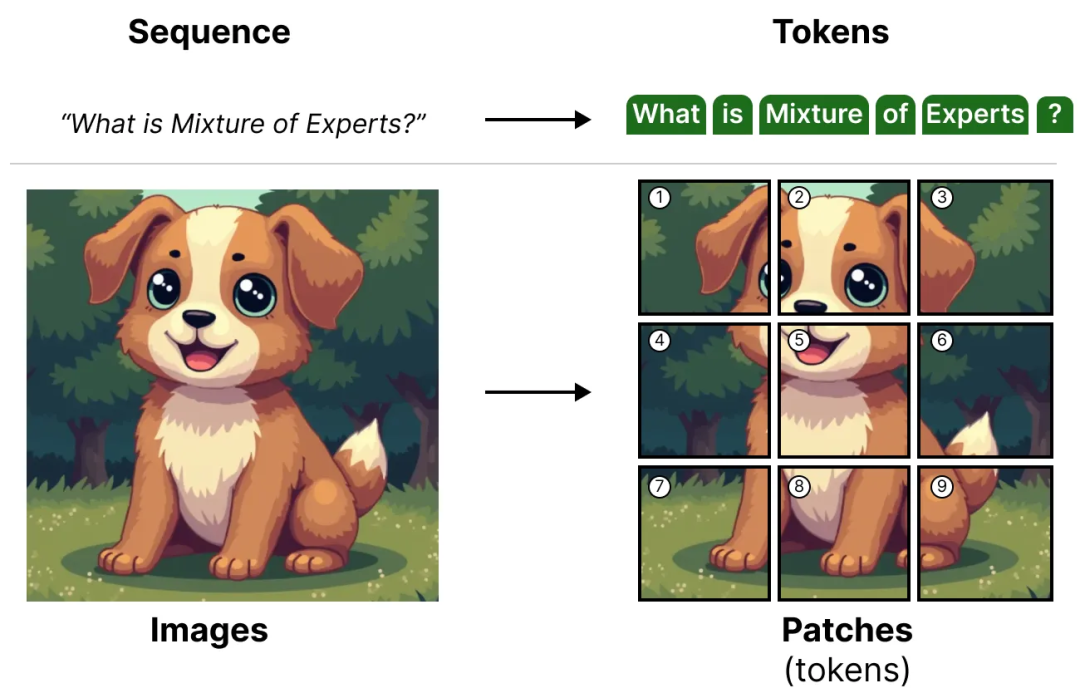
Эти фрагменты изображения (или токены) проецируются в векторы представления (плюс дополнительный позиционный вектор представления), а затем передаются в обычный кодер:

Когда эти фрагменты изображения поступают в кодер, они обрабатываются как токены, что делает эту архитектуру хорошо подходящей для MoE.
(1) Vision-MoE
Vision-MoE (V-MoE) — один из первых примеров реализации MoE в модели изображения. Он заменяет плотные слои FFNN в ViT на разреженные MoE.

Это улучшение позволяет моделям ViT (которые обычно меньше языковых моделей) существенно масштабироваться за счет увеличения числа экспертов.
Для уменьшения ограничений оборудования для каждого эксперта устанавливается небольшая предопределенная емкость, поскольку изображения обычно содержат большое количество участков.
Однако низкая емкость часто приводит к отбрасыванию блоков изображений (аналогично переполнению токена).

Чтобы поддерживать низкую емкость, сеть присваивает каждому патчу оценку важности и отдает приоритет патчам с более высокими оценками, тем самым избегая потери переполненных патчей.
Такой подход называется пакетной приоритетной маршрутизацией.

Таким образом, даже при уменьшении количества токенов мы все равно можем видеть, что важные фрагменты изображения успешно маршрутизируются.

Приоритетная маршрутизация позволяет сосредоточиться на наиболее важных блоках изображения, обрабатывая меньшее количество блоков изображения.
(2) От разреженного MoE к мягкому MoE
В V-MoE механизм оценки приоритетов позволяет различать важные и неважные участки изображения. Однако после того, как фрагменты изображения назначены каждому эксперту, информация в необработанных фрагментах изображения теряется.
Целью Soft-MoE является переход от распределения дискретных блоков изображений (токенов) к мягкому распределению путем смешивания блоков изображений.
На первом этапе мы умножаем входные данные x (внедрение фрагмента изображения) на обучаемую матрицу Φ. Это позволит сгенерировать информацию о маршрутизации, которая покажет нам, насколько токен релевантен конкретному эксперту.

