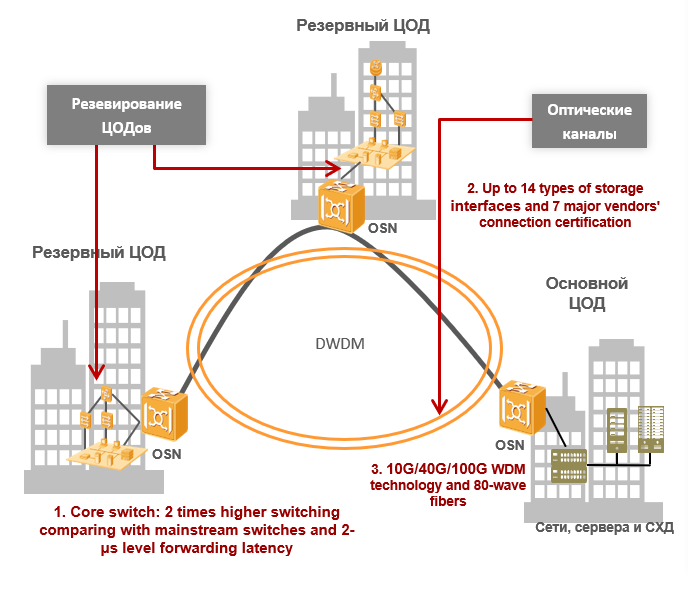
Объемы обрабатываемых человечеством данных выросли до невероятных величин, а роль IT-инфраструктуры в бизнес-процессах настолько велика, что даже кратковременные сбои могут полностью парализовать деятельность компании. Цифровые технологии внедряются повсеместно, и особенно сильно от них зависит финансовый сектор, телеком или, к примеру, крупный интернет-ритейл. Для большого облачного провайдера, банка или крупного оператора связи обеспечиваемой дата-центрами надежности не хватает: потери от небольшого простоя могут исчисляться астрономическими суммами и, чтобы их избежать, нужна катастрофоустойчивая инфраструктура. Создать ее можно только за счет увеличения избыточности — приходится строить резервные ЦОДы.
Отделяем понятия высокодоступности от аварийного восстановления
Объединяться могут корпоративные дата-центры или установленное на арендуемых площадях оборудование. Отказоустойчивость геораспределенных решений достигается за счет программной архитектуры, и на собственных объектах владельцы могут сэкономить: им необязательно строить ЦОД, например, уровня Tier III или даже Tier II. Можно отказаться от дизель-генераторов, использовать бескорпусные серверы, играть с экстремальными температурными режимами и проделывать другие интересные фокусы. На арендуемых площадях степеней свободы меньше, здесь правила игры определяет провайдер, но принципы объединения те же самые. Прежде чем говорить о катастрофоустойчивых IT-сервисах, стоит вспомнить три волшебных аббревиатуры: RTO, RPO и RCO. Эти ключевые показатели эффективности определяют возможность IT-инфраструктуры противостоять сбоям.
RTO (Recovery time objective) — допустимое время восстановления IT-системы после инцидента;
RPO (Recovery point objective) — допустимая при аварийном восстановлении потеря данных. Обычно измеряется как максимальный период, в течение которого данные могут быть потеряны;
RCO (Recovery capacity objective) — часть IT-нагрузки, которую способна взять на себя резервная система. Последний показатель может измеряться в процентах, транзакциях и прочих «попугаях».
