
Всем привет! Меня зовут Сергей Хорошеньких, я руковожу службой исследований и разработки в Яндекс Доставке. Наша команда изучает и внедряет алгоритмы, которые повышают операционную эффективность сервиса.
Изначально Яндекс Доставка была тарифом внутри Яндекс Такси. Но спрос был таким большим, что довольно быстро стало ясно: надо развивать доставку как отдельный продукт, покрывающий множество пользовательских сценариев. И с 2019 года Яндекс Доставка стала самостоятельным сервисом.
Доставка день в день — это не только сценарий «сходи за меня в магазин», но и возможность передать посылку с помощью сервиса. Эти сценарии объединяет то, что они происходят в рамках одного города. Про этот вид доставки мы и поговорим: я расскажу, что уже изобретено для этого сценария, а чего нам не хватало и какие задачи предстояло решить с помощью алгоритмов доставки.
Как устроен поиск и назначение для доставки день в день
Обычно под доставкой день в день подразумевают экспресс‑доставку, но это довольно дорогое решение, которое подходит для срочных заказов. А ещё есть спрос на доставку в течение дня — когда товары пользователю нужны не в каком‑то определённом интервале, а просто сегодня.
Одна из ключевых трудностей доставки день в день состоит в том, что её сложно запланировать, так как заказы поступают в течение дня. И нужно научиться на лету находить и назначать исполнителей на приходящие заказы. В этой статье мы разберём алгоритмы поиска и назначения курьеров.
При построении алгоритмов доставки день в день мы будем иметь дело с двумя ключевыми сущностями: заказами, которые размещают пользователи, и курьерами, которые эти заказы выполняют. При проектировании системы назначения курьеров на заказы необходимо:
-
Сформулировать основные свойства и ограничения, которые есть у заказов и курьеров.
-
Оценить, сколько сущностей нам нужно обрабатывать в единицу времени.
Заказ — это, прежде всего, пара точек: точка отправления (А) и точка вручения (Б). На каждой из этих точек есть ограничения по времени: курьер должен прибыть в точку в определённый интервал. Интервал выбирается клиентом при создании заказа, причём более широкий интервал при прочих равных стоит дешевле.

Интервалы чаще всего имеют вид «от момента создания заказа нужно забрать заказ в течение X минут в точке А и в течение Y минут оказаться в точке Б». У заказа могут быть указаны особые требования, например наличие термосумки, которые влияют на выбор курьера. Также обычно у заказов известны вес и габариты.
У работы курьеров есть нюансы:
-
Сервис функционирует по модели маркетплейса: то есть курьеры могут выйти на линию когда угодно, где угодно и на сколько угодно.
-
Заказы поступают в систему непрерывно, и мы должны подобрать под них наиболее подходящих в моменте исполнителей. А исполнители, при некоторых ограничениях, могут отказываться от предложений.
-
У курьеров бывают разные характеристики. Например, тип транспорта: кроме курьеров на автомобилях, также бывают исполнители на скутерах, велосипедах или без транспорта вовсе. От этого зависит возможная дальность и грузоподъёмность. Другой пример — наличие термосумки, что очевидно влияет на возможность доставки определённых видов заказов.
Теперь оценим нагрузку на систему: для проектирования алгоритмов необходимо хотя бы примерно понимать, сколько сущностей (заказов и курьеров) нужно обрабатывать в единицу времени. На практике часто бывает так, что точный масштаб будущей системы неизвестен, а оценки от бизнеса отличаются на порядок. Поэтому нам в любом случае больше интересна асимптотика (чтобы система могла горизонтально масштабироваться), а для ориентира возьмём величину ~ заказов в сутки.
заказов в сутки.
-
Бо́льшая часть заказов поступает в систему в рабочее время: для круглого счёта возьмём 10 часов. Значит, нужно обрабатывать ~
 заказов в час, или несколько заказов в секунду.
заказов в час, или несколько заказов в секунду. -
Сколько нам нужно курьеров? Поскольку мы должны выполнить все входящие заказы, то оценим, сколько примерно нужно человеко‑часов на выполнение всех заказов за день, и поделим это значение на примерное среднее время работы одного курьера за день.
-
Типичный заказ занимает примерно полчаса‑час времени курьера (если бы он вёз только этот заказ, как в такси). Это сильно зависит от географии города и от конкретной дорожной ситуации, но, так или иначе, это десятки минут. По порядку величины это составляет ~
 человеко‑часов в день.
человеко‑часов в день. -
Типичный курьер проводит на линии несколько часов в день. Из нашей предыдущей оценки ~
 человеко‑часов в день (на всех курьеров) получается, что нам нужно несколько десятков тысяч курьеров.
человеко‑часов в день (на всех курьеров) получается, что нам нужно несколько десятков тысяч курьеров.
Итого в нашу систему поступает несколько заказов в секунду и у нас десятки тысяч исполнителей.
Алгоритм: поиск ближайшего исполнителя
Начнём с самого простого метода назначения — найти самого ближайшего подходящего исполнителя для заказа. Для этого нужно как минимум знать, где находится каждый курьер.
Напомним, что курьер работает с приложением, которое периодически отправляет нам координаты. С какой частотой их нужно отправлять? Если взять среднюю скорость автомобиля по городу 30 км/ч, то за одну секунду автомобиль в среднем проезжает примерно 8 метров. Это как раз примерно та точность, которая нам нужна, а значит, обновлять координаты нужно раз в секунду. Получается, что суммарно от всех исполнителей мы должны будем обрабатывать десятки тысяч обновлений в секунду.
Мы могли бы хранить данные об исполнителях в хеш‑таблице, ключом которой является некоторый идентификатор курьера, который приходит вместе с координатами, а значением — его актуальные координаты. Такая структура данных отлично подходит для хранения актуальных координат, но совершенно не годится, чтобы искать ближайшего исполнителя к заказу. Тогда на каждый запрос нужно перебирать всех исполнителей в системе, что крайне избыточно, так как достаточно близко к заказу обычно находятся десятки исполнителей, остальных можно не рассматривать совсем.
 / (15 × 18) = 0,03, то есть из 1000 курьеров только 30 попадут в круг")
Для эффективного поиска точек в пространстве уже придуманы различные алгоритмы и структуры данных. Мы используем k‑d-дерево, реализованное в библиотеке nanoflann. Теперь предлагаю поближе познакомиться с этой структурой данных и с алгоритмами поиска поверх неё.
Как работает k-d-дерево
K‑d-дерево (k‑dimensional, k‑мерное) — это двоичное дерево, предназначенное для хранения и поиска k‑мерных векторов. Оно в некотором отношении похоже на классическое двоичное дерево поиска: у каждого узла k‑d-дерева есть два дочерних поддерева, каждое из которых тоже является k‑d-деревом.
Каждый узел k‑d-дерева хранит в себе данные: в отличие от двоичного дерева поиска это не одно число, а упорядоченный набор чисел (вектор). С векторами работать немного сложнее, потому что, в отличие от чисел, векторы не всегда можно сравнить между собой. То есть в общем случае для пары векторов нельзя определить, какой из них больше, а какой — меньше.
Для простоты и наглядности мы рассмотрим случай k = 2, когда данными являются точки на плоскости, однако все идеи и подходы нетрудно обобщить на случай произвольной размерности. Для понимания ключевой идеи k‑d-дерева можно вдохновиться известным математическим методом охоты на львов в пустыне Сахара:
МЕТОД БОЛЬЦАНО — ВЕЙЕРШТРАССА. Рассекаем пустыню линией, проходящей с севера на юг. Лев находится либо в восточной части пустыни, либо в западной. Предположим для определённости, что он находится в западной части. Рассекаем её линией, идущей с запада на восток. Лев находится либо в северной части, либо в южной. Предположим для определённости, что он находится в южной части, рассекаем её линией, идущей с севера на юг. Продолжаем этот процесс до бесконечности, воздвигая после каждого шага крепкую решётку вдоль разграничительной линии. Площадь последовательно получаемых областей стремится к нулю, так что лев в конце концов оказывается окружённым решёткой произвольно малого периметра.
Если подойти к вопросу немного серьёзнее, то идея звучит так:
-
В каждом узле дерева мы зададим направление, в котором этот узел разбивает плоскость по горизонтали (по оси x — на западную и восточную части) или по вертикали (по оси y — на северную и южную части).
-
При продвижении по дереву сверху вниз направления будем чередовать: в корне дерева будем разбивать по горизонтали, в потомках — по вертикали, в потомках потомков — опять по горизонтали и так далее («потомки» — термин из теории деревьев, у узла есть потомки, или «дети»).
-
При построении дерева и в операциях над ним мы будем сохранять следующий инвариант. Пусть в вершине хранится вектор (x0, y0). Тогда, если разбиение в вершине выбрано по оси x, то в левом поддереве все элементы имеют первую координату строго меньше x0, а в правом поддереве — больше либо равную x0. Заметим, что на вторую координату ограничений нет. Если же разбиение в вершине выбрано по оси y, то в левом поддереве все элементы должны иметь вторую координату строго меньше y0, а в правом поддереве — больше либо равную y0.

