Просто так выполнять какие-то вычисления на ядрах процессора – скучно, поэтому нужна задача, которая требует больших вычислительных ресурсов, хорошо раскладывается на параллельные вычисления, да и выглядит прикольно. Предлагаем сделать программу, которая рендерит простенькую 3D-сцену, используя алгоритм обратной трассировки лучей, или, по-простому, Ray Tracing.
Начнем с самого начала: наша цель параллельные вычисления на всех ядрах процессора. Все современные процессоры для PC, да и ARM уже тоже (я молчу про GPU) – это многоядерные процессоры. Что же это означает? Это означает, что вместо одного вычислительного ядра у процессора на одном компьютере присутствует несколько ядер. В общем случае, все выглядит несколько сложнее: на компьютере может быть установлено несколько сокетов (чипов процессора), в рамках каждого чипа (в рамках одного кристалла) может находиться сразу несколько физических ядер, а в рамках каждого физического ядра может находиться несколько логических ядер (например, те, что возникают при использовании технологии Hyper Threading). Все это схематично представлено на рисунке ниже, и называется топологией.

Очевидно, что сокеты — это просто несколько установленных процессоров одной материнской плате. Ниже еще несколько картинок, для наглядности.

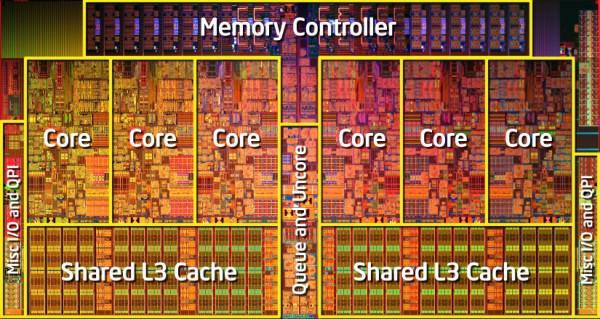
Среди всего этого, самым интересным является наличие логических ядер. В этом проявляется принцип SMT (Simultaneous Multithreading), который означает, на деле, выполнение очередных инструкций из другого логического потока, во время того, как части процессора освободились, ожидая окончания выполнения инструкций из основного потока. Каждое физическое ядро процессора состоит из множества компонентов (кэш, конвейеры, ALU, FPU,…), многие части работают независимо друг от друга и им необходимо синхронизироваться, поэтому пока инструкция перед окончанием выполнения ожидает данных из кэша или памяти, почему бы не выполнить другие инструкции из другого потока, используя те же инструкции? Еще больше информации и картинок можно найти по этой ссылке или в официальных документах Intel, AMD, ARM.
В рамках этой статьи детали топологии будут важны только для улучшения оптимизации (и все ядра буду восприниматься как одинаковые). Получить топологию программным путем можно используя инструкции CPUID, но об этом в следующий раз.
Введем еще несколько понятий:
SMP (Symmetric Multiprocessing) – означает симметричное использование всех процессоров; так, например все ядра процессора могут обращаться к одной и той же оперативной памяти в полном объеме, все ядра процессора одинаковые и ведут себя одинаково.
AMP (Asymmetric Multiprocessing) в противововес предыдущему понятию, означает, что хотя бы одно ядро ведет себя не так как другие. Например, совместную работу CPU и GPU можно рассматривать как пример AMP.
NUMA (Non-Uniform Memory Access) – неравномерный доступ процессоров к разным областям памяти. На деле означает, что каждое ядро процессора может обращаться ко всей памяти, но для каждого ядра есть область памяти, к которой он обращается быстрее, чем к остальной части. Опять же используется для оптимизации.
В современных компьютерных есть все указанные принципы и технологии.
Мы будем рассматривать SMP в чистом виде. При старте системы, процессор сам выбирает одно произвольное ядро и называет его Boot Strap Processor (BSP), все остальные становятся Application Processor (AP). BSP начинает выполнять код BIOS, который, в свою очередь, находит и стартует все ядра процессора в системе, выполняет их предварительную инициализацию и, благополучно их выключает. Таким образом, наша программа после старта будет работать на одном BSP ядре процессора, поэтому наша цель выглядит, на первый взгляд, достаточно просто: узнать, сколько ядер на компьютере, затем запустить и настроить каждое ядро в системе, и заставить все ядра выполнять одну вычислительную задачу, ради общего блага.
Для того, чтобы достигнуть нашей цели нужно ответить на несколько вопросов:
Как определить количество и топологию процессоров и ядер в системе?
