Команда Spring АйО перевела и адаптировала доклад Томаса Витале “Concerto for Java and AI — Building Production-Ready LLM Applications”, в котором рассказывается по шагам, как усовершенствовать интерфейс приложения с помощью больших языковых моделей (LLM). В качестве примера автор доклада на глазах слушателей разрабатывает приложение-ассистент для композитора, пишущего музыку для фильмов.
В первой части рассказывалось о том, какие подходы автор доклада применил к стоящей перед ним проблеме. Также было показано начало работы над усовершенствованием интерфейса программы-помощника с использованием ИИ. Во второй части будет продолжен рассказ о том, как еще больше улучшить программу. Но сначала поговорим о безопасности.
Риски по безопасности в LLM (1)
OWASP: топ 10 рисков для LLM
Если говорить о проблемах с безопасностью, которые возникают при работе с ИИ, то о prompt injection уже говорилось в первой части. OWASP уже публиковал список из 10 наиболее серьезных рисков по безопасности для веб приложений и теперь они сделали подобную выборку также и для больших языковых моделей. Первый риск — инжекция промпта (prompt injection), мы это видели, это может быть атака через инжекцию промпта напрямую, как было показано в первой части, или не напрямую.
Мы часто используем LLM для обработки различных типов данных. Помимо прочего, эти данные могут использоваться для создания веб-страниц методом веб-скрейпинга. Теоретически можно провести атаку, спрятав данные для инжекции промпта в одной из этих веб-страниц. Как только модель распарсит все данные, она произведет какие-то нежелательные действия, например, добавление новых привилегий, поэтому на это действительно необходимо обратить внимание.
Другая угроза — это раскрытие чувствительной информации. Если мы используем облачный сервис, мы должны быть уверены, что мы делимся только теми данными, которыми разрешено делиться. Если у вас есть какие-то данные, относящиеся к бизнесу, чувствительные данные, персональные данные, вы можете оказаться в рискованной ситуации, если предоставите такие данные облачному сервису, ведь вы не знаете, использует ли этот сервис предоставленные данные для обучения модели. Если это так, ваши данные может получить следующий человек, который будет использовать сервис. И это не гипотетическая ситуация, такие вещи реально происходили, даже при работе с самыми популярными и, казалось бы, надежными моделями.
А еще есть вероятность получить Model Denial of Service (MDOS) атаку. Конечно, проблема с подключением к модели может быть вызвана неочищенным кешем, но может быть и другая причина: злонамеренный хакер может послать столько запросов через ваше приложение, что у модели закончатся ресурсы. Поэтому нам необходимо защищаться подобной ситуации, принимая во внимание устойчивость приложения. Ничего нового тут нет, такие защиты реализуются каждый раз, когда появляется точка интеграции с другой системой.
Решение проблем безопасности является частью общего процесса подготовки приложения к выходу в продакшен. Что мы можем сделать, чтобы сделать интеграцию с этими моделями более устойчивой? Прежде всего, мы можем включить виртуальные потоки, для чего нам потребуется Java версии 21 и выше.
spring: threads: virtual: enabled: trueЭто очень важная операция, поскольку мы не хотим напрасно растрачивать платформенные потоки на то, чтобы они просто ожидали, пока модель вернет данные.
Следующий важный момент — механизм retry, который вы можете сконфигурировать через конфигурационные свойства, его нам предоставляет Spring AI.
spring: ai: retry: max-attempts: 5 backoff: multiplier: 5Очень удобно, поскольку вы также можете сконфигурировать:
-
Когда именно вы хотите его вызвать и по какому запросу.
-
Каков код запроса, для которого вы хотите это использовать.
-
На какое именно исключение вы хотите отреагировать таким образом.
Для тех случаев, когда сервис не отвечает или ответ занимает слишком много времени, можно использовать что-то вроде Resilience4J:
@CircuitBreaker @RateLimiter @TimeLimiter public Type classify(String textToClassify) { return chatClient.prompt() .user(textToClassify) .call() .entity(Type.class); }Это решение уже интегрировано в Spring портфолио, например в Spring Cloud проект Circuit Breaker, который базируется на Resilience4J. Мы можем использовать подход, основанный на аннотациях, когда мы вызываем модельный сервис, затем задаем некие ограничения по времени или даже лимитаторы по рейту, если мы платим за использование сервиса и нас беспокоит, что мы слишком много платим за такие простои.
Другие варианты решения проблемы — автоматически переключиться на другой сервис или просто попросить пользователя повторить попытку позднее, чтобы не перегружать бекенд систему.
Observability
Дальше нам потребуется observability. Если говорить более конкретно, распределенное отслеживание. Это, возможно, один из наиболее важных факторов, который надо обеспечить, прежде чем идти в продакшен. Как и для любого приложения, нам нужна стандартная RED телеметрия (Request Rate, Errors, Duration — Рейт запросов, Ошибки, Продолжительность). Третья составляющая — продолжительность — особенно важна, потому что при работе с LLM моделями мы получаем совершенно особенный тип latency, отличающийся от того, с чем мы имеем дело в других привычных нам интеграциях.
Для LLM нам нужно нечто большее, чем стандартные метрики. Нам надо внимательно посмотреть на использования токенов, особенно если мы платим за каждый токен. Токен составляет примерно 75% стоимости, и чем больше текста мы доставляем в модель и генерируем обратно, тем больше мы платим, и это имеет отношение также к Context Window. Это определяет максимальное количество токенов, которое мы можем использовать для той или иной модели.
Ну и наконец, содержимое самого промпта. Мы, как правило, совершаем локальные итерации, работая над содержимым промпта, поэтому нам хотелось бы получить лучший способ отслеживать все промпты, чтобы в конце концов получить оптимальный.
Для первой части упомянутых здесь потребностей решение уже существует в виде Micrometer и инфраструктуры observability, потому что под капотом Spring AI использует RestClient и WebClient из Spring, но нам по-прежнему не хватает решения, касающегося использования токенов и содержимого промпта. Эти возможности придется добавить в приложение вручную, хотя наверняка в будущем это будет поставляться Spring AI из коробки. Но это означает, что мы можем реально посмотреть на то, что происходит со всеми этими запросами, так что я публикую все как открытые данные телеметрии в сервис Grafana:

Выберем наше приложение и посмотрим, что происходит в последние 15 минут. В выпадающем списке Span Name выберем springai chat, чтобы получить дополнительную информацию о функциях чата Spring AI:

Теперь вы видите, что мы начинаем с POST запроса к приложению:

Сервис принимает запрос, затем мы переходим к той части, которая соответствует Spring AI чату:
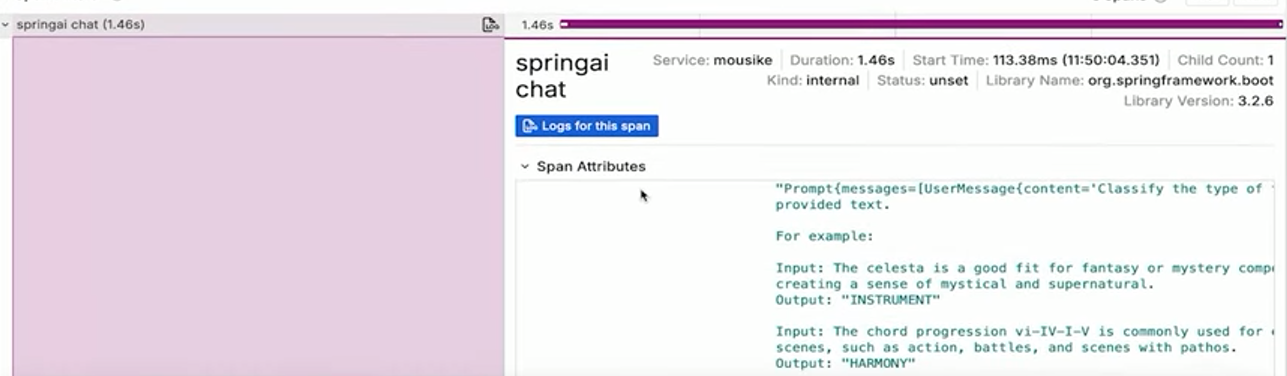
Здесь можно увидеть полный промпт со всеми примерами (если проскроллить вниз в окошке справа), а также некоторые дополнительные данные от Spring AI.
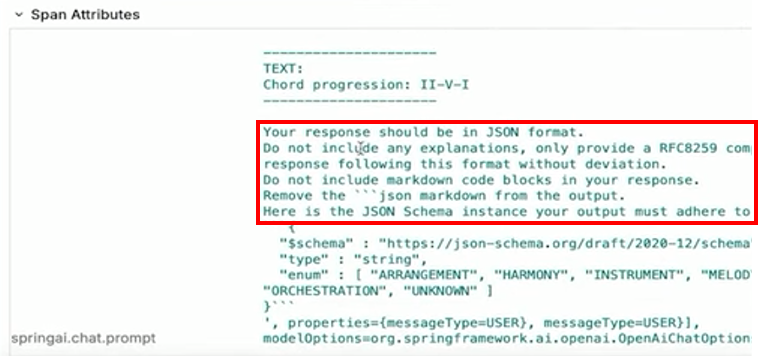
В частности, здесь написано: “Ваш ответ должен быть в формате JSON. Не включайте объяснение, предоставьте объект в соответствии с форматом JSON.”
Такое автоматическое предоставление схемы работает из любого Java класса. Это действительно очень удобно.
Кроме того, можно посмотреть и на токены:

Приведенные здесь числа могут помочь нам вычислить, сколько мы должны заплатить Open AI за использование их модели.
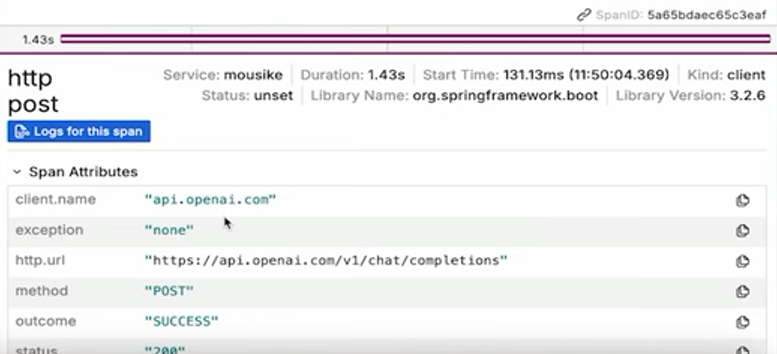
Можно также проверить актуальный вызов Spring AI тут, выполненный RestClient из Spring под капотом.
Опыт разработчика
Итак, мы поговорили о том, что необходимо для выхода в продакшен, что соответствует второму принципу из WHY фактора, но теперь пришло время поговорить о третьем факторе, об опыте разработчика, с учетом всех проблем, которые мы только что увидели. Как с ними работать? Нужен ли нам аккаунт на каким-нибудь облачном сервисе? На самом деле он нам не нужен, потому что мы используем локальные тест-контейнеры, а для них Spring Boot уже предоставил все необходимые интеграции для сервисов разработки.
Когда мы выбираем тест-контейнеры для Postgres или, например, RabbitMQ, мы получаем и сервисы разработки для соответствующих платформ, позволяющие тестировать приложение локально. Spring AI поддерживает все эти тест-контейнеры, но помимо их мы можем также выбрать Ollama. Ollama — это прекрасный инструмент для тех, кто работает в сильно зарегулированной индустрии и хочет хранить всю чувствительную информацию локально.
