
Производитель сделал три смелых маркетинговых заявления:
- Системе всё равно, запись или чтение – скорость будет одинаковой.
- При всём этом время отклика стабильно 250-500 микросекунд даже после месяца постоянной нагрузки.
- Можно вынимать любые комплектующие «на горячую» — системе ничего не будет.
Для начала мы разбили пространство на несколько десятков виртуальных томов и запустили десяток приложений, делающих запись блоками по 4 килобайта в режиме 20/80 (80% записи). А затем продержали модуль под нагрузкой 5 дней. Выяснилось, что маркетинг соврал: скорость записи была очень далека от заявленной 1 мс и составляла в среднем всего 0,4 мс (при 40/60 дело доходило и до 0,25).
Затем при тест-драйве в офисе для IT-директоров у нас начались настоящие проблемы. Дело в том, что я в приглашении упомянул, что как-то во время демонстрации Disaster Recovery-решения мы вырубили стойку в ЦОДе «на живую», после чего просто не осталось шансов закончить мероприятие мирно. Аудитория ждала крови, и мне пришлось позвать сервис-инженера с отвёрткой.
При 450k IOPS я начал с вытаскивания двух вентиляторов. Это почти не впечатлило аудиторию, потому что хотелось добраться до одного из двух контроллеров и посмотреть что Violin скажет на это. Минус два вентилятора заставили систему страшно зарычать (она автоматически ускорила остальные), поэтому дальше я услышал только что-то вроде «твою мать», когда инженер просто взял и выдернул один из двух контроллеров, и железка «просела» только на треть по скорости.
Осторожно, трафик: под катом схемы и скриншоты.
Чтобы рассказать что и как сработало при этом и откуда такие скорости, придётся начать издалека. Пролистывайте сразу к архитектуре системы, если хорошо представляете себе архитектуру современных флеш-СХД. Или оставайтесь здесь, если, как сказал представитель одного крупного хостинга, «я знаю что она быстрая, но даже не знаю, что она делает».
Введение
Давным-давно как таковых отдельных систем хранения данных не было: просто у сервера был жесткий диск, на который записывалась вся информация. Потом информации понадобилось писать всё больше и больше, и в результате выделились отдельные хранилища, создаваемые на магнитной ленте, массивах дисков и массивах флеш-дисков.
При этом скорость развития процессоров существенно превышала скорость развития накопителей. Дисковые массивы постепенно становились бутылочным горлышком. Учитывая аппаратные ограничения самой физики жестких дисков, производили начали собирать из них огромные быстрые RAID’ы с дополнительным резервированием и оптимизировать алгоритмы до непосредственно записи. Но всё равно выше головы не прыгнуть, и скорость принципиально не повышалась несколько лет.
Потом появились первые флеш-диски. Здесь очень интересный момент: учитывая текущую инфраструктуру, каждый флеш-диск был для всей архитектуры выше уровнем обычным жестким диском, просто с более высокой скоростью. То есть флеш-решения втыкались на место старых жестких дисков — и весь стек технологий до контроллера записи уже в коробке накопителя думал, что работает с обычным магнитным диском. А это сразу означало огромный overhead из совершенно ненужных для флеш-технологии операций: например, кэш СХД с его алгоритмами оптимизации совершенно не нужен и является просто лишней задержкой для данных (а даже при его отключении данные всё равно «пролетают» сквозь его микросхемы), классическая схема записи по секторам тоже приводила к совершенно лишним замедлением. При этом сами флеш-диски имели другую схему записи, что вело к тому, что приходилось делать работу трижды: прокидывать интерфейс от НЖМД до флеш, писать как на флеш и ещё при каждой записи работать с аналогом garbage collector’а. Сам подход не менялся с распространением SSD на рынке — всё те же проблемы с шиной, кэшем и алгоритмами записи.
В итоге в какой-то момент парни из Violin посмотрели на эту картину и задали себе простой вопрос: почему если флешовая микросхема памяти работает со скоростью более близкой к DRAM, чем к классическим HDD, да при этом энергонезависима надо обязательно прикручивать её в существующую архитектуру СХД вместо классических дисков? Ответ был только в огромном устаревшем парке протоколов и обработчиков на низких уровнях. Проблема в том, что всю систему пришлось бы разрабатывать с нуля – а это означало серьёзные вложения средств и времени.
