Я бы хотел рассказать о проблемах, с которыми я сталкивался в процессе освоения Selenuim WebDriver, c их решением и тем, как эти решения, в принципе, можно использовать. Все это представлено в виде прототипа фрэймворка, ссылка на который будет в конце статьи.
В этом посте я хочу поделиться своими идеями реализации шаблона Page Object, о том как можно обрабатывать ошибки, возникающие в процессе выполнения тестов, рассказать немного о логгинге. А так же поделиться сведениями о некоторых инструментах, которые реализованы с использованием Selenuim WebDriver, и своими наработками.
План моей статьи следующий:
1. Капитан очевидность, вместо вступления.
2. Немного о себе, надо представиться…
3. Почему Selenium?
4. О Page Object…
5. Не баг, а фича!
6. И снова про логгинг и отчетность.
7. А разве нет аналогов?
8. Обещанные ссылки.
9. В заключение.
1. Капитан очевидность, вместо вступления.

Не думаю, что есть смысл объяснять, что такое тестирование программного обеспечения, какие стратегии и модели существуют, какова его роль в процессе разработки софта и обеспечении качества, и какому риску подвергаются проекты и пользователи, если этот процесс отсутствует. К тому же, сейчас программирование является не искусством, а ремеслом для многих миллионов специалистов. Проекты реализуются в сжатые сроки и с ограниченными бюджетами, и часто могут из себя представлять монстров с просто необъятной функциональностью. Причем продукты могут интенсивно меняться от версии к версии, скажем так улучшаться. И каждое такое «улучшение» может оказаться фатальным.
В таких условиях автоматизированное тестирование играет одну из ключевых ролей. Какие модели, стратегии и методы существуют лучше поискать в других источниках. Моя же статья не об этом. Она посвящена инструментам автоматизации тестирования клиентской части вэб-приложений.
2. Немного о себе, надо представиться…
Я занимаюсь регрессионным автоматизированным тестированием уже четыре года. Мы тестируем десктопный клиент продукта и классы, которые описывают его бизнес-логику. Об инструменте, который используется на нашем проекте можно почитать тут. За это время было автоматизировано множество UI-тестов, unit – тестов, много чего было… Именно тут я наблюдал процесс эволюции автоматизации тестирования, и сам в нем принимал участие.

Сначала это были скрипты, записанные прямо на коленке с использованием автоматических средств записи, в которых логика сценария была неотделима от способов взаимодействия с тестируемыми объектами. По мере увеличения набора тестов всем стало очевидно, что нужно разработать некое подобие фрэймворка и использовать его для автоматизированных сценариев. Любой чих в тестируемом приложении имел весьма печальные последствия для всего прогона тестов.
Далее появилась необходимость использовать программные интерфейсы взаимодействия с продуктом и базами данных, ибо того, что показывали формы диалогов, было недостаточно…
Впрочем, что-то я увлекся. Но именно тут я и понял, насколько важно продумывать с самого начала стратегию и тактику взаимодействия с продуктом разработчиков для его эффективной автоматизированной проверки.
Тенденцию перехода приложений от своих десктопных клиентов к вэб-клиентам не может заметить либо слепоглухонемой, либо человек, родившийся и живущий где-нибудь в Антарктиде. Да и разработка для вэба сейчас мейнстрим, это ни для кого не секрет.
Я решил не оставаться в стороне и попробовать в свободное время освоить что-нибудь, что используют для автоматизации функционального тестирования frontend – части и для проверки ее совместимости с различными клиентскими платформами. Да и к тому же, есть некоторая вероятность, что вэб-клиенту на нашем проекте быть…
Я выбрал Selenium Webdriver.
3. Почему Selenium?

Почему же Selenuim?
Когда-то давно это был маленький инструмент, который использовали лишь отчаянные энтузиасты из мира вэб-разработки. Сейчас же это грозное оружие, которое взяли на вооружение для борьбы с дефектами не только многие тысячи автоматизаторов по всему миру, но даже frontend – разработчики.