Как же построить такое дерево? Применим стандартный приём: определим операцию вставки вершины в дерево, а потом с помощью этой операции последовательно добавим в дерево все вершины. Узел дерева зададим следующей структурой:
class KDNode: def __init__(self, point: Point, cut_dim: int): self.point = point # Двумерный вектор (точка) self.cut_dim = cut_dim # Номер координаты, по которой в узле производится разбиение (0 — по оси x, 1 — по оси y) self.left = None # Ссылка на левое поддерево self.right = None # Ссылка на правое поддерево def in_left_subtree(self, pt: Point): # Функция, определяющая, в каком поддереве искать заданную точку return pt[self.cut_dim] < self.point[self.cut_dim]Операцию вставки зададим рекурсивно:
def insert(pt: Point, p: KDNode, cd: int): if p is None: # «Выпали» из дерева, или дерево ещё не создано p = KDNode(pt, cd) # Создаём новый узел elif p.in_left_subtree(pt): # Если нужно вставить в левое поддерево, то в этом поддереве номер координаты разбиения циклически чередуем p.left = insert(pt, p.left, (cd+1)%2) else: # Аналогично для правого поддерева p.right = insert(pt, p.right, (cd+1)%2) return pНам понадобится не только вставлять, но и удалять вершины из k‑d-дерева. Как и в случае с обычными бинарными деревьями поиска, самый сложный сценарий — удаление из середины дерева. Без ограничения общности считаем, что в удаляемой вершине задана ориентация разбиения по оси x. Простой вариант удаления выглядит так:
-
Если у удаляемой вершины есть правое поддерево, то в нём находим вершину с минимальной координатой x. Значение в этой вершине копируем в удаляемый узел. После такого получим дерево, в котором одно и то же значение дублируется два раза — в узле и в правом поддереве. Удаляем это значение из правого поддерева, запуская рекурсивно процедуру удаления.
-
Если у удаляемой вершины есть только левое поддерево, то поступаем точно так же, дополнительно скопировав удаляемый узел в правое поддерево. Это позволяет сохранить все инварианты, которые требуется поддерживать в k‑d-дереве, но при этом приводит к некоторому дисбалансу.

Дальше нам нужно было найти все точки, которые попадают в заданную на карте область. В исходной постановке область — это круг с центром в точке А заказа. Но мы немного упростим себе задачу и рассмотрим поиск не в круге, а в прямоугольнике, стороны которого параллельны координатным осям.

Для решения этой задачи нам нужно будет немного обогатить k‑d-дерево. А именно: для k‑d-дерева T введём понятие «ограничивающий прямоугольник» (bounding box) — это прямоугольник, который содержит все точки из T и стороны которого параллельны координатным осям.
Такой прямоугольник задаётся координатами двух точек: нижнего левого и верхнего правого угла. Для графа на картинке выше его ограничивающий прямоугольник задаётся точками (5, 5) и (90, 75). Чтобы найти такой прямоугольник, нужно один раз пройтись по входным данным, что мы в любом случае сделаем при построении дерева.
Нам потребуются ограничивающие прямоугольники для всех поддеревьев, их можно найти рекурсивно. Зная ограничивающий прямоугольник для k‑d-дерева T и зная направление разбиения в корне (на рисунке обозначено как cd, cutting dimension), можно элементарно найти ограничивающие прямоугольники для левого и правого поддеревьев корня. На рисунке — пример для разбиения по оси x:

Также нам потребуются две простые операции над прямоугольниками:
-
определить, что прямоугольники не пересекаются;
-
определить, что один из прямоугольников вложен в другой.

