WAS – система облачного хранилища, предоставляющая клиентам возможность хранить практически неограниченные объёмы данных в течение любого периода времени. WAS была представлена в production-версии в ноябре 2008. Ранее она использовалась для внутренних целей Microsoft для таких приложений, как, например, хранение видео, музыки и игр, хранения медицинских записей и др. Статья написана по мотивам работы с сервисами хранилища и посвящена принципам работы этих сервисов.
Клиенты WAS имеют доступ к свои данным отовсюду в любое время и платят только за то, что используют и хранят. Хранящиеся в WAS данные используют как локальную, так и географическую репликацию для реализации восстановления после серьезных сбоев. На данный момент хранилище WAS состоит из трёх абстракций – блобов (файлов), таблиц (структурированного хранилища) и очередей (доставка сообщений). Эти три абстракции данных покрывают необходимость в различных типах хранимых данных для большинства приложений. Обычным сценарием использования является сохранение данных в блобах, с помощью очередей же происходит передача данных в эти блобы, промежуточные же данные, состояние и подобные временные данные сохраняются в таблицах либо блобах.
Во время разработки WAS были учтены пожелания клиентов, и наиболее существенными характеристиками архитектуры стали:
- Строгая согласованность – множество клиентов хотят иметь строгую согласованность, особенно это касается корпоративных клиентов, переносящих инфраструктуру в облако. Они также хотят иметь возможность совершать операции чтения, записи и удаления согласно некоторым условиям для оптимистичного контроля над строго согласованными данными – для этого Windows Azure Storage предоставляет то, что CAP-теоремой (Consistency, Availability, Partition-tolerance) описывается как сложнодостижимое в один момент времени: строгую согласованность, высокую доступность и Partition Tolerance.
- Глобальные и высокомасштабируемые пространства имён – для упрощения использования хранилища в WAS реализовано глобальное пространство имен, которое позволяет хранить данные и обращаться к ним из любой точки земного шара. Так как одной из главных целей WAS является предоставление возможности хранения больших массивов данных, это глобальное пространство имен должно быть способным адресовать экзабайты данных.
- Восстановление после сбоев – WAS сохраняет данные клиентов в нескольких датацентрах, которые расположены за несколько сотен километров друг от друга, и эта избыточность предоставляет эффективную защиту от потери данных из-за различных ситуаций, таких как землетрясения, пожары, торнадо и так далее.
- Мультитенантность и стоимость хранилища – для сокращения стоимости хранилища множество клиентов обслуживаются из одной разделяемой инфраструктуры хранилища, и WAS с помощью этой модели, когда хранилища множества различных клиентов с различными необходимыми им объёмами хранилища группируются в одном месте, существенно снижает общий необходимый объем предоставляемого хранилища, чем если бы WAS выделял отдельное оборудование каждому клиенту.
Рассмотрим подробнее глобальное партициируемое пространство имён. Ключевой целью системы хранилища Windows Azure является предоставление одного глобального пространства имён, которое позволило бы клиентам размещать и масштабировать любое количество данных в облаке. Для предоставления глобального пространства имён WAS использует DNS как часть пространства имён, и пространство имён состоит из трёх частей: имени аккаунта хранилища, имени партиции и имени объекта.
Пример:
http(s)://AccountName..core.windows.net/PartitionName/ObjectName
AccountName – имя аккаунта хранилища, выбранное клиентом, является частью DNS-имени. Эта часть используется для нахождения главного кластера хранилища и, собственно, датацентра, в котором хранятся необходимые данные и куда необходимо посылать все запросы на данные для этого аккаунта. Клиент в одном приложении может использовать несколько имен аккаунтов и хранить данные в совершенно различных местах.
PartitionName — имя партиции, определяющее расположение данных при получении запроса кластером хранилища. PartitionName используется для вертикального масштабирования доступа к данным по нескольким узлам хранилища в зависимости от трафика.
ObjectName – если в партиции множество объектов, для уникальной идентификации объекта используется ObjectName. Система поддерживает атомарные транзакции для объектов в пределах одной PartitionName. Значение ObjectName опционально, для некоторых типов данных PartitionName может уникально идентифицировать объект внутри аккаунта.
В WAS можно использовать для блобов полное имя блоба в качестве PartitionName. В случае таблиц необходимо учитывать, что каждая сущность в таблице имеет первичный ключ, состоящий из PartitionName и ObjectName, что позволяет группировать сущности в одну партицию для осуществления атомарной транзакции. Для очередей PartitionName является значение имени очереди, каждое сообщение же, помещённое в очередь, имеет собственное ObjectName, уникально идентифицирующее сообщение в пределах очереди.