Инженеров Violin это не остановило, они заключили контракт с производителем флеш-памяти Toshiba, позволяющий получить доступ к архитектуре чипа. В результате через некоторое время удалось проделав большую работу создать серверное хранилище, которое выдавало огромные скорости доступа к информации при фантастически низком уровне задержек даже по сравнению с SSD.
Понадобилось избавиться от понятия диска как такового, чтобы убрать весь кусок стека, работавший по-старому. На выходе получилась штука, которую никак нельзя назвать флеш-диском: у нас на столе натуральные микросхемы, внешне больше похожие на DRAM.
Ограничения флеш-памяти
Во-первых, количество циклов записи на ячейку ограничено. Я застал первые флеш-диски для серверов, которые сыпались через месяц-два интенсивной работы. Но, правда, стоит отметить, что в ряде случаев даже так было лучше, чем работать с жесткими дисками: последние имели свойство лететь в непредсказуемый момент из-за механики, а флешовые диски и микросхемы всегда точно знают свою точку отказа и способны предупредить заранее.
Во-вторых, на флеш-накопителях в отличие от классического магнитного диска нет возможности перезаписать новые данные поверх старых, запись можно вести только в пустую ячейку. То есть появляется третья операция помимо классических чтения и записи – стирание. Казалось бы проблемы это не представляет, всего лишь придется перед перезаписью очищать ячейку, но тут и кроется главная опасность: в отличие от чтения и записи операция стирания очень медленная. В разы.
В-третьих, если удастся обойти первые два ограничения, возникнет третье: «бутылочным горлышком» может стать контроллер, который должен будет управлять всем этим хозяйством и готовить данные для чтения и записи.
Если не обходить эти ограничения, то обычный SSD даст всего 20-40 процентов прироста мощности. Если обходить — можно добиться просто фантастических чисел. Violin решили эти вопросы довольно интересно.
Посмотрим на архитектуру системы

Вот так выглядит вся система
В той области, которая обозначена как «flash memory fabric» вы можете разглядеть огромную кучу микросхем, на которые смотрят большие чёрные вентиляторы. Это и есть флеш-память, размещённая вот на таких платах:

Отдельный кирпичик флеш-фабрики.
На одном модуле 16 микросхем непосредственно флеш-памяти, несколько модулей DRAM и одна плата FPGA на один «кирпичик». Кирпичиков в фабрике максимум 64 штуки. Все операции с данными в пределах платы осуществляются локально на FPGA, что позволяет не загружать внешние контроллеры этими заботами.
Рядом с этими штуками стоят 4 Virtual RAID-контроллера, которые занимаются обеспечением целостности данных чётностью по алгоритму аналогичному RAID 3 4+1. По умолчанию контроллеры разбивают платы памяти на группы «ответственности» по 5, да и по 1 HotSpare на контроллер. Однако разбиение это в определенной степени «виртуально», одинаковый по скорости доступ каждого контроллера к каждому модулю всегда обеспечивается коммутационной структурой массива, т.е. как сказали бы мы для классической архитектуры СХД, back-end абсолютно честный active-active.
Механизмы обеспечения целостности сохранят данные даже при последовательном выходе из строя нескольких плат памяти, главное чтобы не «умерли» 2 плашки 1 RAID одновременно, ребилд на FLASH накопителях тоже идет на порядки быстрее. Правда есть особенность: при штатной замене система видит битый модуль и отключает питание на нём автоматически (или позволяет отключить питание любого модуля из интерфейса), затем модуль вытаскивается, затем ставится новый и активируется в интерфейсе. Что самое весёлое – всё можно менять «на горячую». Во время тестов мы создавали до сотни томов с разными приложениями, а затем вынимали последовательно 4 модуля с промежутком минут в 20 (один аварийно, три c предварительным отключением через интерфейс) – и всё работало как часы.
Специализированной защиты на случай отключения внешнего питания, типа батареек или суперконденсаторов в блоках питания на массиве не предусмотрено. Это не значит, что массив не защищен от внезапных перебоев в электросети: ему хватает запасенной в БП энергии, чтобы сбросить последнюю транзакцию на FLASH, причем хватает с большим запасом. После исчезновения тока система на остатках энергии может записать все данные на FLASH более 40 раз.