Итак, мы определили понятие ограничивающего прямоугольника, понимаем, как его находить, и умеем выполнять простые операции над прямоугольниками. Этого достаточно, чтобы сформулировать рекурсивную процедуру поиска в прямоугольнике R для k‑d-дерева T, имеющего ограничивающий прямоугольник B.
def range_search(R: Rectangle, T: KDNode, B: Rectangle) -> tp.List[Point]: if T is None: # Если дерево пустое, то ответ пустой return [] elif R.is_disjoint(B): # Если ограничивающий прямоугольник не пересекается # с областью поиска, то ответ пустой return [] elif R.contains(B): # Если ограничивающий прямоугольник полностью лежит # в области поиска, то возвращаем все точки дерева return collect_points(p) else: # Общий случай — R и B пересекаются res = [] # Проверяем, лежит ли значение корня дерева в области поиска if R.contains_point(T.point): res.append(T.point) # Рекурсивно вычисляем ограничивающие прямоугольники # и запускаем поиск для левого и правого поддерева B_left = B.left_part(T.cut_dim, T.point) res += range_search(R, T.left, B_left) B_right = B.right_part(T.cut_dim, T.point) res += range_search(R, T.right, B_right) return res Такому алгоритму требуется посетить порядка  вершин, чтобы найти все точки, лежащие в заданной области поиска.
вершин, чтобы найти все точки, лежащие в заданной области поиска.
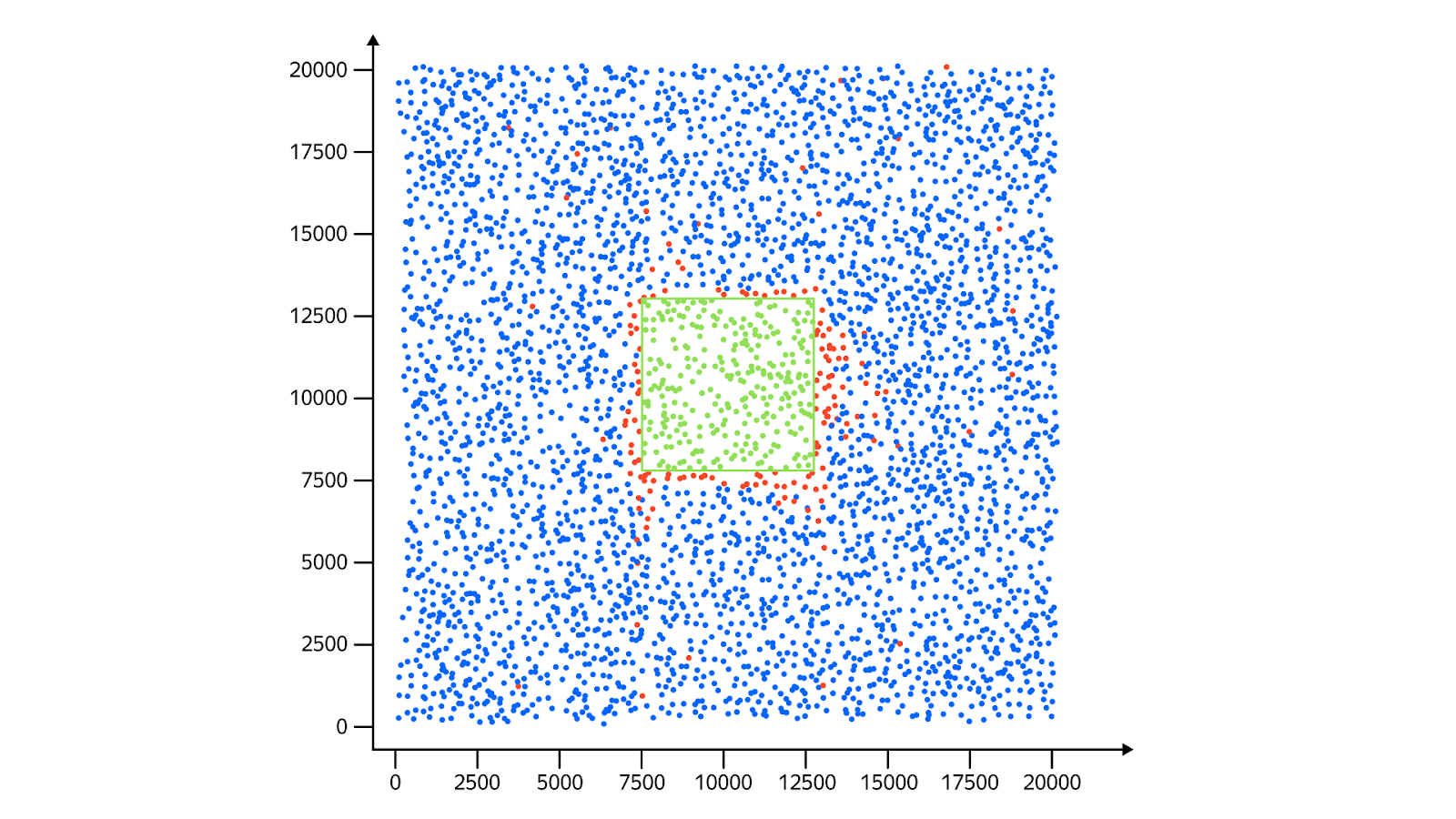
Теперь посмотрим, как работает этот алгоритм на интересующих нас масштабах. В качестве входных данных возьмём 5000 точек, случайно и равномерно распределённых в квадрате 20 × 20 километров. Синим обозначены все точки, зелёным — те из них, которые попали в зону поиска, а красным — точки, посещённые алгоритмом, но не попавшие в зону поиска. Искать будем в квадратах 2 × 2 и 5 × 5 километров.
При поиске в квадрате 2 × 2 в зону поиска попали 44 точки, а всего алгоритм посетил 167 вершин:

При поиске в квадрате 5 × 5 в зону поиска попали 302 точки, а всего алгоритм посетил 535 вершин:
Напоследок вспомним, что позиции исполнителей постоянно меняются. А значит, нам нужно поддержать операцию обновления координат. Это можно сделать так: для дерева T в отдельной хеш‑таблице H хранить для исполнителя ту координату, которая добавлена в T. При получении обновления координаты нужно:
-
Удалить старую координату из T.
-
Вставить новую координату в T.
-
Обновить координату в H.
Для сбалансированного k‑d-дерева удаление и вставка имеют сложность  , поэтому полученная операция обновления получается эффективной.
, поэтому полученная операция обновления получается эффективной.
Итак, с помощью k‑d-дерева мы можем эффективно искать исполнителей, близких к заказу. Но здесь нужно учесть важный момент: близость мы вычисляем на плоскости. Однако город — это не плоскость, и фактическое расстояние исполнителю необходимо будет преодолевать по дорогам. Поэтому вышеописанный поиск по k‑d-дереву лишь приближенный, и его результаты нужно уточнить, вычислив для каждого из найденных исполнителей расстояние и время по реальным городским маршрутам. Как это сделать?