Архитектура WAS
Fabric-контроллер занимается управлением, мониторингом, обеспечением отказоустойчивости и многими другими задачами в датацентре. Это механизм, который знает обо всём, что происходит в системе, начиная с сетевого подключения и заканчивая состоянием операционных систем на виртуальных машинах. Контроллер постоянно поддерживает связь с собственными агентами, установленными на операционных системах и посылающих полную информацию о том, что происходит с этой операционной системой, включая версию ОС, конфигурации сервиса, пакеты конфигурации и так далее. Что касается хранилища, то Fabric Controller выделяет ресурсы и управляет репликацией и распределением данных по дискам, а также балансировкой нагрузки и трафика. Архитектура Windows Azure Storage представлена на рисунке 1.
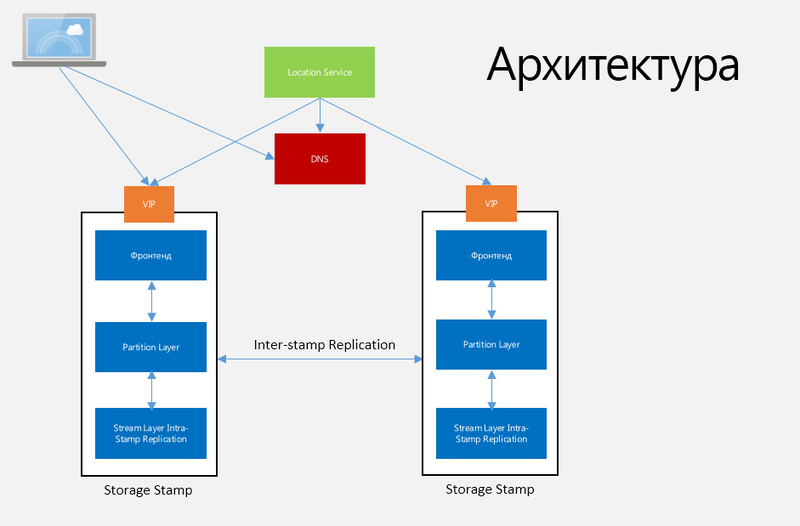
Рис. 1. Архитектура Windows Azure Storage
Storage Stamp (SS). Под этим термином подразумевается кластер, состоящий из N реков (rack) узлов хранилища, где каждый рек находится в собственном домене ошибок с избыточной мощностью сети и питания. Кластера обычно имеют в своем составе от 10 до 20 реков с 18 узлами на рек, при этом первое поколение Storage Stamp-ов содержало около 2 петабайт. Следующее – до 30 петабайт. Storage Stamp также стараются делать наиболее используемым, то есть процент использования каждого SS должен быть равен примерно 70 в терминах использования емкости, количества транзакций и пропускной способности, но не более 80, так как должен быть резерв для более эффективного выполнения дисковых операций. Как только использование SS доходит до 70%, Location Service мигрирует аккаунты на другие SS, используя меж-SS-репликацию.
Location Service (LS). Данный сервис управляет всеми SS и пространствами имён для аккаунтов для всех SS. LS распределяет аккаунты по SS и реализует балансировку нагрузки и другие задачи по управлению. Сам же сервис распределён по двум географически разделенным местам для собственной же безопасности.
Stream Layer (SL). Данный слой хранит данные на диске и отвечает за распределение и репликацию данных по серверам для сохранения данных внутри SS. SL можно рассматривать как слой распределенной файловой системы внутри каждого SS, понимающего файлы (“streams”), как хранить эти файлы, реплицировать и так далее. Данные хранятся на SL, но доступны с Partition Layer. SL предоставляет, по сути, некоторый интерфейс, используемый только PL, и файловую систему с API, позволяющую выполнять операции записи только типа Append-Only, что даёт возможность PL открывать, закрывать, удалять, переименовывать, читать, добавлять части и объединять большие файлы “streams”, упорядоченные списки больших кусков данных, называемых “extents” (рис. 2).

Рис. 2. Наглядное изображение Stream, состоящего из экстентов
Stream может содержать несколько указателей на экстенты, и каждый экстент содержит набор блоков. При этом экстенты могут быть «запечатаны» (sealed), то есть добавлять к ним новые куски данных нельзя. Если происходят попытки чтения данных из Stream, то данные будут получены последовательно от экстента Е1 к экстенту Е4. Каждый stream рассматривается Partition Layer как один большой файл, и содержание Stream может быть изменено или прочтено в random-режиме.
Блок. Минимальная единица данных, доступная для записи и чтения, которая может быть до определенного N байт. Все записываемые данные записываются в экстент в виде одного или более объединённых блоков, при этом блоки не обязаны быть одного размера.
