
Тема этой статьи – определение пороговых значений метрик здоровья ИТ-инфраструктуры, соответствующих комфортной работе пользователей ИТ-сервисов. Я рассмотрю, как сделать так, чтобы пороговые значения метрик здоровья (производительности, доступности и т.п.) ИТ-инфраструктуры соответствовали тому, что пользователи считают комфортной работой с ИТ-сервисом, а также зачем всё это нужно.
Статья предназначена для провайдеров ИТ-сервисов, системных администраторов и всех, кто хочет настроить мониторинг ИТ-инфраструктуры и/или производительности и доступности ИТ-сервисов, но не знает, как это сделать.
Введение
Цель любого мониторинга – узнавать о сбое до того, как он скажется на работе пользователей, клиентов и т.п. Для того чтобы система мониторинга вовремя обнаружила сбой и оповестила о нём системного администратора или службу поддержки, необходимо:
- Знать, какие метрики необходимо контролировать.
- Правильно установить пороговые значения контролируемых метрик.
Ответы на эти вопросы могут быть как простыми, так и сложными, и зависят от того, что ИТ-служба понимает под сбоем.
Некоторое время назад компания HP предложила классифицировать ИТ-службы по уровню зрелости: поставщик ИТ-инфраструктуры, провайдер ИТ-сервисов, бизнес-партнёр. Воспользуемся предложенной классификацией и рассмотрим, что является сбоем для первых двух случаев – поставщика ИТ-инфраструктуры и провайдера ИТ-сервисов, а также как в этих случаях определяются метрики и устанавливаются пороговые значения. Третий случай (бизнес-партнёрство) по причине его сложности и глобальности рассмотрим в одной из следующих статей.
| Уровень ИТ-службы | Что такое сбой |
|---|---|
| Поставщик ИТ-инфраструктуры | В ИТ-инфраструктуре что-то неисправно |
| Провайдер ИТ-сервисов | Пользователи не могут использовать ИТ-сервис для выполнения своих обязанностей |
| Бизнес-партнёр | Остановился или тормозит бизнес-процесс |
Сбой для поставщика ИТ-инфраструктуры: В ИТ-инфраструктуре что-то неисправно
В простейшем случае сбой – это неисправность в ИТ-инфраструктуре. Информация о метриках в этом случае содержится в MIB (Management Information Base). Пороговые значения устанавливаются тремя способами:
- Если метрика измеряется в процентах (утилизация, доступность и т.п.), то методом здравого смысла.
- Для большинства значимых метрик есть референтные значения, содержащиеся в рекомендациях производителей ПО и железа. Значительную часть этой информации мы систематизировали и результаты можно найти на сайте http://www.you-expert.ru, раздел «Экспертизы».
- Если п.1 и п.2 невозможны, то используется Метод Базовых Линий.
Метод Базовых Линий
Базовая Линия – это метрика или набор метрик, характеризующих нормальную (обычную) работу ИТ-инфраструктуры. Чтобы построить Базовую Линию, нужно статистически обработать результаты измерений, полученные за длительный период времени, например, за месяц, и получить усреднённое значение, которое принимается за норму. Значение, превышающее (по модулю) норму, например, на 10%, 30% или 50% (определяется интуитивно) — принимается в качестве порогового значения, соответствующего оценке «плохо».
Существует много способов вычисления и видов представления Базовых Линий. В простейших системах мониторинга это может быть среднее значение метрики, отображаемое в виде прямой линии, пересекающей график измеряемой метрики. В профессиональных системах это несколько статистических оценок (как правило, перцентиль), привязанных ко времени. Это означает, что значения Базовой Линии, например, в 7-00 и в 11-00 – это два разных значения. На Рисунках 2 и 3 показаны примеры Базовых Линий, автоматически вычисляемых продуктами ProLAN. Базовая Линия 20 оценивает метрики в 20-минутных интервалах и имеет вид таблицы. Базовая Линия 60 оценивает метрики в 60-минутных интервалах и имеет вид трёх графиков: среднее значение, перцентиль 75 (отбрасывается 25% худших значений), перцентиль 90 (отбрасывается 10% худших значений).