О линейке продуктов проекта Selenium можно прочитать тут или вот здесь.
Но должен сказать, что это не средство непосредственно автоматизированного тестирования. Например, Selenium Webdriver предоставляет множество программных средств и интерфейсов для эмуляции пользовательского взаимодействия с браузером и загруженным в его окне контентом. Эти средства покрывают почти 100% возможных вариантов такого взаимодействия. Все это может найти более широкое применение. Но, например, он не может, по умолчанию, формировать отчет о прохождении того или иного теста.
Далее, есть некоторые другие проблемы. Ниже часть из них:
Интерфейсы WebDriver и WebElement предоставляют очень ограниченную функциональность. В основном она направлена на поиск элементов активной страницы и выполнение самых простых действий над элементами (ввод значений, клик и т.п.). Многие другие полезные функции предоставляются такими интерфейсами, как HasInputDevices, Locatable, Options, Alert и т.д. И использование только WebDriver и WebElement сильно ограничит возможности автоматизированных тестов.
Под каждый браузер существует свой драйвер. Сейчас это:
ChromeDriver;
FirefoxDrive;
HtmlUnitDriver (для Unit – тестов на уровне html-документа);
InternetExplorerDrive;
OperaDriver;
RemoteWebDriver (мой любимый, хорош для запусков тестов на удаленных машинах);
SafariDriver;
IphoneDriver;
AndroidDriver;
PhantomJSDriver (какой-то экзотический браузер, у меня терпенья не хватило, чтобы его собрать на своей машине).
Я думаю, что команда Yandex’a тоже скоро выпустит свой драйвер.
Богатый выбор, на любой вкус и под любые нужды. Но если в тестовом проекте явно используется какой-то или какие-то из перечисленных, это создаст проблемы, когда нужно быстро переходить с браузера на браузер или использовать сразу несколько.
Поэтому хотелось бы иметь какой-то единственный способ или интерфейс для создания нужного экземпляра. Желательно, чтобы он принимал какую-то настройку, которую всегда можно изменить, в качестве параметра. Эта настройка должна включать в себя тип браузера, возможности, таймауты. Ну и возможность похардкодить пусть тоже будет.
Написание классов, которые бы были ответственны за интерактивную работу со страницами. PageFactory – замечательный инструмент. Однако, его использование становится неудобным из-за потери наглядности кода классов, описывающих очень большие страницы, а повторяющиеся элементы чреваты копипастой. Выход – выделять повторяющиеся элементы в отдельные блоки (классы) и использовать уже блоки. Но это не решает проблему до конца. Что если ваш сервис может работать, открывая страницы на отдельных вкладках или окнах браузера, на всех этих окнах есть повторяющиеся блоки? А часть из них лежит еще и на фрэймах! Я экспериментировал на этом и этом, и сразу же столкнулся с описанной проблемой. А ситуацию усугубляет еще и то, что экземпляр, реализующий WedDriver, видит только активную страницу (окно/вкладку) или фрэйм.
Хотелось бы иметь возможность разбивать страницу на такие блоки, которые работающий тест мог бы запоминать и работать с ними напрямую, без вызовов driver.switchTo().window(somehandle) или driver.switchTo().frame(frameIdentity).
Поэтому, я себе поставил задачу не просто освоить указанный выше инструмент, а сделать некий проект, а еще лучше — прототип фреймворка на основе Selenuim Webdriver. А в дополнение – попробовать найти аналоги и сделать так, чтобы это нечто могло легко с ними интегрироваться. Просто я считаю, что если задача стоит именно таким образом, то поданный материал усваивается намного легче.
В качестве языка была выбрана Java. Среда разработки – Eclipse.
Не буду рассказывать о том, как этот путь постепенно преодолевался. Лучше продолжу с описания проблем и их решений. Может, америк и не открою, но буду рад, если кто-то найдет для себя что-то полезное…
4. О Page Object…
Я думаю, мало найдется таких автоматизаторов, которые бы не знали о design – паттерне Page Object. Кстати, этот паттерн применим и для написания автотестов UI какого-нибудь десктопного приложения. Но сейчас речь пойдет о его реализации на Java для вэб-интерфейса.
О самом приеме можно почитать тут.
Сейчас я вам покажу на данный момент работающий код некоего не очень удачного теста.
Я думаю всем понятно, что такое хорошо, когда вы хотите написать скрипт, где нужно сделать один ввод куда-нибудь и 2-3 клика на чем-нибудь. Такой тест вы быстро исправите, если что-то корректно (!!!) изменилось.
Если тест должен проверить больше, чем описанные выше действия, то получится неудобная для чтения простыня кода. А теперь помножим все это на огромный тестовый проект. Вы уже представили себе, как плачет бедный тестировщик, что поддерживает его, после каждого изменения Google? И вот чтобы он так не плакал, нужны классы, через которые тест выполняет свои действия над страницей. А уж если чего и поменялось (еще раз, это изменение — фича, а не внесенный баг), но правки будут локальными, а не во всем проекте.
Существует множество реализаций Page Object, в том числе, я думаю, и на ваших проектах. Ниже я продемонстрирую свою реализацию и тот же самый тест:
public interface IPerformsClickOnALink
public interface IPerformsSearch
public class SearchBar
public class LinksAreFound
public class AnyPage
public class Google
тест
А если потрудиться и сделать что-то наподобие такой настройки, то тест может работать так.
Многие бывалые автоматизаторы, наверное, сейчас подумали: «Ну да, Page Factory использует… Автор зачем-то усложнил описание главной страницы google – можно же описать как один класс! Ну, разве что какая-то непонятная аннотация появилась… @PageMethod называется. Потомки классов Page и Entity… Мы похожее видели здесь. Автор, мы все это уже видели!».
Ну да. Это был простой пример. Я намерено усложнил описание главной страницы, чтобы показать, что можно описание одной и той же страницы разбить на два независимых класса. Об этой аннотации расскажу ниже…
А теперь пример сложнее…
На картинке продемонстрирована некоторая ситуация.
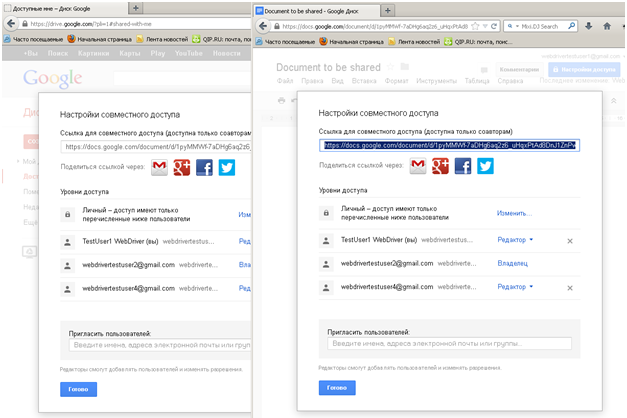
Что делает тест:
1 заходит в docs.google.com
2 открывает доступный Google документ
3 на главной странице сервиса вызывает диалог настройки общего доступа;
4 из открытого документа вызывается тот же самый диалог.
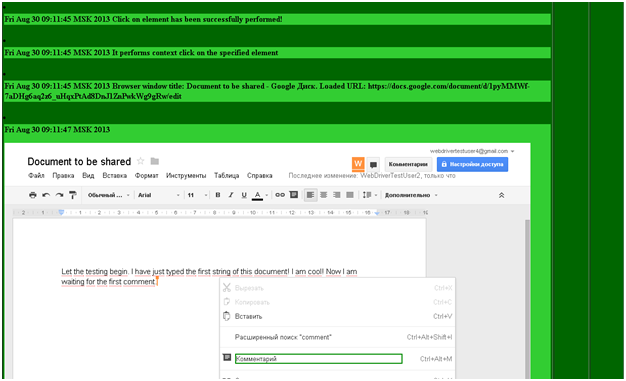
Для наглядности, вся последовательность действий показана в виде скриншотов. Активные элементы выделены:

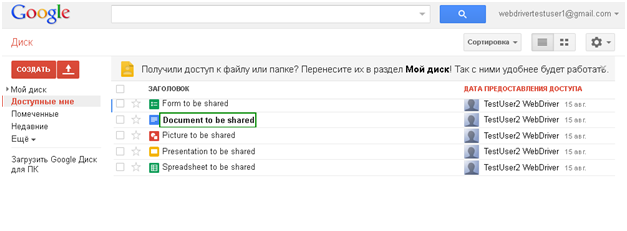
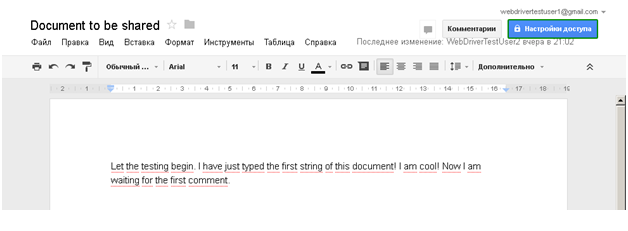

