Сперва захотелось сравнить производительность Erlang парсера mochiweb_html с используемым из Python lxml.etree.HTML(). Провел простейший бенчмарк, нужные выводы сделал, а потом подумал что неплохо было бы добавить в бенчмарк ещё парочку-другую парсеров и платформ, оформить покрасивее, опубликовать код и написать статью.
На данный момент успел написать бенчмарки на Erlang, Python, PyPy, NodeJS и С в следующих комбинациях:
- Erlang — mochiweb_html
- CPython — lxml.etree.HTML
- CPython — BeautifulSoup 3
- CPython — BeautifulSoup 4
- CPython — html5lib
- PyPi — BeautifulSoup 3
- PyPi — BeautifulSoup 4
- PyPi — html5lib
- Node.JS — cheerio
- Node.JS — htmlparser
- Node.JS — jsdom
- C — libxml2 (скорее для справки)
В тесте сравниваются скорость обработки N итераций парсера и пиковое потребление памяти.
Интрига: кто быстрее — Python или PyPy? Как сказывается иммутабельность Erlang на скорости парсинга и потреблении памяти? Насколько быстра V8 NodeJS? И как на всё это смотрит код на чистом C.
Термины
Скорее всего вы с ними знакомы, но почему бы не повторить?
Нестрогий HTML парсер — парсер HTML, который умеет обрабатывать некорректный HTML код (незакрытые теги, знаки > < внутри тегов <script>, незаэскейпленные символы амперсанда &, значения атрибутов без кавычек и т.п.). Понятно, что не любой поломанный HTML можно восстановить, но можно привести его к тому виду, к которому его приводит браузер. Примечательно, что большая часть HTML, которая встречается в интернете, является в той или иной степени невалидной!
DOM дерево — Document Object Model если говорить строго, то DOM это тот API, который предоставляется яваскрипту в браузере для манипуляций над HTML документом. Мы немного упростим задачу и будем считать, что это структура данных, которая представляет из себя древовидное отображение структуры HTML документа. В корне дерева находится элемент <html>, его дочерние элементы — <head> и <body> и так далее. Например, в Python документ
<html lang="ru-RU"> <head></head> <body>Hello, World!</body> </html>Можно в простейшем виде представить как
("html", {"lang": "ru-RU"}, [ ("head", {}, []), ("body", {}, ["Hello, World!"]) ])Обычно HTML преобразуют в DOM дерево для трансформации или для извлечения данных. Для извлечения данных из дерева очень удобно использовать XPath или CSS селекторы.
Конкурсанты
- Erlang
- Mochiweb html parser. Единственный нестрогий HTML парсер для Erlang. Написан на эрланге.
- CPython
- lxml.etree.HTML биндинг libxml2. Cython
- BeautifulSoup 3 Написанный на python HTML DOM парсер (3-я версия).
- BeautifulSoup 4 HTML DOM парсер с подключаемыми бекендами.
- html5lib Написанный на питоне DOM парсер, ориентированный на HTML5.
- PyPi (те же парсеры, что и CPython, кроме lxml)
- BeautifulSoup 3
- BeautifulSoup 4
- html5lib
- Node.JS
- cheerio написанный на JS HTML DOM парсер с поддержкой jQuery API
- htmlparser HTML DOM парсер на чистом JS
- jsdom написанный на JS HTML DOM парсер с навороченным API, похожем на API браузера
- C
- libxml2 Написанный на C нестрогий HTML SAX/DOM парсер.
Цели
Вообще, парсинг HTML (как и JSON) интересен тем, что документ нужно просматривать посимвольно. В нём нет инструкций вроде «следующие 10Кб — это сплошной текст, его копируем как есть». Если мы встретили в тексте тег <p>, то нам нужно последовательно просматривать все последующие символы на наличие конструкции </. Тот факт, что HTML может быть невалидным, заставляет «перепроверять всё по 2 раза». Потому что, например, если мы встретили тег <option>, то далеко не факт, что встретим закрывающий </option>. Вторая проблема, которая обычно возникает с такими форматами — экранирование спецсимволов. Например, если весь документ это <html>...100 мегабайт текста... & ...ещё 100 мегабайт текста...</html>, то парсер будет вынужден создать в памяти полную копию содержимого тега с единственным изменением — "&", преобразованный в "&" (хотя некоторые парсеры просто разбивают такой текст на 3 отдельных куска).
Необходимость строить в памяти довольно большую структуру — дерево из мелких объектов, накладывает довольно жесткие требования на управление памятью, сборщик мусора, на оверхед на создание множества мелких объектов.
Нашим бенчмарком хотим:
- Сравнить производительность и потребление памяти различных нестрогих HTML DOM парсеров.
- Изучить стабильность работы парсера. Возрастет ли время обработки одной страницы и объём потребляемой памяти с ростом числа итераций?
- Как зависит скорость парсинга и потребление памяти от размера HTML документа.
- Ну и оценить эффективность платформы: скорость работы со строками, эффективность менеджмента памяти
Проверять качество работы парсера в плане полноты восстановления поломанных документов не будем. Сравнение удобства API и наличие инструментов для работы с деревом тоже оставим за кадром.
Условия и методика тестирования
Программа один раз считывает документ с диска в память и затем N раз последовательно парсит его в цикле.
Парсер на каждой итерации должен строить в памяти полное DOM дерево.
После N итераций программа печатает время работы цикла и завершается.
Каждый парсер запускаем на наборе из нескольких HTML документов на N = 10, 50, 100, 400, 600 и 1000 итераций.
Измеряем User CPU, System CPU, Real runtime и (примерное?) пиковое потребление памяти с помощью /usr/bin/time.
HTML документы:
- page_google.html (116Kb) — выдача гугла, 50 результатов на странице. Очень много встроенного в страницу HTML и JS, мало текста, весь HTML в одну строку.
- page_habrahabr-70330.html (1,6Mb) — статья на хабре с 900 комментариями. Очень большая страница, много тегов, пробелов и табуляции.
- page_habrahabr-index.html (95Kb) — главная страница habrahabr. Типичная страница блога.
- page_wikipedia.html (99Kb) — статья на wikipedia. Хотел страничку, на которой будет много текста и мало тегов, но выбрал не самую удачную. В итоге много тегов и встроенного CSS.
На самом деле понял, что большинство документов одинакового размера только под конец, но переделывать не стал, т.к. сам процесс измерения занимает довольно много времени. А так было бы интересно отследить различные зависимости ещё и от размера страницы. UPD: готовится вторая часть статьи, в ней будем парсить сайты из TOP1000 Alexa.
