Летят в самолете Петька и
Василий Иванович, Василий Иванович кричит:
— Петька, приборы!
Петька отвечает:
— Двести!
Василий Иванович:
— А что «двести»?
Петька:
— А что «приборы»?
Сегодня выходит из беты наш новый сервис — Яндекс.Город. Он появился как логичное продолжение Яндекс.Справочника, который был единым источником знаний об организациях для всех наших сервисов. Его данные используются собственно в приложении Я.Город, на Яндекс.Картах, в сниппетах на странице результатов поиска, для построения маршрутов в Картах и Навигаторе, определения номера в Яндекс.Ките, выбора мест отправления и прибытия в Такси. Найти места и организации можно было на многих наших площадках, а вот выбирать там не очень удобно. Мы поняли, что пользователям для этого нужен отдельный сервис.
У сервиса поиска мест на Яндексе многолетняя история, и к его созданию приложили руку несколько команд. Растёт он из проекта adresa.yandex.ru. Потом Яндекс интегрировал в него бизнес «Жёлтых страниц» — так появился Справочник. Около года назад очень сильно обновилась команда сервиса. И он начал превращаться в Яндекс.Город. Я в этой команде руковожу службой производства данных и сегодня расскажу вам о том, какие у нас метрики и как они помогают нам делать лучшую базу организаций в России.
И если у вас свой бизнес, и если вы наемный менеджер, вам очень важно уметь измерять бизнес-показатели. Как вы поймёте, что хорошо или плохо всё работает? Как проверите, что изменения привели к улучшению? На чем вы будете основываться, принимая решения? Для всего этого нужны метрики — количественные характеристики состояния системы.
Как мы выбирали метрики
На самом деле, когда-то давно мы жили вообще без них. То, что нам удалось разработать какую-то систему оценки, на которую мы начали ориентироваться, само по себе стало большим достижением для всей команды. На следующем этапе мы начали размышлять о том, хорошие ли у нас метрики.
Одним из наших базовых показателей стало количество известных сервису организаций (POI). Но при ближайшем рассмотрении эта метрика оказалась довольно бессмысленной. Она безусловно удобна и полезна для оперативного управления, потому что её легко считать и она всем понятна. Но мы делаем продукт для пользователей, а их счастье в ней никак не отражалось.
Посудите сами, стало ли пользователю лучше от того, что мы знали 50К организаций, а стали знать 60К организаций? Возможно. А если мы все равно не знаем ближайшей к его дому круглосуточной аптеки или ближайшего банкомата нужного банка?
Но если мы выбрали для себя метрикой количество организаций, то перед тем как ответить человку на его вопрос, нам нужно прояснить один важный момент. А считать ли организацией этот самый банкомат? А киоск Роспечати? А общественный туалет? А автоматический киоск по продаже билетов на метро или электричку?
Кажется, что обобщив потребности пользователя, дать ответы на эти вопросы может менеджер продукта. Но продуктов много и у каждого есть свой менеджер со своими требованиями к данным. Как свести их в единый и не противоречивый заказ, учитывая то, что каждый заказчик не может знать всех деталей о базе?
Осознав, что не нужно дожидаться, что кто-то даст ответ за меня, я написал некоторое консолидированное определение организации и выложил его в общедоступное место. Внизу приписал: «Аргументированные предложения по изменению данного документа присылайте следующему списку людей». Это позволило начать работу параллельно с бесконечными обсуждениями того, как правильно жить.
Как мы уже обсудили выше, метрика «общее количество известных организаций» не самая лучшая, так как не помогает нам понять, насколько хорошо мы решаем задачи пользователя. А делать это — наша главная цель.
Давайте посмотрим, каким все-таки набором метрик можно описывать наш проект. В голову приходят довольно очевидные метрики:
- Упомянутое выше количество организаций – как абсолютное, так и в сравнении с основными конкурентами (в том числе по отдельным категориям).
- Число/доля нерелевантных ответов, которые были вызваны из-за того, что организации не было в базе данных. Удобная метрика, но сложная для измерения, особенно в масштабе нашей страны.
- Точность – доля организаций с правильными данными среди всех доступных в системе организаций.