Экстент. Экстентами называются единицы репликации на Stream Layer, и по умолчанию в Storage Stamp хранится три реплики для каждого экстента, хранящегося в NTFS-файле и состоящего из блоков. Размер экстента, используемого Partition Layer, равен 1 гб, меньшие же объекты дополняются Partition Layer к одному экстенту, а порой и к одному блоку. Для хранения очень больших объектов (например, блобов), объект разбивается Partition Layer на несколько экстентов. При этом, разумеется, Partition Layer следит за тем, к каким экстентам и блокам принадлежат какие объекты.
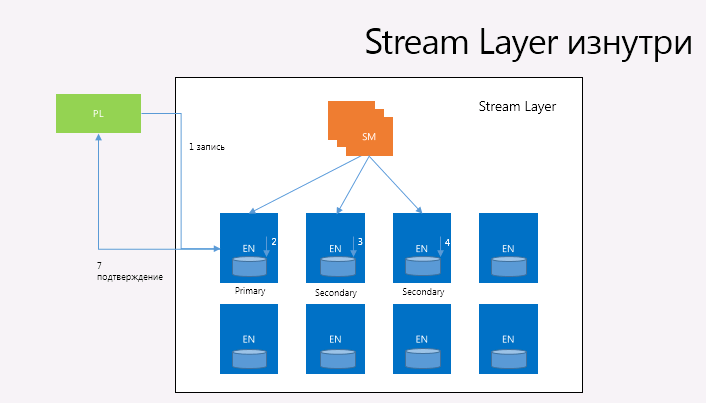
Stream Manager (SM). Stream Manager отслеживает пространство имён stream-ов, управляет состоянием всех активных stream и экстентов и их расположением между Extend Node, следит за здоровьем всех Extend Node, создаёт и распределяет экстенты (но не блоки – о них Stream Manager ничего не знает), а также осуществляет ленивую перерепликацию экстентов, реплики которых были потеряны из-за аппаратных ошибок или просто недоступных и собирает «мусорные экстенты». Stream Manager периодически опрашивает и синхронизирует состояние всех Extend Node и экстенты, которые они хранят. Если SM обнаруживает, что экстент разреплицирован на менее чем ожидаемое количество EN, SM производит перерепликацию. При этом объем состояния, если его так можно назвать, может быть достаточно мал для того, чтобы умещаться в памяти одного Stream Manager. Единственным потребителем и клиентов Stream Layer является Partition Layer, и они так спроектированы, что не могут использовать более 50 миллионов экстентов и не более 100.000 Stream для одного Storage Stamp (блоки не берутся в расчет, так как их может быть совершенно неисчислимое количество), что вполне умещается в 32 гигабайта памяти Stream Manager.
Extent Nodes (EN). Каждый EN управляет хранилищем для набора реплик экстентов, назначенных для них SM. EN имеет N подсоединенных дисков, которые находятся под полным его контролем для сохранения реплик экстентов и их блоков. При этом EN ничего не знает о Stream (в отличие от Stream Manager, который ничего не знает о блоках) и управляет только экстентами и блоками, которые (экстенты) являются, по сути, файлами на дисках, содержащими блоки данных и их контрольные суммы + карту ассоциаций сдвигов в экстентах к соответствующим блокам и их физическому расположению. Каждый EN содержит некоторое представление о своих экстентах и о том, где находятся реплики для конкретных экстентов. Когда на конкретные экстенты более не ссылается ни один из Stream-ов, Stream Manager собирает эти «мусорные» экстенты и уведомляет EN о необходимости освободить пространство. При этом данные в Stream могут быть только добавлены, существующие же данные модифицировать нельзя. Операции добавления атомарны – или весь блок данных добавляется, или не добавляется ничего. В один момент времени может быть добавлено несколько блоков в пределах одной атомарной операции «добавление нескольких блоков». Минимальным размером, который доступен для чтения из Stream, является один блок. Операция же добавления нескольких блоков позволяет клиенту записывать большие объемы последовательных данных в рамках одной операции.
Каждый экстент, как уже было сказано, имеет определенный потолок для размера, и когда он заполняется, экстент запечатывается (sealed) и дальнейшие операции записи оперируют новых экстентом. В запечатанный экстент добавлять данные нельзя, и он является неизменяемым (immutable).
Есть несколько правил относительно экстентов:
1. После добавления записи и подтверждения операции клиенту, все дальнейшие операции чтения этой записи из любой реплики должны возвращать одни и те же данные (данные неизменяемы).
2. После запечатывания экстента все операции чтения из любой запечатанной реплики должны возвращать одно и то же содержание экстента.