Для этого нужно использовать замечательный интерфейс ACPI, а для определения топологии, использовать CPUID.
Как идентифицировать конкретное ядро процессора?
Для этого используется устройство APIC, или вернее LAPIC, который есть у каждого ядра процессора в системе, обладает уникальным для системы идентификатором (вроде PID для процессов), и отвечает за доставку прерываний на конкретное ядро процессора.
Как запустить одно ядро с другого ядра?
Достаточно отправить прерывание с одного ядра процессора на другой. Такой сигнал называется IPI (Inter Processor Interrupt). Для его отправки достаточно использовать LAPIC устройство на одном из ядер, записав в его регистр определенное значение.
Как остановить выполнение ядра процессора?
Достаточно на этом ядре вызвать инструкцию HLT.
Теперь немного подробнее. ACPI (не путать с APIC) – это Advanced Configuration and Power Interface – по сути это стандартный интерфейс, через который операционная система может получать информацию о компьютере, его детальной конфигурации, и управлять питанием компьютера. Этот интерфейс состоит из устройства управления питанием (которое называется ACPI-устройство, и, кстати, присутствует в PCI (смотрим статью)), и нескольких таблиц ACPI, которые расположены в оперативной памяти компьютера и содержат информацию о системе. Помимо информации о ядрах процессоров на компьютере, некоторые таблицы ACPI хранят информацию даже о физических габаритах и форм-факторе компьютера (например, из них можно узнать, что программа работает на планшете…). Таблиц достаточно много, и их полное описание можно найти здесь, а нас интересует только MADP, на которую ссылается RSDT, указатель на которую находится в таблице RSDP, которую можно найти где-то в окрестностях BIOS. Упрощенная схема основных ACPI таблиц представлена так:
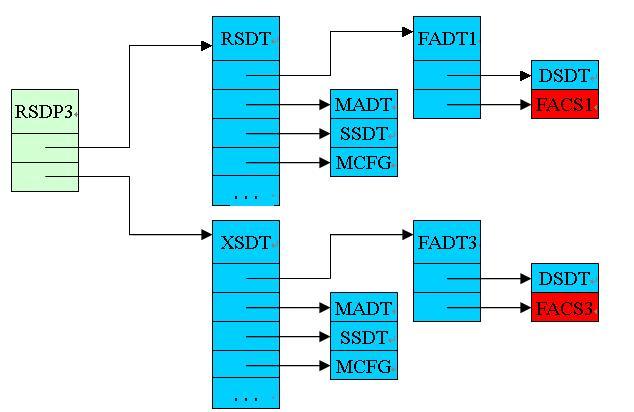
Пока все что нужно знать — что MADT содержит записи с информацией о ядрах процессора. Для каждой записи содержится идентификатор LAPIC этого ядра (длиной 8 бит, что означает не более 256 ядер любого типа в системе) и бит Enable (который говорит о том, можно ли пользоваться этим ядром или оно зарезервировано).
Теперь LAPIC – это Local APIC, а APIC (не путать с ACPI) – это Advanced Programmable Interrupt Controller, что является заменой старого PIC (Programmable Interrupt Controller). PIC раньше сразу доставлял прерывания на процессора, а теперь он это делает через LAPIC. Local APIC не единственный тип APIC – есть еще IO APIC – который является отдельным контроллером прерываний и отвечает за распределение прерываний между ядрами процессоров на системе. Итого картина такая:
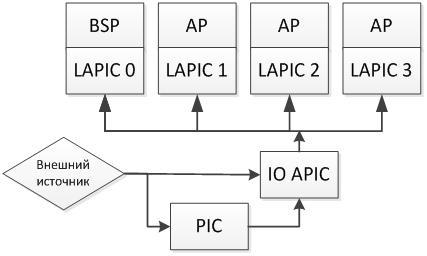
На первый взгляд выглядит сложно, но если разобраться, то все вполне разумно: PIC – контроллер прерываний, который используется уже давно – остался и никуда не делся, он как и прежде входит в состав чипсета на материнской плате. С появлением многоядерности добавили IO APIC, который теперь распределяет прерывания от PIC и других источников между ядрами, ибо кому-то это делать нужно. Каждый LAPIC снабжен уникальным идентификатором, который используется в IPI и настройке IO APIC. Так же в номере LAPIC закодирована его топология. BSP всегда имеет идентификатор LAPIC равный 0.
