Привет, %habra_user%!
Решил в продолжение цикла статей о Flex-компиляторе перевести хорошую статью автора сего творения о том, какие же процессы происходят внутри компилятора при сборке приложения. Датируется она 2008м годом, но при этом в русскоязычном сообществе (да и в других особо тоже) замечена не была. А так как ближайшее время именно этот компилятор остаётся актуальным для сборки подавляющего большинства Flash-проектов, то я решил продолжить цикл статей о его расширении.
Как обычно всех, кто не устал дочитав до этой строчки — прошу под кат!
Во-первых, считаю уместным привести ссылки на другие статьи из цикла:
- Добавляем в Flex-компилятор MXML параметры конструктора
- MXML компилятор. Часть 2. Не строковые инициализаторы параметров
- MXML компилятор. Часть 3. Разбираемся в работе Flex-компилятора
Во-вторых, мне пришлось довольно таки хорошо погуглить чтобы найти актуальную (в связи с передачей Flex-а апачам) ссылку на код ветки 4.6, и чтобы сэкономить Ваше время я просто оставлю её тут:
opensource.adobe.com/svn//opensource/flex/sdk/branches/4.y/
Я (как и автор оригинальной статьи) настоятельно рекомендую скачать исходники для лучшего понимания материала статьи. Материал статьи актуален для обеих (Apache & Adobe) версий компилятора.
Компиляторы языков
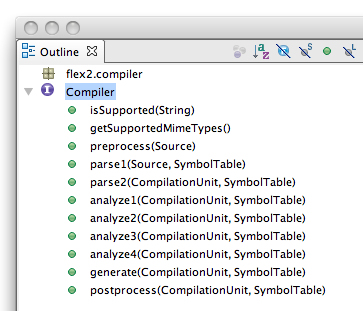
Вообще, Flex компилятор поддерживает разные языки программирования. Компилируются они набором специфичных для каждого языка компиляторами. Если посмотреть список классов проекта с именем Compiler, можно увидеть некоторые из них:
При этом нельзя утверждать, что все языки могут быть скомпилированы в один этап. Например, компилятор MXML может использовать использовать зависимости, написанные на AS3. Поэтому прежде чем скомпилировать MXML компонент в байткод, компилятор обязан выявить, какие AS3 классы ему нужны и проверить, что вызываемый из MXML код на AS3 корректен.
Так же разумно предполагать, что разным компиляторам требуется разное количество этапов. Например, MXML компилятор требует вдвое большее количество шагов чем AS3.
flex2.compiler.SubCompiler
В Flex, все компиляторы языков реализуют один и тот же интерфейс — flex2.compiler.SubCompiler:
public interface SubCompiler { String getName(); boolean isSupported(String mimeType); String[] getSupportedMimeTypes(); Source preprocess(Source source); CompilationUnit parse1(Source source, SymbolTable symbolTable); void parse2(CompilationUnit unit, SymbolTable symbolTable); void analyze1(CompilationUnit unit, SymbolTable symbolTable); void analyze2(CompilationUnit unit, SymbolTable symbolTable); void analyze3(CompilationUnit unit, SymbolTable symbolTable); void analyze4(CompilationUnit unit, SymbolTable symbolTable); void generate(CompilationUnit unit, SymbolTable symbolTable); void postprocess(CompilationUnit unit, SymbolTable symbolTable); void initBenchmarks(); PerformanceData[] getBenchmarks(); PerformanceData[] getEmbeddedBenchmarks(); void logBenchmarks(Logger logger); } Из не относящихся к процессу компиляции методов можно выделить:
String getName() — как можно понять из названия, метод возвращает имя компилятора;
isSupported и getSupportedMimeTypes — служат для определения типа файлов, которые данный компилятор может обрататывать;
benchmarks методы, относящиеся к замеру производительности компиляции.
