Вариантов таких спонтанных хотелок (особенно при наличии времени) много и все из серии украшательств, не несущих по сути никакой смысловой нагрузки — но вот хочется и все 🙂
В данной мини-статье я рассмотрю одну из таких «хотелок».
Допустим у вас есть список элементов, отображаемый в TListView, вы пробуете его отсортировать и получаете вот такой результат.
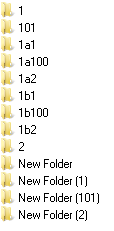
Не красиво, почему это второй элемент с именем «101» находится не на своем месте? Ведь это число, а стало быть место ему как минимум после элемента с именем «2». Да и «New Folder (101)» явно должна быть после «New Folder (2)». Ведь в проводнике все выглядит нормально.
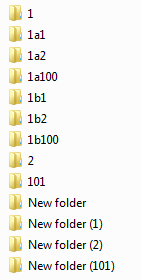
Попробуем разобраться в причинах такого поведения и реализовать алгоритм более правильной, с точки зрения человека, сортировки.
Для начала давайте разберемся в причинах неверной сортировки.
По умолчанию в TListView для сравнения строк используется функция lstrcmp, которая сравнивает строки посимвольно.
К примеру если взять две строки «1» и «2», то первая строка должна располагаться над второй, т.к. символ единицы идет перед двойкой. Однако если вместо первой строки взять «101», функция lstrcmp так-же скажет что данная строка должна идти первой, ибо в этом случае она принимает решение по результату сравнения самого первого символа обеих строк, не учитывая тот факт что обе строки являются строковым представлением чисел.
Немножко усложним, возьмем строки «1a2» и «1a101» на которых lstrcmp опять выдаст неверный результат, сказав что вторая строка должна идти первой. Это решение она принимает на основе результата сравнения третьего символа обеих строк, не смотря на то что в данном случае они так-же являются строковыми представлениями чисел.
С причинами разобрались, теперь думаем решение.
Раз lstrcmp ошибается на сравнении, интерпретируя части чисел в виде символов, нужно реализовать аналогичный ей алгоритм сравнения, в котором числа будут сравниваться именно как числа, а не как символы.
Алгоритмически это сделать достаточно просто.
Возьмем опять-же «1a2» и «1a101». Разобьем их на отдельные составляющие, где символы будут отделены от чисел. Если представить первую строку в виде «1 + a + 2», а вторую в виде «1 + a + 101» то получится что нам нужно выполнить всего три сравнения.
1. Число с числом
2. Символ с символом
3. Опять число с числом
Итог такого сравнения будет верный и покажет что вторая строка действительно должна идти второй, а не первой, как нам об этом сообщала lstrcmp.
Теперь продумаем ТЗ к реализации данного алгоритма.
Очевидно что:
1. Если одна из строк, переданная для сравнения пустая — она должна идти выше первой.
2. Если обе строки пустые — они идентичны.
3. Регистр строк при сравнении не учитывается.
4. Для анализа строк используем курсор содержащий адрес текущего анализируемого символа каждой строки.
5. Если курсор одной из строк содержит число, а курсор другой строки содержит символ — первая строка выше второй.
6. Если курсоры строк указывают на символ — сравнение происходит по аналогу lstrcmp
7. Если курсоры строк указывают на число — извлекаем оба числа и сравниваем их между собой.
7.1 Если оба числа равны нулю (к примеру «00» и «0000») то вверх помещается число с меньшим количеством нулей.
8. Если в процессе анализа курсор любой из строк обнаружил терминирующий ноль — эта строка идет выше.
8.1 Если в этот-же момент курсор второй строки тоже находится на терминирующем нуле — строки идентичны.
Для реализации алгоритма, данного ТЗ более чем достаточно.