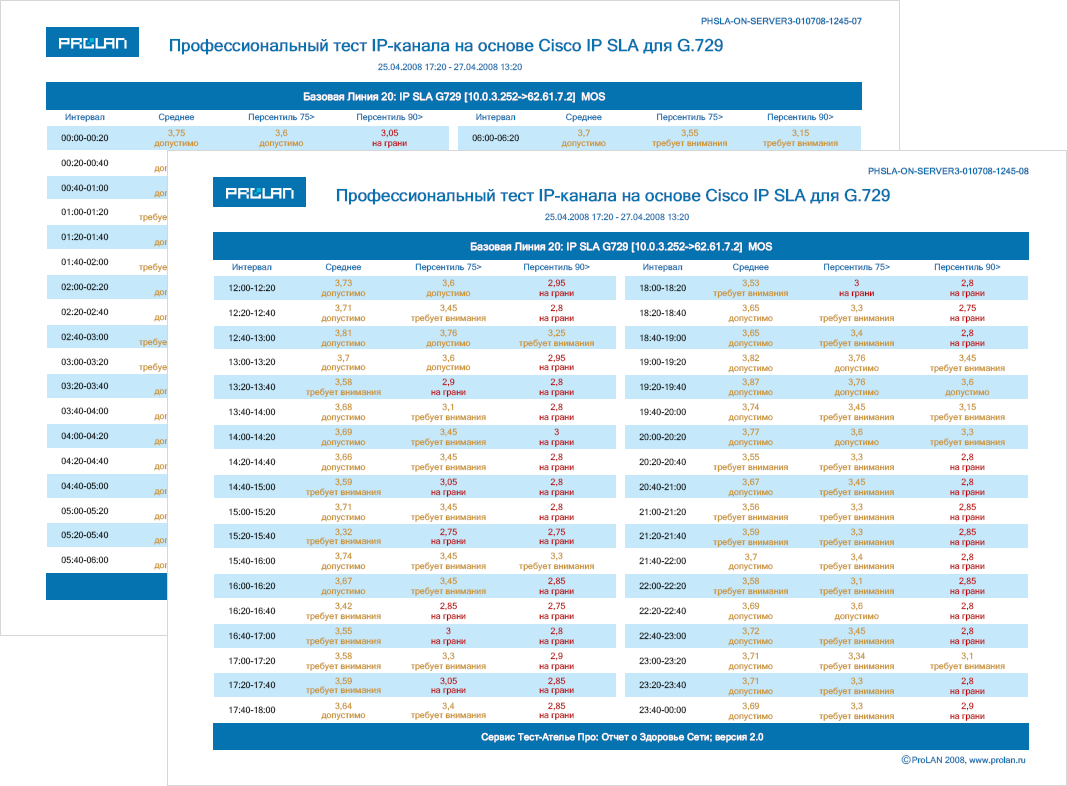
Рисунок 2. Базовая Линия 20.