Ollama можно запускать как нативное приложение как macOS, Linux, и также недавно они добавили поддержку Windows. Наше приложение пока не использует тест-контейнеры, но на них можно переключиться и получить OllamaContainer.
//@Bean @RestartScope @ServiceConnection OllamaContainer ollama() { return new OllamaContainer(DockerImageName.parse("ghcr.io/thomasvitale/ollama-llama3")) .asCompatibleSubstituteFor("ollama/ollama"); } public static void main(String[] args) { SpringApplication.from(OdaiApplication::main).with(TestOdaiApplication.class).run(args); }Это официальный модуль из проекта Test Containers. У проекта Test Containers имеются подобные официальные модули не только для Ollama, но также для многих других сервисов, используемых для этих API.
Мы же вместо этого воспользуемся PG Vector.
@Bean @RestartScope @ServiceConnection PostgreSQLContainer<?> pgvectorContainer() { return new PostgreSQLContainer<>(DockerImageName.parse("pgvector/pgvector:pg16")); }Это контейнер PostgreSQL в той версии, которую мы можем использовать с приложениями, для чего не требуется ни подписка, ни отправка персональных данных третьей стороне. Модель можно запускать локально или в облаке Test Containers, но для нашего примера будет использована вторая опция, чтобы контейнеры не занимали лишние ресурсы на локальном компьютере.
Интеллектуальный поиск по данным
Проблема с классификацией решена, но данных со временем будет много, и как мы сможем организовать эффективный поиск среди многочисленных композиторских заметок? Допустим, композитору для работы необходимо найти все музыкальные инструменты, которые хорошо передают идею сцены боя. Он вводит поисковый термин battle scenes, но оказывается, что в заметке написано fight scenes, что по сути синоним, но поиск по точному совпадению ничего не даст.

