: под катом речь пойдёт не про облака, а про OCR") Мы уже анонсировали крутую штуку под названием ABBYY Cloud OCR SDK. Она постепенно набирает популярность — на днях сервис распознал миллионную страницу. Кажется, это хороший повод повысить OCR-грамотность настоящих и будущих пользователей. Итак, начнём.
Мы уже анонсировали крутую штуку под названием ABBYY Cloud OCR SDK. Она постепенно набирает популярность — на днях сервис распознал миллионную страницу. Кажется, это хороший повод повысить OCR-грамотность настоящих и будущих пользователей. Итак, начнём.
Сегодня речь пойдёт о существовании двух видов распознавания – Full Page OCR и Field-level OCR. Эти подходы отличаются не только ценой, между ними есть фундаментальные различия в том, зачем они нужны. К сожалению, далеко не все начинающие разработчики в области OCR понимают эти различия, и вынуждены учиться на ошибках. И более того, многие крупные и хорошо известные игроки на рынке Data Capture продолжают до сих пор использовать однопроходный алгоритм там, где будет хорош многопроходный (т.е. Full Page OCR вместо Field-level). Причины такого их поведения банальны: приложение написано много лет назад, и им слишком дорого переделывать архитектуру, UI, заново обучать своих партеров. И они вынуждены расплачиваться за это ограничениями в области качества распознавания.
Потребность в Field-level OCR возникает в тот момент, когда мы хотим извлечь из документа какие-то полезные данные. Такой сценарий обработки в индустрии принято называть Data Capture. Например, мы хотим извлечь из Invoice название компании-контрагента, сумму, которую нужно оплатить и дату, до которой необходимо произвести оплату. Причем, на подобных документах бывает много сумм и дат, и тут важно не промахнуться и выбрать правильную. Просто представьте себе последствия того, что например, при оплате вместо суммы счета будет использован номер телефона.
Обычно процесс обработки подобных документов выглядит вот так:

В зависимости от типа обрабатываемых документов, могут применяться различные методы поиска полей. В самом простом случае – машиночитаемых формах, которые «совпадают на просвет», координаты полей заранее известны, остается только совместить лист с шаблоном, для чего используются различные «реперы», как например вот эти черные квадраты.

В случае инвойсов такой метод уже не проходит. Здесь применяются уже более сложные методики, которые основаны на поиске ключевых слов вроде «Invoice #», «Due date:», и уже отталкиваясь от них определяются зоны на документе, в которых и находятся требуемые поля. При этом используются предварительные знания о том, как обычно устроен инвойс данной компании.
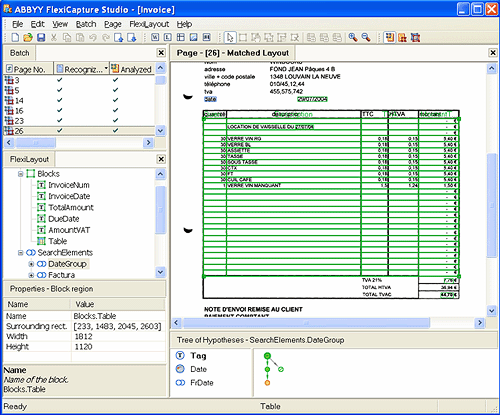
Вот в этот момент, когда мы уже определили местоположения полей или, (как в наиболее продвинутых системах вроде FlexiCapture) несколько возможных гипотез местоположения полей – самое время принять решение – как мы будем извлекать текст этих полей.
Предположим, местоположение полей мы определили правильно, и в поле Total Amount у нас все-таки сумма, а не номер телефона. Но у нас все еще остается отличный шанс поставить не там точку в сумме «$1.000,00», или просто не заметить запятую, и оплатить сто тысяч вместо тысячи долларов. Именно поэтому к извлечению подобных данных обычно относятся крайне серьезно, и вопрос «сколько процентов ошибок распознавания» уже заменяется вопросом «сколько времени требуется на ручную верификацию». Качество технологии тут меряется уже не в количестве неправильных символов, а в количестве ручного труда, необходимого на исправление ошибок распознавания системы. Причем это связано не только с самой точностью распознавания, а еще и с ее умением правильно говорить «что-то я не уверена про этот символ», но это тема для отдельной статьи.
Как я сказал, есть класс приложений, которые используют лишь один проход. Уже на этапе определения типа документа происходит полное распознавание страницы. Ее текст служит основой для принятия решения о типе документа (например, поискав типичные ключевые слова для данного типа), а затем и поиска опорных элементов и определения местоположения полей. И этот же текст в итоге используется для извлечения данных из полей.
На наш же взгляд, в этот самый момент есть смысл еще раз распознать конкретные поля, но уже задав более точно параметры распознавания. Дело в том, что значительно сузив возможное множество распознанных значений, мы можем существенно повысить точность как распознавания, так и определения неуверенно распознанных символов. Что в итоге положительно сказывается на основном параметре системы – количество ручного труда для ввода и обработки документов.
В частности, зная, какое поле мы сейчас будем распознавать, мы можем определить следующие параметры:
· Задать регулярное выражение или специальный язык для дат, сумм, банковских реквизитов, и так далее.
· Задать словарь возможных значений, в случае если данное поле имеет ограниченный набор текстовых значений (название компании, номенклатура и т.д.)
· Задать параметры сегментации текста (одна строка или несколько, моноширинный текст или нет, и т.п.)
· Указать тип текста, если поле напечатано особым шрифтом вроде OCR-A и т.п.
· Применить специальные настройки обработки изображения (например, если сам текст напечатан другим цветом, или часто на него попадает печать организации или подпись)
В принципе, вся эта настройка заключается в отключении различной автоматики, которая есть в любом высококачественном OCR, и практически всегда работает правильно. Но как я уже сказал, в сценарии DataCapture не достаточно уровня качеств «практически всегда работает правильно». Наличие этого «практически» приводит к тому, что результаты распознавания сначала перепроверяются автоматическими правилами, а затем еще и в ручную операторами, а иногда и в несколько этапов, так как и люди тоже, к сожалению, «практически никогда не ошибаются».
Давайте рассмотрим такой пример. Вот, к примеру, отсканированный кассовый чек.