Здесь важно отличать решения высокой доступности (HA — High Availability) от решений для аварийного восстановления (DR — Disaster Recovery). Наглядно разницу между ними можно представить в виде диаграммы с RPO и RTO в качестве координатных осей:
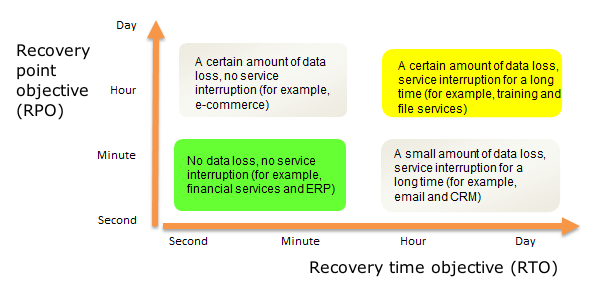
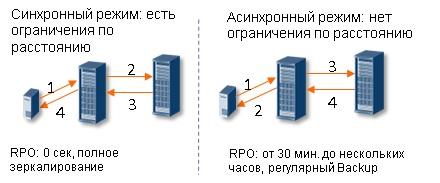
В идеале мы не теряем данные и не тратим время на восстановление после сбоя, а резервная площадка обеспечит полную работоспособность сервисов, даже если основная будет разрушена. Нулевых RTO и RPO можно достичь только при синхронном режиме работы дата-центров: по сути это географически распределенный отказоустойчивый кластер с репликацией данных в реальном времени и прочими радостями. При асинхронном режиме целостность данных уже не гарантируется: поскольку репликация делается с определенной периодичностью, часть информации может быть потеряна. Время переключения на резервную площадку в этом случае составляет от нескольких минут до нескольких часов, если речь идет о т.н. холодном резерве, когда большая часть дублирующего оборудования выключена и не потребляет электроэнергию.
Технические нюансы
Возникающие при объединении двух и более центров обработки данных технические трудности делятся на три категории: задержки при передаче данных, недостаточная пропускная способность каналов связи и проблемы информационной безопасности. Связь между дата-центрами обычно обеспечивают собственные или арендуемые волоконно-оптические линии связи, поэтому дальше мы будем говорить о них. Для работающих в синхронном режиме ЦОДов основной проблемой являются задержки. Чтобы обеспечить репликацию данных в реальном масштабе времени, они не должны превышать 20 миллисекунд, а иногда и 10 миллисекунд — это зависит от типа приложения или сервиса.
В противном случае не будут работать, например, протоколы семейства Fibre Channel, обойтись без которых в современных системах хранения данных практически невозможно. Там чем выше скорость, тем меньше должна быть задержка. Есть, конечно, протоколы, позволяющие работать с сетями хранения данных через Ethernet, но тут уже многое зависит от используемых в дата-центре приложений и установленного оборудования. Ниже в качестве примера представлены требования к задержкам для широко распространённых приложений Oracle и VMware:
Требования к задержкам Oracle Extended Distance Cluster:
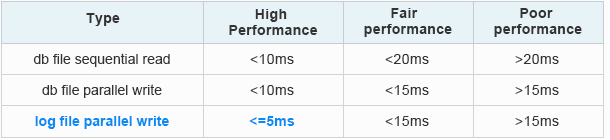
From Oracle official data: How to Tell if the IO of the Database is Slow [ID 1275596.1]
Требования к задержкам VMware:

VMware vSphere Metro Storage Cluster Case Study VMware vSphere 5.0)
При передаче данных задержку сигнала можно представить в виде двух составляющих: Тобщая= Тоборуд. + Тов, где Тоборуд. – задержка, вызванная прохождением сигнала через оборудование, а Тов — задержка, вызванная прохождением сигнала через оптическое волокно. Задержка, вызванная прохождением сигнала через оборудование (Тоборуд ), зависит от архитектуры оборудования и способа инкапсуляции данных при оптико-электрическом преобразовании сигнала. В оборудовании DWDM этот функционал возложен на модули транспондера или мукспондера. Поэтому при организации связи между двумя дата-центрами особенно тщательно подходят к выбору типа транспондера(мукспондера), чтобы величина задержки на транспондере (мукспондере) была наименьшей.