Чтобы программировать LAPIC, нужно читать и записывать данные в его регистры (как и с любым другим устройством), его регистры расположены в памяти по адресу 0xFEE00000. На самом деле этот адрес может быть и другим, но его всегда можно узнать через специальный MSR (Model Specific Register – эти регистры читаются и записываются через инструкции rdmsr/wrmsr). Для всех ядер этот адрес чаще всего одинаковый, но у каждого ядра по этому адресу расположен свой личный LAPIC. Это устройство имеет множество регистров, но нам понадобится только один – ICR (Interrupt Control Register) который позволяет отправить IPI.
Для запуска какого-то ядра процессора этому ядру нужно отправить аж три IPI, которые заставят другое ядро включиться: INIT IPI, затем STARTUP IPI, и еще один STARTUP IPI.Второй STARTUP IPI (или SIPI) нужен для завершения процесса инициализации, поскольку первый мог быть отменен, а второй будет проигнорирован в случае, если первый SIPI прошел успешно. Ничего не поделаешь – такие правила. Для отправки каждого IPI нужно просто записать определенные байтики в ICR регистр своего LAPIC. Эти байтики будут включать в себя байт идентификатора LAPIC на который отправляться IPI, и тип отправляемого IPI. Для SIPI будет использоваться еще 2 байта, из которых будет определен адрес в памяти, с которого будет запускаться AP.
Последнее очень удобно, поскольку нам потребуется запустить процессор сперва с нашего кода, который переведет процессор в Protected Mode (да-да, процессор после INIT-SIPI-SIPI запускается в Real Mode, который нам не подходит). Код инициализации процессора будет рассмотрен подробно далее. Да, без сырого ассемблера не обойдемся.
Про LAPIC и IO APIC подробнее можно прочитать в мануале по процессору Intel.
Теперь осталось разобраться с несколькими мелочами: Lock, FPU и собственно алгоритмом Ray Tracing (полезной нагрузкой).
Первое, что нам еще понадобится – это возможность синхронизации работы всех ядер. Для этого нужно написать код Lock, который бы ожидал в памяти появления, например, единички. Как же сделать Lock правильно? Самый очевидный вариант: написать простой while(1), который ожидает появление по определенному адресу нолика, и сразу записать по этому адресу единицу, пока другие ядра этого сделать не успели. А для разблокировки замка нужно записать нолик.
Теперь FPU (Floating Point Unit) – это специальный модуль на процессоре, который используется для арифметических вычислений с плавающей запятой. Другими словами, если вы хотите использовать переменные типа float и double в своей программе, то вам нужно инициализировать этот модуль. Во всех современных ОС это делает за вас ядро ОС, но в нашем случае это придется самим. Впрочем, это совсем не трудно – просто пара инструкций на ассемблере. Float нам понадобится, поскольку Ray Tracing иначе не будет работать.
Как же будем делать Ray Tracing? Этот алгоритм выходит за рамки этой статьи, поэтому здесь объяснен не будет, но есть много хороших статей про него. Для нашего случая мы просто возьмем готовую программу и немного ее модифицируем.
Теперь, когда с теорией покончено, приступим к написанию программы.
! ВАЖНО!: Все дальнейшие действия могут успешно осуществляться только после успешного прохождения всех 6-ти шагов из третей части статьи “Как запустить программу без операционной системы”
Шаг 1. Сперва чистим лишнее.
В первую очередь нужно немного очистить имеющийся код от лишних файлов и функций. Нам понадобится полноценная математическая библиотека, поэтому нужно удалить лишние файлы из common: удаляем файл common/s_floor.c .
Рисовать фрактал нам не нужно – нам нужен Ray Tracing, поэтому можно удалить fractal.c. Но поскольку графический режим все же нужен, пишем следующий код в kernel.c:
1. добавляем несколько объявлений перед функцией main, которые в том числе задают разрешение экрана и картинки, которую будем рендерить:
i
nt vbe_screen_w = 800, vbe_screen_h = 600; int VBE_SetMode( ulong mode ); int VBE_Setup(int w, int h); extern ulong vbe_lfb_addr; extern ulong vbe_selected_mode; extern ulong vbe_bytes; //Про них будет написано позднее int ray_main(); void SmpPrepare(void); 2. меняем функцию main:
void main() { clear_screen(); printf("\n>>> Hello World!\n"); // Будет включать все ядра процессора SmpPrepare(); VBE_Setup(vbe_screen_w, vbe_screen_h); VBE_SetMode(vbe_selected_mode | 0x4000); // Будет инициировать рисование на экране ray_main(); } 3. удаляем строку:
void DrawFractal(void); Шаг 2. Добавляем математическую библиотеку fdlibm.