Теперь поднимемся ещё уровнем выше и посмотрим как, с точки зрения архитектуры, массив общается с внешним миром:
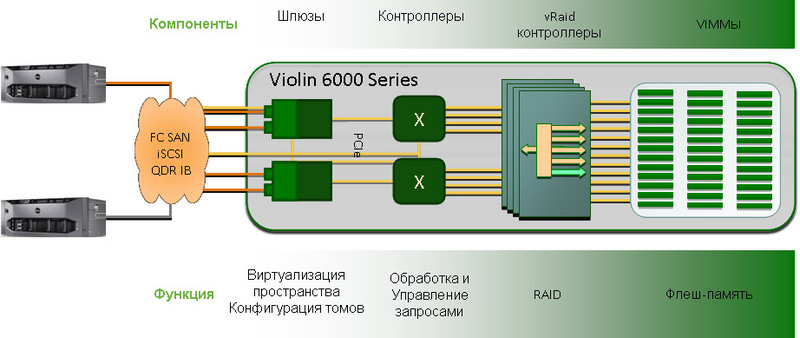
Архитектура системы
Итак, на входе есть данные от серверов, которые отправляют данные по стандартным интерфейсам SAN, позволяющим работать с внешним блоком на нужных скоростях и масштабироваться. Затем данные приходят в шлюзы, где полезная информация передаётся в транспортную инфраструктуру на основе PCIe х8 (ничего более медленное для работы с такими скоростями не подойдет в принципе, не обеспечит выдерживание нужного уровня задержек) и доставляются до vRAID контоллеров блоками по 4 КБ. После чего происходит вычисление четности и затем запись на 1 из пятерок планок памяти по 1 Кб на планку.
Транспортная инфраструктура (Virtual Matrix в терминологии Violine) полностью пассивна и управляется 2 дублированными модулями ACM. Эти модули – чисто управляющий элемент массива, они напрямую не связаны с логикой обработки данных, их функция чисто управляющая, они «рулят» электропитанием и следят за исправностью системы. Транспортная инфраструктура обеспечивает возможность связи всех-со-всеми в рамках корпуса Violine даже при выходе из строя части компонент, однако при этом не создает единой точки отказа, разве что пассивную плату можно таковой посчитать, но вероятность выхода её из строя не сильно отличается от, скажем, вероятности пожара в ЦОД.
Теперь самое интересно и сложное: что делать с ограничением флеш-технологии на запись? Решение в общем-то не сложное, но со слов разработчиков Violin эта простота стоила им доставила больше всего сложностей. Решается эта проблема предварительной очисткой ячеек, сразу после потери актуальности данных. Работает это следующим образом: как известно реальная сырая емкость каждого чипа FLASH памяти гораздо больше декларируемой, это делается для равномерной деградации ячеек вне зависимости от профиля нагрузки, таким образом на физическом уровне каждая запись на чип идет в новую ячейку, а старая помечается как доступная для записи. Старые данные при этом остаются там же где и были, поэтому весьма быстро мы приходим к состоянию, когда пустых ячеек не остается и нам приходится перед каждой записью чистить ячейку, как результат скорость катастрофически падает.

Вот так выглядит это т.н. «обрыв» на графиках производительности для SSD
Violin работает немного по другому, FPGA на каждом чипе отслеживает актуальность информации каждой ячейки и, если данные уже не нужны, специальный фоновый процесс под названием garbage collector очищает её. Таким образом, каждая запись всегда идет в пустую ячейку, что позволяет избежать просадки производительности и использовать чипы FLASH-памяти максимально эффективно не только на чтение, но и на запись.
Давайте пробежимся по архитектуре ещё раз:
- Контроллеры получают данные и транслируют их дальше.
- Модуль управления коммутирует по PCIe х8 все компоненты между собой и обеспечивает мониторинг и управление компонентами.
- Флеш-фабрика распределят данные по отдельным модулям и балансирует всё в соответствии с любыми пиками, плюс обеспечивает равномерность износа и резервирование внутренних путей.