Затем матрица маршрутной информации подвергается операции softmax (по столбцам) для обновления вектора внедрения каждого фрагмента изображения.

Обновленное внедрение фрагмента изображения по сути представляет собой средневзвешенное значение всех внедрений фрагментов изображения.

Визуально это выглядит так, как будто все фрагменты изображения смешаны. Объединенные фрагменты изображений отправляются каждому эксперту. После генерации выходных данных они снова умножаются на матрицу маршрутизации.
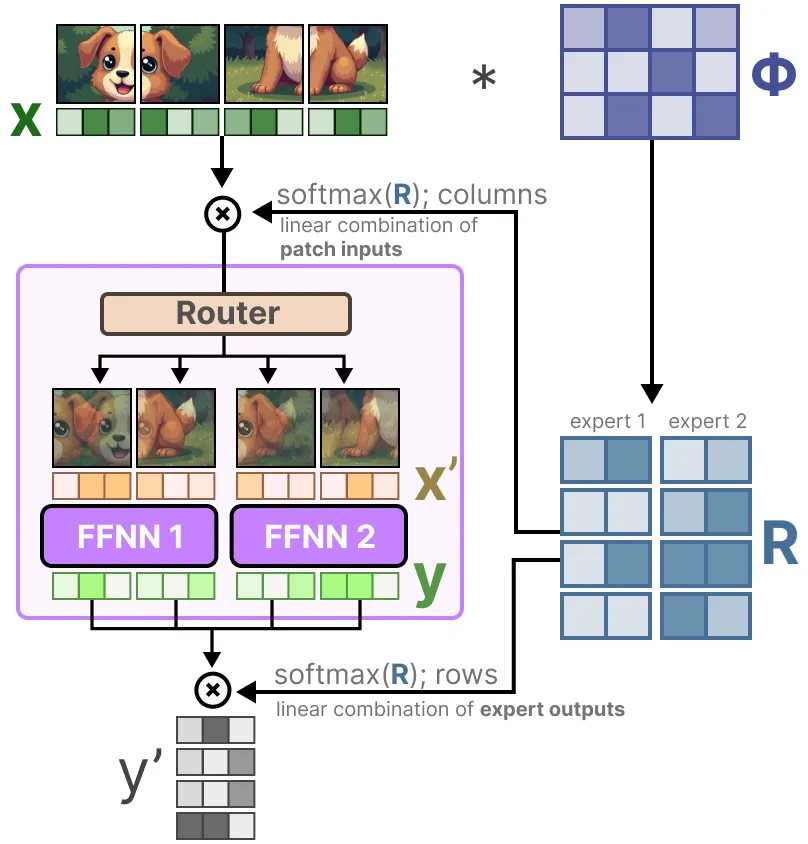
Матрица маршрутизации влияет на вход на уровне токенов и выход на уровне экспертов.
В результате мы получаем «мягкие» фрагменты/токены изображений, которые обрабатываются вместо дискретных входных данных.
Активация Mixtral 8x7B и сравнение разреженных параметров
Важной характеристикой MoE являются его вычислительные требования. Поскольку одновременно используется только часть экспертов, у нас может быть больше параметров, чем фактически используется.
Хотя данный MoE имеет больше параметров (разреженные параметры), активируется меньше параметров, поскольку во время вывода мы используем только подмножество экспертов (активные параметры).