Нужно: как-нибудь обработать оба экземпляра этого диалога в разных окнах. И вот что получилось у меня. Это описанное предусловие.
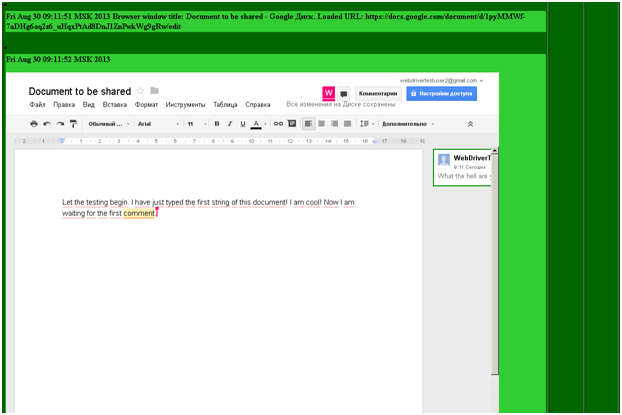
Теперь я сделаю клик по полю, в которое просят ввести имена, адреса электронной почты и т.д., в появившемся всплывающем элементе нажму «Отмена», после чего будет произведен клик по кнопке «Готово». Действия будут выполнены в обоих окнах. Для наглядности, ниже последовательность в виде картинок.
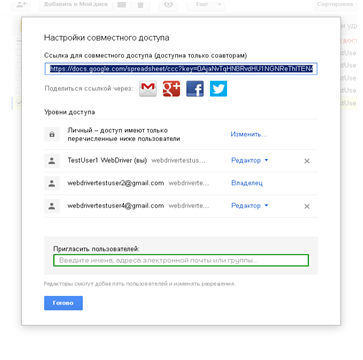
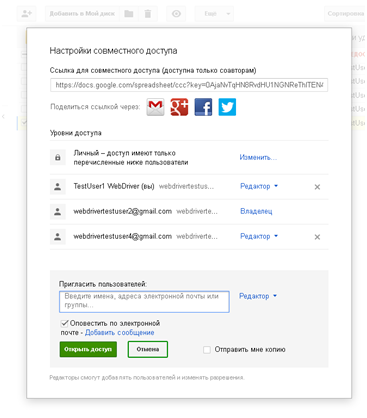
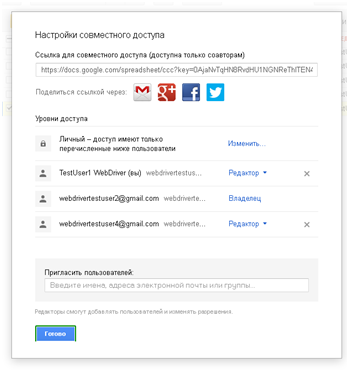
Вот так играючи мы справились с задачей. . Это код метода getCustomizingAccessDialog() для документа и главной страницы.
Т.е. есть некий всплывающий блок элементов, расположенных внутри фрэйма, которым мы воспользовались как объектом, который существует как бы самостоятельно и подхватывается когда надо… Мы знаем, что он есть на странице любого документа и на главной странице сервиса, от них и получаем.
На самом деле я долго пытался найти оптимальный способ организации и описания того или иного тестируемого объекта в разных источниках. Хотя, может плохо искал…
Очевидно, что нужно группировать элементы страниц в блоки для повторного использования. Эти блоки можно даже передать наружу под видом самостоятельных объектов и с ними непосредственно работать. Если этого не делать, то у класса разрастется число атрибутов и методов. Нужна декомпозиция. Иначе, вы получите вот такие объекты:

Если посмотреть на описанный выше пример, то к методам работы с основным контентом, добавляются методы работы с каждым типом всплывающего диалога – настройки доступа, модальные формы переименования, выбора опций, комментарии в документах.
Указанное выше решение можно реализовать безболезненно, когда тестируется то, что загружено в единственном окне (единственной вкладке) браузера.
Но в случае описанного достаточно сложного поведения придется каким-то образом переключать webdriver cо страницы на страницу, не забывая переключаться в нужный фрэйм.
И тут возникла идея! А что если научить каждый такой объект помнить путь к самому себе и автоматически переключать webdriver при вызове метода интерактивного взаимодействия со страницей.
Такое, мне показалось, возможно, если несколько отойти от понятия «страница». Т.е. под ней я буду подразумевать не загруженный контент, а окно браузера с загруженным в нем контентом. У этого окна есть строковый уникальный идентификатор, по которому можно легко опознать его среди прочих. Ок! Т.е перед вызовом метода будет происходить переключение в нужное окно.
Так. А что делать с фрэймами? Можно сделать еще и так, чтобы каждый блок элементов знал, дополнительно, в какой фрэйм следует переключиться.
Таким образом я выстраиваю путь.
Как видно из приведенного списка конструкторов класса, который я назвал Page (название очень условное, возможно, класс следует переименовать), можно составить описание загруженной страницы целиком, а можно по частям, в дополнение к этому указывая другой подобный ему объект в качестве родителя (parent) когда это необходимо. Таким образом можно выстроить связанный граф блоков элементов. Может получиться что-то похожее на иерархию.

Ок! Хорошо, пути указали, иерархию построили. Что дальше? Как реализовать автоматическое переключение при вызове, например клика или ввода строки в поле? Само переключение реализуется таким образом.
Но! Многие могут задать вопрос: «Нам его нужно перевызывать в каждом методе?» Нет. Ниже постараюсь объяснить, как это работает.
В своем решении я предлагаю использовать не сами объекты, созданные конструктором, а их заместителей (proxy, иными словами). Для этого была использована библиотека cglib. А если быть более точным то MethodInterceptor для перехвата вызываемых методов, Enhancer для создания самих proxy — объектов и Callback. Использование перечисленных выше типов избавляет от необходимости, в будущем, создавать набор интерфейсов для каждого наследника Page (см. java.lang.reflect.Proxy) и делает реализацию более гибкой. Однако – есть ограничение – наследник класса Page не должен быть final!!!
Т.е. когда мы пытаемся вызвать тот или иной метод какого-либо Page – объекта (наследника класса Page) происходит перехват этого метода и «переключение» объекта на самого себя. А уже после этого выполнение самого метода.
Прекрасно! Но такого рода перехват происходит при вызове каждого метода? Вопрос, замечу, справедливый. Нельзя забывать, что Page — объект – это еще и объект языка java. У такого объекта могут быть public или protected методы, которые никак не связаны с браузерной интерактивностью. Как быть? Очевидно, нужно придумать способ разделения методов на методы, ответственные за интерактивное взаимодействие и все остальные.

Аннотация @PageMethod как раз и служит таким «разделителем». Т.е, если метод отмечен таким маркером, то будет выполнено предварительное переключение на страницу или ее фрагмент…
В общем, решение выглядит вот так.
Далее немного о возможностях создания Page – объектов.
Любой блок элементов или представление страницы может быть создано тремя основными способами:
— от наследника класса Entity – это что-то вроде модели сервиса, открытого на главной или какой-либо другой странице, в целом. В описанных примерах это Google (поисковик), GoogleDocsApplication (Google Drive). Кстати, пример с Google демонстрирует, что с «приложением», в принципе, мы тоже можем работать как с Page – объектом. Я как бы включил в него элементы с панелью и результатами поиска.
«Сущность» способна порождать те объекты, которые находятся в первом (главном) открытом окне/вкладке сервиса (пример с Google Диск, «docs.getContent();» — обвертка вокруг одного из таких методов, пример с Google – “searchBar = get(SearchBar.class);” – вызов одного из этих методов) либо те, которые существуют во вновь появляющихся окнах/вкладках (AnyGoogleDocument anyDocument = docs.get(AnyGoogleDocument.class, 1);).
На картинке весь список методов класса Entity, которые уже готовы к использованию или могут быть перекрыты в наследниках:

— от другого наследника класса Page. Т.е… У нас есть список доступных документов Google Drive, над которым мы выполняем различные действия – открываем, ставим метки, работаем с выплывающем меню и кнопками панели действий. Все это мы описываем в отдельном классе (в примерах выше — GoogleDocsMainPageContent).
Появляющиеся в результате этих действий элементы (диалог настройки доступа, различные модальные формы и т.п.), являются частями этой страницы. Но они функционально могут быть рассмотрены как бы в отрыве от нее.
Такие элементы можно описать в отдельных наследных класса Page.
Таким же образом, для удобства, могут быть описаны и более крупные, но более статичные блоки (например редактор таблицы или документа).
Во всех описанных ситуациях объекты можно создавать с указанием родителя.
На картинке весь список методов класса Page, которые уже готовы к использованию или могут быть перекрыты в наследниках:
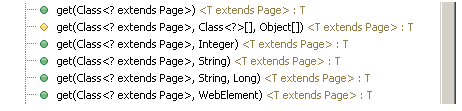
Все описанные выше методы создания объектов для выполнения тестирования являются обвертками вокруг методов класса на скриншоте:

— используя TestObjectFactory. Способ пока хорош тогда, когда имеются такие компоненты, которые могут работать сами по себе, без использования сервиса. Например, документ, таблица, презентация и т.п. могут быть открыты без помощи сервиса при условии, что есть право доступа и ссылка на документ. Если нужно проверить именно такую ситуацию, то можно поступить так. Далее повторяется второй use case. Но этот вариант у меня пока самый непроработанный.
Я мог бы рассказать о глубинных механизмах и приколах работы этой системы. Но глава получится очень большая. Это может стать темой для отдельной заметки.
5. Не баг, а фича!

Любое исключение, которое возникает во время выполнения автоматизированного теста, сигнализирует о проблемах.
Это может быть сигналом о внесенном разработчиком баге. Тест сам по себе может быть плохо написан. И фиксить следует уже этого крикуна. Не исключение и сами используемые инструменты. Список дефектов Selenuim можно посмотреть здесь.
Но речь я поведу не об этом.
Как вам такая ситуация? Например, на этапе ручного тестирования был выявлен дефект. Он занесен в багтрэкер, это может быть “Minor”. Этот баг не смертелен для пользователя, он его сможет легко обойти. На данный момент у разработчиков есть более важные задачи, и фикс этого дефекта могут оставить до лучших времен. И уже сейчас нужен регрессионный тест, путь которого пролегает через описанный дефект. Тест написали, и… О боже! Он падает с каким-то страшным исключением, которое вызвал наш баг.
Ситуация, скажу вам, не из приятных. Лучший выход – сделать какой-нибудь костыль, который бы позволял и ошибку ловить, и тесту проходить до конца. Иначе может случиться страшное – тест дойдет только до этой некритичной ошибки, упадет и остальное не проверит. А именно туда залез какой-нибудь горе – разработчик и устроил там хаос. Но написание «костылей» может усложнить сам тестовый скрипт или классы, которые описывают то, что тестируется. Дефект уже исправили, а «костыль» могут забыть. Со временем весь проект может стать похожим на это.

Бывают ситуации еще хуже…
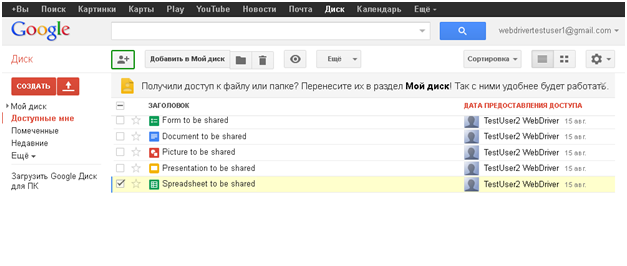
Яркий пример – возникновение StaleElementReferenceException. Можно почитать еще здесь. Это пример того, когда при нормальной работе тестируемого приложения возникают ситуации, на обработку которых используемый инструмент просто не был рассчитан!
Например, я с этим столкнулся, когда пытался написать «тесты» для списка документов Google Drive и табличного документа. На картинке показано, после какого действия чаще всего возникало такое исключение (клик по выделенному зеленым элементу).
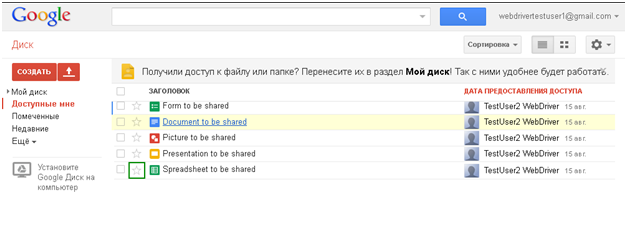
После смены значения «звездочки» дальнейшее прохождение «теста» было похоже на поход по минному полю. Ошибка возникала при попытке вернуть «звездочку» в исходное состояние, или поработать с чекбоксом, расположенным левее, а иногда и при попытке открыть документ.
Способы борьбы с этой ошибкой предлагают разные – от повторного выполнения одних и тех же действий (поиск элемента и выполнения действий) до увеличения виртуальной памяти машины. Ок! Допустим второе я сделать не могу. Тогда мне остается первое.
try
{
//some actions
}
catch (StaleElementReferenceException e)
{
//same actions again
}
Да, это работает. Но легко ли поддерживать класс, у которого каждый метод описан таким образом? А если это наблюдается в любой тестируемой фиче?
Решение созрело еще до того, как я попробовал «протестировать» Google Drive.
Я придумал интерфейс ITestObjectExceptionHandler. А это реализующий его абстрактный класс. Конструкторы и атрибут throwableList добавлены для упрощения процесса возможной обработки исключений. Назначение объекта класса, который будет его наследовать – попытаться обработать исключительную ситуацию и вернуть-таки какое-нибудь значение, или выбросить новое исключение.
Далее.
Вернемся к ранее описанным классам Page и Entity. У них есть класс – предок с этими атрибутами. Предок перехватчиков для Page и Entity имеет такую реализацию. И еще раз напомню, что так работает перехватчик для класса Page и его наследников, нужное выделено /**/. Очень похожа реализация для класса Entity.
Т.е., мы можем выполнить метод. Но если есть вероятность появления исключения, которое следует обработать особым образом, всю логику такой обработки можно вынести в отдельный класс. И для того, чтобы этот алгоритм сработал, нужно выполнить это.
Для Google Drive я создал такой класс, который описывает, что следует делать, когда возникает StaleElementReferenceException. А конструктор абстрактного класса, что описывает работу со списком Google Drive, я решил сделать таким.
Результат: StaleElementReferenceException вообще перестало себя проявлять при работе с таблицей. Со списком документов на главной странице сервиса тоже (Ура!). По всей видимости, для Google этого было достаточно.
Аналогично можно поступать для ситуаций, когда есть какой-то застарелый баг, который мешает прохождению тестов.
Например. Есть ситуация:
1. Мы по очереди создаем документы на Google Drive
2. Закрываем всплывающие модальные формы
3. Переименовываем
4. На некоторых ставим «звездочку»
5. Закрываем
Чтобы всем было понятно, вся последовательность продемонстрирована в виде скриншотов, на которых выделены активные элементы:
Создание
Работа с модальной формой
Переименование
Метка в виде звездочки. Табличный документ
Дело в том, что при выполнении описанных действий без каких-либо ожиданий, когда документ будет синхронизирован с сервером, возникает алерт. Если его не обработать, тест упадет. Причина: UnhandledAlertException. Я-то с вами знаю, что это неправильный тест. Но я хочу выдать ситуацию за некритичный, но противный с точки зрения автоматизации баг приложения. Его исправят позже, но тест, идущий до конца, уже должен быть сейчас.
По плану, после этих действий:
1. Проверка переименования каждого созданного документа (каждый разного типа) на главной страницы сервиса;
2. Проверка возможности удалить все эти документы.
Если эти действия не будут выполнены, то есть риск пропустить очень серьезные баги, и пользователи будут в ужасе.
Я решил задачу так:
1. Сам обработчик.
2. Его использование (в тесте).
Результат: тест проходит до конца. Его статус: FAILED TESTS BUT WITHIN SUCCESS PERCENTAGE. И вот как он сигнализирует об имеющейся проблеме:

Внимание (!!!). Такие обработчики следует реализовывать максимально просто. Желательно, чтобы каждый класс таких обработчиков имел уникальный набор исключений, на который следует реагировать.
6. И снова про логгинг и отчетность.


Ненадолго включу кэпа. Наверное, всем понятно, что кроме непосредственно прохождения тестов, должен быть еще какой-то выхлоп, благодаря которому можно судить о текущем состоянии продукта. Ну, или нужна какая-то детализация прохождения тестов… Эти задачи как раз и решают логгинг и отчетность.
Поскольку для экспериментов я использовал java, моя голова сильно болела при выборе нужного фрэймворка для логгинга. А выбирать было из чего! Автор этой статьи очень хорошо описал ситуацию с логированием в java. Да и на первых порах я сам еще не знал того, что хотел получить. К тому же нужно, чтобы по этому логу можно было построить отчет.
В итоге:
— мне нужен простой логгер, который бы мог регистрировать сообщения, их уровень, выводить данные на консоль – как минимум;
— очень хорошо, чтобы к нему можно было «цеплять» объекты исключений, если они возникают;
— и совсем хорошо – возможность прикрепить к записи лога ссылку на какой-нибудь файл, который получился в процессе прохождения теста;
— Писать видео со спецэффектами.
Думаю, с первыми двумя пунктами все понятно. Третий. Файлом может быть все что угодно, xml-файл, набранный текст или даже скриншот, снятый с браузерного окна. Это может быть удобным при, например, обработке записей лога.
Что касается отчетов:
— мне нужен отчет, который бы формировался как при прогоне одного теста, так и после запуска всей съюты;
— В этом отчете я бы хотел видеть описание выполненных шагов по выбранному тесту;
— Желательно, чтобы такая детализация могла отображать скриншоты или какую-либо другую визуальную информацию.
Не забуду упомянуть, что в качестве фрэймворка для проведения самих тестов я выбрал TestNG. Почему? Сначала, потому что в нем есть возможность формирования отчетов о прохождении тестов. Но при более детальном изучении я понял, что у него много других достоинств, таких как интегрируемость с maven и ant, возможность быть использованным такими continuous integration системами, как jenkins и hudson, многопоточная работа… Очень хорошо этот замечательный фрэймворк описан в этой статье. Кому интересно, можно посмотреть документацию.
Но, что-то я отвлекаюсь…
В качестве логгера я решил использовать java.util.logging.Logger. Почему?
— он есть в любой java’е начиная с 1.4, лишние зависимости на проекте ни к чему;
— его легко интегрировать с логами браузера (Mozilla Firefox, для других баузеров извлечение логов пока не реализовано);
— в случае использования других библиотек логирования (log4j, slf4j или logback, например), всегда есть возможность направлять сообщения в их логгеры.
Но:
— хотелось бы избавиться от явной инициализации логгера;
— есть усложненные варианты использования – построение иерархии сообщений. Большое количество уровней, которые, в принципе, должны соответствовать отладочной информации – FINE, FINER, FINEST… Нужно все лишнее как-то отсечь.
— выбранный логгер, а так же перечисленные выше, не умеют прикреплять файлы к своим сообщениям. Речь идет не о FileHandler’ах или о чем-то похожем.
Теперь решение.
В своем проекте я создал класс, который назвал коротко и ясно – Log. Его основные методы:
— debug(String) – генерирует сообщения с уровнем FINE, предлагаю использовать в целях отладки
— error(String) – генерирует сообщения с уровнем SEVERE, сигналы о серьезных ошибках;
— message(String) – генерирует сообщения с уровнем INFO, сигналы о нормальном состоянии;
— warning(String) – генерирует сообщения с уровнем Warning, сигналы о возможных проблемах;
— log(Level, String) — для тех, кто все-таки хочет сгенерировать сообщение с любым из этих уровней.
Те же методы с дополнительным параметром в виде объекта пойманного исключения:
— debug(String, Throwable);
— error(String, Throwable);
— log(Level, String, Throwable);
— message(String, Throwable);
— warning(String, Throwable).
Далее (внимание!), методы с возможностью связи файла и записи лога:
— debug(String, File);
— error(String, File);
— log(Level, String, File);
— message(String, File);
— warning(String, File).
На самом деле, все это простая обвертка вокруг java.utils.logging.Log и java.utils.logging.LogRecord. Все это статические public методы, которые могут быть доступны в любом месте проекта.
Пример использования. Можно использовать вместо комментариев. Однако, этим врятли кого-то удивишь.
Итак, каким образом я «цепляю» файл к логу? Дело в том, что этот логгер создает не объекты LogRecord, а его наследника, который я назвал LogRecWithAttach. Все просто! Кто найдет 10 отличий от «предка», тому 5 баллов и прибавку к карме.
Ок! Но у кого-то уже, возможно, появился вопрос: «Автор, а зачем тебе такое излишество?» Попробую ответить…
Ну, во первых, одной из важных функций, которую мне хотелось реализовать – снятие скриншотов со страницы. Я считаю, что скриншоты могли бы стать хорошим дополнением к логу и отчетам. И для удобства, как мне показалось, было бы лучше, если запись лога хранила в себе ссылку на фото страницы.
Функции снятия скриншотов у меня выполняет класс, названный Photographer. Список его методов можно посмотреть здесь:

