Перефразируя известную поговорку: «не делает багов тот, кто ничего не кодирует». Каждый разработчик умеет и любит делать баги, но не любит потом их исправлять. Ошибки в коде в одном случае приводят просто к некорректной обработке данных программой, а в другом — к исключениям (вылетам, падениям, крашам). В этом посте я расскажу о том, как можно автоматизировать сбор данных о краше программы, чтобы сильно облегчить себе жизнь при разборе и устранении ошибок.
Знаете, какую реакцию я увидел, когда рассказал одному знакомому, что хочу использовать в проекте библиотеку, которая автоматизирует сбор данных об ошибках? Я услышал буквально следующее: «Да зачем кому-то нужна такая сложная система? Вон если у меня в программе что-то случается, то юзеры мне пишут письмо, какие кнопки они нажимали и что делали. И потом я воспроизвожу ошибку и исправляю ее».
Да, программисты ленивы. Мы хотим убедить себя в том, что исправлять ошибки, обнаруженные юзером, хорошо получается у нас и вручную. Точно также мы убеждаем себя, что писать качественный код вполне реально и без юнит-тестов, и даже без исправления warning’ов, которые сыплет компилятор при сборке проекта. Все равно заказчику нужно, чтобы «было готово побыстрее», а все ошибки выявим и устраним когда-нибудь потом. Вон тестеры же сидят, пусть они и вылавливают баги. Времени всегда не хватает, дедлайны поджимают, начальство всякие «лишние навороты» не одобряет.
Практика показывает, что такие проекты, может быть, и выполняются в рекордные сроки, и, может быть, большинство ошибок вылавливаются тестерами, но, тем не менее, после релиза пользователи массово шлют письма на сапорт и жалуются на исключения в программе. С ходом времени дает о себе знать и отсутствие внятной архитектуры, комментариев к коду, юнит-тестов и тому подобного. Каждый разработчик, кто вносит изменения в чужой код, плодит новые баги и потенциал для исключений, часть из которых опять отлавливается тестерами, а часть уходит в релиз.
Что я обычно делаю, когда пользователь присылает письмо с просьбой о помощи?
Когда пользователь присылает к нам в сапорт письмо с сообщением о том, что в нашей программе, установленной у него на машине, происходит критическая ошибка, обычно я прошу сапорт, чтобы выяснили, какая у него версия приложения и версия операционной системы. Потому что программное окружение системы пользователя очень важно для выявления причин ошибки.
Во-первых, я вынужден общаться с юзером через посредника (сапорт), которому еще нужно объяснить, что я хочу, а во-вторых я должен обращаться за техническими сведениями к пользователю, который может быть, и знает только, как включить компьютер и запустить офис. Большинство пользователей, с которыми я общался, не в обиду им будет сказано, не могут выражать свои мысли и не знают технических терминов. Им не объяснишь, как поменять такой-то ключ реестра и посмотреть файлик в скрытой папке LocalAppData.
Когда пользователь отвечает на мой запрос, то практически всегда у меня возникают дополнительные вопросы: «а попробуйте нажать вот такую-то кнопку и поменять вот такую-то опцию». В ответ я получаю молчание. Пользователь просто не обладает терпением, чтобы сделать это несколько раз, пока я не выужу у него все необходимые мне сведения.
В своих проектах, независимо от того, что это – сервис или приложение с оконным интерфейсом — я веду логи. В лог я записываю сообщения об ошибках и текущие операции. Лог файл в теории должен помогать получить от пользователя ту техническую информацию о работе приложения, которые пользователь не знает, и знать не может.
Когда в приложении возникает ошибка, я запрашиваю у пользователя лог-файл. Вот тут то и начинаются проблемы. Оказывается, что объяснить пользователю, откуда именно взять лог файл и в какой момент времени он должен его взять – это нетривиальная проблема. Часто пользователь перезапускает приложение уже после того как ошибка произошла, после чего лог файл затирался и приходил ко мне пустым, вызывая мое недоумение.