Всё что можно реализовано аппаратно на чипах FPGA, то есть обеспечивается принципиально иной уровень скоростей взаимодействия и обработки, чем обычно.
Линейки железа
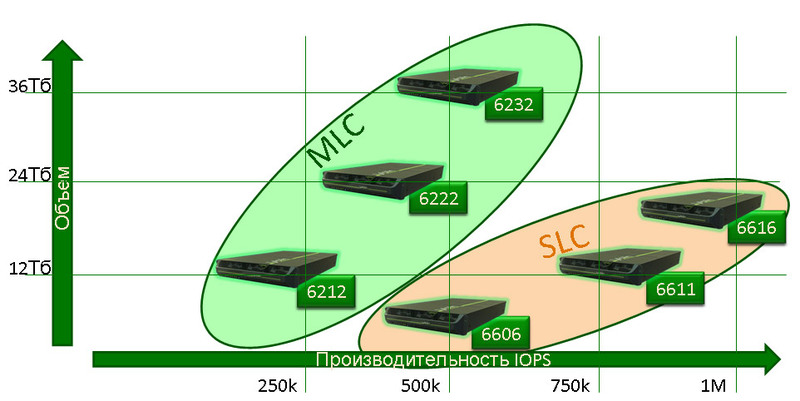
Теперь посмотрим ещё уровнем ниже на отдельную микросхему памяти. Дело в том, что есть две технологии записи на кристалл – SLC и MLC. SLC хранит 1 бит в каждой ячейке памяти, MLC – больше. В итоге получается так, что на одном и том же физическом кристалле SLC обеспечивает большую скорость и больший ресурс модуля, а MLC позволяет получить больше места.
При этом раньше зависимость была линейная – SLC давал в два раза меньше места при увеличении скорости в 2 раза. Однако, благодаря умному софту Violin (они потратили почти два года, чтобы покопаться в обработке данных на низком уровне) MLC отличается от SLC по скорости записи приблизительно на 50%. Ресурс MLC чипов так же повышен, по статистике Violin даже при предельной нагрузке на запись модули памяти проживут не меньше 4-5 лет.
Вот линейка нового поколения по зависимости объёма места и скорости работы:
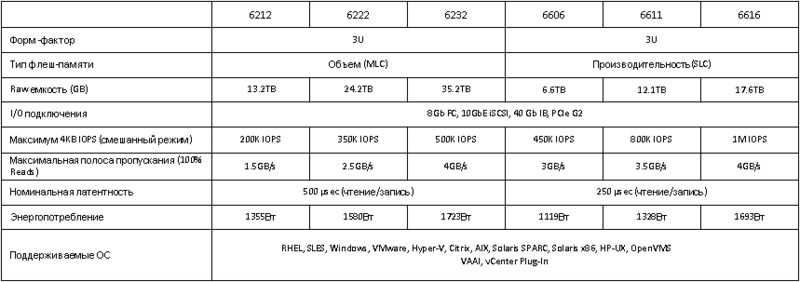
А вот отличия в таблице:
Вот так это выглядит в ЦОДе:
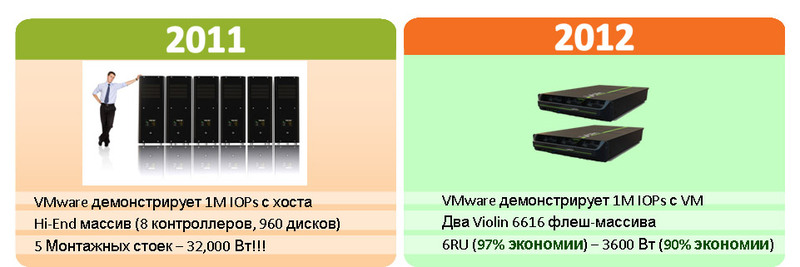
По монтажу – все массивы в 3U корпусе, мощность – 2 блока по 480 ватт, тепловыделение — как у мощного 3 U сервера.