Теперь можно добавить полноценную математическую биьлиотеку. На самом деле нам понадобятся только функции sqrt, tan и pow – они используются в алгоритме Ray Tracing.
1. создаем в корне директорию fdlibm.
2. в эту директорию качаем библиотеку fdlibm отсюда. Закачать нужно все файлы из этой папки.
3. теперь нужно заменить makefile на более простой (заодно можно проверить список файлов). При компиляции будут использоваться те же флаги, что и в основном makefile в корне. При этом будет собираться простая библиотека fdlibm.a. Содержимое нового makefile:
CC = gcc CFLAGS = -Wall -fno-builtin -nostdinc -nostdlib -ggdb3 LD = ld OBJFILES = \ e_acos.o e_acosh.o e_asin.o e_atan2.o e_atanh.o e_cosh.o e_exp.o \ e_fmod.o e_gamma.o e_gamma_r.o e_hypot.o e_j0.o e_j1.o e_jn.o \ e_lgamma.o e_lgamma_r.o e_log.o e_log10.o e_pow.o e_remainder.o \ e_rem_pio2.o e_scalb.o e_sinh.o e_sqrt.o \ k_cos.o k_rem_pio2.o k_sin.o k_tan.o \ s_asinh.o s_atan.o s_cbrt.o s_ceil.o s_copysign.o s_cos.o s_erf.o s_expm1.o \ s_fabs.o s_finite.o s_floor.o s_frexp.o s_ilogb.o s_isnan.o s_ldexp.o s_lib_version.o \ s_log1p.o s_logb.o s_matherr.o s_modf.o s_nextafter.o s_rint.o s_scalbn.o s_signgam.o \ s_significand.o s_sin.o s_tan.o s_tanh.o \ w_acos.o w_acosh.o w_asin.o w_atan2.o w_atanh.o w_cosh.o w_exp.o w_fmod.o w_gamma.o \ w_gamma_r.o w_hypot.o w_j0.o w_j1.o w_jn.o w_lgamma.o w_lgamma_r.o w_log.o \ w_log10.o w_pow.o w_remainder.o w_scalb.o w_sinh.o w_sqrt.o k_standard.o all: fdlibm.a rebuild: clean all .s.o: as -o $@ $< .c.o: $(CC) -Ix86emu –I../include $(CFLAGS) -o $@ -c $< .cpp.o: $(CC) -Ix86emu -I. -Iustl –I../include $(CFLAGS) -o $@ -c $< fdlibm.a: $(OBJFILES) ar -rv fdlibm.a $(OBJFILES) ranlib fdlibm.a clean: rm -f $(OBJFILES) fdlibm.a 4. для того, чтобы все собиралось, внесем изменение в k_standard.c. Нужно объявить errno и определить пустую функцию fputs, которая без файловой системы и графическим дисплеем не имеет в нашем случае смысла. Для этого заменяем строки:
#ifndef _USE_WRITE #include <stdio.h> /* fputs(), stderr */ #define WRITE2(u,v) fputs(u, stderr) #else /* !defined(_USE_WRITE) */ на строки:
void fputs(void *u, int stderr) { } int errno = 0; #ifndef _USE_WRITE #define WRITE2(u,v) fputs(u, 0) #else /* !defined(_USE_WRITE) */ Шаг 3. Добавляем необходимые определения и заголовки
Как обычно, нужно немного расширить определения, которые будут использоваться далее в программе.