Для каждого найденного исполнителя нам необходимо найти кратчайший маршрут до точки А. Конечно, нам не придётся решать эту задачу с нуля: у Яндекса есть собственная технология построения маршрутов, которая доступна по API, а ещё, например, существует проект OpenStreetMap, который предоставляет различные геоданные для бесплатного использования, в том числе и для поиска маршрутов.
Применяется следующий подход: для интересующей нас дорожной сети строится взвешенный ориентированный граф, который мы будем называть дорожным графом. Данные для дорожного графа можно собирать из различных источников: например, с помощью спутниковых снимков или ручной разметки. Ребро графа соответствует какому‑то непрерывному участку дороги: например, одной дорожной полосе без поворотов. В качестве веса ребра берётся оценка времени, нужного для преодоления этого участка. Важно, что один и тот же участок дороги может иметь разную оценку времени в зависимости от дорожной ситуации.
 дорожного графа")
Давайте попробуем оценить количество рёбер в дорожном графе по порядку величины. Сперва прикинем, с какой точностью нужно «нарезать» реальную дорожную сеть, чтобы построить хорошее приближение в виде графа (иными словами, какого порядка будет средний размер одного ребра в метрах). Точность в 1 метр нам скорее не нужна, а точность 100 метров уже слишком плохая — значит, возьмём для оценки порядок 10 метров. Если мы представим себе квадратную сетку из таких рёбер, то на один квадратный километр такой сетки придётся  рёбер (умножение на 2, потому что граф ориентированный).
рёбер (умножение на 2, потому что граф ориентированный).
Далее сделаем оценку для Москвы: её площадь составляет около 2500 км2, что даёт нам примерно  рёбер. Чтобы сделать оценку для всей России, умножим оценку для Москвы примерно на 20, получив в итоге значение
рёбер. Чтобы сделать оценку для всей России, умножим оценку для Москвы примерно на 20, получив в итоге значение  (миллиард) рёбер.
(миллиард) рёбер.
Посчитаем, сколько памяти будет занимать такой граф. Для каждого ребра нам нужно хранить идентификаторы вершин и значение веса. В нашей модели количество вершин пропорционально количеству рёбер, значит, счёт идёт на сотни миллионов или миллиарды вершин.
Чтобы каждой вершине приписать идентификатор, стоит заложить 4 байта на вершину (тип unsigned long). А ещё на каждое ребро нужно потратить пару байт, чтобы хранить вес в short int. Итого получается около 10 байт на ребро, и это даёт нам оценку порядка 10 гигабайт на весь граф. Довольно много, но в память поместится.
Дорожный граф можно немного модифицировать, добавив две дополнительные вершины: одну для водителя и одну для точки назначения. Эти вершины можно построить, спроецировав координаты водителя и координаты точки назначения на ближайшие рёбра.

Осталось запустить на полученном графе алгоритм поиска кратчайшего пути, также известный как алгоритм Дейкстры. Давайте вспомним (или узнаем), как работает этот алгоритм.
Алгоритм Дейкстры
Алгоритм Дейкстры помогает найти кратчайшие расстояния от заданной вершины до всех остальных вершин во взвешенном ориентированном графе с неотрицательными весами. Рассмотрим для примера следующий граф, в котором мы будем искать расстояния от вершины  до всех остальных вершин.
до всех остальных вершин.

