Процессор Intel 8086 был представлен в 1978 году и во многом определил развитие современной вычислительной техники. Хотя семейство процессоров x86 уже десятилетиями поддерживает 64-битную обработку, исходный 8086 был 16-битным процессором. Соответственно, он оснащён 16-битным арифметико-логическим устройством (АЛУ).[примеч.¹] АЛУ — это «сердце» процессора: оно выполняет арифметические операции, такие как сложение и вычитание. Кроме того, оно реализует логические операции булевой алгебры, такие как побитовое AND и OR, а также побитовые сдвиги и циклические сдвиги. Поскольку быстродействие АЛУ критично для общей производительности процессора, в их конструкции часто применяются нетривиальные инженерные приёмы.
На приведённой ниже фотографии показан кремниевый кристалл процессора 8086. АЛУ расположено в левом нижнем углу. Над ним находятся регистры общего и специального назначения. В левом верхнем углу расположен сумматор, используемый для вычисления адресов. (Для повышения производительности в 8086 используется отдельный сумматор для сложения сегментного регистра и смещения в памяти при обращении к памяти.) Большое ПЗУ микрокода расположено в правом нижнем углу.

{kind=link}
При увеличении области АЛУ видно, что оно состоит из 16 почти идентичных каскадов — по одному на каждый бит. Верхний ряд обрабатывает биты с 7 по 0, а нижний — с 15 по 8.(примеч.³) Между ними расположена логика флагов, которая отражает состояние арифметической операции с помощью кодов условий: ноль или не ноль, положительное или отрицательное значение, перенос, переполнение, чётность и т. д. Эти флаги обычно используются для условных переходов.
В этой статье я выполняю реверс-инжиниринг АЛУ процессора 8086 и объясняю, как оно устроено. Оно сложнее, чем другие винтажные АЛУ, которые я изучал,(примеч.²) поскольку использует гибкую схему, способную реализовывать произвольные побитовые функции. Механизм переноса реализован с помощью Манчестерской цепочки переноса (Manchester carry chain) — быстрого решения, появившегося ещё в суперкомпьютерах 1960-х годов.
Схемотехника АЛУ
Схема АЛУ процессора 8086 устроена довольно нетривиально, поэтому начнём с объяснения того, как выполняется сложение двух чисел. Если вы изучали цифровую логику, вам, вероятно, знаком полный сумматор — базовый элемент для сложения двоичных чисел. Полный сумматор принимает два бита и входной перенос. Он складывает эти три значения и формирует на выходе однобитную сумму, а также бит переноса на выходе. (Например, 1+0+1 = 10 в двоичной системе, поэтому перенос равен 1, а бит суммы — 0.) 16-битный сумматор можно построить, объединив 16 полных сумматоров, где выходной перенос каждого подаётся на вход переноса следующего.
На упрощённой схеме ниже показан один каскад сумматора АЛУ. Он принимает два входных значения и входной перенос, складывает их и формирует однобитный результат и выходной перенос. (Обратите внимание, что сигнал переноса распространяется справа налево.) Бит суммы формируется с помощью операции исключающего ИЛИ (XOR) двух аргументов и входного переноса — для этого используются два элемента XOR в нижней части схемы. Однако формирование переноса устроено значительно сложнее.