Интерфейс и администрирование
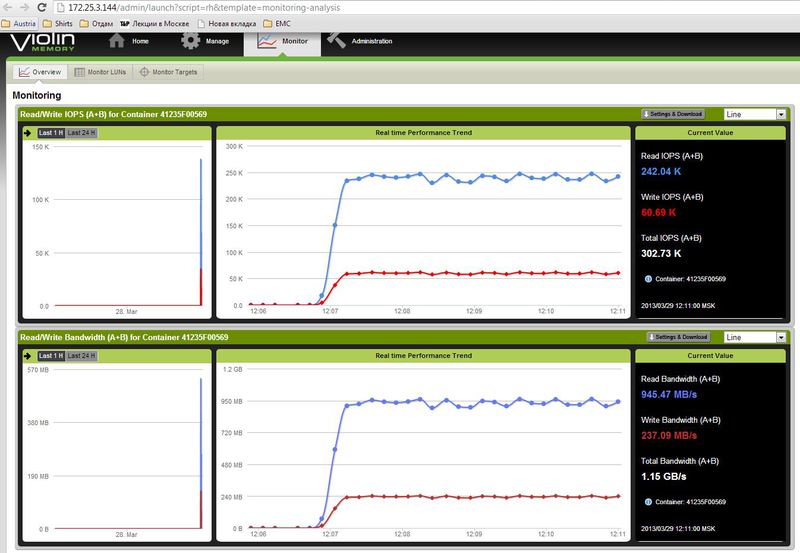
Статистика по IOPS на массиве, это максимальная нагрузка, которую смог создать 1 сервер IBM 3850X5
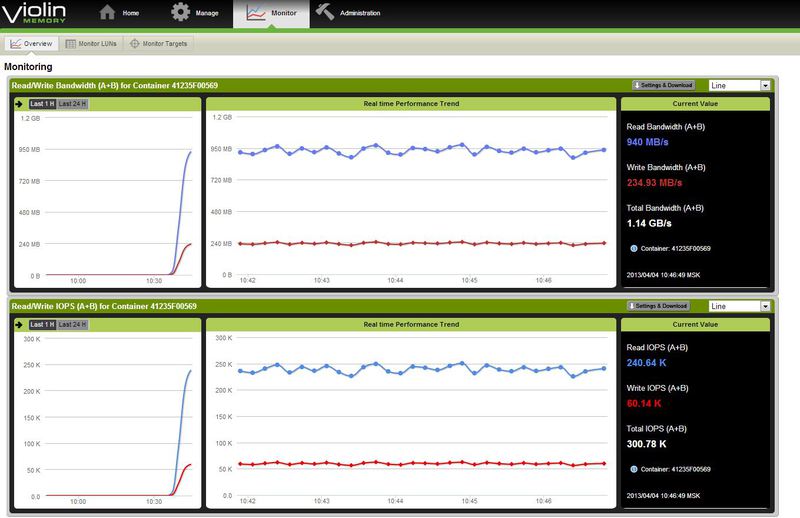
Тa же статистика, но мегабайты в секунду.
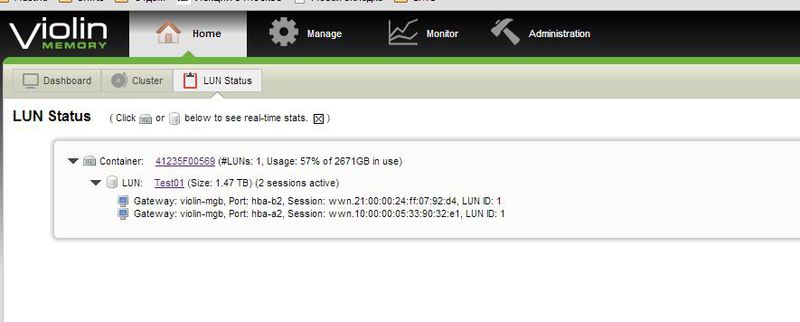
Просмотр параметров тома.
Система очень проста и удобна в управлении, Violin уделяет огромное значение интерфейсу, как удобству и простоте в работе, так и собственно скорости реакции и наглядности самого интерфейса.