При синхронном режиме важную роль играет скорость распространения сигнала в оптическом волокне (Тов). Известно, что скорость распространения света в стандартном (например, G.652) оптическом волокне зависит от коэффициента преломления его сердцевины и примерно равна 70% скорости света в вакууме (~300 000 км/с). Глубоко лезть в физические основы не станем, но легко посчитать что задержка в этом случае составляет где-то 5 микросекунд на километр. Поэтому два датацентра могут работать синхронно на расстоянии лишь около 100 километров.
При асинхронном режиме требования к задержкам не такие жесткие, но если сильно увеличить расстояние между объектами, начинает сказываться затухание оптического сигнала в волокне. Сигнал приходится усиливать и регенерировать, т.е приходится создавать собственные системы передачи или арендовать магистральные каналы связи. Объемы проходящего между двумя дата-центрами трафика достаточно велики и имеют свойство постоянно расти. Основные драйверы роста трафика между ЦОДами: виртуализация, облачные сервисы, миграция и подключение новых серверов и СХД. Здесь можно столкнуться и с проблемой недостаточной пропускной способности каналов передачи данных. Увеличивать ее до бесконечности не получится из-за отсутствия собственных свободных волокон или высокой стоимости аренды. Последний важный момент связан с информационной безопасностью: бегающие между ЦОДами данные нужно шифровать, что также увеличивает задержки. Есть и другие моменты, вроде сложности администрирования распределенной системы, но их влияние не столь велико, а все технические препятствия связаны в основном с особенностями каналов связи и оконечного оборудования.
Два или три — экономические трудности
Оба режима объединения дата-центров имеют существенные недостатки. Работающие синхронно объекты должны быть расположены недалеко друг от друга, что не гарантирует выживание хотя бы одного из них в случае масштабной катастрофы. Да, такой вариант надежно защищен от человеческой ошибки, от пожара, от разрушения машинного зала в