Другими словами, нам по-прежнему необходимо загрузить всю модель (включая всех экспертов) в устройство (разреженные параметры), но при фактическом выполнении вывода нам нужно использовать только подмножество параметров (активные параметры). Модель MoE требует больше памяти графического процессора для загрузки всех экспертов, но работает быстрее во время вывода.
Давайте возьмем в качестве примера Mixtral 8x7B, чтобы изучить разницу в количестве разреженных параметров и активных параметров.
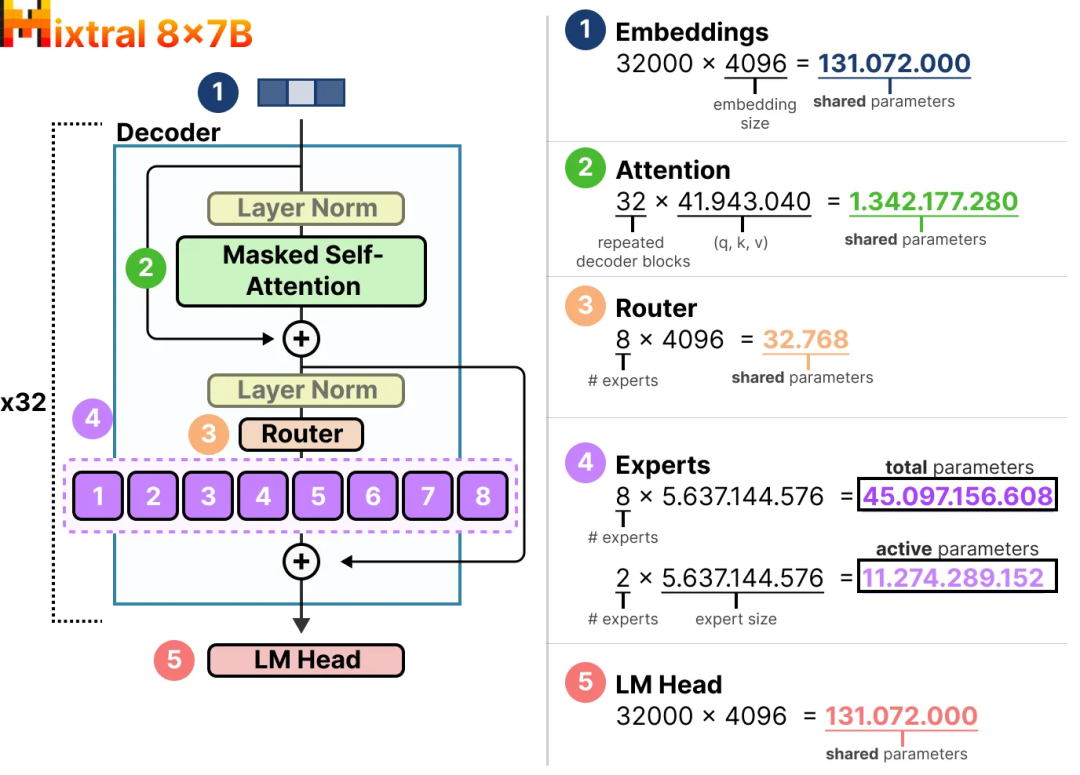
В этом примере мы видим, что количество параметров на одного эксперта составляет 5,6 млрд, а не 7 млрд (хотя всего экспертов 8).

Нам необходимо загрузить 8×5,6 Б (46,7 Б) параметров (плюс все общие параметры), но для вывода необходимо только 2×5,6 Б (12,8 Б) параметров.
В заключение
На этом наше исследование моделей «Смесь экспертов» (MoE) закончено! Надеюсь, эта статья помогла вам лучше понять потенциал этой интересной технологии. Сегодня практически каждая модель архитектуры имеет вариант MoE, что говорит о том, что она, вероятно, будет существовать еще долгое время.
Скрытый текст
🔥Не пропустите важные обновления и углубленные материалы!🔥
Хотите быть в курсе самых свежих обзоров и исследований в мире ML и AI? Переходите по ссылкам ниже, чтобы получить доступ к эксклюзивному контенту:
📌 Все обзоры также доступны в нашем Telegram канале TheWeeklyBrief📢
📌 Более подробный обзор с математической формализацией и программным кодом ждет вас в нашем репозитории Weekly-arXiv-ML-AI-Research-Review 👩💻📂✨
Не упустите шанс глубже погрузиться в мир технологий! 🚀
ссылка на оригинал статьи https://habr.com/ru/articles/882948/
Добавить комментарий