Для одной из задач мне понадобился синтаксический анализатор русскоязычных текстов. Что это такое. Например, у нас есть предложение «Мама мыла раму». Нам нужно получить связи слов в этом предложении в виде дерева:

Из этого дерева понятно, что связаны слова «мама» и «мыла», а также «мыла» и «раму», а слова «мама» и «раму» напрямую не связаны.
Статья будет полезна тем, кому понадобился синтаксический анализатор, но не понятно, с чего начать.
Я занимался этой темой несколько месяцев назад, и на тот момент нашел не много информации по поводу того, где бы взять готовый и желательно свободный анализатор.
На Хабре есть отличная статья об опыте работы с MaltParser. Но с тех пор некоторые пакеты, используемые для сборки, переехали в другие репозитории и чтобы собрать проект с нужными версиями библиотек, придется хорошенько потрудиться.
Есть и другие варианты, среди которых SyntaxNet. На Хабре я не нашел ничего про SyntaxNet, поэтому восполняю пробел.
Что такое SyntaxNet
По сути SyntaxNet — это основанная на TensorFlow библиотека определения синтаксических связей, использует нейронную сеть. В настоящий момент поддерживается 40 языков, в том числе и Русский.
Установка SyntaxNet
Весь процесс установки описан в официальной документации. Дублировать инструкцию здесь смысла не вижу, отмечу лишь один момент. Для сборки используется Bazel. Я попробовал собрать проект с его помощью у себя на виртуалке с Ubuntu 16.04 x64 Server с выделенными 4-мя процессорами и 8 ГБ оперативной памяти и это не увенчалось успехом — вся память съедается и задействуется своп. После нескольких часов я прервал процесс установки, и повторил всё, выделив уже 12 ГБ оперативной памяти. В этом случае все прошло гладко, в пике задействовался своп только на 20 МБ.
Возможно есть какие-то настройки, с помощью которых можно поставить систему в окружении с меньшим объемом оперативной памяти. Возможно сборка выполняется в нескольких параллельных процессах и стоило выделять виртуальной машине только 1 процессор. Если вы знаете, напишите в комментариях.
После завершения установки я оставил для этой виртуальной машины 1ГБ памяти и этого хватает с запасом для того, чтобы успешно парсить тексты.
В качестве размеченного корпуса я выбрал Russian-SynTagRus, он более объемный по сравнению с Russian и с ним точность должна получаться выше.
Использование SyntaxNet
Чтобы распарсить предложение, переходим в каталог tensorflow/models/syntaxnet и запускаем (путь к модели — абсолютный):
echo "Мама мыла раму" | syntaxnet/models/parsey_universal/parse.sh /home/tensor/tensorflow/Russian-SynTagRus > result.txtВ файле result.txt получаем примерно такой вывод, я заменил данные в 6-й колонке на "_", чтобы тут не переносились строки, иначе неудобно читать:
cat result.txt 1 Мама _ NOUN _ _ 2 nsubj __ 2 мыла _ VERB _ _ 0 ROOT _ _ 3 раму _ NOUN _ _ 2 dobj __ Данные представлены в формате CoNLL-U.
Тут наибольший интерес представляют следующие колонки:
1. порядковый номер слова в предложении,
2. слово (или символ пунктуации),
4. часть речи, тут можно посмотреть описание частей речи,
7. номер родительского слова (или 0 для корня).
То есть мы имеем дерево, в которм слово «мыла» — корень, потому что оно находится в той строке, где колонка номер 7 содержит «0». У слова «мыла» порядковый номер 2. Ищем все строки, в которых колонка номер 7 содержит «2», это дочерние элементы к слову «мыла». Итого, получаем:

Кстати, если разобраться подробнее, то дерево не всегда удачно представляется все зависимости. В ABBYY Compreno, например, в дерево добавляют дополнительные связи, которые указывают на связь элементов, находящихся в разных ветках дерева. В нашем случае таких связей мы не получим.
{kind=link}
Интерфейс
Если вам критична скорость парсинга текстов, то можно попробовать разобраться с TensorFlow Serving, с помощью него можно загружать модель в память один раз и далее получать ответы существенно быстрее. К сожалению, наладить работу через TensorFlow Serving оказалось не так просто, как казалось изначально. Но в целом это возможно. Вот пример, как это удалось сделать для корейского языка. Если у вас есть пример как это сделать для русского языка, напишите в комментариях.
В моем случае скорость парсинга не была сильно критичной, поэтому я не стал добивать тему с TensorFlow Serving и написал простое API для работы с SyntaxNet, чтобы можно было держать SyntaxNet на отдельном сервере и обращаться к нему по HTTP.
В этом репозитории есть и веб интерфейс, который удобно использовать для отладки, чтобы посмотреть как именно распарсилось предложение.

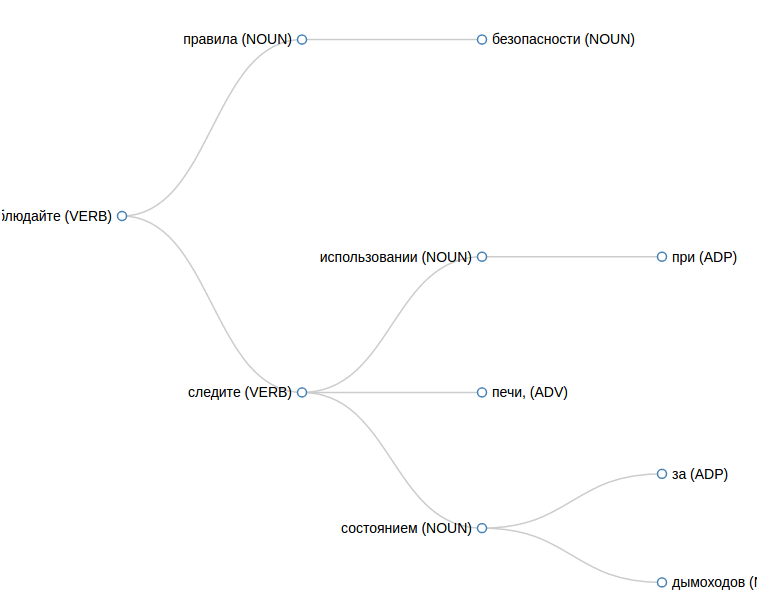
Чтобы получить результат в JSON, делаем такой запрос:
curl -d text="Мама мыла раму." -d format="JSON" http://<host where syntax-tree installed>Получаем такой ответ:
[{ number: "2", text: "мыла", pos: "VERB", children: [ { number: "1", text: "мама", pos: "NOUN", children: [ ] }, { number: "3", text: "раму", pos: "NOUN", children: [ ] } ] }] Уточню один момент. Bazel интересным образом устанавливает пакеты, так, что часть бинарников хранится в ~/.cache/bazel. Чтобы получить доступ к их исполнению из PHP, я на локальной машине добавил права на этот каталог для пользователя веб сервера. Наверное той же цели можно добиться более культурным путем, но для экспериментов этого достаточно.
Что еще
Еще есть MaltParser, о котором я упомянул вначале. Позже я обнаружил, что тут можно скачать размеченный корпус SynTagRus и даже успешно обучил на нем свежую версию MaltParser, но не нашел пока времени довести дело до конца и собрать MaltParser целиком, чтобы получать результат парсинга. Эта система немного иначе строит дерево и мне для своей задачи интересно сравнить результаты, получаемые с помощью SyntaxNet и MaltParser. Возможно в следующий раз удастся написать об этом.
Если вы уже успешно пользуетесь каким-либо инструментом для синтаксического анализа текстов на русском языке, напишите в комментариях, чем вы пользуетесь, мне и другим читателям будет интересно узнать.
ссылка на оригинал статьи https://habrahabr.ru/post/317564/
Добавить комментарий