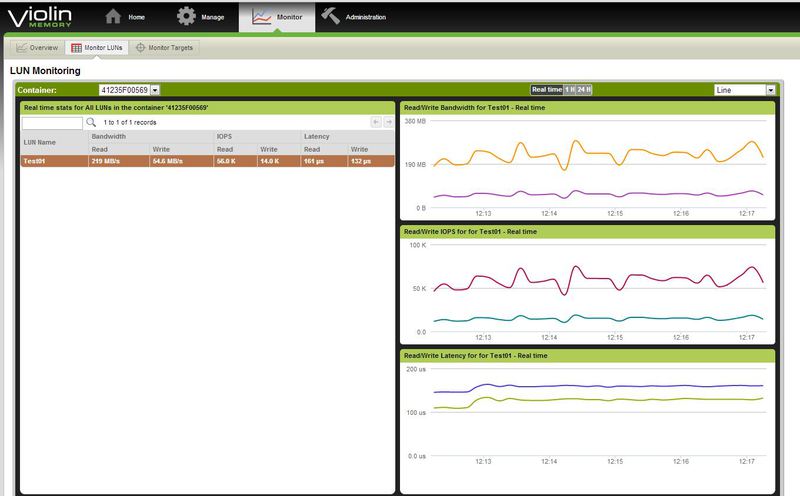
Здесь показана статистика по отдельному луну.
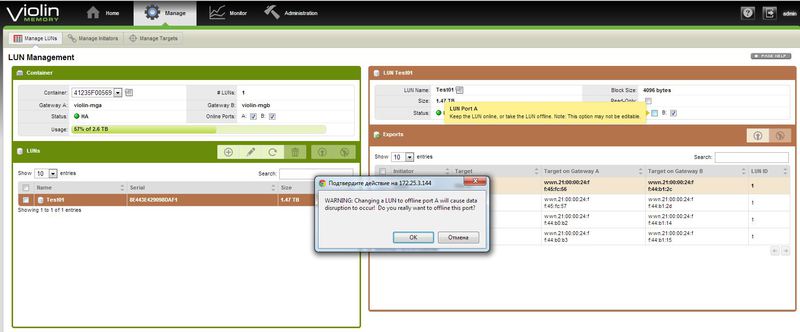
Защита «от дурака» в действии. Любые действия, могущие привести к прерыванию доступа или потере данных требуют дополнительного подтверждения.
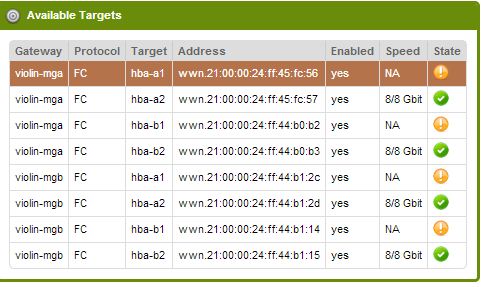
Состояние портов массива.
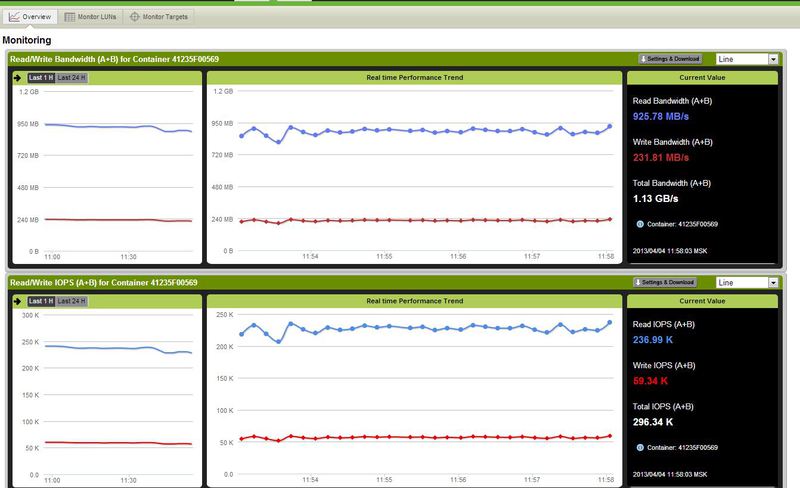
Окошко общей статистики массива.