Собственно реализуем:
// // CompareStringOrdinal сравнивает две строки по аналогу проводника, т.е. // "Новая папка (3)" < "Новая папка (103)" // // Возвращает следующие значения // -1 - первая строка меньше второй // 0 - строки эквивалентны // 1 - первая строка больше второй // ============================================================================= function CompareStringOrdinal(const S1, S2: string): Integer; // Функция CharInSet появилась начиная с Delphi 2009, // для более старых версий реализуем ее аналог function CharInSet(AChar: Char; ASet: TSysCharSet): Boolean; begin Result := AChar in ASet; end; var S1IsInt, S2IsInt: Boolean; S1Cursor, S2Cursor: PChar; S1Int, S2Int, Counter, S1IntCount, S2IntCount: Integer; SingleByte: Byte; begin // Проверка на пустые строки if S1 = '' then if S2 = '' then begin Result := 0; Exit; end else begin Result := -1; Exit; end; if S2 = '' then begin Result := 1; Exit; end; S1Cursor := @AnsiLowerCase(S1)[1]; S2Cursor := @AnsiLowerCase(S2)[1]; while True do begin // проверка на конец первой строки if S1Cursor^ = #0 then if S2Cursor^ = #0 then begin Result := 0; Exit; end else begin Result := -1; Exit; end; // проверка на конец второй строки if S2Cursor^ = #0 then begin Result := 1; Exit; end; // проверка на начало числа в обоих строках S1IsInt := CharInSet(S1Cursor^, ['0'..'9']); S2IsInt := CharInSet(S2Cursor^, ['0'..'9']); if S1IsInt and not S2IsInt then begin Result := -1; Exit; end; if not S1IsInt and S2IsInt then begin Result := 1; Exit; end; // посимвольное сравнение if not (S1IsInt and S2IsInt) then begin if S1Cursor^ = S2Cursor^ then begin Inc(S1Cursor); Inc(S2Cursor); Continue; end; if S1Cursor^ < S2Cursor^ then begin Result := -1; Exit; end else begin Result := 1; Exit; end; end; // вытаскиваем числа из обоих строк и сравниваем S1Int := 0; Counter := 1; S1IntCount := 0; repeat Inc(S1IntCount); SingleByte := Byte(S1Cursor^) - Byte('0'); S1Int := S1Int * Counter + SingleByte; Inc(S1Cursor); Counter := 10; until not CharInSet(S1Cursor^, ['0'..'9']); S2Int := 0; Counter := 1; S2IntCount := 0; repeat SingleByte := Byte(S2Cursor^) - Byte('0'); Inc(S2IntCount); S2Int := S2Int * Counter + SingleByte; Inc(S2Cursor); Counter := 10; until not CharInSet(S2Cursor^, ['0'..'9']); if S1Int = S2Int then begin if S1Int = 0 then begin if S1IntCount < S2IntCount then begin Result := -1; Exit; end; if S1IntCount > S2IntCount then begin Result := 1; Exit; end; end; Continue; end; if S1Int < S2Int then begin Result := -1; Exit; end else begin Result := 1; Exit; end; end; end; Смотрим результат работы данного алгоритма.
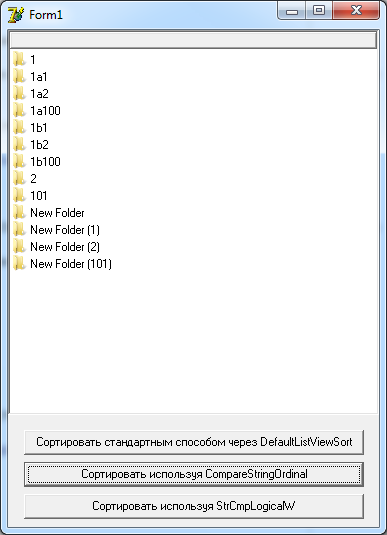
Собственно что и ожидалось.
Очередная «украшалка» готова 🙂
Можно конечно сказать что это велосипед и нужно использовать StrCmpLogicalW:
msdn.microsoft.com/en-us/library/windows/desktop/bb759947
Чтож, попробуйте — третья кнопка отвечает за такую сортировку.
Обратите внимание на первые пять элементов списка после сортировки.
Хоть они и похожи на то, что отобразит проводник, но не совсем верны. Ну не должен элемент с именем «0» располагаться под элементом «00» и прочими 🙂
Исходный код демо-примера можно забрать по данной ссылке.
© Александр (Rouse_) Багель
Июнь, 2013
ссылка на оригинал статьи http://habrahabr.ru/post/181760/
Добавить комментарий