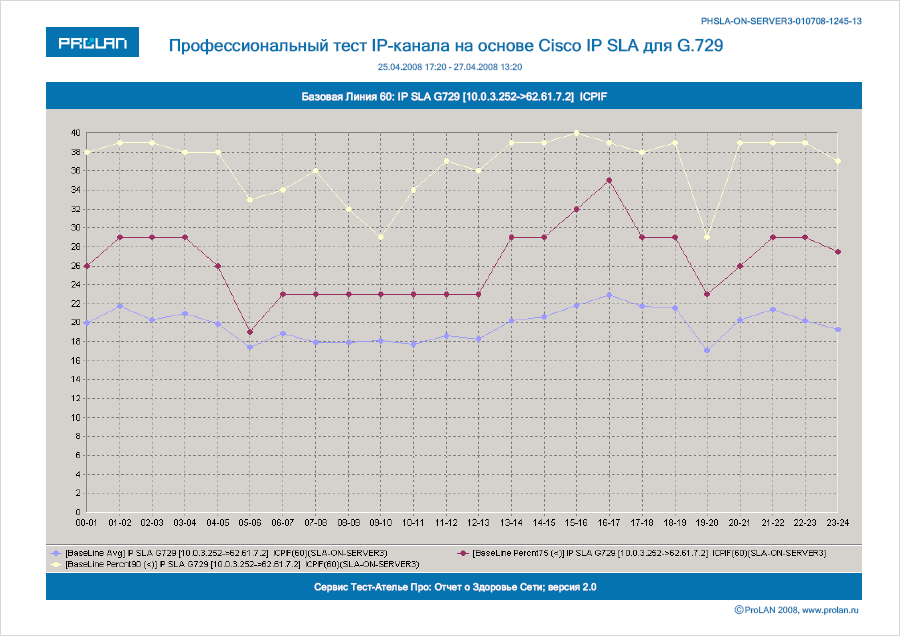
Рисунок 3. Базовая Линия 60.
Сбой для провайдера ИТ-сервисов: Пользователи не могут использовать ИТ-сервис для выполнения своих обязанностей
По сравнению с неисправностью в ИТ-инфраструктуре этот случай более сложный и более интересный. Значимость его определяется тем, что доступность ИТ-сервисов – это основная составляющая SLA (Service Level Agreement).
Часто, чтобы упростить себе жизнь, ИТ-служба трактует доступность ИТ-сервиса как доступность всех задействованных компонентов ИТ-инфраструктуры. Такое упрощение простительно небольшому аутсорсеру (de facto поставщику ИТ-инфраструктуры), но не зрелому поставщику ИТ-сервисов, т.к. это объективно неправильно. Классический пример – ip-телефония. Все компоненты ИТ-инфраструктуры, поддерживающие связь между абонентами, могут быть исправны и технически функционировать, но качество связи при этом ужасно настолько, что пользоваться сервисом невозможно (звук булькает, изображение замирает). Поэтому доступность ИТ-сервиса – это не техническая метрика, и для её измерения недостаточно пинговать оборудование.
Нужно либо определить, при каких значениях каких метрик сервис работает хорошо, а при каких – не очень, либо замерять время реакции бизнес-приложений(end-to-end response time).
Рассмотрим оба способа подробнее.
Первый способ – измерять время реакции бизнес-приложений (end-to-end response time). Для того чтобы измерять время реакции бизнес-приложений, нужны специальные метрики и специальных измерительные средства. Можно использовать GUI-роботы (мы используем AutoIT, интегрированный со SLA-ON Probe), анализаторы сетевых протоколов (например, Observer Suite компании Network Instruments), программные агенты, устанавливаемые на клиенте или сервере (например, Пятый Уровень). Пороговые значения устанавливаются либо методом здравого смысла, либо методом базовых линий.
Второй способ – установить соответствие, когда, при каких значениях какой метрики сервис работает хорошо (пользователь может им пользоваться для достижения своих целей, выполнения своих обязанностей), а когда плохо (пользоваться сервисом невозможно). В этом случае контролируется не время реакции бизнес-приложений, а технические метрики, от которых оно зависит. Мониторинг существенно упрощается и удешевляется, т.к. вместо плохо масштабируемых GUI-роботов или дорогих анализаторов можно использовать обычную, даже бесплатную, систему мониторинга.
Как же на практике определить, какие значения метрик соответствуют комфортной работе пользователей?
Алгоритм определения поровых значений, соответствующих комфортной работе пользователей ИТ-сервиса
Для потоковых приложений (голос, видео) задача приведения в соответствие пороговых значений технических метрик и пользовательского восприятия (или удобства пользования ИТ-сервисом) давно решена. Все, кто работают с оборудованием Cisco (и не только), знают, что данное оборудование позволяет контролировать субъективные метрики MOS (Mean Opinion Score) и ICPIF, которые не измеряются, а вычисляются (в зависимости от типа кодека) из технических метрик: jitter, delay, packet loss (которые собственно и измеряются). Для этого используется модель R-Value. Выдержки из соответствующих стандартов и приказа Мининформсвязи №113 есть в поддерживающих их Экспертизах и другую информацию по теме можно найти на сайте www.you-expert.ru.