- Полнота – доля известных Яндексу организаций среди всех организаций в реальном мире.
И мы выбрали последние две метрики как те, которые наилучшим образом отражают качество работы системы и сложность измерения которых нас устраивала.
Как мы считали метрики
Вроде бы жизнь наладилась: мы определили метрики, регулярно измеряли их, продумывали мероприятия по их улучшению. Живи и радуйся. Внутри компании крайне охотно стали обсуждать метрики в терминах «точность должна быть не ниже Х» или «полнота должна быть не ниже Y». Всем казалось понятным, что такое точность – и она, конечно, должна быть как можно выше. Не очень интересно, что же мы считаем организацией, что мы считаем ошибкой, влияющей на точность, и так далее.
Но когда мы проанализировали, как на самом деле мы измеряем точность, то оказалось, что разные стороны часто понимают под этим немного разное. И удалось бы сэкономить многие часы, потраченные на оживленные совещания, если бы сразу стало понятно – мы говорим на разных языках и потому не можем договориться. Наши данные используются разными сервисами Яндекса, и каждый сервис предъявляет свои требования к точности. Но удивительная история: при этом они просто требуют «данные с точностью не ниже X». Большим сюрпризом для всех оказалось то, что точность все понимают сильно по-разному.
В результате мы описали несколько метрик точности, последовательно усиливающих одна другую. Благодаря этому мы увидели, что если по базовой метрике, использовавшейся с самого начала, наша точность действительно высока (выше 90%), то по остальным она может достигать 50-60%. И именно вложенность метрик друг в друга позволяет последовательно работать над качеством базы, переходя от одной метрики к другой.
Естественно, все подобные измерения происходят на случайных выборках организаций, и это влечет за собой еще одну коварную ошибку. Часто люди забывают, что у любой косвенной метрики есть погрешность. То есть, если полгода назад точность по замерам была 62%, а сейчас после выполнения какого-то проекта стала 63%, то это еще ни о чем не говорит, рано бить в барабаны. Подобное цитирование статистических данных вообще непрофессионально, если одновременно не указывается погрешность.
Вторая ошибка при работе с подобными метриками – использование каких-то балльных метрик. Например, в зависимости от значимости ошибки ставить «оценку» от 1 до 5. Получить приемлемую погрешность оценки при вменяемых затратах на измерение можно только в случае бинарной метрики – то есть данные о конкретной организации либо точные, либо нет.
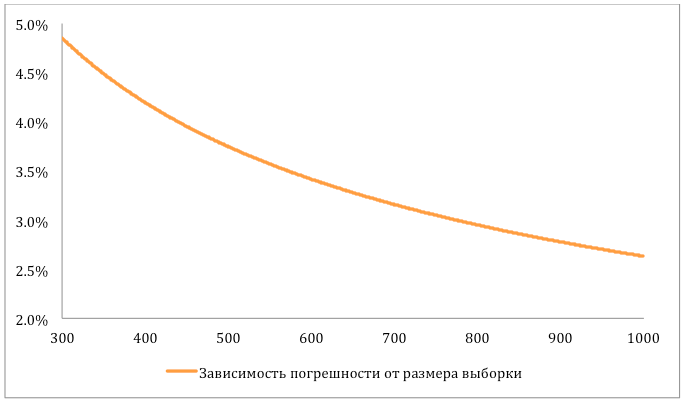
Как уже говорилось выше, измерение метрик происходит на основе случайных выборок. Случайные выборки вручную проверяются людьми, и на основании этого оценивается итоговая метрика. Чем больше выборка, тем выше трудозатраты на ее проверку (разметку). В идеальном мире, которого не существует, трудозатраты ничего не стоят и проверка организации занимает бесконечно мало времени. Поэтому там, в идеальном мире, логичным было бы проверить всю базу и посчитать значение точности. Тогда бы, кстати, не пришлось постоянно делать поправки на погрешности. Однако реальность вносит свои коррективы и хочется определить оптимальный размер выборки. На помощь приходит математическая статистика.