Тесты запускал последовательно на Ubuntu 3.5.0-19-generic x86_64, процессор Intel Core i7-3930K CPU @ 3.20GHz × 12. (Нафига 12 ядер, если тесты запускать последовательно? Эхх…)
Код
Весь код доступен на github. Можете попробовать запустить самостоятельно, подробные инструкции есть в README файле. Даже нет — настоятельно рекомендую не верить мне, а проверить как поведут себя тесты на вашем окружении!
Tip: если хотите протестировать только часть платформ (например, не хотите устанавливать себе Erlang или PyPy), то это легко задается переменной окружения PLATFORMS.
Буду рад пулл-реквестам с реализацией парсеров на других языках (PHP? Java? .NET? Ruby?), постараюсь добавить в результаты (в первую очередь интересны нативные реализации — биндинги к libxml как правило не отличаются по скорости). Интересно было бы попробовать запустить тесты на каких-нибудь других интересных HTML файлах (большая вложенность тегов, различные размеры файлов).
Результаты
Вот сырые результаты измерений в виде CSV файлов results-1000.csv results-600.csv results-400.csv results-100.csv results-50.csv results-10.csv. Попробуем их проанализировать, для этого воспользуемся скриптом на языке R (находится в репозитории с бенчмарком в папке stats/).
Скорость