Но для транзакционных приложений, работающих поверх TCP, а не UDP, подобных стандартов нет. Это значит, что нам придётся самим устанавливать соответствия между значениями технических метрик и восприятием пользователей. Для этого предлагается использовать методику APDEX (см. ниже) и решения ProLAN.

Рисунок 4. Работа бизнес-приложения АЛЬФА.
Предположим, что есть два офиса, разделённых каналом связи. При этом сервер приложений АЛЬФА находится в одном офисе, а сами пользователи приложения АЛЬФА в другом, см. Рисунок 4. Название АЛЬФА, конечно, условное. Допустим также, что у нас есть система мониторинга ProLAN SLA-ON (или какая-то другая), позволяющая измерять технические метрики здоровья маршрутизаторов, сервера приложений, канала связи, в частности, jitter, delay, packet loss.
И вот мы озаботились тем, какие значения jitter, delay, packet loss нам нужно прописать в SLA c оператором связи, чтобы пользователи бизнес-приложения АЛЬФА работали комфортно. Они будут также введены в нашу систему мониторинга как пороговые значения, чтобы системный администратор или служба поддержки при их превышении могли сразу узнавать, что произошёл сбой (т.е. пользователи лишены возможности нормально выполнять свои обязанности, используя предоставляемый сервис – бизнес-приложение АЛЬФА).

Рисунок 5. Сбор метрик здоровья ИТ-инфраструктуры, информации о работе пользователей и случаях неудовлетворительной работе приложения АЛЬФА
1. Для решения этой задачи установим на компьютеры наиболее адекватных пользователей приложения АЛЬФА Красную Кнопку (USB-устройство, программу SelfTrace, программу EPM-Agent Plus). Программа SelfTrace будет автоматически измерять, когда пользователи работают с приложением АЛЬФА (именно работают, т.е. нажимают клавиши на клавиатуре и двигают мышью, а не просто приложение открыто, а сотрудник пьёт кофе в другом отделе), и передавать результаты в консолидированную базу данных, см. Рисунок 5.
2. Система мониторинга настраивается на сбор метрик jitter, delay, packet loss, которые также автоматически записываются в консолидированную базу данных, и привязываются к общей временной шкале.
3. Пользователи приложения АЛЬФА инструктируются, что в тот момент, когда, с их точки зрения, они не могут комфортно пользоваться приложением АЛЬФА для выполнения своих обязанностей, они должны нажать «красную кнопку». Результаты нажатия кнопок тоже автоматически передаются в консолидированную базу данных и также привязываются к общей временной шкале. Таким образом, в консолидированной базе данных значения метрик jitter, delay, packet loss, периоды времени использования приложения АЛЬФА и сообщения о неудовлетворительной работы приложения АЛЬФА оказываются привязаны к одной общей временной шкале.
4. Переходим собственно к вычислению пороговых значений. Запускаем специальное приложение (скрипт), которое обращается к консолидированной базе данных и вычисляет средние значения метрик jitter, delay, packet loss:
- в те моменты времени, когда пользователи АЛЬФА жаловались на ИТ-сервис (нажимали кнопку);
- в те моменты времени, когда, по мнению пользователей, c АЛЬФОЙ было всё нормально.
Примечание. Партнёры, использующие коммерческие продукты ProLAN, могут получить этот скрипт бесплатно.
В результате для каждой метрики jitter, delay, packet loss у нас будет 2 пороговых значения:
- jitter_satisfied и jitter_frustrated
- delay_satisfied и delay_frustrated
- packet loss_satisfied и packet loss_frustrated
В соответствии с методикой APDEX метрики с суффиксом frustrated – это четырёхкратное пороговое значение соответствующей метрики. То есть если значение jitter_frustrated cоставило 200 микросекунд, то пороговое значение метрики jitter, соответствующее комфортной работе пользователей АЛЬФА, составляет 50 микросекунд.