Вычисление переноса использует оптимизацию, называемую Манчестерской цепочкой переноса(примеч.⁴), разработанную ещё в 1959 году, чтобы избежать задержек при последовательном распространении переноса от одного каскада к другому. Идея заключается в том, чтобы параллельно определить, будет ли каждый каскад генерировать перенос, пропускать входящий перенос или блокировать его. После этого перенос может быстро распространяться по «цепочке переноса» без последовательных вычислений.
Чтобы понять это, рассмотрим случаи сложения двух битов и входного переноса. При сложении 0+0 выходного переноса не будет независимо от входного переноса. В случае 1+1 перенос всегда возникает независимо от входного — этот случай называется генерацией переноса. Наиболее интересны случаи 0+1 и 1+0: выходной перенос появится только если был входной перенос. Это называется распространением переноса, поскольку входной перенос проходит через каскад без изменений.
В Манчестерской цепочке переноса сигнал распространения переноса управляет открытием и закрытием транзисторов в линии переноса. В случае распространения переноса активируется верхний транзистор, соединяя вход переноса с выходом, благодаря чему перенос свободно проходит через каскад. В противном случае активируется нижний транзистор, и на выход переноса подаётся сигнал генерации переноса, который формирует перенос, если оба входных бита равны 1. Поскольку все эти транзисторы могут настраиваться параллельно, вычисление переноса происходит быстро. Некоторая задержка всё же остаётся — она связана с прохождением сигнала переноса через транзисторы цепочки — но это значительно быстрее, чем вычислять перенос последовательно через цепочку логических элементов.(примеч.⁵)
Это объясняет, как АЛУ выполняет сложение,(примеч.⁶) но как насчёт логических операций? Как реализуются AND, OR или XOR? Представим, что элемент исключающего ИЛИ (XOR) в блоке распространения переноса заменён на другой логический элемент (AND, OR или XOR), а блок генерации переноса принудительно выдаёт 0, как показано ниже. В этом случае на выходе получится просто результат операции AND (или OR, или XOR) над двумя входами — в зависимости от выбранного элемента. (Правый элемент XOR в этой схеме не влияет на результат, поскольку XOR с 0 пропускает значение без изменений.) Суть в том, что если бы можно было «переключать» логические элементы, одна и та же схема могла бы выполнять как логические операции AND, OR, XOR, так и сложение.
 заменяется на другой логический элемент, а генерация переноса блокируется.")
Ещё одна важная операция — побитовый сдвиг. АЛУ выполняет сдвиг влево, используя линию переноса необычным образом (см. ниже).(примеч.⁷) Бит первого аргумента направляется на выход переноса, тем самым сдвигаясь на одну позицию влево. Полученный бит переноса проходит через элемент XOR, что в итоге даёт сдвиг влево на один бит. Сигнал распространения переноса устанавливается в 0 — это одновременно направляет бит аргумента на выход переноса и превращает элемент XOR в «прозрачный» проход (без изменения значения). (Сдвиг вправо реализуется отдельной схемой, как будет показано далее.)

Таким образом, АЛУ может использовать одну и ту же схему для выполнения различных операций, «перепрограммируя» блоки распространения и генерации переноса на разные функции. Но как реализованы эти «магические» перенастраиваемые элементы? Ключевая идея состоит в том, что любую булеву функцию двух переменных можно задать четырьмя значениями в таблице истинности. Например, операция AND имеет следующую таблицу истинности и, соответственно, может быть задана четырьмя значениями: 0, 0, 0, 1:
|
A |
B |
A |
|---|---|---|
|
0 |
0 |
0 |
|
0 |
1 |
0 |
|
1 |
0 |
0 |
|
1 |
1 |
1 |
Если подать эти значения на мультиплексор и выбирать нужное значение в зависимости от двух входов, на выходе получится операция AND. Если же подать значения 0, 1, 1, 0, на выходе получится XOR. Аналогичным образом можно реализовать и другие логические функции. При соответствующем наборе значений можно реализовать любую логическую функцию двух переменных.(примеч.⁸) (Некоторые частные случаи: 0, 0, 0, 0 даст на выходе константу 0; 0, 0, 1, 1 — просто повторит значение входа A.) Эта схема на основе мультиплексора используется для блока распространения переноса. Для блока генерации переноса применяется аналогичная, но упрощённая схема.(примеч.⁹)

Теперь, когда разобраны основные принципы, ниже показана полная схема АЛУ, где вместо блоков распространения и генерации переноса используются мультиплексоры. На кристалле сигналы входного и выходного переноса инвертированы, и это отражено на схеме. Также показано подключение АЛУ к шине, через которую передаётся результат вычислений. Схема в нижней части поддерживает операцию сдвига вправо, которая не вписывается в общую архитектуру АЛУ. В рамках этой статьи я не буду рассматривать, как формируются управляющие сигналы.(примеч.¹⁰)

