Впервые фреймворк Vision был представлен широкой общественности на WWDC в 2017 году, вместе с iOS 11.
Vision был создан, чтобы помочь разработчикам классифицировать и идентифицировать объекты, горизонтальные плоскости, штрих-коды, выражения лица и текст.
Однако с распознаванием текста была проблема: Vision мог найти место, где находится текст, но фактического распознавания текста не происходило. Конечно, было приятно видеть ограничивающую рамку вокруг отдельных фрагментов текста, но затем их нужно было вытаскивать и распознавать самостоятельно.
Эту проблему решили в обновлении Vision, которое вошло в iOS 13. Теперь Vision framework предоставляет истинное распознавание текста.
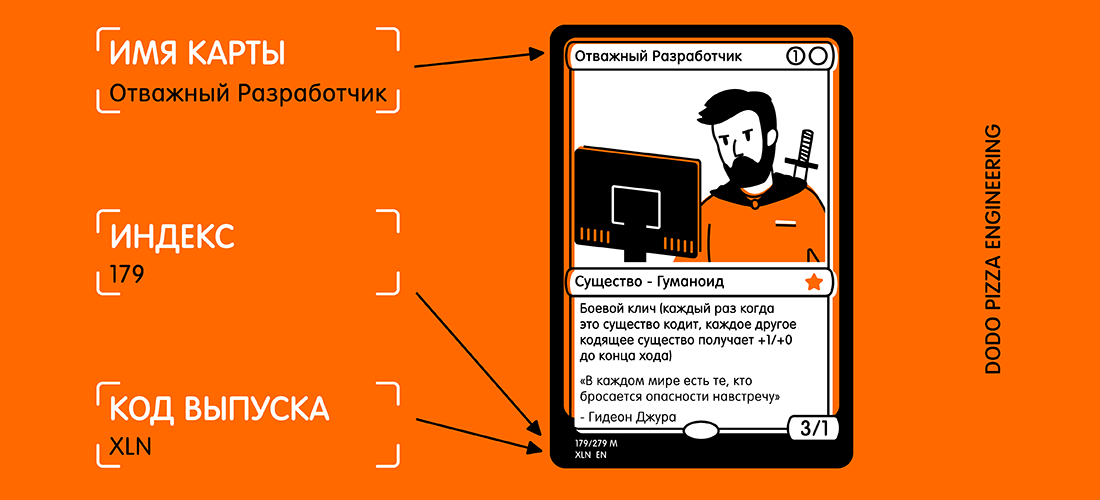
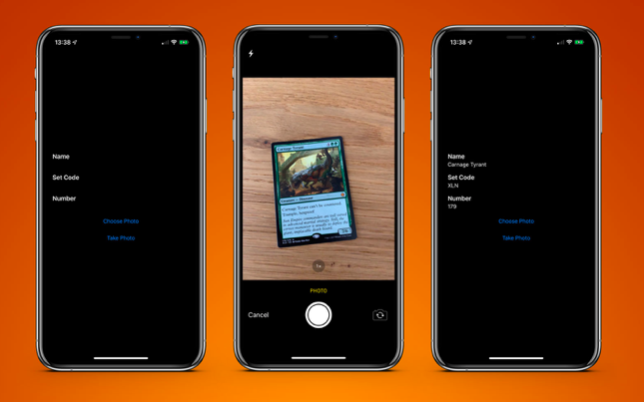
Чтобы проверить это, я создал очень простое приложение, которое может распознать карточку из настольной игры Magic The Gathering и извлекать из нее текстовую информацию:
- имя карты;
- код выпуска;
- коллекционный номер (он же индекс).
Вот пример карты и выделенного текста, который я хотел бы получить.

Глядя на карточку вы можете подумать: «Этот текст довольно мелкий, плюс на карточке есть много другого текста, который может помешать». Но для Vision это не проблема.
Для начала нам нужно создать VNRecognizeTextRequest. По сути, это описание того, что мы надеемся распознать, плюс настройка языка распознавания и уровень точности:
let request = VNRecognizeTextRequest(completionHandler: self.handleDetectedText) request.recognitionLevel = .accurate request.recognitionLanguages = ["en_GB"] Блок завершения имеет вид handleDetectedText(request: VNRequest?, error: Error?). Мы передаём его в конструктор VNRecognizeTextRequest и затем устанавливаем оставшиеся свойства.
Доступно два уровня точности распознавания: .fast и .accurate. Поскольку на нашей карточке довольно маленький текст в нижней части, я выбрал более высокую точность. Быстрый же вариант скорее лучше подойдет для больших объемов текста.
Я ограничил распознавание британским английским, так как все мои карты именно на нём.Вы можете указать несколько языков, но при этом нужно понимать, что сканирование и распознавание может занять немного больше времени для каждого дополнительного языка.
Есть еще два свойства, которые стоит упомянуть:
customWords: вы можете добавить массив строк, которые будут использоваться поверх встроенного лексикона. Это полезно, если в вашем тексте есть какие-нибудь необычные слова. Я не применял опцию для этого проекта. Но если бы я делал коммерческое приложение-распознавалку для карточек Magic The Gathering, то добавил бы некоторые из наиболее сложных карт (например, Fblthp, the Lost), чтобы избежать проблем.minimumTextHeight: это float-значение. Оно обозначает размер относительно высоты изображения, при котором текст больше не должен быть распознан. Если бы я создавал этот сканер, чтобы просто получить имя карты, это было бы полезно для удаления всего другого текста, который не нужен. Но мне нужны самые маленькие кусочки текста, поэтому пока я проигнорировал это свойство. Очевидно, при игнорировании мелких текстов скорость распознавания будет выше.