В алгоритме Дейкстры поддерживается множество вершин  , для которых уже вычислены окончательные веса кратчайших путей до них из заданной вершины
, для которых уже вычислены окончательные веса кратчайших путей до них из заданной вершины  . Также по ходу алгоритма мы будем обновлять оценки весов кратчайших путей до всех вершин. Алгоритм инициализируется так:
. Также по ходу алгоритма мы будем обновлять оценки весов кратчайших путей до всех вершин. Алгоритм инициализируется так:
-
 (кратчайшие пути ни для каких вершин не вычислены);
(кратчайшие пути ни для каких вершин не вычислены); -
![d[s] = 0](https://habrastorage.org/getpro/habr/upload_files/029/11c/e04/02911ce0448059af11d5e1d215703b12.svg) (расстояние от
(расстояние от  до самой себя нулевое);
до самой себя нулевое); -
![d[v]=∞,v ≠ s](https://habrastorage.org/getpro/habr/upload_files/fee/afe/caa/feeafecaa3655689f37d0b5242f1624f.svg) (расстояния до остальных вершин оцениваем сверху как бесконечное).
(расстояния до остальных вершин оцениваем сверху как бесконечное).
Те вершины, для которых пока не вычислены окончательные веса, образуют очередь  , из которой на каждой итерации мы будем переносить одну вершину в
, из которой на каждой итерации мы будем переносить одну вершину в  . До начала работы алгоритма
. До начала работы алгоритма  (ни для какой вершины не вычислены кратчайшие пути).
(ни для какой вершины не вычислены кратчайшие пути).
Алгоритм Дейкстры можно записать так:
# Пока есть вершины, для которых не вычислены кратчайшие расстояния while Q: # Находим в очереди вершин ту, для которой текущая оценка кратчайшего расстояния минимальна u = argmin(Q, d) # Эту вершину считаем «рассмотренной» S = S + {u} # И удаляем её из очереди Q = Q - {u} # Проводим «релаксацию», то есть переоцениваем кратчайшие расстояния до всех соседей вершины u for n, w in neighbors[u]: if d[u] + w < d[n]: d[n] = d[u] + wВот как работает алгоритм Дейкстры для графа из примера выше:
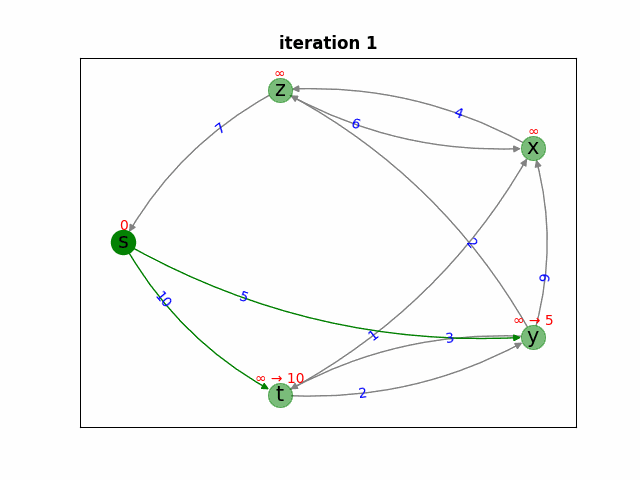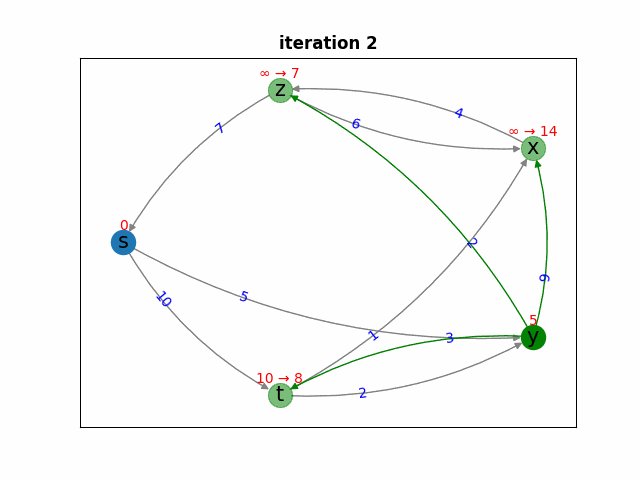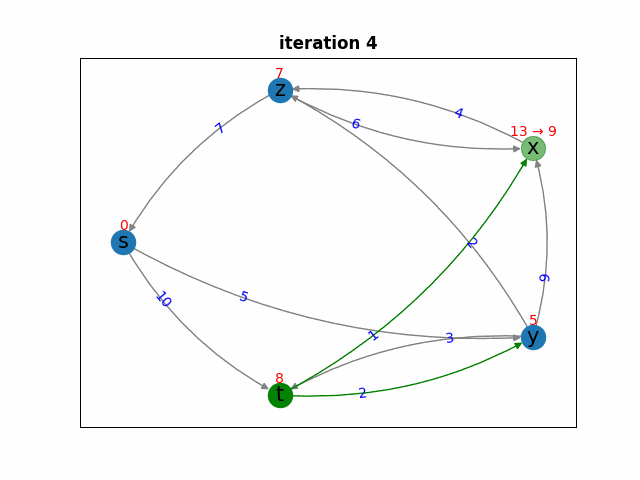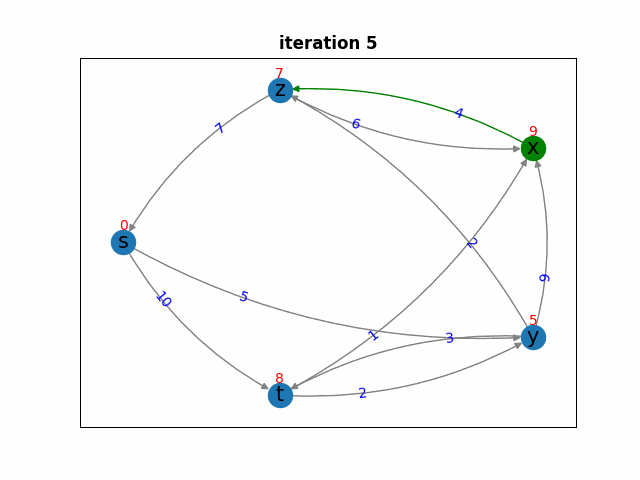
Синим цветом отмечены вершины из множества  , зелёным — вершины из очереди
, зелёным — вершины из очереди  . Тёмно‑зелёным цветом выделяется та вершина из
. Тёмно‑зелёным цветом выделяется та вершина из  , которая на данной итерации переходит в
, которая на данной итерации переходит в  . Красным показаны оценки расстояний
. Красным показаны оценки расстояний  , а зелёные рёбра указывают на соседей выбранной вершины, для которых проводится релаксация.
, а зелёные рёбра указывают на соседей выбранной вершины, для которых проводится релаксация.
Операцию argmin можно реализовать эффективнее, чем просто полным перебором, если использовать очередь с приоритетами.
Чтобы понять интуицию, которая стоит за этим алгоритмом, рассмотрим детальнее первые несколько итераций.
Итерация 1. Мы с полной уверенностью добавляем s в множество рассмотренных вершин, потому что расстояние от вершины до самой себя равно  . Обновляем оценки расстояний до всех соседей:
. Обновляем оценки расстояний до всех соседей: ![d[y] = 5, d[t] = 10](https://habrastorage.org/getpro/habr/upload_files/3e6/fa6/a34/3e6fa6a3491de951c985261a0b878d97.svg) .
.
Итерация 2. Самая близкая вершина по оценке расстояния — вершина ![y, d[y] = 5](https://habrastorage.org/getpro/habr/upload_files/2c5/963/b9b/2c5963b9b18cfb5b8f046ef110d5ee94.svg) . Уверены ли мы, что до этой вершины не найдётся расстояния короче? Да, уверены, потому что эта вершина — ближайший сосед вершины
. Уверены ли мы, что до этой вершины не найдётся расстояния короче? Да, уверены, потому что эта вершина — ближайший сосед вершины  , а раз отрицательных весов в графе нет, то путь через другого соседа (через вершину
, а раз отрицательных весов в графе нет, то путь через другого соседа (через вершину  ) не может быть короче, ведь
) не может быть короче, ведь ![w(s, t) = 10 > d[y]](https://habrastorage.org/getpro/habr/upload_files/cb2/9cc/d9e/cb29ccd9ec58691b19d7e04425dca175.svg) . Значит, можем гарантированно считать, что кратчайшее расстояние до
. Значит, можем гарантированно считать, что кратчайшее расстояние до  известно и равно
известно и равно  . Для соседей вершины
. Для соседей вершины  обновляем оценки кратчайших расстояний:
обновляем оценки кратчайших расстояний: ![d[z] = 7, d[t] = 8](https://habrastorage.org/getpro/habr/upload_files/bd7/a34/e70/bd7a34e706090fe81a36c22f49a45fd4.svg) .
.
Итерация 3. На этой итерации мы выберем вершину  , и расстояние до неё считаем равным
, и расстояние до неё считаем равным ![d[z] = 7](https://habrastorage.org/getpro/habr/upload_files/7cb/ee2/405/7cbee24056ee8e4e3b0b61dd4aa40a0a.svg) . Почему расстояния короче быть не может? До вершины
. Почему расстояния короче быть не может? До вершины  мы можем «дойти» по графу либо через вершину
мы можем «дойти» по графу либо через вершину  , либо через вершину
, либо через вершину  . Путь через вершину
. Путь через вершину  займёт как минимум
займёт как минимум  , что уже больше 7; значит, кратчайший путь проходит через вершину
, что уже больше 7; значит, кратчайший путь проходит через вершину  . Для вершины y мы уже убедились, что кратчайший путь до неё — 5. Поскольку
. Для вершины y мы уже убедились, что кратчайший путь до неё — 5. Поскольку  является непосредственным соседом
является непосредственным соседом  , то можно применить уже знакомые нам рассуждения: путь из
, то можно применить уже знакомые нам рассуждения: путь из  в
в  может быть либо напрямую, либо через другие вершины (через
может быть либо напрямую, либо через другие вершины (через  или
или  ), но через другие вершины точно длиннее.
), но через другие вершины точно длиннее.
Для остальных итераций алгоритма можно применить аналогичные рассуждения.
Напоследок заметим, что алгоритм Дейкстры для нашей задачи (определение кратчайшего расстояния между заданной парой вершин  и
и  ) не требует полного перебора всех вершин. В силу того, как устроен алгоритм, итерации можно завершить после того, как вершина
) не требует полного перебора всех вершин. В силу того, как устроен алгоритм, итерации можно завершить после того, как вершина  добавляется в множество
добавляется в множество  .
.
Мы разобрались, как работает поиск кратчайших маршрутов между заданными точками. Далее в тексте будем называть такой «поисковик маршрутов» роутером. Можно считать, что роутер — это сервис, который умеет по паре точек отдавать кратчайший маршрут между ними, скрывая от пользователя детали реализации (алгоритм) и эксплуатации (дорожный граф).
Итого с помощью комбинации из k‑d-дерева и роутера мы научились искать ближайших к заказу исполнителей. Мы теперь умеем искать исполнителей, у которых время кратчайшего маршрута до точки А заказа не превышает заданного при поиске порога. Такой «поисковик по исполнителям» будет играть важную роль в нашем дальнейшем повествовании, поэтому давайте выделим его в отдельный сервис поиска исполнителей.
Конечно, на практике при построении сервиса поиска исполнителей возникает большое количество нюансов и невозможно охватить их все в рамках одной статьи. Поэтому в завершение этого раздела мы оставим читателю несколько упражнений для самостоятельного обдумывания.
Задачи со звёздочкой
Упражнение 1. На заказы нужно назначать только тех исполнителей, которые не заняты другим заказом. Допустим, что данные о занятости вам доступны. Как бы вы изменили структуру данных для хранения исполнителей? Как бы вы поменяли алгоритм поиска?
Упражнение 2. А что, если разрешать назначать не только свободных исполнителей, но и тех, которые скоро закончат имеющийся у них заказ? Какие данные вам потребуются для поиска исполнителей? Как изменится структура данных и алгоритм поиска?
Упражнение 3. Можно ли сделать поиск исполнителей более эффективным, избавившись от промежуточного этапа в виде k‑d-дерева? Не бойтесь нарушить инкапсуляцию и считайте, что вам доступен дорожный граф. Подсказка: вспомните, как работает алгоритм Дейкстры. В каких случаях такая оптимизация будет работать хорошо, а в каких — практически не приносить выигрыша?
Алгоритм: буферное назначение
Мы разобрались, как быстро искать ближайших к заказу исполнителей, но, поскольку при таком поиске мы рассматриваем заказы независимо, может возникнуть вот такая ситуация.
-
Появляется красный заказ, на который мы назначаем единственного ближайшего курьера. Время, за которое он доберётся до точки, — 4 минуты (240 секунд).