Его функции следующие:
1. Снятие скриншота с активной страницы, сохранение его в файл;
2. Создание записи лога с нужным уровнем важности, добавление к ней ссылки на сохраненный скриншот;
3. Наверное, вы заметили, что в качестве параметров у некоторых методов указан WebElement. Эти методы выделяют элемент на странице, делают ее фото и возвращают элемент в исходное состояние. Примеры таких скриншотов были показаны ранее. Причем, цвет подсветки зависит от «правильности» состояния выделенного фрагмента страницы. Так, на скриншоте сфотографировано некорректное (ну, типа) состояние:
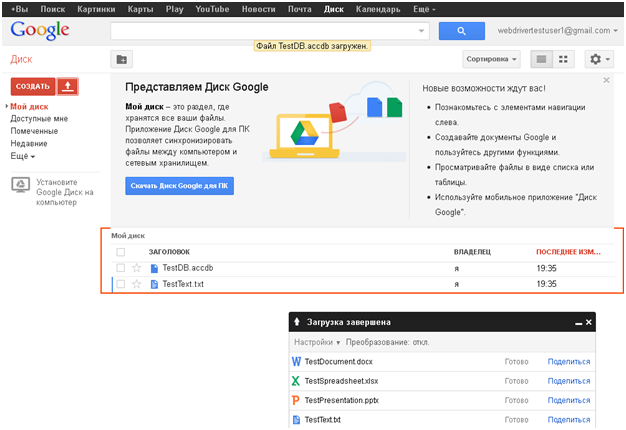
Список документов с некорректным содержимым (по условию «теста» текстовый документ и база данных MS Access не должны загружаться) выделен ярко оранжевым. Такая фотография сделана одним из вызовов метода Photographer.takeAPictureOfAWarning(WebDriver, WebElement, String).
Правда, есть одно НО (!!!) – элементы выделяются при помощи javaScript’а. Была идея делать проекции на скриншотах по координатам элементов. Это даже получилось. Однако, для элементов, которые сидят внутри фрэймов или находятся на страницах со скроллами, такие проекции (обведенные области) получались со смещением. От идеи пришлось отказаться. Но с другой стороны – теперь есть возможность записывать видео со спецэффектами!..
В общем – мой фотограф как бы дополняет лог.
Вторая, неплохая, возможность – прикреплять любой файл, в принципе. Например, разве плохо в отчете, который отображает детализацию, построенную на основе накопленных сообщений, найти ссылку на файл? Например тот, что загружали в Google Drive из примера выше. И по этой ссылке его открыть на просмотр.
Так, я плавно перехожу к построению оперативных отчетов о прохождении одного или нескольких тестов.
Начну с того, что для тех случаев, когда нужна конвертация лога с учетом описанных выше особенностей, я придумал интерфейс, который я назвал IlogConverter.
А вот пример использования. Например, мы дополнительно используем библиотеку log4j. Нам нужно, чтобы в этом логгере были данные о файлах. Можно создать класс, объект которого бы проверял, есть ли у приходящего сообщения «аттач». И если он есть – генерируется дополнительное сообщение log4j. А чтобы этот объект мог «слушать» лог, я предлагаю такой метод – Log. addConverter(ILogConverter). Этот механизм работает благодаря этому коду.
И вот что происходит, когда появляется новое сообщение:
converting.convert(rec);
Я сделал для своего фрэймворка что-то вроде «стандартной» реализации названного интерфейса, которая отвечает за формирование детализации отчета TestNG. Ее я назвал ConverterToTestNGReport. Что она делает? Она перехватывает сообщения от лога, по определенному html — шаблону (который я пока захардкодил в виде final-атрибута) формирует строку отчета:
Reporter.setEscapeHtml(false);
Reporter.log(htmlInjection);
Дополнительно – если у сообщения есть прикрепленный скриншот – то мы его превращаем в "<img src=\", если какой-либо другой файл — "<a href= \". Правда, есть только ссылки на файлы. Пока сами файлы по этим ссылкам почему-то не открываются. Но мне сейчас (!!!) этого достаточно.
Результат — приведенные ниже фрагменты отчетов. Хочу обратить внимание на то, что это не кастомизированные отчеты.


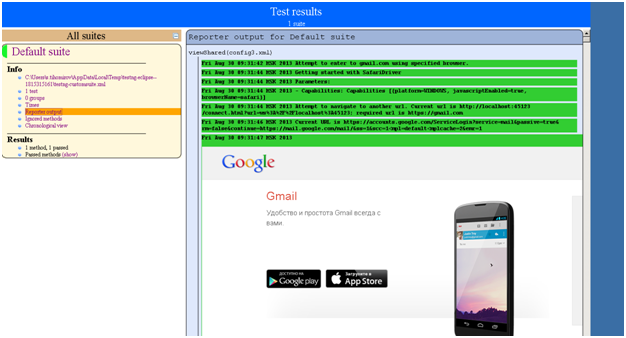
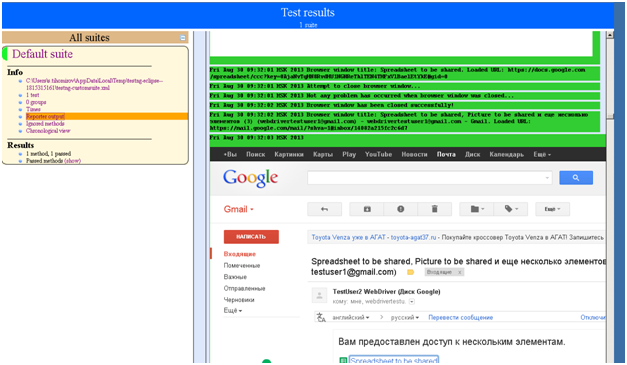
Конечно, может и грубовато, но на первое время сойдет. Я думаю, стоит разобраться, можно ли кастомизировать детализацию отчета TestNG. Если да, то можно сделать такой кастом и пользоваться им вместо захардкоденного шаблона.
И вроде пока все хорошо. Но этого не достаточно. Поясню…
Ок! У нас есть простой в использовании логгер. У нас есть даже инструмент, который позволяет строить отчет. Но нужно еще позаботиться о том, чтобы статус прошедшего теста был синхронизирован с максимальным уровнем сообщений лога.
Поясняю. Если ничего не предпринять, то тест будет иметь статус SUCCESS если он прошел до конца и не упал. Если же в процессе его выполнения возникло непойманное исключение, то тест будет иметь статус FAILURE. Если тест зависимый, и определяющий тест не проходил — SKIP. А теперь зададим себе вопрос: “А можно ли считать тест в полной мере прошедшим, если в ходе его выполнения произошло нечто, из-за чего в лог попали записи с уровнем WARNING или даже SEVERE?”. Т.е, прошедший тест имеет статус SUCCESS, однако, глядя на его детализацию, мы видим желтые и красные строчки. Я считаю это, как минимум, дезинформацией.
Мое решение ниже.
Я реализовал класс, который связывает поток (а TestNG поддерживает многопоточность) с самим тестом. Далее, реализовано хранение сообщений лога с привязкой к конкретному тесту (экземпляру класса, реализующего ITestResult). На этом моменте я останавливаться не буду. Продемонстрирую, как происходит привязка сообщения лога к тестам. Ее производит объект упомянутого ConverterToTestNGReport. И наконец, я реализовал интерфейс ITestListener в виде класса, который:
— перед началом выполнения тестов (тестовых методов) добавляет в лог экземпляр ConverterToTestNGReport в качестве слушателя.
— после выполнения каждого тестового метода синхронизирует статус его прохождения с тем, что зафиксировал лог:
1. если тест прошел до конца, но в логе есть сообщения с уровнем SEVERE – статус его прохождения меняется на FAILURE.
2. если тест прошел до конца и не было зафиксировано сообщений с уровнем SEVERE или WARNING – его статус остается неизменным – SUCCESS.
3. Если же были зафиксированы сообщения с уровнем WARNING, то я предлагаю сменить его статус на SUCCESS_PERCENTAGE_FAILURE. Либо позволить «пользователю» выбрать подходящий статус самому.
А теперь финал!
Для построения описанных выше отчетов нужно выполнить вот такое действие:
@Listeners({ReportBuildingTestListener.class})
public class NewTest {
В заключение к этой главе, я хотел бы сказать, что логирование уже в значительной степени автоматизировано. Т.е. графически регистрируется любое интерактивное действие – вводы значений (до ввода и после ввода), клики и submit’ы (до выполнения действия), появления новых вкладок/браузерных окон, результаты переходов по ссылкам. Для всего остального формируются некие «стандартные» текстовые сообщения.
Часть этих функций берут на себя классы, которые являются прослойкой между инструментами, входящими в состав Selenium, и классами более высокого уровня.
Это ExtendedEventFiringWebDriver – наследник EventFiringWebDriver, который фактически выполняет всю черную работу. Его «просушкой» занимается реализация интерфейса IExtendedWebDriverEventListener (расширенный WebDriverEventListener), входящая в состав WebDriverEncapsulation в качестве nested – класса. Часть функций логирования на себя берут WindowSwitcher и SingleWindow – менеджер браузерных окон/вкладок и представление самого окна/вкладки.
Само логирование можно настроить для проекта в целом. Однако о конфигурировании и названных классах я бы хотел рассказать в другой статье, которой возможно быть…
7. А разве нет аналогов?