Вообще при разборе бага моя основная цель — воспроизвести этот баг на своей машине. Это позволит мне его исправить. Со слов пользователя редко бывает понятно, как же он заставляет приложение упасть, как ему удается вызвать исключение в приложении? Сложно ответить на этот вопрос, имея перед глазами только кучу текста в логе.
Поэтому следующим этапом моего общения с пользователем является просьба, чтобы он сделал скриншот или записал видеоролик, в котором бы показал свои действия, как он добивается ошибки в приложении. Думаете, много пользователей присылает мне ролик? Нет, но, тем не менее, такие умельцы мне встречались. И вот такой ролик оказывался подчас самой полезной вещью, чтобы воспроизвести ошибку.
Итак, основным недостатком ручного сбора данных о критической ошибке в приложении является то, что пользователь ленив и косноязычен. Он не станет проверять ваши гипотезы для установления причины ошибки – у него для этого нет желания, терпения и технических знаний.

Как же, всё-таки, лучше собирать информацию об ошибке – вручную или автоматически?
Идея автоматического сбора и доставки отчетов об ошибках появилась в начале 2000-х годов в Microsoft [1], когда они были озадачены градом ошибок, возникающих в многочисленных продуктах (в том числе Windows и Office). Команда разработчиков Windows разработала инструмент, позволявший делать дамп ядра системы, который затем можно было анализировать.
Независимо от них, команда разработчиков Office создала инструмент, который умел ловить необработанные исключения и создавать минидамп. Минидамп, в отличие от дампа, содержал в себе лишь небольшие фрагменты виртуальной памяти процесса, необходимые, чтобы прочитать снимок стека того потока, в котором произошло исключение. Минидамп оказался очень удобным, потому что его можно автоматически пересылать через интернет.
Эту разработку назвали Windows Error Reporting (WER) и внедрили в Windows XP. С тех пор во всех продуктах от Microsoft ошибки отлавливает WER. Существует следующая статистика [2] по эффективности использования WER в продуктах Microsoft:
- исправление 20 процентов от «топовых» обнаруженных ошибок может решить 80 процентов проблем клиентов;
- исправляя причину всего 1-го процента ошибок, можно исправить 50 процентов проблем клиентов.
Любой разработчик может использовать WER для автоматизации сбора данных об ошибках в своем приложении. WER отправляет отчет об ошибках на сервер Microsoft, а разработчик может «бесплатно» получить доступ к этому серверу. Но для этого нужно иметь сертификат VeriSign. Покупка такого сертификата стоит от 500 долларов в год. На самом деле, если вы разрабатываете под Windows, то покупка сертификата вам необходима, поэтому будем считать, что доступ к серверу WER вы можете получить бесплатно.
Кроме WER, существуют и другие бесплатные библиотеки для сбора данных о падениях программы. Например, в своих С++ проектах под Windows я пользуюсь библиотекой с открытым исходным кодом под названием CrashRpt [3]. Линуксоидам могу посоветовать воспользоваться открытой библиотекой Google breakpad [4].
Лично я предпочитаю CrashRpt, поскольку пишу только под Windows. Кроме того эта библиотека позволяет отсылать файлики отчетов об ошибках не только на сервер через HTTP, но и как письмо на мой почтовый ящик, что более для меня удобно. Дальше я расскажу, что еще умеет делать эта библиотека.
Какие данные об ошибке можно собрать автоматически?
Итак, в приложении произошло и исключение. Исключение может быть спровоцировано многими причинами: обращение по нулевому адресу в памяти, переполнение стека, исчерпание памяти и так далее. В MSDN вы можете найти с десяток функций, которые C run-time предоставляет для перехвата (обработки) исключений. Этими функциями и пользуется библиотека CrashRpt.
Когда происходит исключение, запускается обработчик CrashRpt, который, прежде всего, сохраняет exception pointers (это структура, содержащая адрес исключения, его код и тип). Далее CrashRpt запускает новый процесс и передает ему exception pointers. Родительское приложение, в котором произошло исключение, может быть нестабильным, и оно ликвидируется, как только все данные об ошибке будут извлечены.