-
Курьер занят заказом, заказ назначен, поэтому они как бы «исчезают» из поля зрения алгоритма назначения, так как с ними ничего больше делать не нужно.

-
Спустя 5 секунд появляется новый заказ, и для него пока нет свободных курьеров.

-
Спустя ещё 5 секунд появляется свободный курьер, на которого мы назначаем заказ. На дорогу ему нужно 300 секунд.

В рассматриваемом примере время ожидания курьера для первого заказ составит 420 секунд, при том, что курьер нашёлся мгновенно, а для второго — 305 секунд (первые 5 секунд после создания заказа не было доступных курьеров, после чего появился курьер в 300 секундах от заказа).
А если бы мы подождали 10 секунд и собрали бы информацию обо всех доступных исполнителях и всех размещённых заказах в системе, то результат был бы значительно лучше. На первый заказ исполнитель бы приехал через 10 + 180 = 190 секунд, а на второй заказ — через 10 + 60 = 70 секунд.

С точки зрения продукта подождать те самые 10 секунд вполне оправданно — мы не обязаны находить исполнителя мгновенно, у нас есть некоторое время на оптимизацию. Давайте воспользуемся этим свойством и придумаем более эффективный алгоритм назначения.
Прежде всего, новый алгоритм должен работать с совокупностью. Значит, у нас должно быть какое‑то хранилище для заказов, на которые мы пока ещё не назначили исполнителей. Посчитаем размер множества неназначенных заказов. Вспомним оценки количества заказов — их примерно  , считаем, что это количество распределено по примерно 10 часам.
, считаем, что это количество распределено по примерно 10 часам.
Если допустить, что заказы примерно равномерно приходят и равномерно назначаются на исполнителей и что время от создания заказа до момента его назначения может составлять примерно 1/10 часа (6 минут), то в каждый момент времени в системе будет находиться ~ заказов.
заказов.
Организуем наш алгоритм так: будем периодически вычитывать всё множество неназначенных заказов из хранилища, пытаться назначать на них исполнителей, а всё, что не смогли назначить, — отправлять обратно в хранилище. Поскольку у нас есть довольно много времени на назначение заказа (несколько минут), мы можем позволить себе от 1 до 10 секунд на итерацию.
Как выглядит одна итерация? Кроме всех заказов, можно было бы подать на вход всех курьеров, а потом как‑то их назначить. Однако, как мы видели в предыдущем разделе, здесь скрывается множество подводных камней: например, каких курьеров мы можем считать доступными для назначения на конкретный заказ? Поэтому воспользуемся уже построенным «поисковиком исполнителей», который всю сложность задачи скрывает за довольно простым интерфейсом: он умеет для заказа возвращать исполнителей, которые подходят для назначения и смогут приехать к точке А не позже чем через заданное наперёд время t.