1. в этот раз будет использоваться С++, даже с шаблонами, поэтому, для избегания ряда ошибок нужно исправить файл include/string.h. В нем надо добавить явное приведение типов во всех местах, где преобразуется void* в char*. У меня это оказались строки: 42, 53,54,79,80. Везде аналогичное изменение, например, исправленная строка 42 выглядит так:
p = (char *)addr;
2. Нужно добавить несколько определений для математической библиотеки. К ним относятся несколько глобальных определений переменных, несколько типов, несколько констант и кодов ошибок, которые использует fdlibm. В итоге, добавляем в include/types.h следующий код (перед последним #endif в конце файла):
typedef unsigned long long u64; #define FLT_MAX 1E+37 #define DBL_MAX 1E+37 #define LDBL_MAX 1E+37 # ifndef INFINITY # define INFINITY (__builtin_inff()) # endif #define NUM 3 #define NAN 2 #define INF 1 #define M_PI 3.14159265358979323846 /* pi */ #define __PI 3.14159265358979323846 #define __SQRT_HALF 0.70710678118654752440 #define __PI_OVER_TWO 1.57079632679489661923132 typedef const union { long l[2]; double d; } udouble; typedef const union { long l; float f; } ufloat; extern double BIGX; extern double SMALLX; 3. добавляем файл include/errno.h со следующим кодом:
#ifndef _ERRNO_H #define _ERRNO_H extern int errno; #define EDOM -6 #define ERANGE -8 #endif 4. теперь, нужно добавить много определений, связанных с аппаратурой, настройкой SMP, ACPI, LAPIC и функций настройки специальных регистров процессора. Для этого создаем файл include/hardware.h, в который добавляем следующий код. В этот раз мы разместили два файла с готовым кодом на github. Это связано с тем, что кода получилось относительно много (~500 строк), поэтому в рамках статьи его писать неудобно. Подчеркиваем, что код снабжен большим количеством комментариев на русском языке, поэтому код на github можно считать продолжением статьи. В самом пункте мы приведем содержание файла:
a. определения структур, использующихся для разбора ACPI таблиц. Этот код сформирован на основе официальной спецификации ACPI. Код содержит только определения для таблиц, необходимых нам (RSDP, RSDT, MADT).
b. далее в файле идет объявление нескольких функций inline содержащих ассемблерные инструкции. По большей части функции очень маленькие, хоть и выглядят громоздкими из-за особенностей использования ассемблера в gcc, где типичная конструкция выглядит так: __asm__ __volatile__ ("<инструкции>": <выходные параметры>: <входные параметры>); Код этих функций по названиям можно найти в интернете в разных местах, как в коде FreeBSD, Linux, так и таких проектов как Bitvisor. Нам же понядобятся следующие функции: rdtsc, __rdmsr, __rdmsrl, __wrmsr, __wrmsrl, __rep_nop и __cpuid_count, __get_cr0, __set_cr0.
c. особо хочется выделить две функции, которые мы назвали SmpSpinlock_LOCK и SmpSpinlock_UNLOCK. Обе функции взяты из orangetide.com/src/bitvisor-1.3/include/core/spinlock.h и так же написаны на ассемблере. Они представляют собой функции работы с объектом синхронизации для ядер процессора, работающих одновременно. Это простые замки. Суть их работы проста: в качестве замка используется один байт в памяти, который может принимать значение 0 или 1. Если 0 – то замок открыт, а если 1 – то закрыт. Суть функции SmpSpinlock_LOCK сводится к ожиданию значения 0 в байте замка и установки этого байта в значение 1. Для ожидания используется обычный цикл с примененим инструкции “pause”, которая позволяет оптимизировать работу процессора и снизить его энергопотребление при циклах ожидания. Для чтения и одновременной установки значения 1 в байт памяти используется инструкция “xchg”, которая позволяет атомарным образом выполнить обмен значениями между памятью и регистром. Атомарность означает, что другое ядро процессора не сможет нарушить работу этой инструкции и вклинится в середину ее работы.
d. далее в коде hardware.h содержится описание нескольких констант, связанных с LAPIC. Они взяты из документации Intel.
e. в конце файла объявлена еще одна ассемблерная функция __enable_fpu, которая осуществляет включение FPU на процессоре. Напомним, что это необходимо для работы с типами float. Функция представляет собой выполнение двух инструкций: “fnclex” и “fninit”, которые необходимы для включения FPU на ядре.
Шаг 4. Добавляем код инициализации ядер процессора.
Теперь, можно приступить к созданию файла smp.c, который будет содержать функции для работы с несколькими ядрами процессора. Самая главная часть этого файла: код на ассемблере, который будет выполняться на вновь запущенных ядрах. Код smp.c так же расположен на github и снабжен большим количеством комментариев с пояснениями; часть кода пришлось собирать из множества источников в интернете, часть пришлось писать самому. Дело в том, что настройка многоядерности – дело специфическое для каждой ОС, поэтому код содержит много того, что нужно именно конкретной ОС. Целью автора статьи было упрощение подобного кода, чтобы можно было продемонстрировать суть происходящего и того минимума действий, которые необходимо совершить для использования SMP. Код smp.c содержит две части:
1. код для поиска и включения каждого AP. Начало всей инициализации происходит с вызовом функции SmpPrepare. Для работы некоторых подфункций требуется соблюдение не большой задержки времени. Правильно эти задержки делать с использованием таймера или CMOS, но для примера используется задержка, основанная на ожидании определенного значения счетчика TSC (счетчик тактов процессора, прошедших с начала его работы). В рамках SmpPrepare выполняются следующие шаги:
- a. проверка наличия LAPIC при помощи CPUID.