Итак! Одной из поставленных задач было попытаться найти аналоги и попробовать с ними поработать. Это расширяет кругозор. Кроме того, многие полезные функции бывают уже реализованы. И тогда зачем писать велосипед, который делает все тоже самое? Лучше уже все равно не получится! Гораздо полезнее посмотреть, как реализованы нужные функции, и научиться их использовать.
А собственно, в чем аналогия?
Функциональность, которую я совсем отказался реализовывать – работа с объектами, классы которых в том или ином виде реализуют WebElement. Т.е. я решил совсем ничего не предпринимать в этом направлении, т.к. наткнулся на видео – доклад об этом замечательном фрэймворке. И скорее возник интерес попробовать его на практике. Это мне в полной мере удалось во время экспериментов с Google Drive. Причем наладить взаимодействие с yandex-qatools htmlelements удалось без каких-либо усилий. Например, вот так выглядят конструкторы абстрактного класса, от которого наследуются все Page — объекты на этом дэмо-проекте. А вот такой набор атрибутов у меня получился для класса, который описывает общие свойства всех Google — документов. Вы видите здесь WebElement? Везде типизированные атрибуты, описывающие поля страницы, а часть из них – те, которые включены в пакеты названной библиотеки. Часть элементов, которые были нужны, не оказалось. Но с помощью этого инструмента их легко удалось описать.
Причем все это удалось без ущерба для функциональности, на которую закладывался я. Даже наоборот. Декомпозиция описаний страниц, о которой я рассказывал ранее, стала еще более наглядной. Вот это ситуация win-win!
Другой интересный прием работы с полями на странице представлен на примере наследника класса PageObject, который реализован во фрэмворке thucydides (о нем будет позже).
Итак, аргументов в пользу того, чтобы не делать бесполезную работу в этом направлении, более чем достаточно.
В процессе своих «исследований» мне попался другой инструмент – уже упомянутый thucydides. Читая статьи о нем, разглядывая репозиторий и пытаясь что-то написать, я пришел к выводу, что лучше всего использовать его возможности и как-нибудь с ним подружиться. А причин, поверьте, для этого много:
— пошаговая организация автоматизированных тестов;
— возможности описывать сценарии с использованием JBehave framework, а не просто в виде работающего кода;
— набор удобных методов и инструментов для работы с страницами;
— интеграция с JIRA и другими issue tracker’ами.
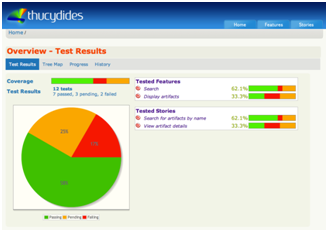
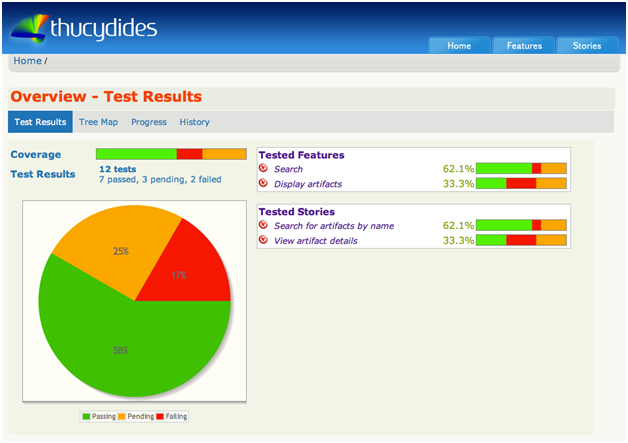
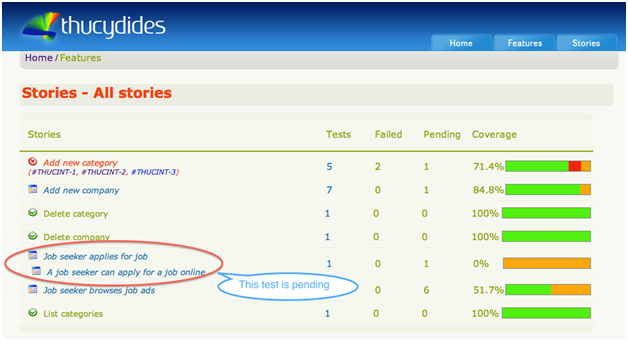
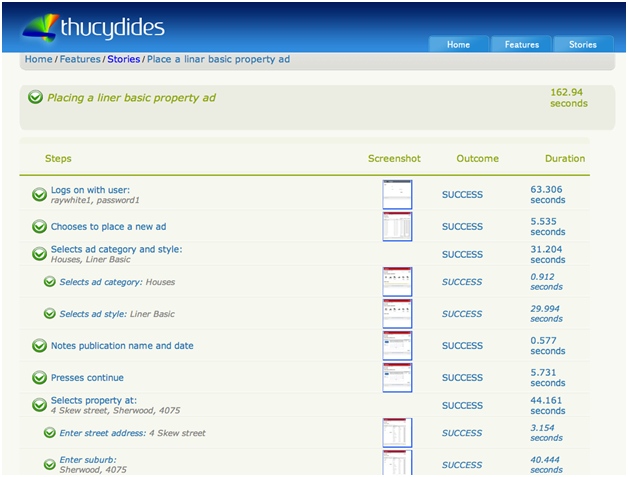
— отчеты. О покрытии. История. И т.д.
1. 
2. 
3. 
Скажу по-правде, у меня была идея сделать второй дэмо прект в связке с thucydides. Не хватило то ли времени, то ли энтузиазма. Но, возможно, я к нему еще вернусь. Хочу просто поделиться идеей и узнать, насколько она осуществима. И вот теперь расскажу о том, что удалось реализовать мне:
— реализована «кроссдрайверность».
— возможность работы с несколькими открытыми браузерами в одном тесте.
— реализована конфигурируемость.
Можно сделать одну настройку на весь проект с указанием используемого браузера, параметров Capabilities, таймаутов (таймауты ожиданий для Webdriver, свои – связанные со временем ожидания новых окон/вкладок, переключениями между ними).
Можно сделать набор дополнительных/индивидуальных настроек, которые могут частично перекрывать общую.
Т.е. – в общей указаны браузер, его возможности/настройки и набор таймаутов. В дополнительной – только браузер и возможности. В случае создания нового экземпляра Webdriver’а по этой настройке – откроется указанный браузер, настроенный нужным образом, но его таймауты возьмутся из общей настройки.
Это может быть использовано, например, для параметризации тестов. Пример параметризации для TestNG. Мой пример.
— механизмы управления окнами/вкладками браузера (в том числе и загрузка нужных страниц) без привязки к контенту.
— набор инструментов, которые скрывают экземпляр webdriver на самых верхних уровнях. Вся работа происходит через них. В чем выигрыш – все черная работа, связанная с использованием таких интерфейсов, как HasInputDevices, Options, JavascriptExecutor и т.д. уже выполнена. Примеры.
Если есть смысл, о перечисленном выше я расскажу в другой статье.
— описанный в 4 и 5 способ организации объектов, реализующих интерактивное взаимодействие.
— описанный в 6 логгинг и способ построения отчетности на примере отчета TestNG.
Как видно из перечисленного, основной упор я попытался сделать на работу с WebDriver’ом и связанными с ним компонентами.
Чего нет у меня и есть в thucydides (впечатление при еще отдаленном знакостве) в этом плане:
— возможность трэккинга и построения карты открываемых страниц. Классы Pages и PageUrls. У меня же возможен только прямой переход по ссылке, возврат вперед и назад;
— инструменты для работы с элементами, дополнительный набор ожиданий. PageObject.
А теперь идея в общем:
1. Хочу использовать свой механизм для открытия браузера.
2. Объект наследника описанного ранее класса Entity – wrapper для объекта Pages. Таким образом я попытаюсь объединить функциональности обоих классов.
3. Можно как-нибудь объединить функциональности наследников классов Page (глава 4) и PageObject (thucydides).
4. Вернемся к отчету с номером 3. Как видите, шаги могут быть очень большими (самый первый прошел за минуту, есть идущие по 30 и более секунд). Наверняка это не атомарные шаги. Представленные в этом отчете скриншоты – состояния в конце выполнения шага. Что если шаг завершился неудачно? Я бы, например, хотел видеть иллюстрации того, что привело продукт в некорректное состояние.
Так вот, думаю, если провернуть фокус, описанный в главе 6, при условии что существует возможность для создания детализации шага в отчете, которую можно вызвать извне в процессе его выполнения – это было бы здорово!
5. Все остальное делает thucydides.
Примерно так!
На данный момент, я считаю, идеальным вариантом является не разработка какой-то монстрообразной системы, функциональность которой невозможно расширить за счет использования сторонних инструментов. Мне бы хотелось получить на выходе простой в использовании инструмент, который:
— мог бы быть системообразующим компонентом;
— либо мог работать совместно с другими инструментами за счет замены имеющихся функций на более подходящие или дополнения своими функциями то, чего нет в других инструментах для автоматизации тестирования, которые используют Selenium Webdriver в качестве основы.