Этапы компиляции
Как Вы могли заметить, процесс компиляции состоит из 9 этапов. Главный Flex-компилятор выступает в роли координатора и отвечает за вызов экземпляров компиляторов, которые ожидают примерно такого порядка:
- preprocess (один раз)
- parse1 (один раз)
- parse2 (один раз)
- analyze1 (один раз)
- analyze2 (один раз)
- analyze3 (один раз)
- analyze4 (один раз)
- generate (один раз)
- postprocess (многократно, пока экземпляр не потребует остановки)
Помимо вызова этих методов, главный Flex-компилятор делает ряд вещей:
- Подбирает подходящий экземпляр компилятора основываясь на типе исходного файла;
- Получает от экземпляров список не разрешённых типов и ищет их среди исходников проекта и библиотек;
- Передаёт информацию по типам в экземпляры;
- Решает какой компилятор должен выполниться основываясь на состоянии экземпляров и общему состоянию ресурсов.
Для того чтобы управлять всем и вся, главный компилятор заставляет экземпляры кооперироваться. В основном, он требует следовать определённому набору правил:
- Синтаксическое дерево должно быть доступно к концу этапа parse2;
- analyze1 должен иметь информацию об имени суперкласса;
- analyze2 должен знать о всех зависимостях;
- analyze4 должен предоставлять полную информацию о типе.
Процесс компиляции продолжается до того момента как:
- Не останется зависимостей, которые надо разрешить;
- Экземпляры компиляторов выдадут ошибку.
Алгоритмы вызова
Как было сказано ранее, процесс компиляции состоит из вызова этих 9 методов. Но не смотря на то, что порядок вызова этих методов определён довольно-таки точно, главный компилятор всё равно может вызывать их по-разному. По сути дела, существуют 2 алгоритма: Один (flex2.compiler.API.batch1()) структурированный, другой (flex2.compiler.API.batch2()) условно-патогенный. Рассмотрим их по отдельности:
API.batch1() — консервативный и более структированный алгоритм. Его суть заключается в том, что он гарантирует наступление одной фазы для каждого файла прежде чем перейти на другую фазу. Например, analyze1() будет вызвана для всех файлов прежде чем перейти к analyze2().
API.batch2() — условно-патогенный алгоритм, его главная цель — минимизировать потребление памяти. В отличие от API.batch1(), исходные файлы с меньшим количеством зависимостей могут дойти до этапа generate гораздо раньше чем файлы с бОльшим количеством зависимостей дойдут до фазы analyze3(). Идея в том, чтобы ресурсы, выделенные для файла, могли быть освобождены сразу как файл будет скомпилирован в байткод.
Заключение
Что ж, теперь Вы знаете гораздо больше о внутренней работе Flex компилятора! Давайте подытожим:
- Главный компилятор Flex-а использует только один из двух алгоритмов для компиляции: batch1 или batch2;
- Алгоритмы компиляции используют 2 разные стратегии для вызова 9 этапов сборки приложения;
- В процессе компиляции экземпляры компиляторов должны кооперироваться и предоставлять информацию о типах главному компилятору в конце каждого этапа;
- Главный компилятор выполняет всю гразную работу (поиск исходных файлов\библиотек, управление логированием ошибок и т.д.), а значит компиляторам языков не приходится об этом беспокоиться.
Описанное Выше актуально для всех версий утилит (mxmlc, compc, asdoc), входящих в состав Flex Framework.
От переводчика:
Просьба найденные грамматические ошибки и неточности отправлять личным сообщением, дабы не увеличивать количество полупрозрачных комментариев;)
P.S. Вообще, изначально идея была написать статью о Flex Compiler Extension-ах, которые позволяют расширять компилятор не меняя его код (подключатся через flex-config.xml в виде jar-ок), но одумавшись я решил сначала сделать эту статью, которая описывает всю подноготную.
P.S.S. Учитывая темпы развития ASC2.0, я считаю, что Flex Compiler будет актуальным ещё как минимум год, а то и больше, поэтому не бойтесь изучать и ковырять его, тем более, что это бесценный опыт!
P.S.S.S. Да, да, мёртв. Да, Adobe отказались от плеера. Да, отдача Apache. Бла-бла-бла…
ссылка на оригинал статьи http://habrahabr.ru/post/180139/
Добавить комментарий