- b. получение базового адреса LAPIC через MSR.
- c. получение указателей на две части 64-х битного регистра ICR. Это обычные указатели на определенную область в памяти. Они будут использоваться для отправки IPI.
- d. затем ищется адрес RSDP. По нему определяется адрес таблицы TSDT. В таблице RSDT находится адрес на MADT. Сканируется вся таблица MADT и в ней анализируются все записи относящиеся к Local APIC. Каждая такая запись содержит LAPIC ID и флаг включенности ядра. В итоге собирается массив всех найденных и включенных LAPIC ID, которые есть в системе.
- e. следующий шаг – резервирование памяти пот стек каждого ядра процессора. Стек выделяется по 64Кб и располагается начиная с 5-го мегабайта физической памяти.
- f. затем по физическому адресу 0x6000 копируется ассемблерный код, который инициализирует каждое ядро AP. Про этот код описано далее.
- g. после этого выполняется запуск каждого AP ядра процессора. Для этого каждому ядру последовательно отправляются INIT-SIPI-SIPI сигналы, путем записи определенных байтов в ICR. Этот код взят из (http://fxr.watson.org/fxr/source/i386/i386/mp_machdep.c ). Для выполнения код используется LAPIC ID полученные ранее и вектор 6, соответствующий адресу 0x6000 по которому располагается на код инициализации.
- h. затем BSP ожидает включения всех ядер процессора, для чего он ожидает момента, когда счетчик включенных ядер сравняется с общим их количеством. Каждое ядро AP увеличивает этот счетчик на 1.
- i. на этом функция завершает свою работу.
2. код, выполняющийся на каждом AP. Этот код начинается с ассемблера. Расположен сразу в начале файла smp.c. У этого ассемблерного кода каждая строка прокомментирована. Если описывать этот ассемблерный код кратко, то он выполняет следующие действия:
- a. сборс нескольких флагов во флаговом регистре, и обнуление базовых регистров для начала работы.
- b. включение в cr0 защищенного режима без страничной адресации.
- c. переход на 32-х битный сегмент кода.
- d. загрузка GDTR и всех сегментов как 32-х битные (код и данные) .
- e. чтение базового адреса LAPIC из MSR.
- f. чтение регистра LAPIC для определения своего ID (для текущего ядра).
- g. получение указателя на стек для текущего ядра. Для каждого ядра заранее резервируется память под его личный стек.
- h. вызов функции на C (SmpApMain).
В функции SmpApMain определяется индекс процессора. Индекс – это его номер от 0 до N – где N-1 – это общее количество ядер на компьютере. Затем синхронно увеличивается счетчик запущенных ядер, который используется для ожидания запуска всех процессоров. Потом ядро процессора переходит в ожидание включения флага запуска полезной нагрузки. Как только флаг включается вызывается функция ap_cpu_worker – которая и выполняет полезную нагрузку (Ray-Tracing).
Шаг 5. Добавление Алгоритма Ray Tracing.
Самая сложная часть позади. Теперь нужно добавить полезную нагрузку в виде алгоритма Ray Tracing. Сам алгоритм выходит за рамки этой статьи, поэтому теорию и практику можно получить на этих ресурсах . Код Ray Tracing комментировать не будем. Вместо этого мы возьмем за основу готовый код и расскажем, как его нужно поменять, для того, чтобы он скомпилировался в нашей программе. За основу возьмем код отсюда. В нем надо будет удалить динамическое выделение памяти и STL, заменив все на статический массив. Затем, нужно исправить функцию render так, чтобы она могла рендерить только область картинки по строкам. Последнее, нужно будет реализовать функцию ap_cpu_worker, которая вызывает render с определенными параметрами.
1. создать файл ray.cpp. В него скопировать итоговый код.