Реализация АЛУ в кремнии
Процессор 8086 и другие процессоры того времени строились на транзисторах типа NMOS. Кремниевая подложка подвергалась легированию путём диффузии мышьяка или бора, чтобы сформировать проводящие области и сами транзисторы. Поверх кремния располагались соединения из поликремния, которые образовывали затворы транзисторов и связывали элементы между собой. Наконец, сверху добавлялся металлический слой для дополнительной разводки. (Для сравнения, современные процессоры строятся на технологии CMOS, объединяющей NMOS- и PMOS-транзисторы, и используют множество слоёв металлической разводки).
, реализованного в интегральной схеме.")
На схеме выше показано устройство NMOS-транзистора. Транзистор можно рассматривать как переключатель, позволяющий току течь между двумя диффузионными областями, называемыми истоком и стоком. Управление транзистором осуществляется через затвор, выполненный из особого вида кремния — поликремния. Высокое напряжение на затворе позволяет току протекать между истоком и стоком, а низкое — блокирует ток.
Самый простой логический элемент — инвертор; на схеме ниже показано, как он реализуется с помощью NMOS-транзистора и резистора.(примеч.¹¹) Розоватые области — это легированный кремний, а коричневые линии — поликремниевые соединения поверх него. Транзистор формируется в месте пересечения поликремниевой линии с легированным кремнием. При низком входном сигнале транзистор закрыт, поэтому подтягивающий (pull-up) резистор устанавливает высокий уровень на выходе. При высоком входном сигнале транзистор открывается, соединяя выход с землёй и тем самым устанавливая низкий уровень. Таким образом, входной сигнал инвертируется.

Более сложный элемент, например двухвходовый элемент NOR, показанный ниже, использует те же принципы. При низких входах транзисторы закрыты, и подтягивающий резистор устанавливает высокий уровень на выходе. Если хотя бы один вход становится высоким, соответствующий транзистор открывается и тянет выход к земле. Таким образом, эта схема реализует логическую операцию NOR. Топология на кристалле соответствует принципиальной схеме, но выглядит сложнее из-за оптимизаций, направленных на экономию площади. Можно было бы ожидать, что транзисторы имеют простую прямоугольную форму, однако области кремния имеют неправильные очертания, чтобы максимально эффективно использовать пространство. Кроме того, некоторые транзисторы (не относящиеся к данному элементу NOR) используют общие соединения с землёй, что также позволяет сэкономить место.

Мультиплексоры реализованы с использованием совершенно иного подхода — на основе проходных транзисторов. Вместо того чтобы подтягивать выход к земле, такие транзисторы пропускают входной сигнал напрямую на выход. В мультиплексоре каждый вход подключён к своей паре транзисторов. В зависимости от значений аргументов ровно одна пара оказывается полностью открытой. Например, если arg2 равен 0, а arg1 равен 1, то пара транзисторов в верхнем левом углу соединит сигнал ctl01 с выходом. Все остальные входы будут заблокированы закрытыми транзисторами. Таким образом, мультиплексор выбирает один из четырёх входов и передаёт его на выход. (Подход с проходными транзисторами более компактен, чем реализация мультиплексора на стандартных логических элементах.)

На схеме ниже показан один каскад АЛУ с обозначенными основными компонентами. Можно увидеть инвертор, элемент NOR и мультиплексор, описанные ранее. Остальные элементы реализованы аналогичными методами. Эту схему можно сопоставить с ранее приведённой принципиальной схемой. Красноватые горизонтальные линии — это остатки металлического слоя, который был удалён для получения данного изображения. По этим линиям передавались управляющие сигналы, питание и земля.