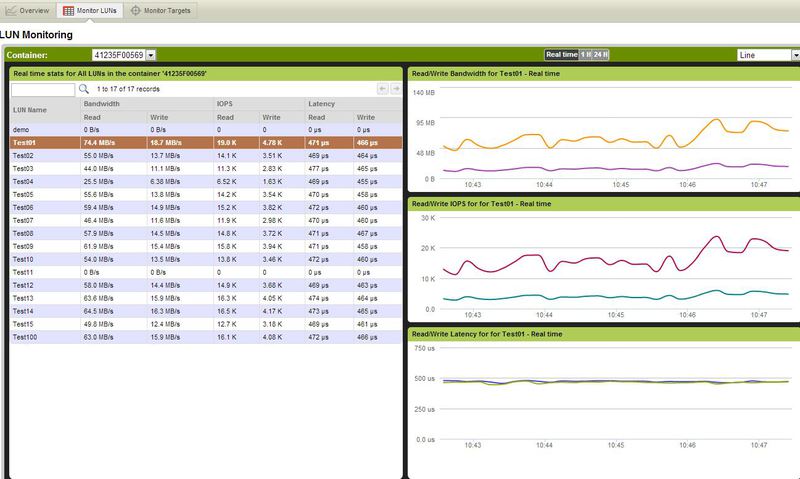
Окошко статистики по томам отдельно.
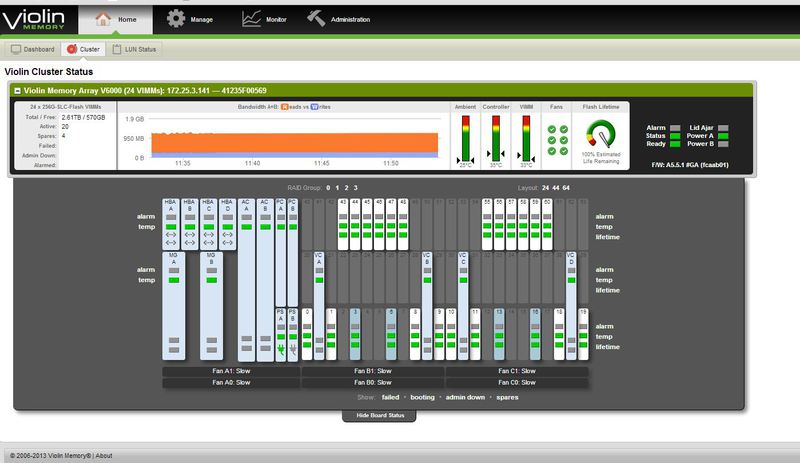
Интерфейс мониторинга аппаратных компонент системы.
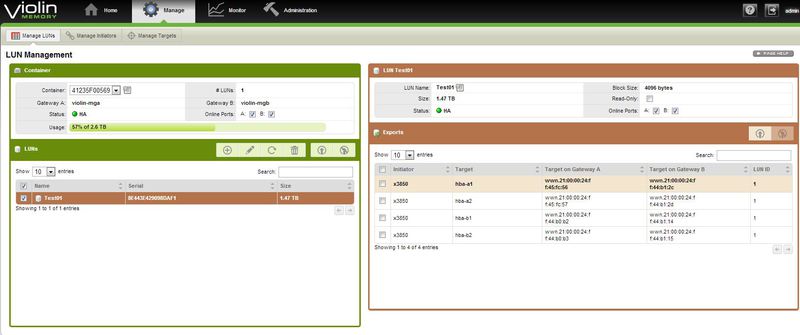
Страничка управления томами.
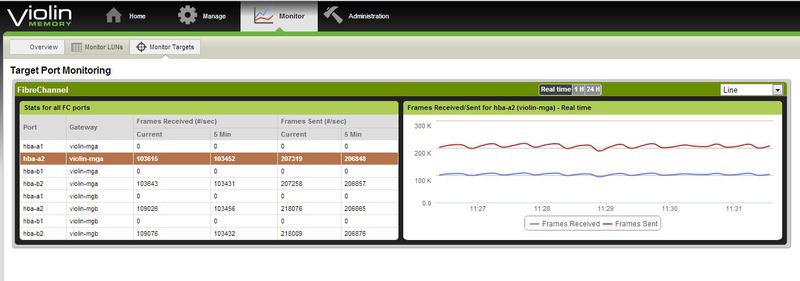
Страничка мониторинга нагрузок на портах.