2. заменить в нем строки:
#include <cstdlib> #include <cstdio> #include <cmath> #include <fstream> #include <vector> #include <iostream> #include <cassert> На строки:
extern "C" { #include "types.h" #include "printf.h" #include "string.h" #include "hardware.h" double tan(double x); double sqrt(double x); double pow (double x, double y); extern int vbe_screen_w; extern int vbe_screen_h; extern ulong vbe_lfb_addr; extern ulong vbe_bytes; extern u32 cpu_count; extern ulong SmpStartedCpus; void SmpReleaseAllAps(); } namespace std { template <class T> const T& max (const T& a, const T& b) { return (a<b)?b:a; // or: return comp(a,b)?b:a; for version (2) } template <class T> const T& min (const T& a, const T& b) { return !(b<a)?a:b; // or: return !comp(b,a)?a:b; for version (2) } } 3. удалить следующие строки:
friend std::ostream & operator << (std::ostream &os, const Vec3<T> &v) { os << "[" << v.x << " " << v.y << " " << v.z << "]"; return os; } и эти:
// Save result to a PPM image (keep these flags if you compile under Windows) std::ofstream ofs("./untitled.ppm", std::ios::out | std::ios::binary); ofs << "P6\n" << width << " " << height << "\n255\n"; for (unsigned i = 0; i < width * height; ++i) { ofs << (unsigned char)(std::min(T(1), image[i].x) * 255) << (unsigned char)(std::min(T(1), image[i].y) * 255) << (unsigned char)(std::min(T(1), image[i].z) * 255); 4. заменить:
const std::vector<Sphere<T> *> &spheres, const int &depth) На:
const Sphere<T> **spheres, unsigned spheres_size, const int &depth) 5. во всем файле ray.cpp заменить spheres.size()на spheres_size (всего 3 замены).
6. заменить функцию render таким образом:
void render(const Sphere<T> **spheres, unsigned spheres_size, unsigned y_start, unsigned y_end) { Vec3<T> pixel; T invWidth = 1 / T(vbe_screen_w), invHeight = 1 / T(vbe_screen_h); T fov = 30, aspectratio = vbe_screen_w / T(vbe_screen_h); T angle = tan(M_PI * 0.5 * fov / T(180)); // Trace rays for (unsigned y = y_start; y < y_end; ++y) { for (unsigned x = 0; x < (unsigned)vbe_screen_w; ++x) { T xx = (2 * ((x + 0.5) * invWidth) - 1) * angle * aspectratio; T yy = (1 - 2 * ((y + 0.5) * invHeight)) * angle; Vec3<T> raydir(xx, yy, -1); raydir.normalize(); pixel = trace(Vec3<T>(0), raydir, spheres, spheres_size, 0); // Формируем цвет int color = ((int)(pixel.x * 255) << 16) | ((int)(pixel.y * 255) << 8) | (int)(pixel.z * 255); // Рисуем точку на экране *(int *)((char *)vbe_lfb_addr + y * vbe_screen_w * vbe_bytes + x * vbe_bytes + 0) = color & 0xFFFFFF; } } } 7. соответственно во всем файле исправить два оставшихся вызова функции trace, добавив еще один параметр spheres_size:
Vec3<T> reflection = trace(phit + nhit * bias, refldir, spheres, depth + 1); заменить на:
Vec3<T> reflection = trace(phit + nhit * bias, refldir, spheres, spheres_size, depth + 1) ;
и это:
refraction = trace(phit - nhit * bias, refrdir, spheres, depth + 1) ;
на:
refraction = trace(phit - nhit * bias, refrdir, spheres, spheres_size, depth + 1) ;
8. в конце файла вместо функции main дописываем функцию ray_main и ap_cpu_worker:
#define RAY_SHAPES_COUNT 6 Sphere<float> *ray_spheres[RAY_SHAPES_COUNT]; extern "C" void ap_cpu_worker( int index ) { __enable_fpu(); render<float>((const Sphere<float> **)ray_spheres, 6, vbe_screen_h/cpu_count * index, vbe_screen_h/cpu_count * index + vbe_screen_h/cpu_count); forever(); } extern "C" int ray_main() { Sphere<float> sp1 (Vec3<float>(0, -10004, -20), 10000, Vec3<float>(0.2), 0, 0.0); Sphere<float> sp2 (Vec3<float>(0, 0, -20), 4, Vec3<float>(1.00, 0.32, 0.36), 1, 0.0); Sphere<float> sp3 (Vec3<float>(5, -1, -15), 2, Vec3<float>(0.90, 0.76, 0.46), 1, 0.0); Sphere<float> sp4 (Vec3<float>(5, 0, -25), 3, Vec3<float>(0.65, 0.77, 0.97), 1, 0.0); Sphere<float> sp5 (Vec3<float>(-5.5, 0, -15), 3, Vec3<float>(0.90, 0.90, 0.90), 1, 0.0); Sphere<float> sp6 (Vec3<float>(0, 20, -30), 3, Vec3<float>(0), 0, 0, Vec3<float>(3)); ray_spheres[0] = &sp1; ray_spheres[1] = &sp2; ray_spheres[2] = &sp3; ray_spheres[3] = &sp4; ray_spheres[4] = &sp5; ray_spheres[5] = &sp6; SmpReleaseAllAps(); ap_cpu_worker(0); forever (); return 0; } Шаг 6. Последние доработки и запуск.