результате падения самолета или от другого локального ЧП, но далеко не факт, что оба ЦОДа выдержат, например, катастрофическое землетрясение. В асинхронном режиме объекты можно разнести на тысячи километров, но обеспечить приемлемые значения RTO и RPO при этом уже не получится. Идеальным решением будет схема с тремя дата-центрами, два из которых работают синхронно, а третий расположен максимально далеко от них и играет роль асинхронного резерва.
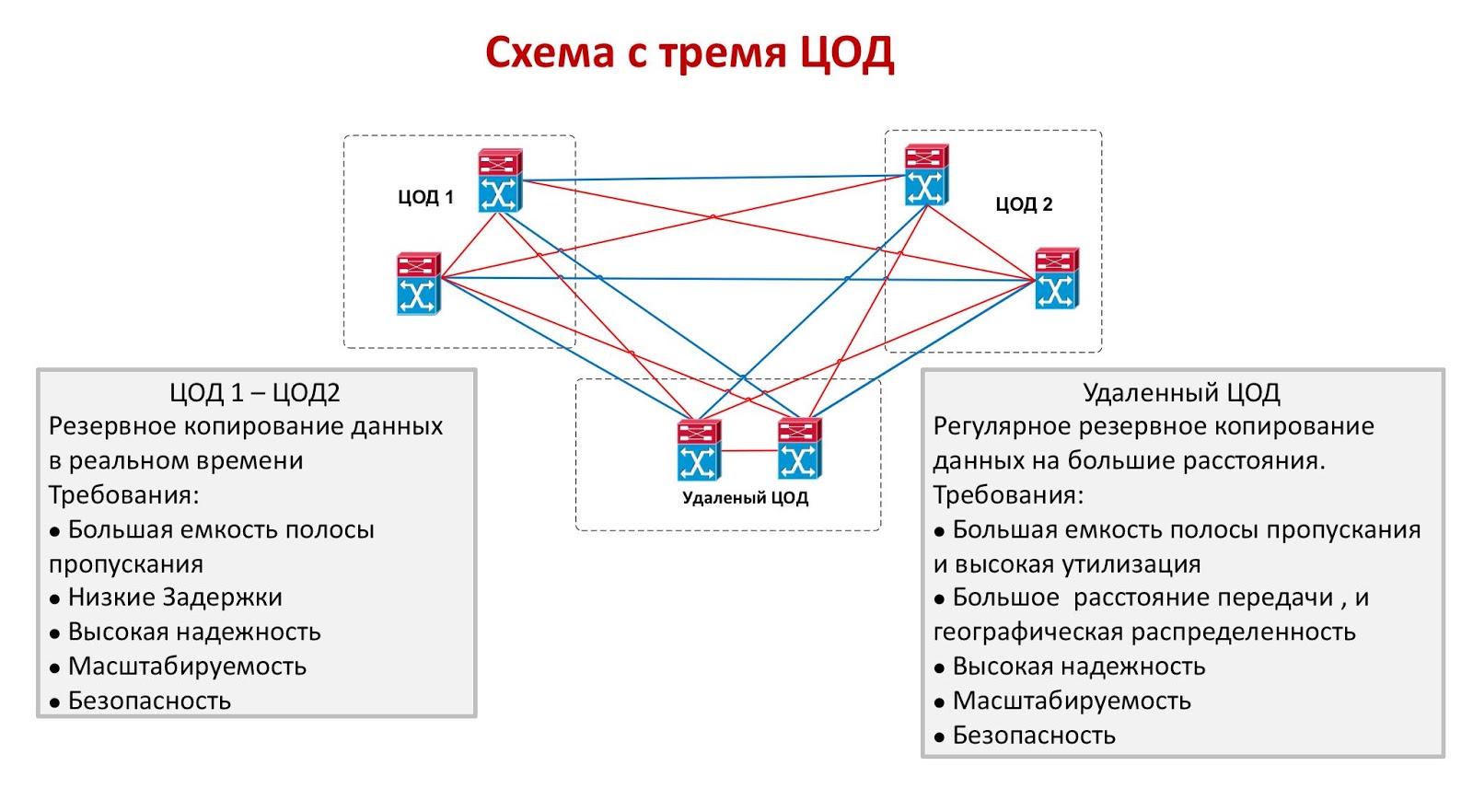
Единственная проблема схемы с тремя ЦОДами — ее чрезвычайно высокая стоимость. Организация даже одной резервной площадки обходится недешево, а уж держать два простаивающих дата-центра могут себе позволить немногие. Подобный подход иногда применяется в финансовом секторе, если стоимость транзакции очень высока: крупная биржа может запустить схему с тремя небольшими ЦОДами, но уже в банковском секторе предпочитают использовать синхронное объединение двух. В других отраслях обычно объединяются два ЦОДа, работающие в синхронном или в асинхронном режиме.
DWDM — оптимальное решение для DCI
Если заказчику необходимо объединить два центра обработки данных, он неизбежно столкнется с указанными выше проблемами. Для их решения мы используем технологию спектрального уплотнения DWDM, позволяющую мультиплексировать ряд несущих сигналов в одно оптическое волокно с использованием разных длин волн (λ, т.е.«лямбд»). При этом в одной оптической паре может быть до 80(96) длин волн согласно сетке частот ITU-T G.694.1. Скорость передачи данных каждой длины волны составляет 100 Гбит/с, 200 Гбит/с или 400 Гбит/с, а емкость одной оптической пары может достигать 80 λ * 400Гбит/с = 32Tбит/с. Уже есть готовые разработки, обеспечивающие 1 Тбит/с на одну длину волны: они дадут еще большую пропускную способность в ближайшем будущем. Проблему пропускной способности каналов на сегодняшний день это решает полностью: вместо дополнительных волокон заказчик будет более эффективно использовать имеющиеся — утилизация трафика достигнет фантастических величин.