Например, когда Stream создаётся, SM назначает первому экстенту три реплики (одну primary и две secondary) для трех Extent Nodes, которые, в свою очередь, выбираются SM для случайного распределения между различными доменами обновлений и ошибок и учитывая возможность балансировку нагрузки. Кроме этого SM решает, какая реплика будет Primary для экстента и все операции записи в экстент совершаются сначала на primary EN, и только после этого с primary EN запись совершается на два secondary EN. Primary EN и расположение трех реплик не изменяется для экстента. Когда SM размещает экстент, информация по экстенту отправляется обратно клиенту, который после этого знает, какие EN содержат три реплики и которая из них является primary. Эта информация становится частью метаданных Stream и кэшируется на клиенте. Когда последний экстент в Stream запечатывается, процесс повторяется. SM размещает еще один экстент, который теперь становится последним экстентом в Stream, и все новые операции записи совершаются на новом последнем экстенте. Для экстента каждая операция добавления реплицируется три раза по всем репликам экстента, и клиент отправляет все запросы на запись на primary EN, но операции чтения могут быть совершены с любой реплики, даже для незапечатанных экстентов. Операция добавления посылается на primary EN, и primary EN ответственна за определение сдвига в экстенте, а также упорядочивании всех операций записи в том случае, если происходит параллельная запись в один экстент, отправку операции добавления с необходимым сдвигом на два secondary EN и посылке подтверждения операции клиенту, которое посылается только в том случае, когда операция добавления была подтверждена на всех трёх репликах. Если же одна из реплик не отвечает или происходит (или произошла) какая-либо аппаратная ошибка, клиенту возвращается ошибка записи. В этом случае клиент связывается с SM и экстент, в который происходила операция записи, запечатывается SM.
SM после этого размещает новый экстент с репликами на других доступных EN и отмечает этот экстент как последний в stream, и информация об этом возвращается клиенту, который продолжает совершать операции добавления в новый экстент. Необходимо упомянуть, что вся последовательность действий по запечатыванию и размещению нового экстента выполняется в среднем всего 20 миллисекунд.
Что касается самого процесса запечатывания. Для того, чтобы запечатать экстент, SM опрашивает все три EN об их текущей длине. В процессе запечатывания два сценария – либо все реплики одного размера, либо какая-то из реплик длиннее или короче других. Вторая ситуация возникает только при ошибке операции добавления, когда какой-то из EN (но не все) не были доступны. При запечатывании экстента SM выбирает самую короткую длину, основываясь на доступных EN. Это позволяет запечатать экстенты так, что все изменения, подтвержденные для клиента, будут запечатаны. После запечатывания подтвержденная длина экстента более не изменяется и, если SM не может связаться с EN во время запечатывания, но затем EN становится доступным, SM принуждает этот EN синхронизироваться к подтвержденной длине, что приводит к идентичному набору бит.
Однако здесь может возникать другая ситуация – SM не может связаться с EN, однако Partition Server, который является клиентом, может. Partition Layer, о котором немного позже, имеет два режима чтения – чтение записей в известных позициях и с помощью итерации по всем записям в stream. Что касается первого — Partition layer использует два типа Stream – запись и блоб. Для этих Stream операции чтения всегда происходят для определенных позиций (экстент+сдвиг, длина). Partition Layer производит операции чтения для этих двух типов, используя информацию о позиции, возвращенную после предыдущей успешной операции добавления на Stream Layer, что случается только тогда, когда все три реплики отрапортовали об успешном выполнении операции добавления. Во втором случае, когда все записи в Stream перебираются последовательно, каждая партиция имеет два отдельных Stream (метаданные и лог подтверждения), которые Partition Layer будет читать последовательно с начала и до конца.
В Windows Azure Storage введён механизм, позволяющий сэкономить на занятом дисковом пространстве и трафике, не снижая при этом уровень доступности данных, и называется он erasure codes. Суть этого механизма заключается в том, что экстент разбивается на N примерно равных по размеру фрагментов (на практике это опять же файлы), после чего по алгоритму Рида-Соломона добавляется M фрагментов кодов, корректирующих ошибку. Что это значит? Любые X из N фрагментов равны по размеру оригинальному файлу, для восстановления же первоначального файла достаточно собрать X любых фрагментов и декодировать, остальные же N-X фрагментов могут быть удалены, нарушены и так далее. До тех пор, пока в системе хранится больше чем M фрагментов кодов, корректирующих ошибку, система может полностью восстановить оригинальный экстент.
Подобная оптимизация запечатанных экстентов очень важна при гигантских объемах данных, хранящихся в облачном хранилища, так как позволяет сократить стоимость хранения данных с трёх полных реплик исходных данных до 1.3-1.5 исходных данных в зависимости от количества используемых фрагментов, а также позволяет увеличить «устойчивость» данных по сравнению с хранением трех реплик внутри Storage Stamp.
При совершении операций записи для экстента, у которого есть три реплики, все операции ставятся на исполнение с определенным значением времени и, если операция не выполнена за это время, эта операция не должна быть выполнена. Если EN определяет, что операция чтения не может быть полностью выполнена за определенное время, он сразу же сообщает об этом клиенту. Этот механизм позволяет клиенту обратиться с операцией чтения к другому EN.