Время t мы будем дальше называть «радиусом поиска», а «время кратчайшего маршрута до точки А заказа» сократим до понятия «время подлёта». Подбор радиуса поиска — отдельная задача, пока будем считать, что этот радиус как‑то разумно выбран: например, он для всех заказов одинаков и равен 5 минутам. Заметим, что для разных заказов может найтись один и тот же курьер — как раз и нужно будет решить, на какой из заказов его назначить.

Как нам принять решение о том, какой вариант назначения лучше? Давайте сформулируем такие критерии:
-
Мы должны сделать максимально возможное количество назначений, причём нельзя назначать сразу два заказа на курьера или сразу двух курьеров на заказ.
-
Суммарный подлёт должен быть минимальным.
Для примера с прошлой картинки довольно легко выбрать оптимальный вариант назначения. Но что, если курьеров и заказов будет уже пять или десять?
Для начала представим задачу в форме графа. Вершинами графа будут курьеры и заказы, а рёбра мы будем проводить от заказа к найденным на него курьерам. Рёбра будут взвешенными, вес равен времени подлёта.

Мы получили граф специального вида: вершины в нём двух типов (курьеры и заказы), а рёбра существуют только между этими двумя типами (нет рёбер между парами курьеров или парами заказов). Такие графы называются двудольными.
Возьмём какое‑нибудь подмножество рёбер в этом графе. Если так вышло, что никакие рёбра в этом подмножестве не имеют общих вершин, то такое подмножество имеет специальное название — паросочетание. Поскольку мы рассматриваем взвешенные графы, то можем определить такую величину, как вес паросочетания — это сумма весов всех рёбер, входящих в паросочетание.
Далее представим множество всех возможных паросочетаний на заданном графе и отберём те, которые содержат наибольшее количество рёбер — они называются максимальными. Наконец, среди всех максимальных паросочетаний есть те, чей вес наименьший, — они называются максимальными паросочетаниями минимального веса.

С помощью определений из предыдущего абзаца мы теперь можем сформулировать задачу об оптимальных назначениях на математическом языке: на взвешенном двудольном графе найти максимальное паросочетание минимального веса. Эту задачу можно решить с помощью венгерского алгоритма.
Венгерский алгоритм
Здесь я опишу только ключевые идеи и «строительные блоки», лежащие в основе венгерского алгоритма. Более подробные описания можно найти по ссылкам в конце статьи.
Ограничимся частным случаем, когда число вершин в левой и правой долях совпадает и равно N, причём каждая вершина соединена со всеми вершинами в противоположной доле. Вот пример такого графа для N = 3:

Для графов такого вида максимальное паросочетание содержит N рёбер. Вот как выглядит максимальное паросочетание минимального веса на графе из примера выше:

Можно убедиться в корректности решения, перебрав все 3! = 6 вариантов паросочетаний.
В дальнейшем нам иногда будет удобнее представлять граф в виде матрицы:

На такой матрице оптимальное паросочетание выглядит так:

Наша стратегия будет состоять в том, чтобы свести задачу к поиску максимального паросочетания на невзвешенном графе. В свою очередь, задача поиска на невзвешенном графе решается алгоритмом Куна, который, по сути, является алгоритмом поиска в глубину.

Ключевая идея венгерского алгоритма состоит в следующем простом наблюдении: если для любой вершины графа поменять веса всех исходящих из неё рёбер на одну и ту же величину, то итоговое решение не изменится. Почему? Представьте себе все возможные максимальные паросочетания: каждое из них содержит ровно одно ребро, исходящее из заданной вершины. Значит, при таком преобразовании в каждом паросочетании суммарный вес изменится на одну и ту же величину, поэтому лучшее паросочетание останется тем же.
В нашем примере для каждой вершины из левой доли уменьшим все веса так, чтобы хотя бы одно ребро получило нулевой вес, а остальные веса были бы неотрицательными. В матричном представлении это означает, что мы из каждой строки матрицы вычитаем минимальное значение в этой строке:

Очевидно, что такую операцию можно проделать и над столбцами, причём поверх результатов предыдущих преобразований:

Чем полезна преобразованная таким образом матрица? Давайте построим алгоритмом Куна максимальное невзвешенное паросочетание только на рёбрах нулевого веса. Если окажется, что это паросочетание содержит N рёбер, то задача решена, ведь оно по построению имеет минимально возможный вес 0. Если же рёбер недостаточно, чтобы построить на них паросочетание нужной мощности N, то мы придумаем способ, как гарантированно добавить ещё как минимум одно ребро нулевого веса, и потом повторим процедуру. Рано или поздно мы наберём достаточно рёбер нулевого веса, чтобы построить на них паросочетание размера N.
Сначала продемонстрируем способ получения ребра нулевого веса на примере, а потом обобщим его.
Шаг 1. Выберем минимально возможное количество вершин (строк и столбцов) так, чтобы покрыть все нули в матрице. В нашем случае достаточно выбрать строку Order B и столбец Andrey.

Шаг 2. Для наглядности переставим строки матрицы и мысленно разобьём её на несколько подматриц A, B, C, D (они выделены цветами). Первые строки и последние столбцы — это вершины, которые мы выбрали для покрытия нулей на предыдущем шаге.

Шаг 3. Найдём минимальное значение в матрице B — оно равно 2.
Шаг 4. Прибавим 2 к подматрицам A и C (в нашем случае — к строке Order B).

Шаг 5. Вычтем 2 из подматриц A и B (в нашем случае — из столбцов Dmitrii, Sergei).