Возникает необходимость использования больших языковых моделей для настройки семантического поиска. Тогда поиск будет базироваться на значении слов, а не на точном их совпадении. Для внедрения такого поиска необходима модель с эмбеддингами, то есть модель, которая производит конвертацию текста в числовые векторы. Эти векторы и представляют значения слов.
У нас есть все необходимые интеграции в Spring AI для работы с такими моделями. Например, можно выбрать Weaviate, векторную базу данных, которая специализируется на хранении только векторов.

Другая опция — использовать Chroma, это другая векторная база данных, которая является open source. Но когда приложение уже использует PostgreSQL, решение использовать ту же платформу и для хранения векторов напрашивается само собой, ведь все конфигурации и настройки уже готовы.
Так в проекте появляется новая абстракция, vectorStore (хранилище векторов).
Теперь, когда мы классифицируем объект, используя наш классификационный сервис, разработанный ранее, необходимо сделать две вещи. Во-первых, сохранить заметку о классификации в базу данных. Во-вторых, воспользоваться Spring Data JDBC.
public CompositionNote save(CompositionNote compositionNote) { var savedCompositionNote = compositionNoteRepository.save(compositionNote); vectorStore.add(List.of(new Document(savedCompositionNote.getId().toString(), savedCompositionNote.getType() + ". " + savedCompositionNote.getContent(), Map.of("type", savedCompositionNote.getType().toString()) ))); return savedCompositionNote; }Здесь мы используем PostgreSQL для хранения данных и Flyway для генерации схемы, например, для заметок композитора используется следующий запрос:
CREATE TABLE COMPOSITION_NOTE ( id UUID DEFAULT uuid_generate_v4() PRIMARY KEY, type VARCHAR(255) NOT NULL, content TEXT NOT NULL );Эти данные уже есть в проекте, но теперь нам надо добавить вторую таблицу, чтобы каждый раз при сохранении заметки сохранять также и ее векторное представление. Поэтому в коде добавляется второй шаг, где из хранилища векторов добавляется список документов. Документ — это абстракция, которая предоставляется в Spring AI, чтобы работать с этим типом данных и преобразовывать их в векторы. Другое популярное название для этой абстракции — эмбеддинг.
vectorStore.add(List.of(new Document(savedCompositionNote.getId().toString(), savedCompositionNote.getType() + ". " + savedCompositionNote.getContent(), Map.of("type", savedCompositionNote.getType().toString()) ))); return savedCompositionNote; Теперь можно делать семантический поиск. И как это работает? Хранилище векторов используется как механизм поиска на семантическое сходство, отправляется соответствующий запрос и модель присылает обратно все заметки, так или иначе относящиеся к значению запроса.
public List<CompositionNote> semanticSearch(String query) { var similarDocuments = vectorStore.similaritySearch( SearchRequest.query(query).withTopK(3) ); return compositionNoteRepository.findAllById(similarDocuments.stream() .map(Document::getId) .map(UUID::fromString) .toList()); }Знак волшебной палочки на этом пункте меню уже присутствует, поэтому разрешается добавлять сюда больше ИИ-возможностей, ничего не меняя в графическом интерфейсе меню. Необходимо просто добавить семантический поиск в соответствующий экран.
pageLayout.add(buildSemanticSearch());
После перезагрузки приложения можно выполнять поиск. Поскольку это не стандартный поиск по ключевому слову, а семантический поиск, мы ожидаем, что при поиске по слову “battle” будет найдена заметка, упоминающая “fight scene”, а также все другие заметки, имеющие семантическое отношение к военным сценам.