Аналогично с данными, для которых применяется erasure coding – когда операция чтения не успевает выполниться за временной промежуток из-за большой нагрузки, эта операция может не применяться для чтения полного фрагмента данных, но может воспользоваться возможностью реконструкции данных и в этом случае операция чтения обращается ко всем фрагментам экстента с erasure code, и первые N ответов будут использованы для реконструкции необходимого фрагмента.
Обращая внимание на то, что система WAS может обслуживать очень большие Streams, может возникать следующая ситуация: некоторые физические диски обслуживают и замыкаются на обслуживании больших операций чтения или записи, начиная обрезать пропускную способность для других операций. Для предотвращения подобной ситуации WAS не назначает диску новые I/O-операции тогда, когда ему уже назначены операции, которые могут выполняться более 100 миллисекунд или тогда, когда уже назначенные операции были назначены, но не выполнились за 200 миллисекунд.
Когда данные определяются Stream Layer как записываемые, используется дополнительный целый диск либо SSD в качестве хранилища для журнала всех операций записи на EN. Диск журналирования полностью отведен под один журнал, в который последовательно логируются все операции записи. Когда каждый EN совершает операцию добавления, он записывает все данные на диск журналирования и начинает записывать данные на диск. Если диск журналирования возвратит код успешной операции раньше, данные будут буферизованы в памяти и до тех пор, пока все данные не будут записаны на диск данных, все операции чтения будут обслуживаться из памяти. Использование диска журналирования предоставляет важные преимущества, так как, например, операции добавления не должны «соревноваться» с операциями чтения с дисков данных с целью подтвердить операцию для клиента. Журнал позволяет операциям добавления с Partition Layer быть более согласованными и иметь меньшие задержки.
Partition Layer (PL). Данный слой содержит специальные Partition Servers (процессы-демоны) и предназначен для управления собственно абстракциями хранилища (блобами, таблицами, очередями), пространством имён, порядком транзакций, строгой согласованностью объектов, хранением данных на SL и кэшированием данных для снижения количества I/O операций на диск. Также PL занимаются партиционированием объектов данных внутри SS согласно PartitionName и дальнейшей балансировкой нагрузки между серверами партиций. Partition Layer предоставляет внутреннюю структуру данных под названием Object Table (OT), которая является большой таблицей, способной разрастаться до нескольких петабайт. OT в зависимости от нагрузки динамически разбивается на RangePartitions и распределяется по всем Partition Server внутри Storage Stamp. RangePartition представляет из себя диапазон записей в OT, начинающихся с предоставленного наименьшего ключа до наибольшего ключа.
Есть несколько различных типов OT:
• Account Table хранит метаданные и конфигурацию для каждого аккаунта хранилища, ассоциированные с Storage Stamp.
• Blob Table хранит все объекты блобов для всех аккаунтов, ассоциированных со Storage Stamp.
• Entity Table хранит все записи сущностей для всех аккаунта хранилища, ассоциированных со Storage Stamp и используется для сервиса хранилища таблиц Windows Azure.
• Message Table хранит все сообщения для всех очередей для всех аккаунтов хранилища, ассоциированных со Storage Stamp.
• Schema Table отслеживает схемы для всех OT.
• Partition Map Table отслеживает все текущие RangePartitions для всех Object Table и то, какие Partition Server обслуживают какие RangePartition. Эта таблица используется FE-серверами для перенаправления запросов к необходимым Partition Server.
Таблицы всех типов имеют фиксированные схемы, которые хранятся в Schema Table.
Для всех схем OT имеется стандартный набор типов свойств — bool, binary, string, DateTime, double, GUID, int32 и int64, кроме этого, система поддерживает два специальных свойства DictionaryType и BlobType, первый из которых позволяет реализовать добавление свойств без определенной схемы как запись. Эти свойства хранятся внутри типа словаря в виде
(имя, тип, значение). Второе же специальное свойство используется для хранения больших объемов данных и на данный момент используется только для Blob Table, при этом данные блобов хранятся не в общем потоке записей, а в отдельном потоке для данных блоба, в сущности же хранится только ссылка на данные блоба (список ссылок «экстент+сдвиг, длина»). OT поддерживают стандартные операции – вставку, обновление, удаление и чтение, а также пакетные транзакции для записей с одним значением PartitionName. Операции в одном пакете подтверждаются как одна транзакция. OT также поддерживают режим snapshot isolation для того, чтобы позволить операциям чтения осуществляться параллельно операциям записи.