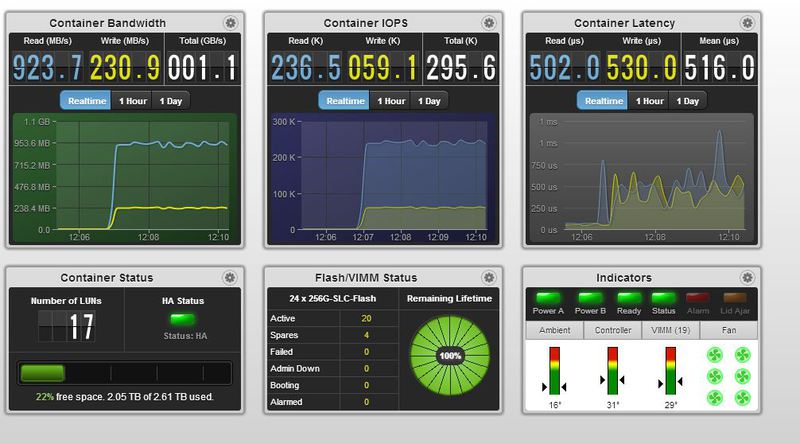
Главная страница мониторинга, полностью настраиваема, позволяет выводить наиболее нужную администратору, по его мнению, информацию по состоянию массива.
Эти железки в России
Как вообще появилась сама компания Violin? Довольно просто – когда стало понятно, что мощностей SSD всё равно не хватает для решения современных задач, а размазывать приложения по куче дисков – не самая крутая идея, они заключили партнёрство с Toshiba и начали работать со своим софтом контроллеров на низком уровне, близко-близко к физике процессов. Собрали в 2005-м первые линейки систем, показали какие они крутые, получили различные премий в области IT и стали «стартапом года» в кремниевой долине), а затем перевернули мир систем хранения. В настоящее время многие ведущие производители серверерных решений и ПО использовали решения Violin для раскрытия потенциала своих платформ в бенчмарках (TPC-C, VMmark и другие).
В Россию Violin пришли буквально только «вчера», и компания КРОК получила эксклюзивное годичное партнерство. Мы, в свою очередь, на текущий момент обеспечили локальные склады запчастей, обучили сервисных инженеров.
По внедрениям – было несколько десятков крупных интеграций железа прошлого поколения и несколько уже нового. Например, одна очень крупная компания формировала месячный билинг-отчет миллионам своих клиентов 72 часа, а стала формировать всего 22 часа. В VDI-решении удалось избежать простоя (ожидания) ответа от системы хранения за счет ультракороткого времени отклика, что позволило загрузить ядра так, что вместо старых 10 пользователей на ядро получилось 25 пользователей на ядро при аналогичной производительности, а это ещё экономия на лицензиях и вычислительном оборудовании.
Кстати, огромное спасибо маркетингу Violin – слава богу, они не делают особо громких заявлений и показывают не пиковые параметры, а стандартные– мы всё-таки интеграторы, и нам совершенно не нужно, чтобы очарованный чужим маркетинговым гением клиент потом спрашивал, почему у него всё не так. Благодаря такому подходу теперь клиент получает больше, чем ожидает.
И всё равно многие не верят в фантастические скорости флеш-систем, поэтому именно для Violin мы делаем не только тест-драйвы, где можно потыкать пальцем в железку, но и расчёты и пробные внедрения. Например, когда клиенту нужно было развернуть СХД инфраструктуру VDI на 1000 пользователей, при 50.000 IOPs, на 50Тб данных, рассматривалось два варианта: две СХД 7 х 200Гб Cache SSD 180 x 600Гб SAS против Violin 6212, 12Тб RAW = 7Тб Usable для «горячих» данных и 60 х 600Гб SAS 18 x 3Тб SATA для хранения «медленных» данных. Результат – экономия почти в два раза при повышении производительности от заявленных 50k IOPS до 200 000 IOPS.
Если интересно в деталях, как так получилось, могу просчитать решение вашей задачи с использованием флеш-СХД, пишите на vbolotnov@croc.ru. Я советую на всякий случай просто иметь такой проект и положить в стол – если вдруг понадобится резко ускориться, можно будет достать и показать расчёт.
ссылка на оригинал статьи http://habrahabr.ru/company/croc/blog/181494/
Добавить комментарий