Что мы получили? У нас есть “последовательность аккордов для эпичных, экшн или драматических сцен”. “Перкуссии… довольно хорошо подходят для сцен экшн или битв”, и у нас также есть еще один инструмент, про который сказано, что он подходит для “экшн и героизма”. Неплохо.
Представим себе другие сценарии использования данной возможности, относящиеся к здравоохранению или к страховке. Можно сделать очень много полезных вещей, особенно если подключить Retrieval Augmented Generation. Разработав некоторые дополнительные надстройки над уже реализованной функциональностью, мы также можем получить модель, напрямую отвечающую на наши вопросы на основании введенных данных.
Попробуем подтянуть Retrieval Augmented Generation. Соответствующие методы уже имеются в проекте, поэтому надо лишь заменить один вызов метода на другой:
//pageLayout.add(buildSemanticSearch()); pageLayout.add(buildRag());Под капотом извлечение всех релевантных документов по-прежнему выполняется, но документы больше не будут возвращаться нам напрямую, вместо этого они передаются в LLM, в данном случае Open AI, и затем она использует эту информацию, чтобы ответить на заданный вопрос.
Попробуем ввести “instrument for battle scene”. Отработает процесс Retrieval Augmented Generation, и модель выдаст следующий ответ.

Здесь снова упоминаются перкуссии и медные инструменты, как и ранее, но ответ облекается в форму связного текста на человеческом языке, а в конце модель добавляет от себя: “В целом ваш подход кажется весьма подходящим для создания драматической атмосферы.” И это прекрасно!
Автоматизированная структуризация данных
Это был очень простой пример. Теперь представьте, что вам надо сделать какой-то отчет о страховке. Или вы идете к доктору, и вам надо заполнить очень большую форму с большим количеством различной информации о вашем состоянии здоровья. Разве не было бы хорошо, если бы вместо заполнения всех этих форм самому, мы могли заставить модель структурировать информацию за нас, если мы предоставим ее в виде сплошного текста?
Возвращаясь к работе композитора, когда он работает над сценой в фильме, он, как правило, очень много разговаривает с режиссером, который дает ему многочисленные инструкции по той или иной сцене, к которой надо написать музыку. Эти инструкции, будучи введенными в приложение, включают название фильма, описание сцены и набор временных отметок, таких как начало сцены, момент нарастания напряжения и затем, скажем, через 30 секунд, появление злодея, здесь требуется звук медных инструментов.

Но режиссер подает композитору всю эту информацию как свободный поток текста, и композитору не хочется тратить много времени на вставку различных элементов этих данных в ячейки формы. Поэтому есть смысл еще больше усовершенствовать приложение, модель сама структурировала эти заметки, используя примерно тот же подход, который использовался для классификации, но применяя его ко всему объекты в Java.
Пришло время украсить волшебной палочкой и второй пункт меню, “Заметки режиссера”, иначе. Как мы помним, не считается. Давайте это сделаем.

Теперь у нас есть “Режиссерские заметки” в новом интерфейсе.

Здесь можно ввести всю информацию как простой текст либо просто загрузить запись беседы голосом как файл в формате .mp3 и снова использовать Spring AI. Здесь будет применен другой клиент, который напишет транскрипт всей беседы.