Остается только доработать makefile, чтобы все скомпилировалось. Для этого внесем следующие изменения:
1. обновим OBJFILES:
OBJFILES = \ loader.o \ common/printf.o \ common/screen.o \ common/bios.o \ common/vbe.o \ common/qdivrem.o \ common/udivdi3.o \ common/umoddi3.o \ common/divdi3.o \ common/moddi3.o \ common/setjmp.o \ common/string.o \ x86emu/x86emu.o \ x86emu/x86emu_util.o \ smp.o \ ray.o \ kernel.o 2. добавим цель для компиляции C++:
.cpp.o: $(CC) -Ix86emu -I. -Iustl -Iinclude $(CFLAGS) -o $@ -c $< 3. далее нужно изменить строку вызова компановщика для подключения новой библиотеки:
$(LD) -T linker.ld -o $@ $^ fdlibm/fdlibm.a 4. теперь нужно собрать библиотеку:
cd fdlibm make rebuild 5. теперь можно пересобрать проект:
make rebuild sudo make image 6. запускаем проект с опцией эмуляции 4-х ядерного процессора, чтобы убедиться, что все работает:
sudo qemu-system-i386 -hda hdd.img –smp 4 Если все сделано правильно, то мы должны увидеть вот такую красоту:
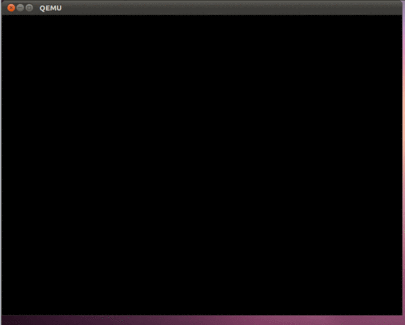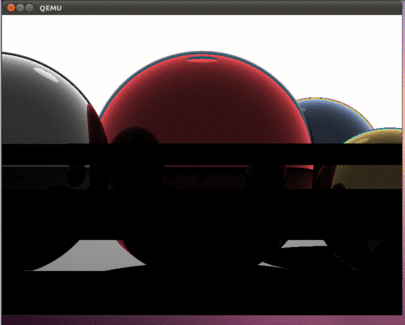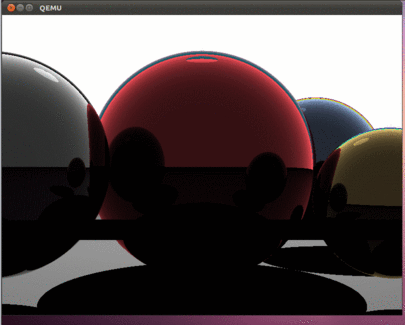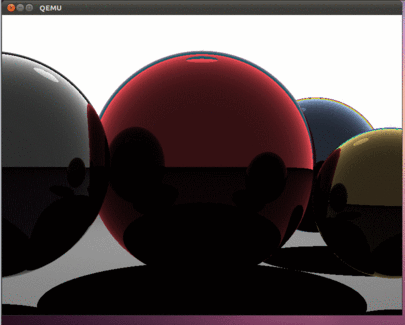
Как и в предыдущих частях статьи, при помощи команды dd можно скопировать образ hdd.img на флешку и проверить работу программы на реальном компьютере.
В итоге получилась интересная программа, которая использует все ядра современных процессоров. Эта статья открывает возможности по разработке программ, которые заточены под трудоемкие вычисления. Важно отметить, что как и в прежних статьях, операционной системы нет, поэтому все вычисления выполняются с задействованием всех имеющихся аппаратных ресурсов. В программе даже не обрабатываются прерывания – они просто выключены. Поэтому то с какой скоростью все будет рисоваться и будет определять реальные вычислительные возможности вашего процессора. Конечно это все верно, если программа выполняется на голом железе. Наш Intel i5 тратит примерно 800 милисекунд на рисование этой картинки. Будет интересно увидеть в комментариях информацию о скорости, которая у вас получилась на реальном железе.
ссылка на оригинал статьи http://habrahabr.ru/company/neobit/blog/181626/
Добавить комментарий