Объем данных, доступных в Интернете, постоянно растет как по количеству, так и по форме. И эти данные очень часто бывают нужны для обучения ИИ. Большая часть этих данных доступна через API, но в то же время многие ценные данные по-прежнему доступны только через парсинг.
В данном руководстве будут рассмотрены несколько вариантов получения данных.
Для примера данных возьмем список мероприятий Рунета
Посмотрим исходный код страницы, чтобы понимать откуда мы будем извлекать данные
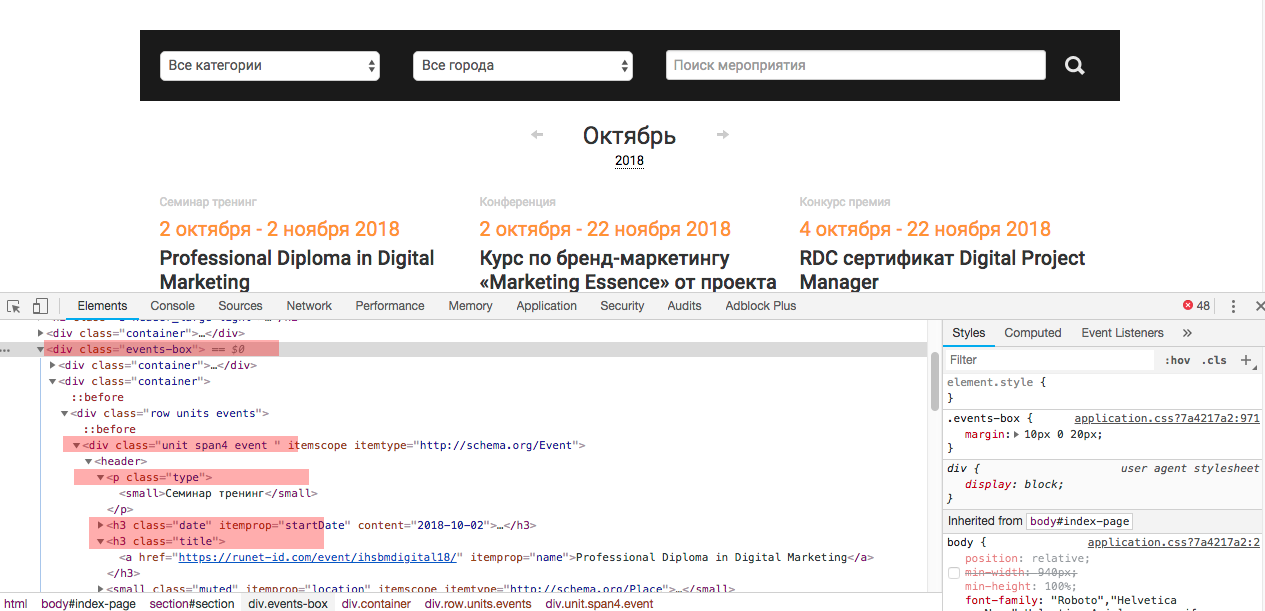
Как видно — все события выводятся в слое —
<div class="events-box">
отдельное событие выводится в слое —
<div class="unit span4 event " itemscope="" itemtype="http://schema.org/Event">
и каждое событие имеет определенные атрибуты, которые мы и будем собирать
-
Тип
<p class="type"> -
Заголовок
<h3 class="title"> -
Содержание
<p itemprop="description">
Теперь, когда мы имеем представление, что конкретно из содержимого нам нужно можно приступать к парсингу.
1. Получение данных с помощью применения библиотек Requests и Beautiful Soup.
Для начала установим библиотеки
$ pip install requests
$ pip install bs4
После установки приступим непосредственно к парсингу
Начнем с подключения библиотеки Requests и проверки правильно ли отрабатывается запрос
import requests url = 'https://runet-id.com/events/' requests.get(url)
Получим вывод в консоли:
<Response [200]>
Значит все верно сделано и страница получена.
Теперь посмотрим в каком виде она нам передается, добавим к нашему коду:
req = requests.get(url).text print(req[:100]) #отображение 100 символов
Результат:
<html> <head> <link rel="stylesheet" type="text/css" href="/javascripts/jquery.u
Как видно мы получили html код страницы. Но данный формат не удобен для анализа — поэтому мы будем использовать библиотеку Beautiful Soup, чтобы данные получить в нужном формате.