Если присмотреться внимательнее, то мы увидим, что это настоящий кошмар для OCR. Буквы слипшиеся и не полностью пропечатавшиеся.

И тем не менее, современные технологии OCR могут справиться и с таким. Если просто открыть это в ABBYY FineReader 11 и распознать с настройками по умолчанию, мы увидим, что даже из этого ужаса можно вполне кое-что вытащить. В целом, он справился неплохо, хотя совершил массу ошибок. В частности, в особо интересующей нас части – таблице с товарами и ценой, одно из значений распозналось как «$o.ce» вместо «$0.00».

Но почему, скажете вы? Ведь очевидно, что это именно «$0.00»! Но почему это очевидно вам? Потому что вы, поглядев на изображение, понимаете, что это кассовый чек, а в его центре идет таблица, и в третьей колонке таблицы идут цифры, а не абракадабра. Но откуда OCR программа могла это знать? Ведь в левой колонке же могут встречаться полные абракадабры вроде «5UAMM575», почему бы им не встретиться в третьей тоже? Программа по магазинам не ходит, и покупки не совершает, и с настройками по умолчанию она с равной вероятностью ожидает на вход как чеки, так газеты, так и журнальные статьи со гламурной версткой. В случае двухпроходного алгоритма мы определяем, что вообще говоря это чек, кроме того мы можем определить его структуру, а также запомнить, что для чеков компании «AJ Auto Detailing Inc.» в третьей колонке всегда располагаются суммы формата $XXX.XX и никаких букв там быть не может. Таким образом, повторно распознав только эти поля, задав соответствующие ограничения (например, через регулярное выражение), мы гарантированно избавимся от подобных ошибок.
В случае однопроходного алгоритма мы вынуждены полностью полагаться на автоматику, и задавать максимально широкие настройки обработки изображения, так как распознать нужно не только эти поля, но еще и весь остальной текст тоже, а так же и для всех возможных типов документов, и все за один раз. Это является серьезным лимитирующим фактором, который разработчики пытаются компенсировать более умными правилами последующей обработки и проверки результатов, более эффективным процессом ручной верификации и т.п. Все это, безусловно, тоже важно, но если есть возможность значительно уменьшить количество ошибок сразу, почему бы не воспользоваться?
Если кроме цен на товары нас еще интересуют и их номенклатуры, то подключив словарь имеющихся номенклатур для данного поставщика, можно так же пройтись по этим полям тоже, значительно повысив качество данных. Но почему же не подключить словарь сразу? Но вначале ведь мы даже не знаем поставщика, а значит, придется подключать сразу все словари всех поставщиков, а от этого результат вполне может только еще больше ухудшиться.
К слову, в этом споре обычно приводят аргумент времени обработки, как объяснение, почему они не используют второй проход. Но дело в том, что как раз этот аргумент именно в пользу двухпроходного распознавания, и вот почему. При повторном распознавании обрабатывается ничтожно малая часть площади исходного документа, да еще и добрая доля автоматики при этом отключена и переведена в ручной режим. Если распознавание происходит на локальном сервере, то время дополнительного прохода распознавания исчезающе мало по сравнению со временем первого прохода. Однако, в двухпроходном сценарии, первый проход используется только для извлечения опорного текста и классификации, которые толерантны к ошибкам распознавания за счет применения нечетких алгоритмов сравнения. Сам же текст в результаты напрямую не идет, а значит, вместо тщательного режима распознавания можно использовать быстрый, тем самым сократив время в два и более раза.
В случае же распознавания в облаке действительно, мы вынуждены будем делать два обращения к серверу вместо одного. Но и в этом случае аргумент про возможность достичь более высокое качество остается в силе.
Андрей Исаев,
директор департамента продуктов для разработчиков.
ссылка на оригинал статьи http://habrahabr.ru/company/abbyy/blog/173571/
Добавить комментарий