Для исследования зависимости скорости работы парсера от числа итераций, построим гистограммы зависимости [времени на обработку одной страницы] от [числа итераций]. Время на обработку одной страницы считаем как время работы парсера, разделенное на число итераций. В идеальном варианте скорость работы парсера не должна зависеть от числа итераций, а лучше — должна возрастать (за счет JIT например).
Все графики кликабельны! Не ломайте глаза!
Зависимость времени на обработку документа от числа итераций парсера (здесь и далее — для каждой HTML страницы отдельный график).
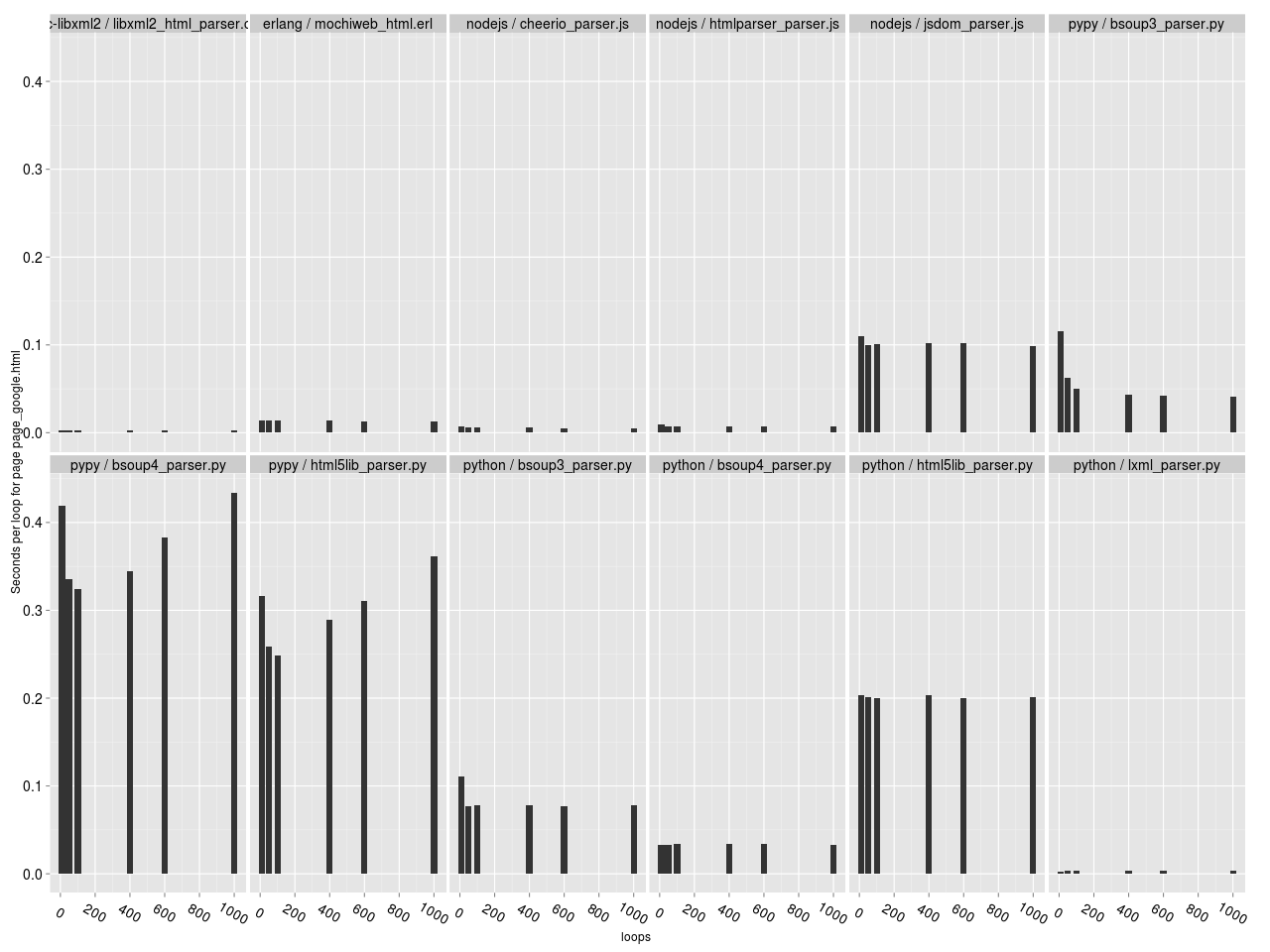

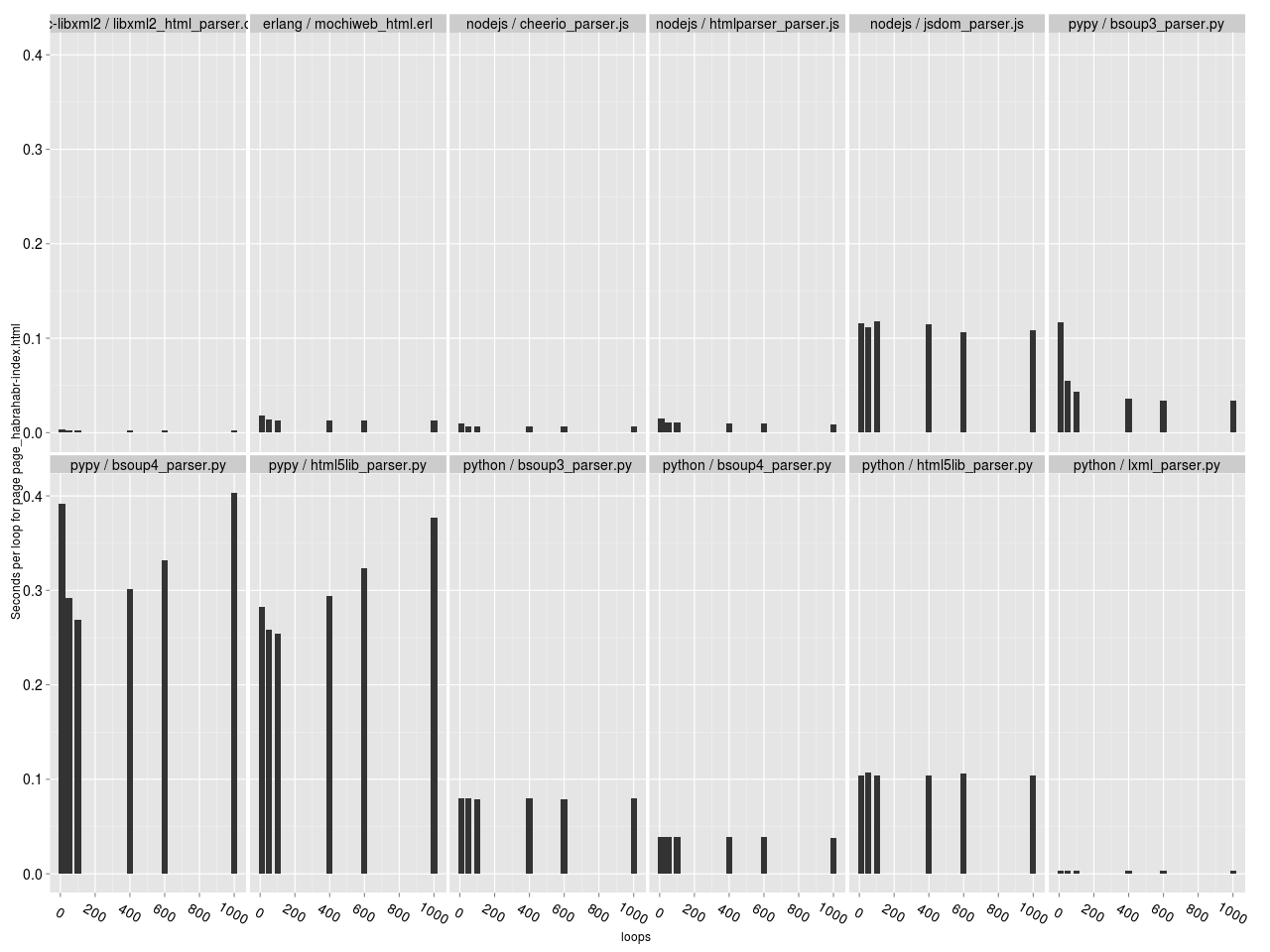
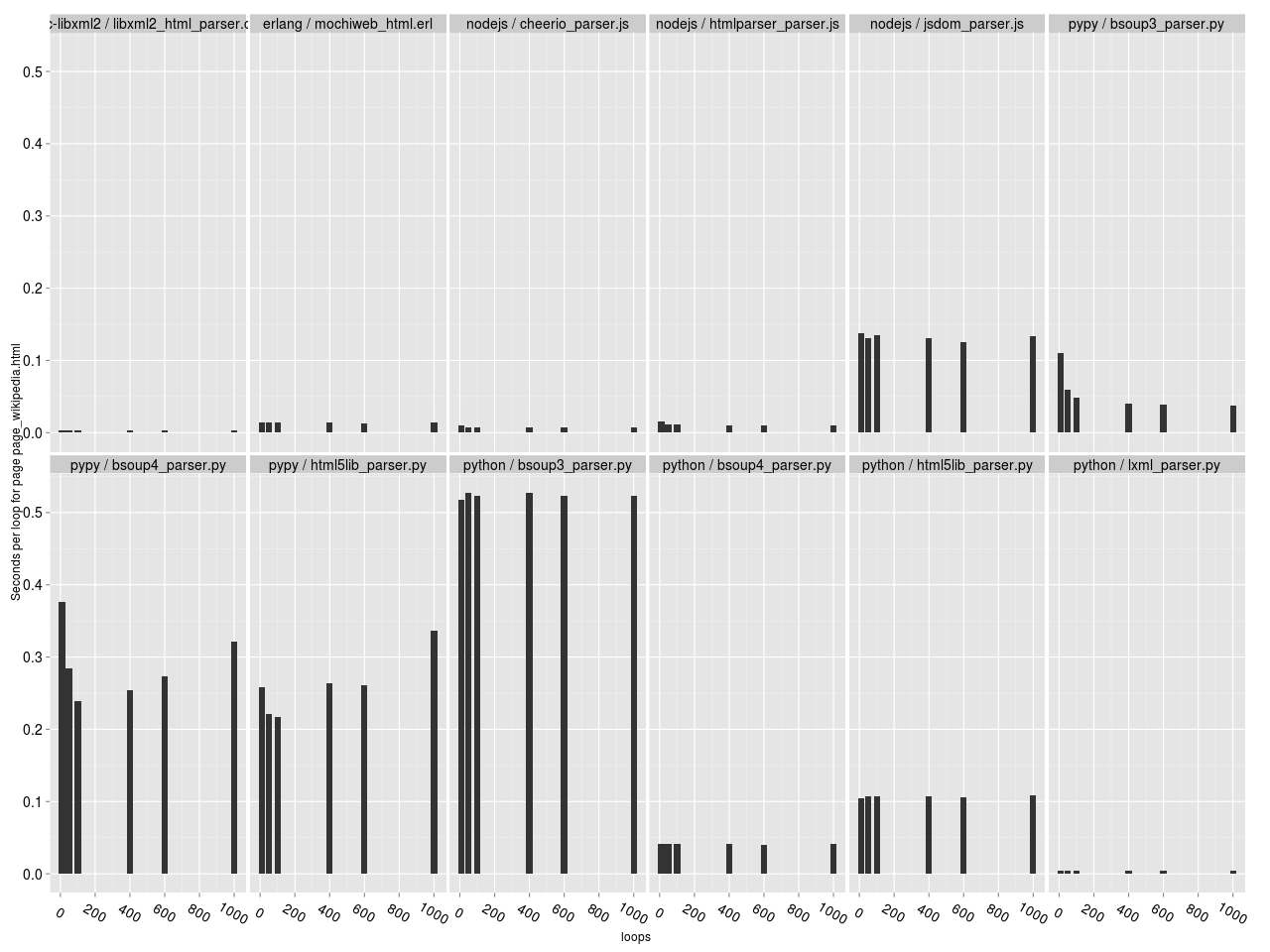
Столбики одинаковой высоты — хорошо, разной — плохо. Видно, что для большинства парсеров зависимости нет (все столбики одинаковой высоты). Исключение составляют только BeautifulSoup 4 и html5lib под PyPy; по какой-то причине у них с ростом числа итераций производительность снижается. То есть если ваш парсер на PyPy должен работать продолжительное время, то производительность будет постепенно снижаться. Неожиданно…
Теперь самый интересный график — средняя скорость обработки одной странички каждым парсером. Построим box-plot диаграмму.