Временные регистры АЛУ
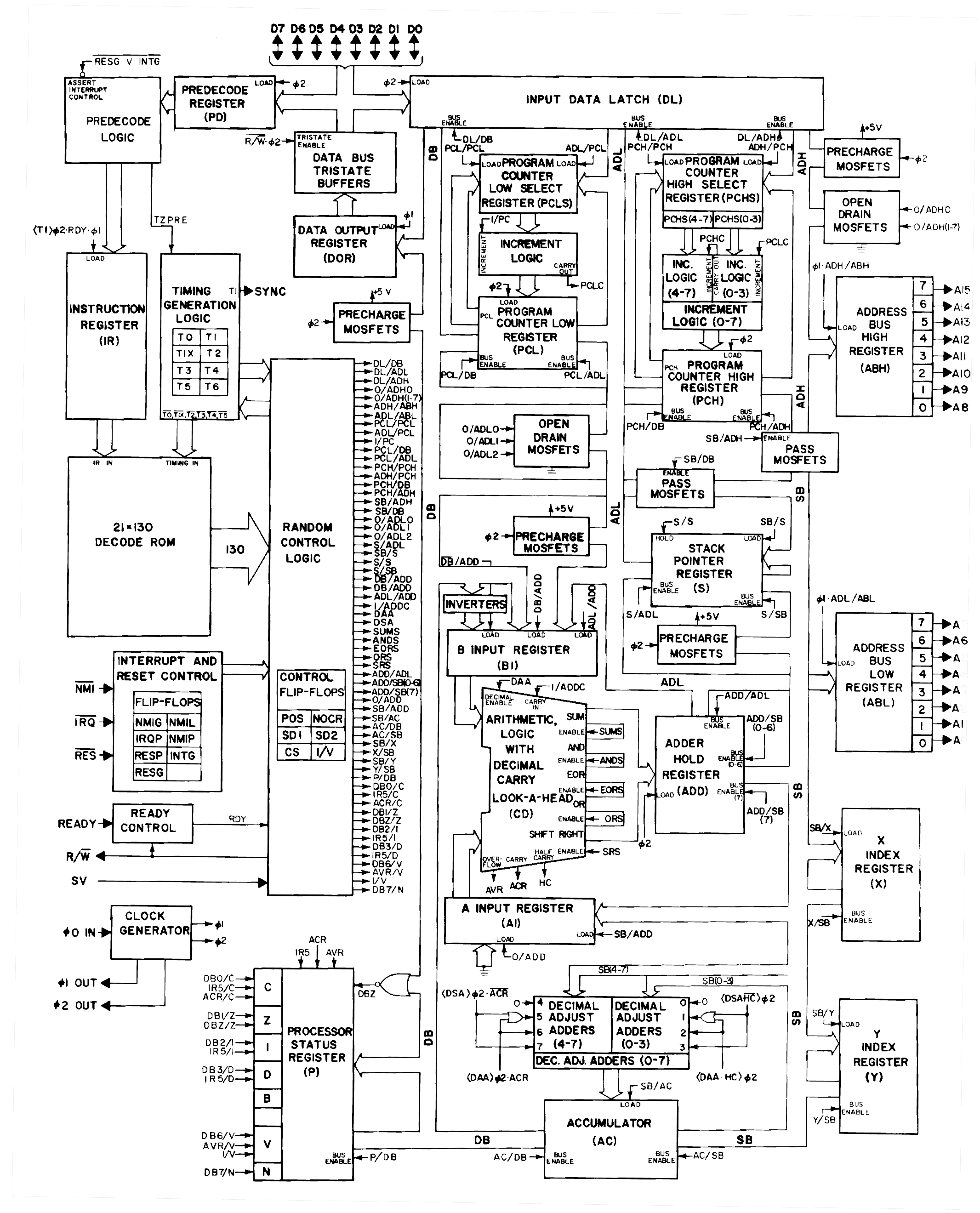
На схеме ниже (из патента на 8086) показано, как АЛУ связано с остальной частью процессора через шину АЛУ. В предыдущем обсуждении рассматривался блок «полнофункционального АЛУ» в центре схемы, который принимает два 16-битных входа и формирует 16-битный результат. Эти входы поступают из трёх временных регистров: A, B и C. (Эти регистры не видны программисту и не должны путаться с регистрами AX, BX и CX процессора 8086.) Отмечу несколько особенностей этих регистров, которые будут важны далее. Первый вход АЛУ может поступать из любого регистра, но второй вход всегда берётся из регистра B. Эти регистры имеют двунаправленное соединение с шиной АЛУ, поэтому в них можно как записывать данные, так и считывать их.
Одной из необычных особенностей АЛУ является наличие единственного канала передачи данных между ним и остальной частью процессора — через шину АЛУ.(примеч.¹²) Это выглядит как потенциальное узкое место, поскольку для загрузки регистров требуется два тактовых цикла, а затем ещё один цикл нужен для получения результата. Тем не менее, на практике такая архитектура оказалась достаточно эффективной для процессора 8086.