Пользователь может подредактировать текст по своему желанию, и затем сохранить его, когда текст полностью его устроит.
Это очень полезная функциональность, которая может помочь во многих различных ситуациях. Spring AI предоставляет три различные абстракции для ввода данных в приложение (data ingestion), в частности, считыватель документов (document reader) для считывание данных с любого источника. Вы можете использовать, например, PDF файл или веб страницу. Чтобы затем подготовить данные к сохранению, можно использовать, например, JobRunr, который очень хорошо интегрирован со Spring, это очень хорошая библиотека.
@Job(name = "Data Ingestion Pipeline") @Recurring(id = "data-ingestion", cron = "*/5 * * * * *") public void runDataIngestion() { ... }Здесь задается джоба, которая периодически принимает все поступающие данные и загружает их в векторную базу данных, это решение можно интегрировать с библиотеками Spring Cloud, такими как Spring Cloud Stream и Spring Cloud Function; нам пригодятся также Spring Batch и Spring Integration:

Ну и последнее.
Галлюцинации

Именно так. Галлюцинации — это один из тех терминов, которые были введены для необычного и эффектного звучания. Сам Томас Витале предпочел бы переименовать этот термин в RFBD, что расшифровывается как Randomly Failing By Design — случайные ошибки, введенные преднамеренно. Большие языковые модели иногда случайно ошибаются, потому что они так устроены. Именно поэтому нам приходится делать всю эту работу. LLM не являются детерминированными, они базируются на вероятностях. Они лишь предсказывают, какой вывод необходимо предоставить.
Мы должны по-настоящему хорошо представлять себе, что мы делаем, как мы выстраиваем наши промпты. Неправильно построенный промпт может привести к получению совсем не тех результатов, которых мы ожидаем.
Контейнеризация
Теперь поговорим о более приземленных вещах. Как только мы добираемся до продакшен, мы хотим использовать тот же механизм, к которому мы привыкли уже в Spring Boot, а именно Cloud Native Buildpacks, для процесса контейнеризации, либо мы можем использовать GraalVM. Spring AI предоставляет поддержку GraalVM из коробки. И затем, если мы работаем на Kubernetes, мы можем положиться на его возможности по service bindings. Добавляем следующую зависимость в приложение:
dependencies { implementation 'org.springframework.ai:spring-ai-spring-cloud-bindings' }После этого команда платформы, которая управляет Kubernetes, может добавить следующие binding декларации:
apiVersion: servicebinding.io/v1beta1 kind: ServiceBinding spec: service: apiVersion: v1 kind: Secret name: ollama workload: apiVersion: serving.knative.dev/v1 kind: Service name: spring-ai-applicationВ этом коже содержится инструкция по поводу привязки сервиса Ollama к приложению на Spring AI. И этого достаточно, со стороны приложения конфигурировать ничего не надо.
Комментарий редакции Spring АйО
Остаток доклада посвящен практической демонстрации работы с новым приложением и созданию короткого музыкального трека на основании предварительно сохраненных заметок. Вы можете посмотреть эту презентацию в оригинальном видео: https://www.youtube.com/watch?v=3zTf8NxF-6o, начиная примерно с 46-минутной временной отметки.
На этом заканчивается цикл из двух статей по докладу Томаса Витале “Concerto for Java and AI — Building Production-Ready LLM Applications”, благодаря которому мы узнали, как эффективно использовать ИИ для внесения различных усовершенствований в интерфейсы пользовательских приложений, как подготовить такие приложения к продакшен и какие проблемы придется решать в процессе такой работы, чтобы не столкнуться с прорехами в безопасности или другими неприятными сюрпризами.

Присоединяйтесь к русскоязычному сообществу разработчиков на Spring Boot в телеграм — Spring АйО, чтобы быть в курсе последних новостей из мира разработки на Spring Boot и всего, что с ним связано.
ссылка на оригинал статьи https://habr.com/ru/articles/893052/
Добавить комментарий