Архитектура Partition Layer
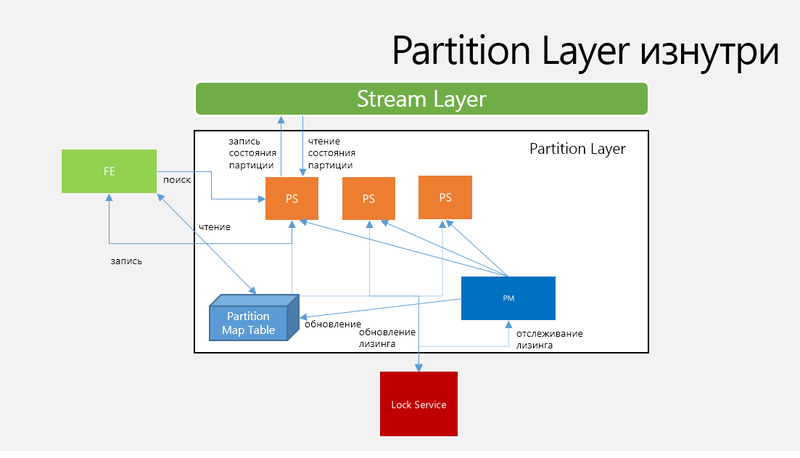
Рис. 4. Архитектура и Workflow Partition Layer
Partition Manager (PM) отслеживает и разделяет большие OT на N RangePartition в пределах Storage Stamp и назначает RangePartition определенным Partition Server. Информация о том, что где хранится, сохраняется в Partition Map Table. Одна RangePartition назначается одному активному Partition Server, что гарантирует что две RangePartition не будут пересекаться.
Каждый Storage Stamp имеет несколько экземпляров PM и все они «соревнуются» за один Leader Lock, хранящийся в Lock Service.
Partition Server (PS) обслуживает запросы для RangePartitions, назначенных этому серверу PM и хранит все состояние партиций в Streams и управляет кэшем в памяти. PS способен обслуживать несколько RangePartition из нескольких OT, возможно, в среднем до десятка. PS обслуживает следующие компоненты, храня их в памяти:
• Memory Table, версию лога подтверждений для RangePartition, содержащую все недавние изменения, которые ещё не были подтверждены контрольной точкой.
• Index Cache, кэш, содержащий позиции контрольной точкой потока данных записей.
• Row Data Cache, кэш в памяти для страниц данных записей для контрольной точки. Этот кэш существует только для чтения. Когда происходит доступ к кэшу, проверяются Row Data Cache и Memory Table с предпочтением ко второму.
• Bloom Filters – если данные не найдены в Row Data Cache и Memory Table, то осматриваются позиции и контрольные точки в потоке данных, причем грубый их перебор будет неэффективным, поэтому для каждой контрольной точки используются специальные bloom-фильтры, которые указывают, может ли быть осуществлен доступ к записи в контрольной точки.
Lock Service используется для выбора обслуживающего PM. Каждый PS также управляет лизингом с Lock Service для обслуживания партиций. При ошибке PS все N RangePartitions, обслуживавшие этот PS, переназначаются доступным PS. PM выбирает N PS, основываясь на их нагрузке, затем PM назначает RangePartitions PS и обновляет Partition Map Table соответствующими данными, что позволяет Front-End Layer найти расположение RangePartitions, обратившись к Partition Map Table. RangePartition использует для сохранения данных Log-Structured Merge-Tree, каждая из RangePartition состоит из собственного набора Streams на Stream Layer и Stream относится полностью к определенной RangePartition.
Каждая RangePartition может состоять из одного из следующих Streams:
• Metadata Stream – этот Stream является главным для RangePartition. PM назначает PS партицию, предоставляя имя Metadata Stream этого PS.
• Commit Log Stream – этот Stream предназначен для хранения логов подтвержденных операций вставки, обновления и удаления, применённых к RangePartitions с последней точки, сгенерированной для RangePartition.
• Row Data Stream сохраняет данные записи и позицию для RangePartitions
• Blob Data Stream используется только для Blob Table для сохранения данных блобов.
Все перечисленные Stream являются различными Stream в Stream Layer, управляемой OT RangePartition. Каждая RangePartition в OT имеет только один поток данных, исключая Blob Table – RangePartition в Blob Table имеет поток данных записей для сохранения данных последней контрольной точки для записи (позицию блоба) и отдельный поток данных для блоба для сохранения данных для специального типа BlobType.
Балансировка нагрузки RangePartitions
Для того, чтобы осуществить балансировку нагрузки между Partition Servers и определить общее количество партиций в Storage Stamp, PM проводит три операции:
• Балансировка нагрузки. С помощью этой операции определяется, когда определенный PS испытывает слишком большую нагрузку, и затем одна или более RangePartitions переназначаются на менее нагруженные PS.
