Предыстория
Года два назад, руководство решило вложиться в проект виртуализации нашего датацентра. Задача стояла достаточно простая, около 50 серверов, в основном Windows, пара линукс машин, ничего нестандартного. Датацентры хоть и небольшой но очень гордый важный, являемся европейской штаб-квартирой крупной организации – хостим сервисы для 30 стран (Европа+СНГ).Два датацентра, связь надежная и дублированная, по определенным причинам выбрали связку VMWare ESXi (4 затем 5) и HP Lefthand P4000(первый транш) и P4500 (второй транш). Причины чисто субъективные, VMWare и HP являются стратегическими партнерами и т.д.
Что случилось?
По принятым правилам, два раза в год тестируем избыточность и отказоустойчивость (redundancy & failover), в случае с виртуализированными сервисами мы решили разделить процесс на два этапа. Первым этапом было симулирование сбоя только хостов гипервизора (мы реально вырубили питание – грубовато, но именно так описан процесс тестирования в документации). Как и ожидалось, VMWare HA и FT сработали как надо, комитет выставил галочки в протоколах и подписался. На втором этапе, вместе с гипервизорами вырубили и устройства хранения (LeftHand) и … чуда не произошло. В HP Centralized Management Console ошибка, данные недоступны, хотя резервные устройства включены и доступны,… но кворума нет. Восстановить работоспособность не удалось – пришлось срочно все включать обратно, никакого фейловера добиться не удалось.
Начали выяснять.
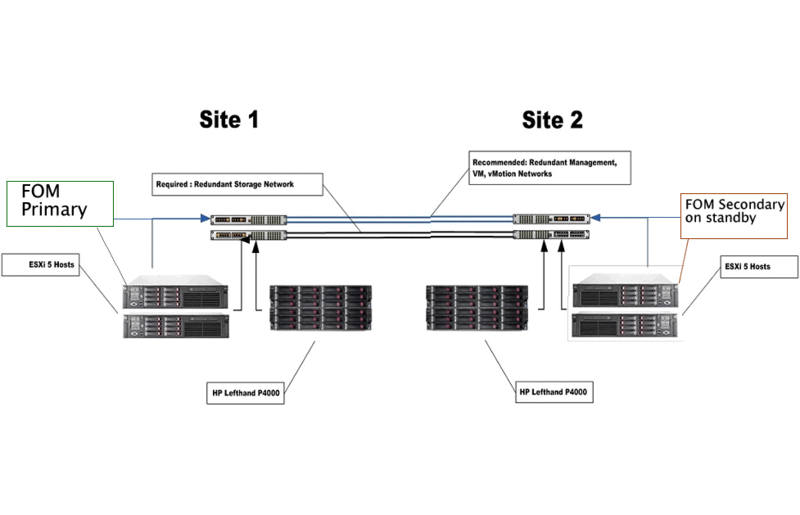
Мы знали, для автоматического фейловера нужны 3 дата центра — на pre-sales встречах представители HP об этом многократно нас предупреждали. Админы на встречи не приглашались, уточняющие вопросы не задавались, руководство почему-то решило что «автоматический фейловер возможен только с 3-мя дата центрами» подразумевает что «если вручную, то и двух датацентров достаточно». Ан нет, в ответ на запрос, HP Support ответил что ни вручную, ни автоматически без третьего дата центра фейловер невозможен. Принцип похож на описанный здесь ( в нашем случае системы несколько отличаются – но в общем, тот же случай). Короче, все завязано на Failover Manager (FOM) – он в момент сбоя основного устройства должен быть доступен из сети резервного дата центра – во избежание ситуации параллельного функционирования – split brain. Сам FOM никаких данных не содержит, и нужен только в случае сбоя, к качестве свидетеля (witness). Для функционирования FOM, который является обычной виртуальной машиной с более чем скромными требованиями (2Ghz,1GB RAM, 13Gb HDD) нужен только доступ в наш iSCSI VLAN. Мы сразу прикинули и представили руководству вариант Windows сервера в облаке с VPN в наш iSCSI VLAN и бесплатным VMWare Server для запуска FOM… но проект был отклонен с комментариями: а) Автоматический фейловер не нужен; б) использование cloud-hosted серверов в сети хранения данных противоречит ИБ политике.Руководством была поставлена задача: решить проблему без использования облака и обеспечить возможность ручного переключения между основным и резервными устройствами хранения.
Короче, все завязано на Failover Manager (FOM) – он в момент сбоя основного устройства должен быть доступен из сети резервного дата центра – во избежание ситуации параллельного функционирования – split brain. Сам FOM никаких данных не содержит, и нужен только в случае сбоя, к качестве свидетеля (witness). Для функционирования FOM, который является обычной виртуальной машиной с более чем скромными требованиями (2Ghz,1GB RAM, 13Gb HDD) нужен только доступ в наш iSCSI VLAN. Мы сразу прикинули и представили руководству вариант Windows сервера в облаке с VPN в наш iSCSI VLAN и бесплатным VMWare Server для запуска FOM… но проект был отклонен с комментариями: а) Автоматический фейловер не нужен; б) использование cloud-hosted серверов в сети хранения данных противоречит ИБ политике.Руководством была поставлена задача: решить проблему без использования облака и обеспечить возможность ручного переключения между основным и резервными устройствами хранения.
И вот как мы проблему решили:
- На одном из ESXi хостов в резервном дата центре активируем локальное хранилище (чтобы обеспечить доступ в случае сбоя SAN)
- Создаем полную копию основного FOM (копируем все, и самое главное MAC-адрес виртуальной сетевой карты подключенной к iscsi сети) на хосте в резервном дата центре
- Оставляем FOM в резервном дата центре в режиме StandByИ все, при сбое в основной системы, FOM в резервном дата центре выводим из режима StandBy, и он полностью подменяет собой недоступный основной FOM. При возвращении в штатный режим, надо только не забыть вернуть его обратно в режим StandBy.
ссылка на оригинал статьи http://habrahabr.ru/post/181956/
Добавить комментарий