Показанное выше слово состояния процессора (Processor Status Word, PSW) хранит флаги условий — биты состояния результата работы АЛУ: ноль, знак (отрицательное значение), переполнение и т. д. Хотя на схеме PSW выглядит довольно простым, фотография кристалла в начале статьи показывает, что он занимает примерно треть всей схемы АЛУ. Из-за сложности я отложу подробное рассмотрение логики флагов: каждый флаг реализован отдельной схемой, учитывающей множество частных случаев.
На схеме ниже показан один бит реконструированной реализации временных регистров АЛУ. Регистры построены на защёлках (latch); каждый прямоугольник представляет собой защёлку — схему, способную хранить один бит. Два крупных элемента AND-NOR выполняют роль мультиплексоров, выбирая выход одного из защёлок. Верхний элемент выбирает регистр для чтения. Нижний — определяет, какой регистр будет подан на вход АЛУ.

Хотя мультиплексор на основе 6-входового элемента AND-NOR может выглядеть сложным, его реализация на NMOS-транзисторах довольно проста. На схеме показано, как он собирается из шести транзисторов и подтягивающего элемента. Можно убедиться, что если оба транзистора в паре открыты, выход будет подтянут к земле, реализуя функцию AND-NOR.

Схема защёлки показана ниже. Я уже подробно писал о защёлках в 8086, поэтому приведу краткое объяснение. Суть защёлки в том, что она может устойчиво хранить либо 0, либо 1. Когда тактовый сигнал clk’ находится в высоком состоянии, верхний транзистор открыт и соединяет инверторы в замкнутую цепь. Если на входе первого инвертора 1, он выдаёт 0 на второй инвертор, который, в свою очередь, возвращает 1 на первый — таким образом состояние сохраняется. Аналогично система остаётся стабильной и при входном значении 0.

Особенность этой защёлки в том, что она является динамической. Когда сигнал clk’ низкий, обратная связь разрывается, но значение на входе первого инвертора сохраняется благодаря ёмкости проводника и транзистора. Когда clk’ снова становится высоким, это напряжение восстанавливается. Альтернативно, при низком уровне clk’ можно загрузить новое значение в защёлку, активировав сигнал load: это включает первый транзистор и пропускает новый входной сигнал внутрь защёлки. В 8086 используются динамические защёлки, поскольку они компактны — всего два транзистора и два инвертора. Реализация защёлки в кремнии показана ниже.

Схема ниже обобщает компоненты реализации временных регистров. Этот блок повторяется 16 раз для формирования полноразмерных регистров.(примеч.¹³) Выходы регистров подаются на вход схемы АЛУ, описанной ранее.