Среднее время на обработку документа.
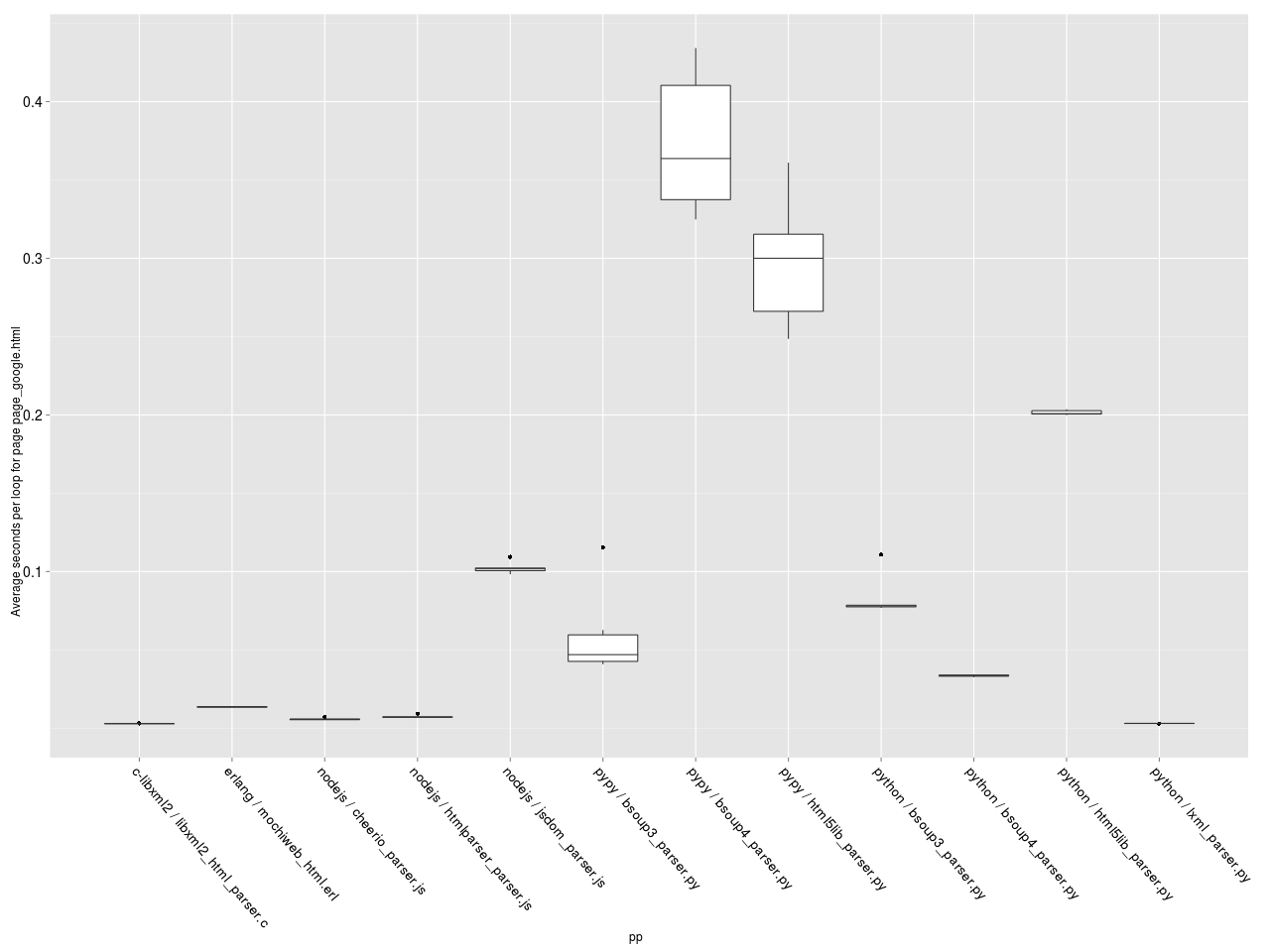

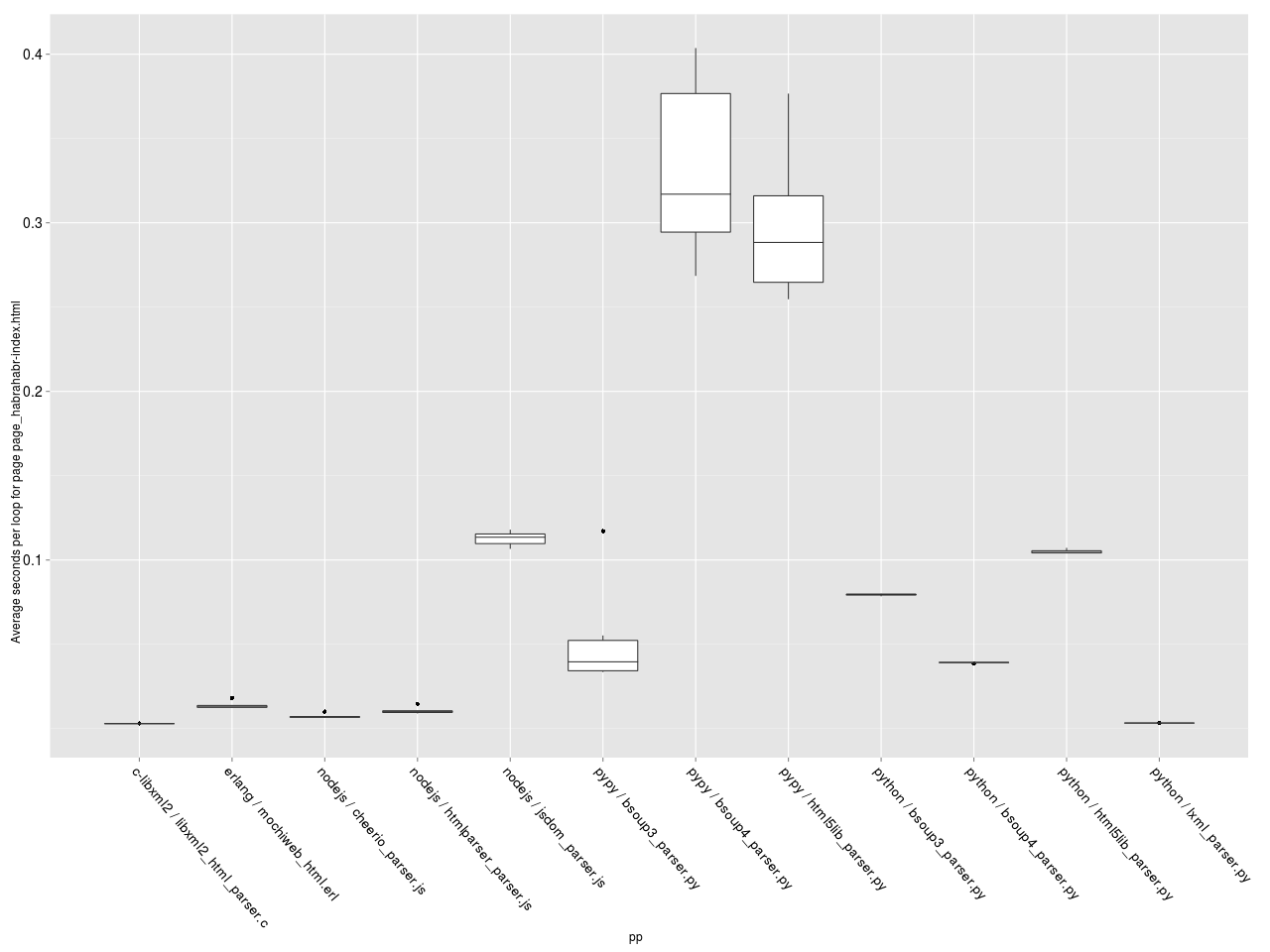
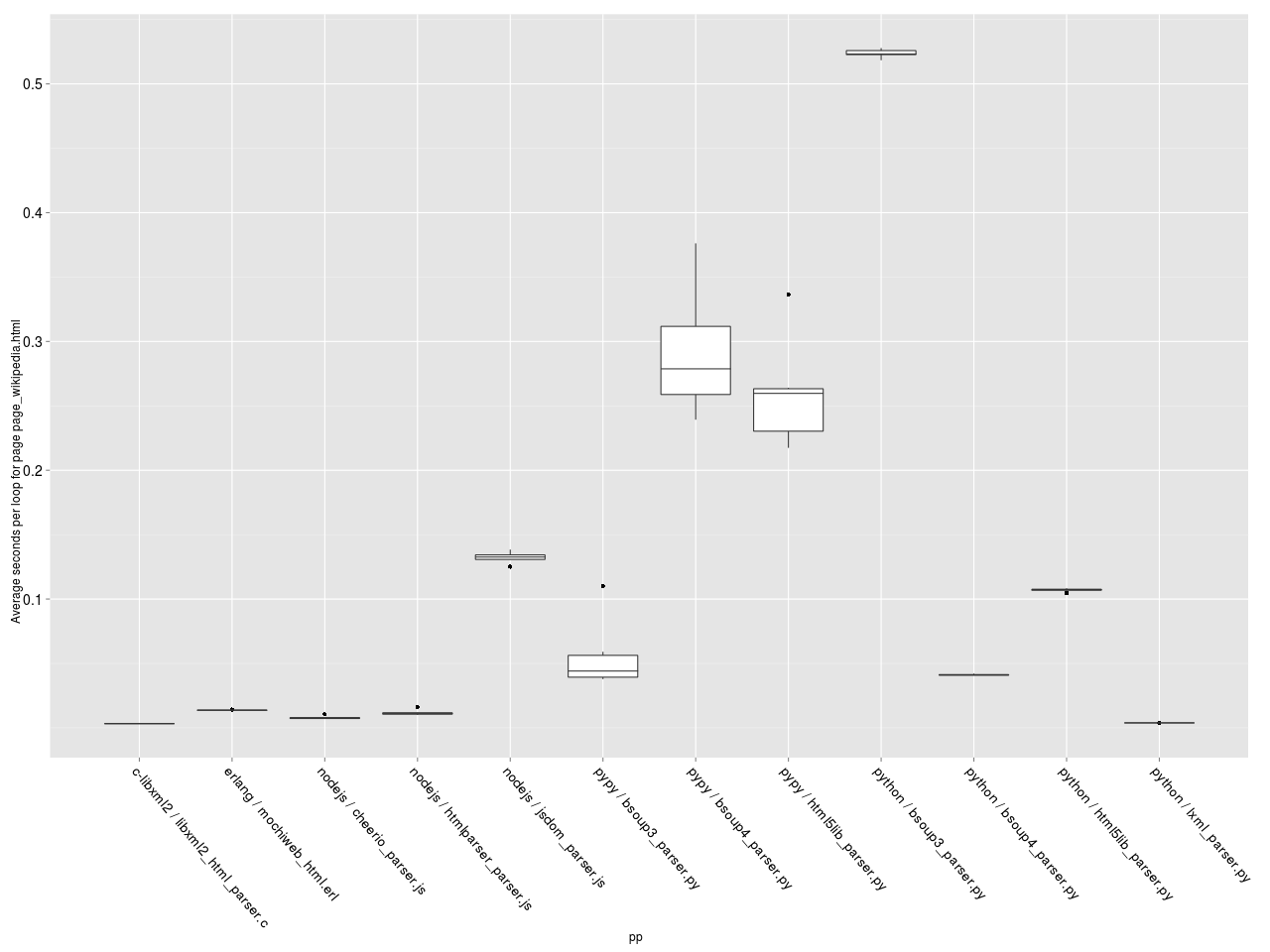
Чем выше находится бокс — тем медленнее работает парсер. Чем больше бокс по площади, тем больше разброс значений (т.е. выше зависимость производительности от числа итераций). Видно, что парсер на C лидирует, за ним следуют lxml.etree, почти вплотную парсеры на NodeJS и Erlang, потом bsoup3 парсер на PyPy, парсеры на CPython и потом с большим отрывом те же парсеры, запущенные на PyPy. Вот так сюрприз! PyPy всем сливает.