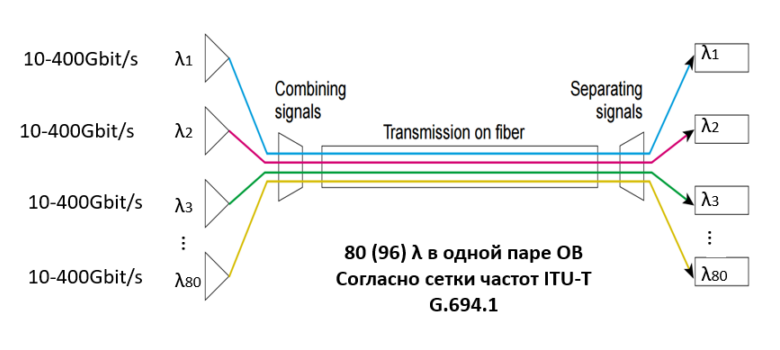
Спектральное уплотнение позволяет решить проблемы с полосой пропускания, и для работающих в синхронном режиме ЦОДов этого вполне достаточно, поскольку задержки при передаче данных между ними невелики из-за небольшого расстояния и больше зависят от типа применяемого транспондера (или мукспондера) в системе DWDM. Стоит отметить одну из главных особенностей технологии спектрального уплотнения DWDM: полностью прозрачную передачу траффика из-за того, что технология работает на первом физическом уровне семиуровневой модели OSI. Если так можно выразиться, система DWDM «прозрачна» для своих клиентских подключений, как если они были бы соединены прямым патч-кордом. Если говорить про асинхронный режим, то основная величина задержки зависит от расстояния между ЦОДами (мы помним, что в ОВ задержка 5 микросекунд на километр), а жестких требований к задержкам нет. Поэтому дальность передачи определяется возможностями системы DWDM и ограничивается тремя факторами: затуханием сигнала, отношением сигнала к шуму и поляризационно-модовой дисперсии света.
При расчете оптической части DWDM-линии все эти факторы учитываются и на основе расчетов подбираются типы транспондеров (или мукспондеров), необходимое количество и тип усилителей, а также прочих составляющих оптического тракта. С развитием систем DWDM и появлением в их составе транспондеров, поддерживающих когерентный прием со скоростями в 40Гбит/с и 100 Гбит/с и выше, поляризационно-модовая дисперсия света как ограничивающий фактор перестала учитываться. Вопрос расчета оптической линии и выбора типа усилителя — это большая отдельная тема, требующая от читателя знаний основы физической оптики, и подробно в этой статье мы ее не рассматриваем.
Технология WDM способна решить и проблемы информационной безопасности. Конечно, шифрование не обязательно должно выполняться на оптическом уровне, но у такого подхода есть ряд неоспоримых преимуществ. Шифрование на более высоких уровнях часто требует автономных устройств для разных потоков трафика и способствует значительным задержкам. С увеличением количества таких устройств растут и задержки, сложность управления сетью также увеличивается. Шифрование на оптическом уровне OTN (G.709 — рекомендация ITU-T, описывающая формат кадра в DWDM-системах) не зависит от типа сервиса, не требует отдельных устройств и выполняется очень быстро — разница между зашифрованным и не зашифрованным потоком данных обычно не превышает 10 миллисекунд.

Без использования технологии спектрального уплотнения DWDM почти невозможно объединить крупные центры обработки данных и создать катастрофоустойчивый распределенный кластер. Объемы передаваемой по сети информации растут экспоненциально и рано или поздно возможности существующих оптико-волоконных линий связи будут исчерпаны. Прокладка или аренда дополнительных обойдётся заказчику гораздо дороже покупки оборудования, по сути сегодня уплотнение — это единственный экономически целесообразный вариант. На небольших расстояниях технологии DWDM позволяют эффективнее использовать имеющиеся оптические волокна, поднимая утилизацию трафика до небес, а на дальних — еще и минимизируют задержки при передаче данных. На сегодняшний день это, пожалуй, лучшая из имеющихся на рынке технологий и к ней стоит присмотреться внимательнее.
ссылка на оригинал статьи https://habr.com/company/huawei/blog/428249/
Добавить комментарий