Минидамп
В новом процессе и происходит основная работа по сбору данных об ошибке.
Во-первых, с помощью системной библиотеки dbghelp.dll от Microsoft записывается минидамп. Для этого все потоки процесса-родителя приостанавливаются, и делается «снапшот» процесса. Записываются имена и версии всех DLL-модулей, загруженных в процесс. Сохраняются идентификаторы потоков, которые работали в процессе. Для каждого потока записывается снимок стека. Также в минидамп сохраняется информация о версии операционной системы, количестве ЦП и их марке. Весит минидамп порядка нескольких десятков килобайт.
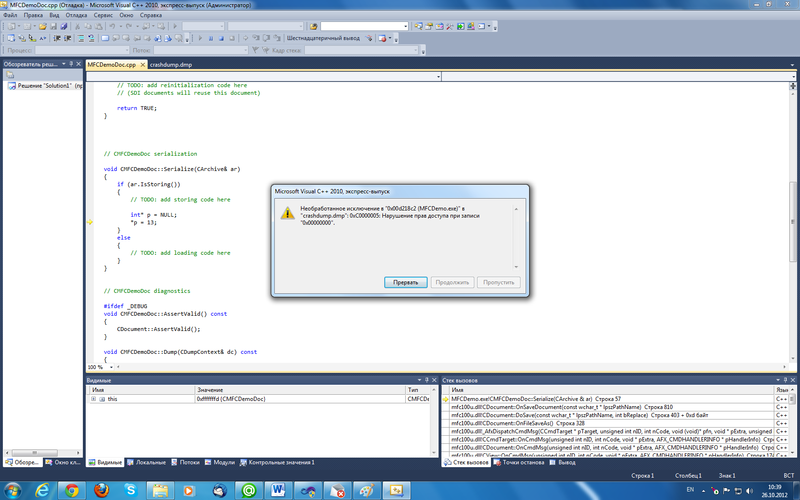
После того, как мы получили файл минидамп, мы можем открыть его в среде Visual Studio и наглядно увидеть состояние программы на момент краша: определить версию приложения, версию операционной системы и посмотреть место в коде, где произошло исключение (см. рис. ниже). Правда упрощает жизнь?
Логи
Автоматизация сбора информации о падениях программы не заставляет нас отказываться от привычных логов. Мы можем, как и прежде, записывать текущие операции в лог, а при краше лог автоматически добавится в отчет об ошибке. Это избавляет от непонимания, которое могло раньше возникать при «ручных» запросах логов у пользователя. Теперь лог всегда будет содержать актуальные данные на момент падения программы, а пользователю не придется объяснять, как открыть скрытую папку LocalAppData и какой файлик оттуда взять.
Помимо логов мы можем добавить в отчет об ошибке и любые другие файлы, которые пожелаем.
Скриншоты
Что мне не нравится в минидампе и логах – так это то, что они зачастую не позволяют воспроизвести ошибку. Да, я могу увидеть место в программе, где произошел краш, и могу построить гипотезу, от чего он мог произойти. Например, часто краши происходят от того, что переменная не инициализирована, и идет обращение по мусорному адресу в памяти.
Но, как я ни бейся, в большинстве случаев я не смогу подобрать действия, которые позволяют воспроизвести краш на моей машине. Дело не только в том, что у каждого пользователя своя уникальная программная среда, отличная от среды моей машины. Дело еще и в том, что у пользователей свои паттерны работы с вашей программой. То как вы используете программу, какие действия вы с ней выполняете, может кардинально отличаться от того, что делает пользователь.
