Сам Яндекс.Перевод вышел из беты несколько месяцев назад. От других немногочисленных подобных сервисов его отличает автословарь, уникальная технология которого разработана командой лингвистов и программистов Яндекса. Во время его разработки удалось объединить современные статистические подходы машинного перевода и традиционные лингвистические инструменты.
Чтобы понять, насколько значимым шагом в развитии машинного перевода является появление автословаря, стоит вспомнить, что 20 лет назад были распространены синтаксические переводчики, для которых таблицы соответствия фраз на разных языках составляли вручную. Процесс их создания стал меняться только в конце 1990-х, когда появились первые статистические переводчики. Для обучения их моделям переводов стали использовать параллельные тексты. Документы, в которых одно и то же написано на разных языках, извлекали, например, из дипломатической документации. Большой базой параллельных текстов стали документы ООН. Но на подобной лексике создать общелексический переводчик не получилось, потому что даже неформальные тексты он переводил сухим дипломатическим языком.
Решением проблемы обучения универсальной модели перевода стало использование параллельных документов, извлечённых из индексов поисковых машин. И это не только мультиязычные сайты, которые изначально были созданы на нескольких языках. К примеру, в интернете появился документ с текстом о каком-то событии. Для него создаётся своеобразный «паспорт» с характерными (контрастными) словами, который потом сравнивается с паспортами других документов, и при их совпадении делается вывод, что это текст об одном и том же, но на разных языках. Этот процесс требует значительных вычислительных ресурсов, потому что приходится обрабатывать миллиарды веб-документов.
Естественно, не все предложения в таких текстах будут последовательными переводами друг друга. Чтобы составить таблицы соответствия слов и фраз со всеми возможными переводами, нужно сделать специальное выравнивание и выкинуть те, которые случайно туда попали. В итоге получается, что, например, каждому русскому слову соответствует 20–30 английских.
Практически весь вышеописанный процесс основывается на статистических методах и теории вероятностей. Автоматический переводчик знает величину вероятности каждого перевода и на её основе быстро делает свой выбор по языковой модели из десятков вариантов, а иногда и сотен.
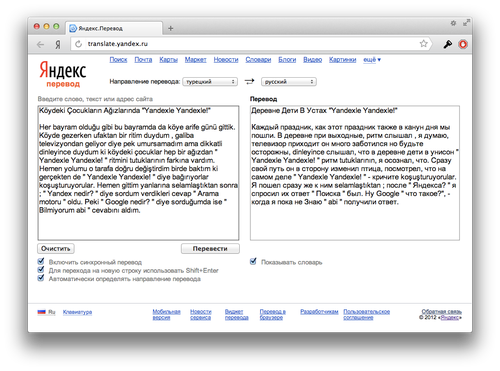
Кажется, что для точности перевода и учёта стилистики текста, нужно всего лишь показывать варианты переводов человеку и он подберёт наиболее подходящее по контексту и стилю слово. Но это статистические фрагменты текста, которые сами по себе могут не нести для простого пользователя никакого смысла. Как минимум, потому что он может увидеть тысячи вариантов для одного слова, что ему никак не поможет. Особенно, если человек не очень хорошо знает язык, на который переводит.
Автословарь решает проблему выбора, выбирая только самые подходящие переводы и показывая их в читабельной для простого пользователя форме. Для этого наша команда специалистов провела сложную и ресурсоёмкую работу. Во-первых, мы сделали так, что автословарь показывает словарную форму слова. Во-вторых, научили выявлять из всего набора фраз действительно устойчивые словосочетания, которые человек может потом сформулировать.
В составлении автоматического словаря есть и другие трудности. Например, когда пользователь запрашивает перевод слова без контекста, то для группировки вариантов на другом языке приходится выводить все его значения. И зачастую на языке, который ему незнаком. Чтобы помочь человеку сориентироваться среди вариантов переводов, нужно не просто показать все главные значения слова, но и сделать группировку по их смысловым значениям.
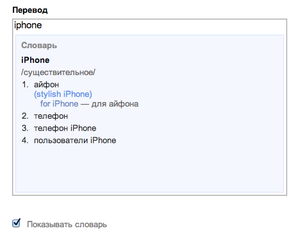 Для этого используется словарь синонимов, который тоже строится на основе статистических данных, накопленных нами в процессе построения модели перевода. Благодаря тому, что в Яндекс.Переводе есть оба направления перевода, мы знаем, что разные слова одного языка часто переводят в одно и то же слово другого языка. Это позволяет предположить, что они являются синонимами. Таким образом, мы автоматически формируем группы переводов, каждая из которых имеет свое смысловое значение.
Для этого используется словарь синонимов, который тоже строится на основе статистических данных, накопленных нами в процессе построения модели перевода. Благодаря тому, что в Яндекс.Переводе есть оба направления перевода, мы знаем, что разные слова одного языка часто переводят в одно и то же слово другого языка. Это позволяет предположить, что они являются синонимами. Таким образом, мы автоматически формируем группы переводов, каждая из которых имеет свое смысловое значение.
В результате пользователю Яндекс.Перевода не нужно дополнительно смотреть статьи из обычных словарей, чтобы подобрать более точный перевод. Автословарь покажет ему автоматически сформированную статью, в которой даже будут примеры употребления слова. К тому же, основанный на статистике словоупотребления в интернете, автоматический словарь быстрее обновляется. Благодаря всему этому, переводы, выполненные с помощью машинного переводчика Яндекса, будут гораздо качественнее.
ссылка на оригинал статьи http://habrahabr.ru/company/yandex/blog/156187/
Добавить комментарий