Ещё одна странность — bsoup 3 парсеру на Python чем-то не понравилась страничка википедии :-).
Пример табличных данных:
> subset(res, (file=="page_google.html") & (loops==1000))[ c("platform", "parser", "parser.s", "real.s", "user.s") ] platform parser parser.s real.s user.s 6 c-libxml2 libxml2_html_parser.c 2.934295 2.93 2.92 30 erlang mochiweb_html.erl 13.346997 13.51 13.34 14 nodejs cheerio_parser.js 5.303000 5.37 5.36 38 nodejs htmlparser_parser.js 6.686000 6.72 6.71 22 nodejs jsdom_parser.js 98.288000 98.42 98.31 33 pypy bsoup3_parser.py 40.779929 40.81 40.62 57 pypy bsoup4_parser.py 434.215878 434.39 433.91 41 pypy html5lib_parser.py 361.008080 361.25 360.46 65 python bsoup3_parser.py 78.566026 78.61 78.58 49 python bsoup4_parser.py 33.364880 33.45 33.43 60 python html5lib_parser.py 200.672682 200.71 200.70 67 python lxml_parser.py 3.060202 3.08 3.08
Память
Теперь посмотрим на использование памяти. Сперва посмотрим, как потребление памяти зависит от числа итераций. Снова построим гистограммы. В идеале все столбики одного парсера должны быть одинаковой высоты. Если потребление растет с увеличением числа итераций, то это указывает на утечки памяти или проблемы со сборщиком мусора.
Потребление памяти в зависимости от числа итераций парсера.


Занятно. Bsoup4 и html5lib под PyPy заняли по 5Гб памяти после 1000 итераций по 1Мб файлу. (Привел здесь только 2 графика, т.к. на остальных такая же картина). Видно, что с ростом числа итераций практически линейно растет и потребляемая память. Получается, что PyPy просто не совместим с Bsoup4 и html5lib парсерами. С чем это связано и кто виноват я не знаю, но зато понятно, что использование PyPy без тщательной проверки совместимости со всеми используемыми библиотеками — весьма рискованное занятие.
Выходит, что комбинация PyPy с этими парсерами выбывает. Попробуем убрать их с графиков:
Потребление памяти в зависимости от числа итераций парсера (без Bsoup4 и html5lib на PyPy).



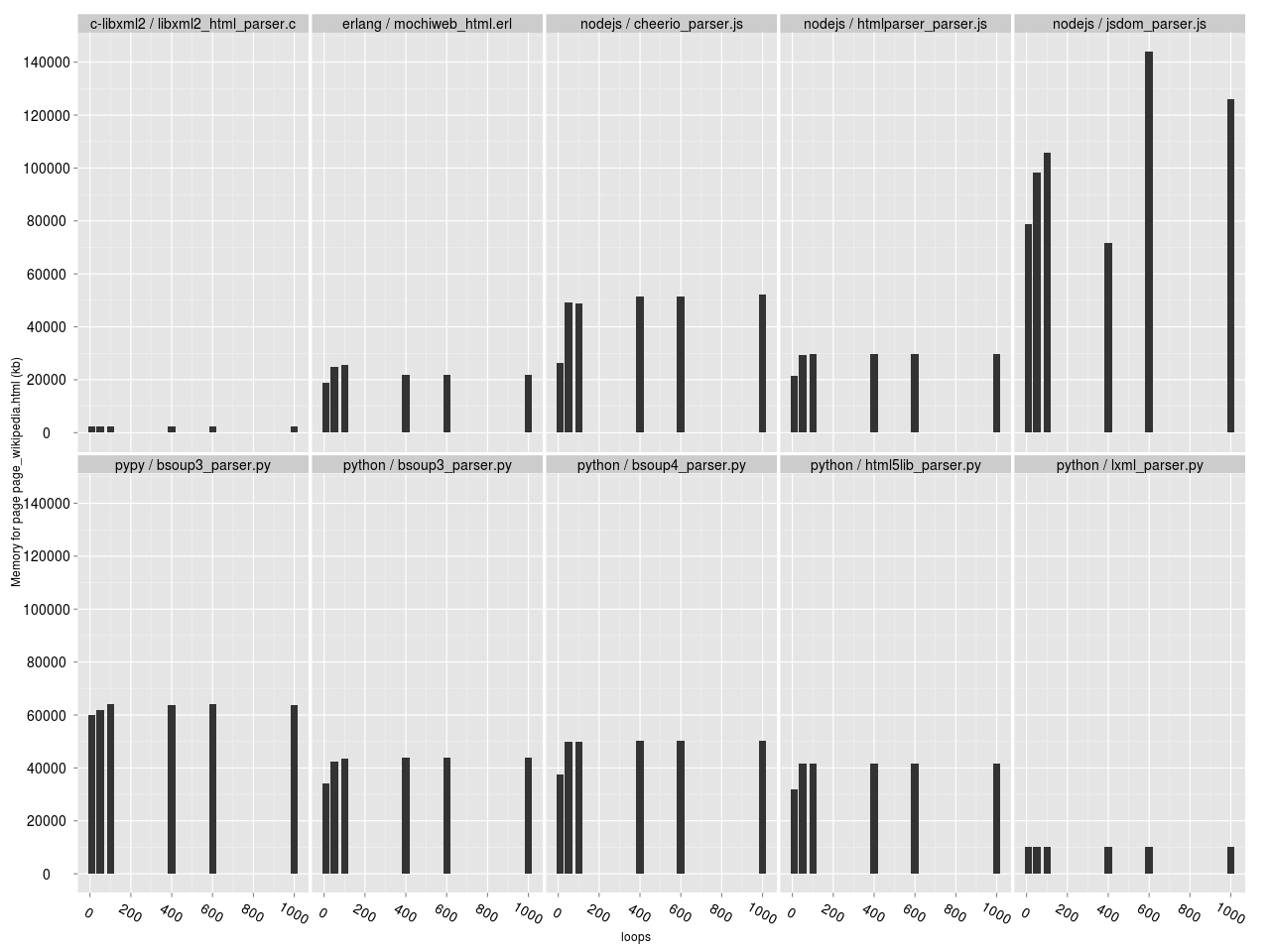
Видим, что для парсера на C все столбики практически идентичной высоты. То же самое для lxml.etree. Для большинства парсеров потребление памяти при 10 итерациях немного меньше. Возможно просто time не успевает её замерить. NodeJS парсер jsdom ведет себя довольно странно — у него потребление памяти для некоторых страниц скачет весьма случайным образом, но в целом виден рост потребления памяти со временем. Возможно какие-то проблемы со сборкой мусора.