В результате такого преобразования мы получили 0 в одной из ячеек подматрицы B. При этом матрицу D мы вообще не трогали, поэтому все нули в ней сохранились, а в матрице A мы сперва увеличили все элементы на 2, а потом уменьшили на 2, поэтому в результате все нули тоже сохранились.
И главное: теперь нулей в этой матрице хватает, чтобы построить паросочетание размера 3 на рёбрах нулевого веса. Вы можете убедиться, что это паросочетание совпадает с тем, которое мы нашли на исходной матрице полным перебором.
Как же обобщить этот метод? Сперва введём обозначения: множество строк матрицы назовём  , множество столбцов —
, множество столбцов —  . Пусть есть некоторые подмножества
. Пусть есть некоторые подмножества  , которые разбивают матрицу на четыре непустые подматрицы
, которые разбивают матрицу на четыре непустые подматрицы  :
:

Пусть  . Тогда, если сперва прибавить
. Тогда, если сперва прибавить  к
к  и
и  , а потом вычесть
, а потом вычесть  из
из  и
и  , то получим такой результат:
, то получим такой результат:

Видно, что в подматрице  по построению появляется дополнительный 0, а подматрицы
по построению появляется дополнительный 0, а подматрицы  и
и  не меняются.
не меняются.
Алгоритм выбора подмножеств  приведём без деталей и без доказательства, чтобы не затягивать:
приведём без деталей и без доказательства, чтобы не затягивать:
-
Нужно на рёбрах нулевого найти минимальное вершинное покрытие (это как раз минимальное множество строк и столбцов, которое покрывает все нули матрицы). Это делается вариантом поиска в глубину поверх уже найденного максимального паросочетания на этих рёбрах. Найденные множества вершин в левой и правой доле обозначим
 .
. -

Теперь мы готовы к тому, чтобы собрать всё в единый алгоритм:
-
Вычитаем из каждой строки значение её минимального элемента.
-
Вычитаем из каждого столбца значение его минимального элемента.
-
Получаем подграф на рёбрах нулевого веса, ищем на нём максимальное паросочетание:
-
если оно содержит N рёбер, то эти рёбра и являются искомым паросочетанием, алгоритм закончен;
-
иначе применим операцию по добавлению ещё одного нуля и повторим шаг 3 ещё раз.
-
Можно показать, что полученный алгоритм имеет сложность  . Это довольно много, но всё равно лучше полного перебора. Можно организовать вычисления более эффективно и собрать из этих же идей и строительных блоков алгоритм сложности
. Это довольно много, но всё равно лучше полного перебора. Можно организовать вычисления более эффективно и собрать из этих же идей и строительных блоков алгоритм сложности  .
.
Практические свойства венгерского алгоритма
Венгерский алгоритм имеет кубическую сложность от числа вершин. Если вспомнить нашу предыдущую оценку числа заказов на итерации (~ ), то при возведении в третью степень мы получим порядка
), то при возведении в третью степень мы получим порядка  итераций венгерского алгоритма. При этом количество итераций можно значительно сократить.
итераций венгерского алгоритма. При этом количество итераций можно значительно сократить.
До этого мы оценивали общее количество заказов в системе, но сама система распадается на независимые городские агломерации. Например, нам не нужно рассматривать назначение заказа из Москвы на курьера из Саратова. То есть система горизонтально масштабируется по географии и минимальной единицей является городская агломерация. Если мы оценим самую крупную городскую агломерацию в 1/10 от всех заказов, то оценка количества итераций венгерского алгоритма сократится до  .
.
Венгерский алгоритм универсален: он умеет находить максимальное паросочетание минимального веса без каких‑либо ограничений на веса рёбер. Это значит, что мы можем выйти за рамки задачи «минимизировать суммарный подлёт» и решать сразу общую задачу «минимизировать суммарный вес назначений». Этот подход даёт значительную гибкость: по сути, мы можем при необходимости повышать приоритет одних назначений над другими, понижая вес более приоритетных рёбер в графе. Такая гибкость, в свою очередь, полезна как для экспериментов, так и для продуктовых фич.
Выше в качестве критерия оптимальности назначения мы сформулировали требование «сделать максимально возможное количество назначений». Важно, что здесь оптимальность достигается только в рамках одной итерации алгоритма, и из этого не следует «глобальная» оптимальность. Для примера давайте рассмотрим последовательность из нескольких итераций алгоритма:



Выглядит знакомо, правда? Это тот самый сценарий, который мы хотели исправить с помощью алгоритма буферного назначения. Но теперь мы уже почти у цели, нам осталось сделать последний шаг.
Глобальная неоптимальность возникает потому, что мы не знаем будущего. Нам неизвестно, какие курьеры и какие заказы появятся в системе в ближайшее время. Но допустим, что мы с какой‑то точностью всё же можем это будущее угадать. И тогда возникает вопрос: как нам этим воспользоваться, как заложить этот прогноз в алгоритм?
Снова воспользуемся универсальностью венгерского алгоритма. Мы имеем право не только модифицировать веса, но и добавлять какие угодно вершины и рёбра. Давайте для каждого заказа добавим «виртуального кандидата», то есть для каждой вершины из правой доли графа мы добавим соответствующую ей вершину в левой доле графа и соединим их ребром — вес этого ребра должен быть равен весу «достаточно хорошего» кандидата для заказа.
На примере выше посмотрим, как добавление «виртуального кандидата» меняет глобальное решение:

Конечно, глобальное качество полученного алгоритма драматически зависит от того, какие веса мы приписываем виртуальным кандидатам, и в частности — насколько хорошо мы прогнозируем будущее состояние системы. Это сложная и интересная исследовательская задача, но в рамках этой статьи мы не будем её касаться.
Полезные ссылки
Про k‑d-дерево:
-
Multidimensional Binary Search Trees Used for Associative Searching
-
Курс CMSC Advanced Data Structures. Особенно рекомендую главы Point quadtrees and kd‑trees и Answering Queries with kd‑trees
Про алгоритм Дейкстры:
Про венгерский алгоритм:
Резюме
Итак, мы рассмотрели два алгоритма поиска и назначения курьеров: поиска ближайшего исполнителя и буферного назначения.
Алгоритм поиска ближайшего исполнителя помогает найти курьера, который ближе всего к заказу. Для этого нам нужно знать местоположение каждого курьера, а значит, обрабатывать десятки тысяч обновлений в секунду. Для эффективного поиска мы используем k‑d-дерево, реализованное в библиотеке nanoflann. В рамках алгоритма поиска ближайшего исполнителя разобрали и алгоритм Дейкстры, который помогает найти кратчайшие расстояния от заданной вершины до всех остальных вершин во взвешенном ориентированном графе с неотрицательными весами.
Алгоритм буферного назначения помогает рассматривать заказы не по отдельности, а совместно и оптимизировать время доставки. Разобрали условия, при которых он подойдёт лучше, чем первый, и сформулировали задачу об оптимальных назначениях на математическом языке, которую решили с помощью венгерского алгоритма.
Но это не все алгоритмы, которые мы используем в работе Доставки: есть и множество других, например алгоритмы объединения нескольких заказов в один маршрут. Но думаю, что это тема для других статей — а пока жду вопросов по разобранным алгоритмам в комментариях.
ссылка на оригинал статьи https://habr.com/ru/articles/887484/
Добавить комментарий