Заключение
Хотя процессор Intel 8086 обладает достаточно сложной схемотехникой, его элементы имеют достаточно крупный размер, чтобы их можно было изучать под микроскопом. АЛУ является ключевой частью процессора и занимает значительную долю площади кристалла. Его схемы можно восстановить с помощью внимательного анализа, что позволяет увидеть интересные инженерные решения. В нём используется Манчестерская цепочка переноса для быстрого распространения переноса. Сигналы генерации и распространения переноса формируются с помощью мультиплексоров, которые работают как генераторы произвольных функций, обеспечивая гибкость АЛУ при относительно небольшой сложности схемы. АЛУ построено с использованием комбинации стандартной логики, логики на проходных транзисторах и динамической логики — это позволяет оптимизировать производительность и уменьшить размер.
Вы могли заметить, что АЛУ 8086 не поддерживает напрямую операции умножения, деления или сдвиги на несколько бит, несмотря на наличие соответствующих инструкций в наборе команд. Эти операции реализуются на уровне микрокода с использованием более простых операций АЛУ (сдвиг, сложение и вычитание для умножения и деления, а также последовательные одноразрядные сдвиги для больших сдвигов).
Некоторые особенности АЛУ ещё остаются за рамками рассмотрения, в частности логика флагов и механизм формирования управляющих сигналов на основе кодов операций (opcode). Я планирую рассказать об этом в следующих материалах, поэтому следите за обновлениями.
Примечания и ссылки
-
Размер АЛУ почти всегда соответствует разрядности процессора, но бывают исключения. Например, процессор Z-80 является 8-битным, но имеет 4-битное АЛУ. В результате АЛУ Z-80 выполняет каждую арифметическую операцию в два прохода, обрабатывая половину байта за раз. В некоторых ранних компьютерах использовалось 1-битное АЛУ для снижения стоимости, однако такие последовательные процессоры работали медленно.
2. Я изучал АЛУ различных ранних микропроцессоров, включая 8008, Z-80 и 8085. Также я выполнял реверс-инжиниринг специализированных микросхем АЛУ, таких как 74181 и Am2901.
3. В топологии АЛУ биты 15–8 расположены сверху, а биты 7–0 — снизу. Такое расположение обусловлено порядком битов в тракте данных: биты идут не линейно, как 15-14-…-0, а вперемежку: 15-7-14-6-…-8-0. Причина такого чередования в том, что оно упрощает перестановку двух байтов в 16-битном слове: для этого достаточно поменять местами пары битов. АЛУ разделено на два ряда, чтобы вписаться в доступное горизонтальное пространство. Даже при высокой и узкой компоновке одного каскада АЛУ ширина одного бита АЛУ всё равно больше, чем ширина одного бита регистрового файла. Разделение АЛУ на два ряда позволяет сохранить примерно одинаковый шаг между битами и избежать длинных соединений между регистровым файлом и АЛУ.
4. Манчестерская цепочка переноса (Manchester carry chain) была разработана в Манчестерском университете и описана в статье Parallel addition in digital computers: a new fast «carry» circuit, опубликованной в 1959 году. Она использовалась в суперкомпьютере Atlas (1962).
5. АЛУ также использует технику пропуска переноса (carry-skip) для ускорения вычисления переноса; кратко поясню её суть. Идея carry-skip состоит в том, чтобы по возможности «перепрыгивать» через некоторые каскады цепочки переноса, уменьшая максимальную задержку при его распространении. Например, если на бит 8 приходит входной перенос и для битов 8, 9, 10 и 11 включено распространение переноса, то можно сразу сделать вывод, что перенос поступит и на бит 12. Таким образом, если выполнить логическое И над входным переносом и четырьмя сигналами распространения переноса, то в этом случае входной перенос для бита 12 можно вычислить немедленно. Иначе говоря, перенос перескакивает с бита 8 на бит 12. Аналогично другие схемы carry-skip позволяют переносу перескакивать с бита 2 на бит 4 и с бита 4 на бит 8. Эти схемы уменьшают время вычисления в худшем случае. Именно наличием carry-skip объясняется, почему отдельные каскады АЛУ похожи друг на друга, но не полностью идентичны. Обратите внимание: при логических операциях или сдвиге либо сигнал распространения переноса, либо сигнал генерации переноса равен 0, поэтому carry-skip не срабатывает и не искажает результат.
6. Стоит пояснить, как реализовано вычитание. В типичном АЛУ один из входов инвертируется перед сложением, так что та же схема сложения используется и для вычитания. Однако в АЛУ 8086 вычитание реализовано иначе — за счёт изменения входов мультиплексоров, как показано ниже. Это позволяет задействовать универсальный мультиплексор и не вводить отдельную схему отрицания. (Операция сравнения реализуется как вычитание без сохранения результата. Если разность равна нулю, значения равны; если разность положительна, первое значение больше.)