Теперь, когда у нас есть наш запрос, его вместе с картинкой надо передать обработчику запросов:
let requests = [textDetectionRequest] let imageRequestHandler = VNImageRequestHandler(cgImage: cgImage, orientation: .right, options: [:]) DispatchQueue.global(qos: .userInitiated).async { do { try imageRequestHandler.perform(requests) } catch let error { print("Error: \(error)") } } Я использую изображение прямо с камеры, преобразовав его из UIImage в CGImage. Это используется в VNImageRequestHandler вместе с флагом ориентации, чтобы помочь обработчику понять, какой текст он должен распознавать.
В рамках этого демо я использую телефон только в портретной ориентации. Поэтому, естественно, я добавляю ориентацию .right. Так, падажжи!
Оказывается, ориентация камеры на вашем устройстве полностью отделена от вращения устройства и всегда считается слева (как по умолчанию было принято в 2009 году, что для съемки фотографий нужно держать телефон в альбомной ориентации). Конечно, времена изменились, и мы в основном снимаем фотографии и видео в формате портретной ориентации, но камера по-прежнему выровнена слева.
Как только наш обработчик настроен, мы переходим в поток с приоритетом .userInitiated и пытаемся выполнить наши запросы. Вы можете заметить, что это массив запросов. Так происходит, потому что вы можете попытаться вытащить несколько фрагментов данных за один проход (т. е. идентифицировать лица и текст из одного и того же изображения). Если ошибок нет, обратный вызов, созданный с помощью нашего запроса, будет вызван после обнаружения текста:
func handleDetectedText(request: VNRequest?, error: Error?) { if let error = error { print("ERROR: \(error)") return } guard let results = request?.results, results.count > 0 else { print("No text found") return } for result in results { if let observation = result as? VNRecognizedTextObservation { for text in observation.topCandidates(1) { print(text.string) print(text.confidence) print(observation.boundingBox) print("\n") } } } } Наш обработчик возвращает наш запрос, который теперь имеет свойство results. Каждый результат является VNRecognizedTextObservation, у которого для нас есть сразу несколько вариантов результата (далее — кандидаты).
Вы можете получить до 10 кандидатов на каждую единицу распознанного текста, и они сортируются в порядке убывания уверенности. Это может быть полезным, если у вас есть определенная терминология, которую синтаксический анализатор неправильно распознает с первой попытки. Но определяет правильно позже, даже если он менее уверен в правильности результата.
В этом примере нам нужен только первый результат, поэтому мы проходимся циклом по observation.topCandidates(1) и извлекаем как текст, так и уверенность. В то время как сам кандидат имеет различный текст и уверенность, .boundingBox остается той же. .boundingBox использует нормализованную систему координат с началом координат в левом нижнем углу, поэтому, если она в дальшнейем будет использоваться в UIKit, для вашего же удобства её надо преобразовать.
Это почти всё, что нужно. Если я прогоню фотографию карты через это, я получу следующий результат чуть менее чем за 0,5 секунд на iPhone XS Max:
{kind=link}
Carnage Tyrant 1.0 (0.2654155572255453, 0.6955686092376709, 0.18710780143737793, 0.019915008544921786) Creature 1.0 (0.26317582130432127, 0.423814058303833, 0.09479101498921716, 0.013565015792846635) Dinosaur 1.0 (0.3883238156636556, 0.42648010253906254, 0.10021591186523438, 0.014479541778564364) Carnage Tyrant can't be countered. 1.0 (0.26538230578104655, 0.3742666244506836, 0.4300231456756592, 0.024643898010253906) Trample, hexproof 0.5 (0.2610074838002523, 0.34864263534545903, 0.23053167661031088, 0.022259855270385653) Sun Empire commanders are well versed 1.0 (0.2619712670644124, 0.31746063232421873, 0.45549616813659666, 0.022649812698364302) in advanced martial strategy. Still, the 1.0 (0.2623249689737956, 0.29798884391784664, 0.4314465204874674, 0.021180248260498136) correct maneuver is usually to deploy the 1.0 (0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009) giant, implacable death lizard. 1.0 (0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258) 7/6 0.5 (0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593) 179/279 M 1.0 (0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193) XLN: EN N YEONG-HAO HAN 0.5 (0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319) TN & 0 2017 Wizards of the Coast 1.0 (0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)
Это невероятно! Каждый фрагмент текста был распознан, помещен в его собственную ограничивающую рамку и возвращен в результате с рейтингом доверия 1.0.
Даже очень маленький копирайт в основном корректен. Все это было сделано на изображении 3024×4032 весом в 3,1 МБ. Процесс был бы еще быстрее, если бы я сначала уменьшил изображение. Также стоит отметить, что этот процесс намного быстрее на новых бионических чипах A12, которые имеют специальный нейронный движок.
Когда текст распознан, последнее, что нужно сделать, это вытащить нужную мне информацию. Я не буду помещать весь код здесь, но ключевая логика состоит в том, чтобы перебирая каждую .boundingBox определять местоположение, чтобы я мог выбрать текст в нижнем левом углу и в верхнем левом углу, игнорируя что-либо дальше справа.
Конечным результатом получилось приложение сканирующее карточку и возвращающее мне результат менее, чем за одну секунду.
P.S. На самом деле мне нужен только код выпуска и коллекционный номер (он же индекс). Затем их можно использованы в API сервиса Scryfall для получения всей возможной информации об этой карте, включая правила игры и стоимость.
Пример приложения доступен на GitHub.
ссылка на оригинал статьи https://habr.com/ru/company/dodopizzaio/blog/459668/
Добавить комментарий