• Split. С помощью этой операции определяется, когда определенная RangePartition испытывает слишком большую нагрузку, и эта RangePartition разделяется на две или более более мелких партиций, после чего эти RangePartitions распределяются по двум или более PS. PM посылает команду Split, но решает, где будет разделена партиция, PS, основываясь на AccountName и PartitionName. При этом, например, для разделения RangePartition B в две RangePartitions C и D выполняются следующие операции:
o PM посылает команду PS на разделение B в C и D.
o PS делает контрольную точку для B и перестает принимать трафик.
o PS выполняет специальную команду MultiModify, собирая Streams с B (метаданные, логи подтверждения и данные) и создаёт новые наборы Streams для C и D в том же порядке, что и в B (это происходит быстро, так как создаются, по сути, только указатели на данные). Затем PS добавляет новые диапазоны Partition Key для C и D к метаданным.
o PS возобновляет обслуживание трафика для новых партиций C и D.
o PS уведомляет PM о выполнении разделения, обновляет Partition Map Table и метаданные, затем переносит разделенные партиции на разные PS.
• Merge. С помощью этой операции две «холодных» или малонагруженных RangePartitions объединяются так, чтобы сформировать диапазон ключевых в их OT. Для этого PM выбирает две RangePartitions со смежными диапазонами PartitionName, имеющими малую нагрузку, и выполняет следующую последовательность действий:
o PM переносит C и D таким образом, чтобы они обслуживались одним PS, и сообщает PS команду об объединении C и D в E.
o PS сохраняет контрольную точку для C и D и ненадолго прекращает обслуживание трафика к C и D.
o PS выполняет команду MultiModify для создания нового лога подтверждения и потоков данных Е. Каждый из этих потоков является объединением всех экстентов из соответствующих потоков из C и D.
o PS создаёт поток метаданных Е, содержащий имена лога подтверждения и потока данных, комбинированный диапазон ключей для Е и указатели (экстент+сдвиг) для лога подтверждений (от С и D).
o Начинается обслуживание трафика для RangePartition E.
o PM обновляет Partition Map Table и метаданные.
Для балансировки нагрузки отслеживаются следующие метрики:
• Количество транзакций в секунду.
• Среднее количество незаконченных транзакций.
• Нагрузка CPU.
• Нагрузка на сеть.
• Задержка запросов.
• Размер данных RangePartition.
PM при этом управляет heartbeat-ом каждого из PS, и информация об этом передается обратно к PM в ответ на heartbeat. Если PM видит, что RangePartition испытывает слишком большую нагрузку (исходя из метрик), то он разделяет партицию и отсылает команду PS для осуществления операции Split. Если же сам PS испытывает большую нагрузку, но не RangePartition, то PM переназначает имеющиеся у этого PS RangePartitions на менее нагруженные PS. Для балансировки нагрузки на RangePartition PM посылает команду PS, имеющий RangePartition, на запись текущей контрольной точки, после выполнения чего PS посылает подтверждение PM и PM переопределяет RangePartition на другой PS и обновляет Partition Map Table.
Решение о выборе механизма партиционирования на основе диапазонов (на котором работают RangePartition) вместо индексирования на основе хэшей (когда объекты назначаются серверу по значениям хэшей их ключей) было обосновано тем, что партиционирование на основе диапазонов помогает проще реализовать Performance Isolation, так как объекты определенного аккаунта хранятся рядом в пределах набора RangePartitions, индексирование на основе хэшей же упрощает задачу распределения нагрузки на сервера, но при этом лишает преимущества локальности объектов в целях изоляции и эффективного перечисления. Партиционирование на основе диапазонов позволяет хранить объекты одного клиента вместе в одном наборе партиций, что также предоставляет возможность эффективно ограничивать или изолировать потенциально небезопасные аккаунты. Одним из недостатков же подобного похода является масштабирование в сценариях последовательного доступа – например, если клиент записывает все свои данные в самый конец диапазона ключей таблицы, то все операции записи будут перенаправляться в самую последнюю RangePartition таблицы клиента. В этом случае преимущество партиционирования и балансировки нагрузки в системе не используется. Если же клиент распределяет операции записи по большому количеству PartitionNames, то система быстро разделяет таблицу на набор RangePartitions и распределяет их по нескольким серверам, что позволяет линейно увеличивать эффективность.
Front-End (FE). Слой фронтенда состоит из набора stateless-серверов, принимающих входящие запросы. Получив запрос, FE читает AccountName, аутентифицирует и авторизовывает запрос, после чего переводит его на сервер партиций на PL (основываясь на полученном PartitionName). Сервера, принадлежащие FE, кэшируют так называемую карту партиций (Partition Map), в которой системой управляется некоторый трекинг диапазонов PartitionName и того, какой сервер партиций какие PartitionNames обслуживает.