Сравним усредненное потребление памяти для оставшихся парсеров. Построим box-plot.
Усредненное потребление памяти.


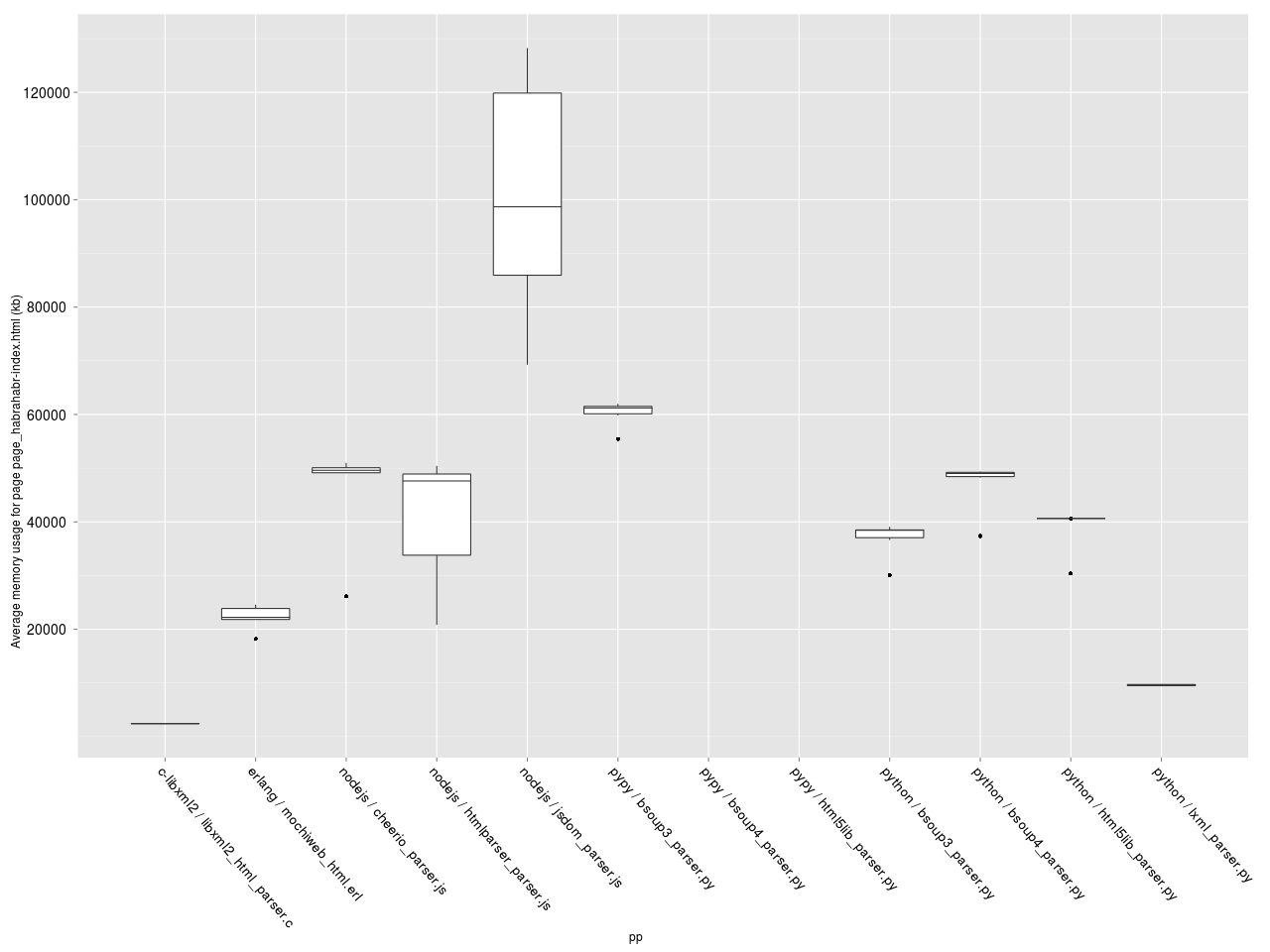
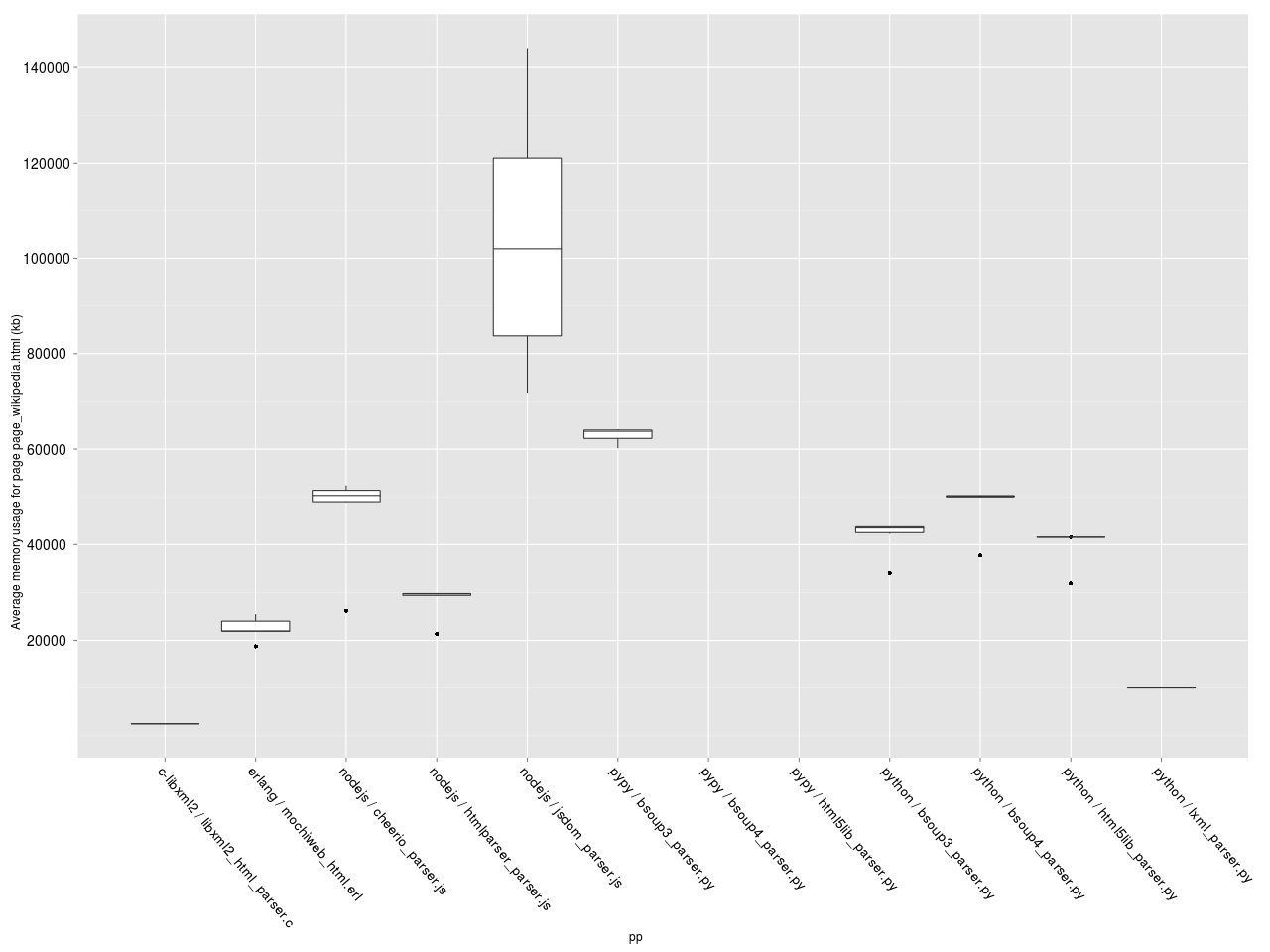
Видим, что расстановка примерно такая же, как в сравнении скорости, но у Erlang потребление памяти оказалось ниже, чем у NodeJS. lxml.etree требует памяти примерно в 2 раза больше, чем C libxml2, но меньше чем любой другой парсер. NodeJS парсер jsdom несколько выпадает из общей картины, потребляя ~ в 2 раза больше памяти, чем другие NodeJS парсеры — видимо у него значительный оверхед, связанный с созданием дополнительных атрибутов у элементов DOM дерева.
Пример табличных данных:
> subset(res, (file=="page_google.html") & (loops==1000))[ c("platform", "parser", "maximum.RSS") ] platform parser maximum.RSS 6 c-libxml2 libxml2_html_parser.c 2240 30 erlang mochiweb_html.erl 21832 14 nodejs cheerio_parser.js 49972 38 nodejs htmlparser_parser.js 48740 22 nodejs jsdom_parser.js 119256 33 pypy bsoup3_parser.py 61756 57 pypy bsoup4_parser.py 1701676 41 pypy html5lib_parser.py 1741944 65 python bsoup3_parser.py 42192 49 python bsoup4_parser.py 54116 60 python html5lib_parser.py 45496 67 python lxml_parser.py 9364
Оверхед на запуск программы
Это уже не столько тест HTML парсера, сколько попытка выяснить какую платформу стоит использовать для написания консольных утилит. Просто небольшое дополнение (раз у нас уже есть данные). Оверхед платформы — это время, которое программа тратит не на непосредственно работу, а на подготовку к ней (инициализация библиотек, считывание HTML файла и т.п.). Что бы его вычислить, вычтем из времени, которое вывела утилита time — «time.s», время, которое замерили вокруг цикла парсера — «parser.s».

Видно, что оверхед в большинстве случаев несущественный. Примечательно, что у Erlang он сравнимый с Python. Можно предположить, что он зависит от массивности библиотек, которые программа импортирует.
Выводы