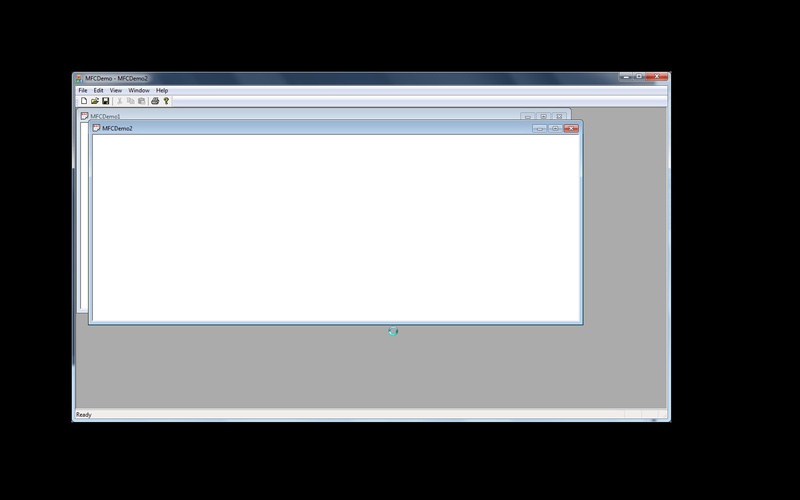
Поэтому очень полезной информацией об ошибке является скриншот экрана пользователя в момент краша. Библиотека CrashRpt позволяет автоматически создавать такой скриншот, сохраняя его в формате JPEG (качество сжатия можно настраивать) или PNG. В результате, я могу увидеть, какую кнопку пользователь нажал в момент ошибки, что, поверьте мне, очень помогает именно в воспроизведении ошибки.
На рисунке ниже я привел пример скриншота, снятого в момент краша приложения. Скриншот содержит только область окна приложения, остальные области автоматически закрашены черным (охраняем приватность пользователя).
Видеоролики
Помните, я говорил, что пару раз пользователи присылали мне ролики с изображением действий, которые они делали непосредственно перед моментом падения программы? Так вот, с библиотекой CrashRpt вам не придётся упрашивать пользователя сделать ролик. Библиотека сама их сделает (с согласия пользователя, конечно).
Понятно, что нельзя предсказать, когда произойдет краш. Поэтому CrashRpt периодически (с интервалом, который задаете вы) делает скриншоты экрана и сохраняет их на диск в несжатом виде (как BMP-файлы). При накоплении скриншотов, старые удаляются, а их место занимают новые. В тестах на моей машине это занимает порядка 5-7% ресурсов ЦП и несколько сот мегабайт диска.
Если происходит исключение, записанные скриншоты сжимаются кодеком OGG Theora [5], и получается видео файл, который можно открыть в браузере Chrome или Firefox, или в любом видеопроигрывателе.
Да, операция записи видео довольно ресурсоемкая, но не обязательно ведь включать ее всегда. Можно, например, включать ее, только если разбирательство с пользователем зашло в тупик, и остается последняя возможность воспроизвести ошибку – снять ролик.
Заключение
Не спорю, исправлять баги в программе, которые приводят к падениям, можно и без автоматизации сбора данных об ошибке. Но автоматизация позволяет делать это действительно эффективно. Она позволяет облегчить жизнь разработчика. Причем не обязательно только после релиза. Мы, например, используем автоматизацию еще на ранних этапах бета тестирования программы, чтобы облегчить себе общение с тестерами, которые ведь тоже (не в обиду им будет сказано) не всегда понимают, как сделать скриншот или записать видео ролик.
Кстати, а знаете какая самая короткая падающая программа на C [6]?
main(){main();} Ссылки
- Kirk Glerum et al. Debugging in the (Very) Large: Ten Years of Implementation and Experience. Proceedings of the 22nd ACM Symposium on Operating Systems Principles (SOSP ’09), 2009.
- Windows Error Reporting: Getting Started, MSDN
- CrashRpt – a crash reporting system for Windows applications. Google Project Hosting.
- breakpad – crash reporting. Google Project Hosting.
- Theora video compression
- Самая короткая «падающая» программа на C, RSDN Forums
ссылка на оригинал статьи http://habrahabr.ru/post/156255/
Добавить комментарий