Для этого мы импортируем библиотеку
from bs4 import BeautifulSoup
создадим объект и передадим ему содержимое
soup = BeautifulSoup(req.text, 'lxml')
Обозначим Beautiful Soup, что является контейнером данных и что затем в нем искать
events = soup.find('div', {'class': 'events-box'}).findAll('div', {'class', 'unit span4 event '})
И создадим словарь, в который разместим все события с атрибутами
i = 0 events = [] for event in events: event_type = event.find('small').text event_title = event.find('h3', {'class', 'title'}).text event_desc = event.find('p', {'itemprop': 'description'}).text event_details[i] = [event_type, event_title, event_desc] i += 1
Можно все оформить как функцию
import requests from bs4 import BeautifulSoup def get_upcoming_events(url): req = requests.get(url) events_dict = {} i = 0 soup = BeautifulSoup(req.text, 'lxml') events = soup.find('div', {'class': 'events-box'}).findAll('div', {'class', 'unit span4 event '}) for event in events: event_type = event.find('small').text event_title = event.find('h3', {'class', 'title'}).text event_desc = event.find('p', {'itemprop': 'description'}).text events_dict[i] = [event_type, event_title, event_desc] i += 1
Вызов функции:
get_upcoming_events('https://runet-id.com/events/')
2. Получение данных с помощью Scrapy
Scrapy — очень популярный фреймворк для извлечения данных.В предыдущем пункте мы использовали библиотеки requests для получения и Beautiful Soup для извлечения данных. Scrapy предлагает все эти функции со многими другими встроенными модулями и расширениями.
Scrapy предлагает ряд мощных функций, которые стоит упомянуть:
- Встроенные расширения для создания HTTP-запросов и обработки сжатия, проверки подлинности, кэширования, управления user-agent и HTTP заголовками
- Встроенная поддержка выбора и извлечения данных с использованием выбора языков, таких как CSS и XPath, а также поддержка использования регулярных выражений для выбора контента и ссылок
- Поддержка кодирования для работы с языками и нестандартными объявлениями кодирования
- Гибкие API для повторного использования и написания собственных промежуточных программ и конвейеров, которые обеспечивают простой способ реализации таких задач, как автоматическая загрузка изображений или файлов и хранение данных в хранилищах, таких как файловые системы, S3, базы данных и другие
Его принцип действия схож с обходчиками поисковых систем.
Начнем с установки фреймворка
$ pip install scrapy
Все в Scrapy вращается вокруг создания «паука». «Пауки» сканируют страницы в Интернете на основе правил, которые мы предоставляем. «Паук» создается с определением класса, от которого он происходит. Наш происходит от scrapy.Spider класса.
Каждому «пауку» присваивается имя, а также один или несколько start_urls, которые сообщают, с чего начать сканирование.
class PythonEventsSpider(scrapy.Spider): name = 'pythoneventsspider' start_urls = ['https://runet-id.com/events/', ]
Затем обозначается метод, который будет вызываться для каждой страницы, которую собирает «паук».
for events in response.xpath('//div[contains(@class, "unit span4 event ")]'): event_type = events.xpath('.//small/text()').extract_first() event_title = events.xpath('.//h3[@class="title"]/a/text()').extract_first() event_desc = events.xpath('.//p[@itemprop="description"]/text()').extract_first() events_dict[i] = [event_type, event_title, event_desc] i += 1
Реализация этого метода использует XPath для получения данных со страницы (XPath — встроенное средство навигации по HTML в Scrapy).
Оставшийся код выполняет программный запуск «паука».
process = CrawlerProcess({ 'LOG_LEVEL': 'ERROR'}) process.crawl(PythonEventsSpider) spider = next(iter(process.crawlers)).spider process.start()
Он начинается с создания CrawlerProcess, который выполняет фактическое сканирование и множество других задач. Мы передаем ему LOG_LEVEL OF ERROR, чтобы предотвратить объемный вывод Scrapy. Измените это на DEBUG и запустите его, чтобы увидеть разницу.
Затем мы сообщаем процессу, что нужно использовать нашу реализацию «паука».
И запускаем все это — вызывая process.start ().
Полный код:
import scrapy from scrapy.crawler import CrawlerProcess class PythonEventsSpider(scrapy.Spider): name = 'pythoneventsspider' start_urls = ['https://runet-id.com/events/', ] events_dict = {} def parse(self, response): i = 0 for events in response.xpath('//div[contains(@class, "unit span4 event ")]'): event_type = events.xpath('.//small/text()').extract_first() event_title = events.xpath('.//h3[@class="title"]/a/text()').extract_first() event_desc = events.xpath('.//p[@itemprop="description"]/text()').extract_first() events_dict[i] = [event_type, event_title, event_desc] i += 1 if __name__ == "__main__": process = CrawlerProcess({'LOG_LEVEL': 'ERROR'}) process.crawl(PythonEventsSpider) spider = next(iter(process.crawlers)).spider process.start()
ссылка на оригинал статьи https://habr.com/post/427903/
Добавить комментарий