О некоторых мыслях по этому поводу я бы хотел рассказать в заключении.
8. Обещанные ссылки.
Результат моего эксперимента.
Пример проекта для тестирования Google Drive. Реализовано с использованием Yandex QA Tools Html Elements. Возможно, что-то можно сделать и лучше. Но я сам учился. В этом проекте используются FireFox, Chrome, Safari и RemoteWebDriver, вызывающий Chrome.
На всякий случай положил *.jar файл. Если кому-то интересно посмотреть на этот проект в работе, то:
1. Использовать jdk7.
2. Нужно создать maven project.
3. Добавить библиотеку. Не забудьте про selenium (версия 2.35) и TestNG!
4. В файл pom.xml добавить зависимости.
Но заранее предупреждаю, что могут быть проблемы. Документация отсутствует. Возможно, что каким-то ориентиром послужит это. Прошу прощения за корявости, если есть. Все делалось на коленке. На момент публикации кое-что стало неактуальным. Постараюсь исправить. Просто на нормальную документацию нет времени. Да и нужна ли она для проекта, к которому сам относишься, как к эксперименту, пусть даже и интересному?
9. В заключение.

Итак, моя статья уже почти закончилась. Сейчас я ее последний раз перечитываю…
Глядя назад, я вижу, что получился немаленький такой обзор, на который я даже не рассчитывал. Я был бы очень рад, если эта статья кому– то в чем–то помогла, или кто-то сделал для себя небольшое открытие.
Что касается меня, то в любом случае я своей цели добился. Я попробовал самостоятельно копнуть в сторону ранее малоизвестных мне технологий автоматизированного тестирования, поделиться какими-то своими идеями и наработками. Данная статья охватывает не все проблемы, с которыми пришлось столкнуться, и соответственно не все решения рассмотрены. Если этот пост кому-то показался интересным, я могу написать продолжение, но позже.
Результатом стал более или менее рабочий прототип инструмента. Пока что это просто эксперимент, о потенциальной полезности которого я сам не имею представления. Хотелось бы его продолжить и развить до чего-нибудь серьезного. В этом случае:
— я бы попробовал улучшить уже имеющуюся кроссбраузерность. Сейчас есть возможность работы с:
FireFox (использовал 21.0);
Chrome (26-30);
Internet Explorer (использован 9.0.8112);
Safari (5.1.7 для Windows);
Opera (12.16)
HTMLUnitDriver – добавил на всякий случай;
RemoteWebDriver c запуском любого из перечисленных браузеров.
— я бы попробовал добавить поддержку мобильных браузеров iPhone и Android, а так же PhantomJS.
— постарался бы улучшить отчетность для TestNG. Пробовал бы разные варианты их кастомизации.
— можно было бы двинуться в сторону интеграции с Junit.
— исследовать и улучшить интеграционные возможности.
Это здорово, если кому-то идея понравилась. Рад буду узнать критические мнения (но конструктивные), предложения, советы и пожелания.
До встречи!
ссылка на оригинал статьи http://habrahabr.ru/post/192742/
Добавить комментарий