Как видим — реализация на C впереди планеты всей (но и кода в ней получилось побольше).
Биндинг libxml2 к питону (lxml.etree.HTML) работает практически с такой же скоростью, но потребляет в 2 раза больше памяти (скорее всего оверхед собственно интерпретатора). Выходит, предпочтительный парсер на Python — это lxml.
Парсер на голом Erlang показывает на удивление высокие результаты, несмотря на приписываемые эрлангу «копирования данных на каждый чих» ©. Скорость сравнима с простыми парсерами на NodeJS и выше, чем у Python парсеров. Потребление памяти ниже только у C и lxml. Стабильность отличная. Такой парсер можно выпускать в продакшн (что я и сделал).
Простые парсеры на NodeJS работают очень быстро — в 2 раза медленнее сишной libxml. V8 работает крайне эффективно. Но памяти потребляют на уровне с Python, причем память расходуется не слишком стабильно (расход памяти может вырасти при увеличении числа итераций с 10 до 100, но потом стабилизируется). Парсер jsdom для простого парсинга явно не подходит, т.к. у него слишком высокие накладные расходы. Так что для парсинга HTML в NodeJS лучший выбор — cheerio.
Парсеры на чистом Python сливают как по скорости, так и по потреблению памяти, причем результаты сильно скачут на разных страницах. Но при этом ведут себя стабильно на разном количестве итераций (GC работает равномерно?)
Но больше всех удивил PyPy. То ли какие-то проблемы с GC, то ли задача для него не подходящая, то ли парсеры реализованы неудачно, то ли я где-то накосячил, но производительность парсеров на PyPy снижается с ростом числа итераций, а потребление памяти линейно растет. Bsoup3 парсер более-менее справляется, но его показатели находятся на уровне с CPython. Т.е. для парсинга на PyPy подходит только Bsoup3, но заметных преимуществ перед CPython он не дает.
Ссылки
Код бенчмарка
Document Object Model
Присылайте свои реализации! Это очень просто!
ссылка на оригинал статьи http://habrahabr.ru/post/163979/
Добавить комментарий