Предположим, что у нас в базе N=40 000 организаций. Нас интересует размер выборки n, которую необходимо разметить, чтобы на ее основе сделать достоверное заключение о точности всей базы. Отметим, что на основе выборочной разметки можно будет сделать лишь вывод следующего вида:
«Реальная точность базы отклоняется от некоторого числа p не более чем на δ с вероятностью не менее P».
Итак, у нас есть три величины: n – размер выборки, δ – погрешность оценки, P – вероятность данной оценки. Само собой, мы хотим минимизировать наши затраты на разметку n организаций, минимизировать погрешность оценки δ и максимизировать вероятность P, с которой мы сможем утверждать, что результаты, полученные на основе выборки, применимы и ко всей базе в целом. Но, как в известной шутке «Быстро, качественно, недорого — выбирайте любые два пункта», нам необходимо чем-то пожертвовать. Вероятностью P мы сильно жертвовать не будем, иначе полученная оценка будет лишь с малой вероятностью отражать реальное состояние дел, а зачем же тогда проводился замер? Договоримся на вероятности P=95% и допустимой погрешности δ=5%. А размер минимальной выборки теперь не составит труда вычислить. И что не может не радовать, можно заведомо утверждать, что достаточно будет разметить выборку всего лишь из 384 организаций!
Предположим, что мы оценили выборку размера n=384 организаций, и из них m=290 организаций оказались верными. Тогда имеем следующую оценку: ![]() . А погрешность оценки есть
. А погрешность оценки есть ![]() %
%
Как уже отмечалось, получив при следующем измерении, например,
Теперь перейдем к другой определяющей метрике каждого справочника – метрике полноты. Полнотой называется доля организаций реального мира, представленных в справочнике. Так, если в городе Х расположено 10000 интересующих вас организаций, а вам известно только 6000 из них, то ваша полнота равняется 60%.
Эту метрику «честным» способом можно измерять, только посещая организации в реальном мире, — то есть сама по себе метрика, с точки зрения трудозатрат, достаточно дорогая. К счастью, по тем же соображениям, что и выше, нам достаточно случайного потока всего в 384 организации, чтобы измерить полноту с приемлемой погрешностью.
Сам процесс замера происходит следующим образом. Первое, что нам нужно сделать – создать случайную выборку адресов (номеров домов) на основании имеющейся у нас на Картах базы адресов. Далее необходимо посетить каждый дом и согласно выбранному определению описать все присутствующие там организации.

Случайная выборка из собранных организаций проверяется на факт присутствия в Яндекс.Городе. Оценка полноты и погрешность данной оценки вычисляются по формулам, которые нам уже знакомы.
Выводы
Помимо технических вещей, хочется выделить те менеджерские уроки, которые я вынес за время работы в Яндекс.Городе.
- [капитан очевидность™] Метрики нужны для управления любым процессом или проектом. При этом по возможности они должны быть простыми и понятными. Ничего плохого в сложных метриках нет, но в случае с большой распределенной командой обязательно должна существовать простая метрика, разделяемая всеми членами команды.
- При оценке любой метрики и сравнении метрик в разные моменты времени важно понимать погрешность данной оценки.
- При оценке метрик на случайных выборках требуется использовать бинарные метрики, так как только такой подход позволяет достичь приемлемой точности оценки при относительно небольшом числе измерений.
- Если вам приносят какую-то метрику, не поленитесь, выясните, как именно она посчитана. Попросите исходник, формулу, описание алгоритма расчета, примеры разметки. Узнайте размеры выборок, и как они генерировались. Сюрпризом может оказаться, что какая-нибудь оффлайновая метрика, измеряемая раз в год, считается обычно на данных за последний месяц — то есть без учета сезонности.
Мы рассмотрели две метрики – точность и полноту, которые, с одной стороны, позволяют нам адекватно судить о том, насколько хорошо мы отражаем организации из реального мира в нашей системе, а с другой стороны — достаточно понятные для всей компании и недорогие для измерения.
В следующий раз мы расскажем о том, как измерять оффлайновую метрику полноты в тех случаях, когда для города нет хорошей карты, что в нашем случае значит, что у нас нет адресной информации и полного списка «домиков».
ссылка на оригинал статьи http://habrahabr.ru/company/yandex/blog/226517/
Добавить комментарий