Intra-Stamp Replication (stream layer). Данный механизм управляет синхронной репликацией и сохранностью данных. Он сохраняет достаточно реплик по разным узлам в разных доменах ошибок для того, чтобы сохранить эти данные в случае какой-либо ошибки, и выполняется он полностью на SL. В случае операции записи, поступившей от клиента, она подтверждается только после полной успешной репликации.
Inter-Stamp Replication (partition layer). Данный механизм репликации производит асинхронной репликацией между SS, и проводит он эту репликацию в фоне. Репликация происходит на уровне объектов, то есть либо целый объект реплицируется, либо реплицируется его изменение (delta).
Различаются эти механизмы тем, что intra-stamp предоставляет устойчивость против «железных» ошибок, которые периодически случаются в большого масштаба системах, тогда как inter-stamp предоставляет географическую избыточность против различных катастроф, которые происходят редко. Одним из основных сценариев для этого типа репликации является географическая репликация данных аккаунта хранилища между двумя датацентрами в целях восстановления от природных бедствий.
Все данные в сервисах хранилища блобов и таблиц географически реплицируются (но очереди – нет). С географически избыточным хранилищем платформа сохраняет опять же три реплики, но в двух локациях. При развертывании аккаунта хранилища LS выбирает Storage Stamp в каждой из географических локаций и регистрирует выбранный AccountName во всех Storage Stamp, при этом одна из локаций будет принимать «живой» трафик, тогда как вторые, secondary, будут осуществлять только inter-stamp replication (по сути и есть географическую репликацию). LS затем обновляет DNS для новой записи AccountName.service.core.windows.net, ведущей на VIP главной локации. Таким образом, если с датацентром что-то случится, данные будут доступны из второй локации. Когда операция записи поступает в главную локацию для аккаунта хранилища, изменения полностью реплицируются с использованием intra-stamp replication на Stream Layer, после чего код об успешном завершении операции возвращается клиенту. По подтверждению операции в асинхронном режиме происходит репликация в другую географическую локацию и уже там транзакция применяется на Partition Layer.
Что касается географической отказоустойчивости и того, как все восстанавливается в случае серьезных сбоев. Если серьезный сбой возник в главной географической локации, естественно что корпорация пытается по максимуму сгладить последствия. Однако, если всё совсем плохо и данные потеряны, может возникнуть необходимость в применении правил географической отказоустойчивости – клиент оповещается о возникшей катастрофе в главной локации, после чего соответствующие DNS-записи перебиваются с главной локации на вторую (account.service.core.windows.net). Разумеется, в процессе перевода DNS-записей вряд ли что-то будет работать, но по его завершению существующие блобы и таблицы становятся доступными по их URL. После завершения процесса перевода вторая географическая локация повышается в статусе до главной (до тех пор, пока не случится очередной провал датацентра сквозь землю). Также сразу по завершению процесса повышения статуса датацентра инициируется процесс создания новой второй географической локации в этом же регионе и дальнейшей репликации данных. Командой разработки было анонсировано, что пользователь сможет выбирать, где будет его вторая географическая локация, в том случае, если в одном регионе будет более двух датацентров, но пока я не заметил такой возможности (возможно потому, что не знаю таких регионов).
Процесс географической репликации гораздо более интересен хотя бы потому, что на наши действия он влияет больше и чаще, чем эфемерный динозавр, съевший датацентр, что привело к geo-failover.
Итак, например, в нашем аккаунте хранилища есть несколько блобов (пример из блога разработчиков), foo и bar. Для блобов полное имя блоба равно значению PartitionKey. Мы выполняем две транзакции A и B на блобе foo, после чего выполняем две транзакции X и Y на блобе bar. Система гарантирует, что транзакция А будет географически реплицирована перед транзакцией B, и, соответственно, транзакция X будет географически реплицирована перед транзакцией Y. В остальном же гарантий нет – доподлинно неизвестно, сколько будет затрачено времени на географическую репликацию между транзакциями на foo и транзакциями на bar. Также, если в момент репликации датацентр по какой-то причине сломается, что приведет к невозможности географической репликации недавних транзакций, может случиться так, что реплицируются транзакции A и X, тогда как транзакции B и Y будут потеряны. Либо реплицируются только А и В, а X и Y пропадут. То же самое может произойти и с сервисами таблиц (учитывая то, что партиции в таблицах определяются заданным приложением PartitionKey сущности, а не именем блоба).
Резюме
Сервисы хранилища Windows Azure являются важнейшей составляющей платформы, предоставляющей услуги по хранению данных в облаке и реализующих комбинацию таких характеристик, как строгая согласованность, глобальное пространство имён и высокая отказоустойчивость данных в условиях мультитенантности.
ссылка на оригинал статьи http://habrahabr.ru/post/173661/
Добавить комментарий