7. Обычно сдвиг влево на один бит в процессоре реализуется как сложение значения с самим собой. Я не знаю, почему в 8086 был выбран подход через линию переноса, а не через сложение.
8. ПЛИС (программируемая пользователем вентильная матрица — FPGA, field-programmable gate array) использует схожие подходы для реализации произвольных логических функций. Таблица истинности хранится в таблице поиска (lookup table, LUT). Такие таблицы обычно имеют больший размер: например, LUT с шестью входами содержит 2⁶ = 64 значения. Одно из отличий FPGA от АЛУ заключается в том, что FPGA программируется один раз, после чего функции логических элементов фиксируются, тогда как в АЛУ функции элементов могут изменяться при каждой операции.
9. Мультиплексор в блоке генерации переноса возвращает 0, если первый аргумент равен 0. Иными словами, он реализует только два случая из таблицы истинности и имеет два управляющих входа. Чтобы обработать оставшиеся два случая, его выход принудительно притягивается к нулю тактовым сигналом. Поскольку схема управляется тактовым сигналом и зависит от заряда, накопленного в ёмкости цепи, она относится к динамической логике. В процессоре 8086 в основном используется стандартная статическая логика, но в отдельных местах применяется и динамическая.
10. Управляющие сигналы для АЛУ формируются с помощью программируемой логической матрицы (PLA, programmable logic array), аналогичной ПЗУ, которая принимает на вход 5-битный код операции (код операции (opcode)). Этот код может поступать непосредственно из инструкции или задаваться микрокодом. В случае инструкции часть, отвечающая за операцию АЛУ, обычно располагается в битах 5–3 первого байта инструкции или в битах 5–3 байта MOD R/M. Это позволяет одной процедуре микрокода обрабатывать сразу несколько сходных арифметических и логических инструкций, уменьшая объём микрокода. PLA управления АЛУ генерирует сигналы, необходимые для выполнения нужной операции, прозрачно для микрокода. Стоит отметить, что управляющих сигналов у АЛУ значительно больше, чем было описано: часть из них отвечает за обработку флагов, другие — за различные частные случаи.
Управляющие сигналы проходят через показанную ниже необычную схему. Если на вход подаётся высокий уровень, она передаёт тактовый импульс в АЛУ; в противном случае сигнал остаётся низким. В фазе отрицательного фронта тактового сигнала управляющий сигнал разряжается на землю через нижний транзистор. При отсутствии входного сигнала линия не возбуждается в фазе положительного фронта, но остаётся в низком состоянии за счёт динамической ёмкости. Один элемент остаётся не до конца понятным — транзистор с затвором, постоянно подключённым к +5 В, из-за чего он всегда открыт и, на первый взгляд, кажется избыточным. Он снижает напряжение на затворе транзистора clk и, соответственно, выходное напряжение, но точная причина его использования неочевидна. Возможно, он нужен для ограничения тока или замедления сигнала.

11. Подтягивающий резистор в NMOS-логике реализуется с помощью специального транзистора обеднённого типа (depletion-mode transistor). Такой транзистор выполняет роль резистора, но занимает меньше места и работает эффективнее, чем обычный резистор.
12. В процессоре 6502 два входа АЛУ подключены к раздельным шинам (подробности), что позволяет загружать их одновременно. В 8085 (и во многих других ранних микропроцессорах) один из входов АЛУ напрямую соединён с аккумуляторным регистром, чтобы снизить нагрузку на шину (подробности).
{kind=link}
{kind=link}
13. Кремниевая реализация младших восьми бит АЛУ и регистров выполнена зеркально относительно старших восьми бит. Это сделано для того, чтобы сигналы АЛУ располагались ближе к схеме флагов, которой они необходимы. Поскольку логика флагов находится между двумя половинами АЛУ, обе части оказываются примерно зеркальными отражениями друг друга. (См. фотографию кристалла в начале статьи.)

Если хочется не просто читать про схемотехнику уровня 8086, а понимать её на уровне собственных решений, нужна практика — от транзистора до платы. На курсе «Электроника и электротехника» последовательно разбирают, как проектировать цифровые и аналоговые схемы, подбирать компоненты и доводить устройство до производства. Это тот уровень, где АЛУ перестаёт быть абстракцией и становится инженерной задачей.
Чтобы узнать больше о формате обучения и задать вопросы преподавателям курсов, приходите на бесплатные уроки:
-
15 апреля, 20:00. «Запутывание кода (обфускация) как метод сокрытия вредоносного ПО». Записаться
-
21 апреля, 20:00. «Связанные списки в ядре Linux: от API до реального кода». Записаться
-
23 апреля, 20:00. «Многопоточность в C++: как писать быстрые и безопасные приложения». Записаться
ссылка на оригинал статьи https://habr.com/ru/articles/1023002/