Рисунок 6. 2, 7, 11, 12 – значения jitter не учитываются (пользователь в это время не работал в приложении АЛЬФА). 5, 14 – учитываются для вычисления jitter_frustrated. 1, 3, 4, 6, 8, 9, 10, 13, 15 – учитываются для вычисления jitter_satisfied.
Задача решена. Мы получили пороговые значения, превышение которых означает сбой с точки зрения пользователя, а значит и провайдера ИТ-сервиса (нарушение комфортного режима работы для пользователей ИТ-сервиса).
Попутно решается ещё одна важная задача: определяем, какие метрики значимы с точки зрения производительности данного сервиса. Например, если выяснится, что значения jitter_satisfied и jitter_frustrated близки, то метрика jitter для комфорта работы с приложением АЛЬФА (для его производительности) не является значимой. К метрикам, характеризующим работу IP- канала, это не очень применимо. А вот для метрик здоровья маршрутизаторов, серверов приложений – это важно.
Методика APDEX
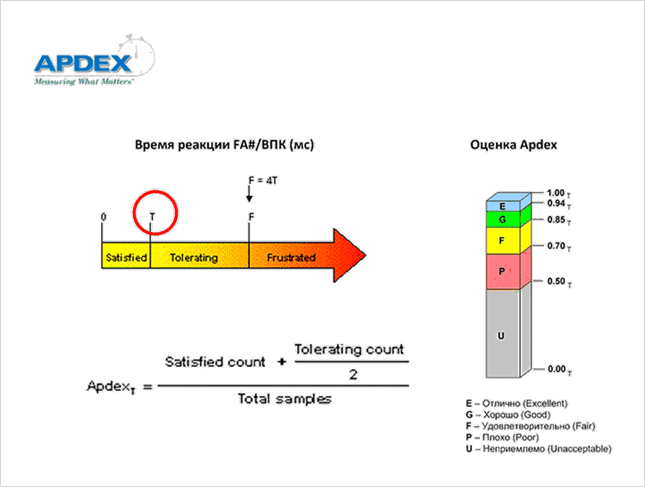
Рисунок 7. Методика APDEX.
В заключение несколько слов о методике APDEX.
APDEX (Application Performance Index) – это стандарт, количественно определяющий удовлетворённость пользователей производительностью приложения. Методика APDEX заключается в следующем. Все результаты измерений (например, результаты измерений времени реакции бизнес-приложения) разделяются на три группы.
В первую группу попадают измерения, значения которых меньше порогового значения T, соответствующего комфортной работе пользователей. (Именно его нам и нужно определить.) Число таких измерений – это значение переменной Satisfied count: пользователи удовлетворены.
Во вторую группу попадают измерения, значения которых больше T, но меньше 4*T. Число таких измерений – это значение переменной Tolerating count: пользователи не очень довольны, но готовы терпеть.
Все остальные измерения заносятся в третью группу – Frustrated: пользователи жалуются. Общее число измерений – это значение переменной Total samples. Значение APDEX вычисляется по формуле, приведённой на Рисунке 7.
Post scriptum
Удивительный факт. Объём продаж систем мониторинга в огромной России почти в 30 раз меньше, чем в маленькой Германии. За цифру 30 не поручусь, но порядок точно такой. Мне долго было не понятно, с чем это связано, пока недавно у меня не состоялся разговор с ИТ-директором очень крупного ритейлера. Я спросил, чем они мониторят ИТ-инфраструктуру. Он назвал один из продуктов Open Source. Я спрашиваю: «Ну и как, устраивает?» «Да, – говорит. – Инженеры довольны. Пользователи только не довольны, периодически жалуются, что у них всё тормозит, и письма иногда не приходят. А по нашим данным всё работает нормально. Не знаешь, что это может быть?»
ссылка на оригинал статьи http://habrahabr.ru/company/prolan/blog/182504/
Добавить комментарий