
Первая задача, с которой чаще всего сталкиваются разработчики, начинающие программировать на JavaScript, – как регистрировать события в журнале консоли с помощью метода console.log. В поисках информации по отладке кода на JavaScript вы найдёте сотни статей в блогах, а также инструкций на StackOverflow, советующих «просто» вывести данные в консоль через метод console.log. Это настолько распространённая практика, что пришлось ввести правила для контроля качества кода, подобные no-console, чтобы не оставлять случайные записи из журнала в коде для продакшена. Но что делать, если нужно специально зарегистрировать какое-нибудь событие, чтобы предоставить дополнительную информацию?
В этой статье рассматриваются различные ситуации, в которых требуется вести логи; показывается разница между методами console.log и console.error в Node.js и демонстрируется, как передать функцию логирования библиотекам, не перегружая пользовательскую консоль.

Теоретические основы работы с Node.js
Методы console.log и console.error можно использовать как в браузере, так и в Node.js. Тем не менее, при использовании Node.js нужно помнить одну важную вещь. Если создать следующий код в Node.js, используя файл под названием index.js,

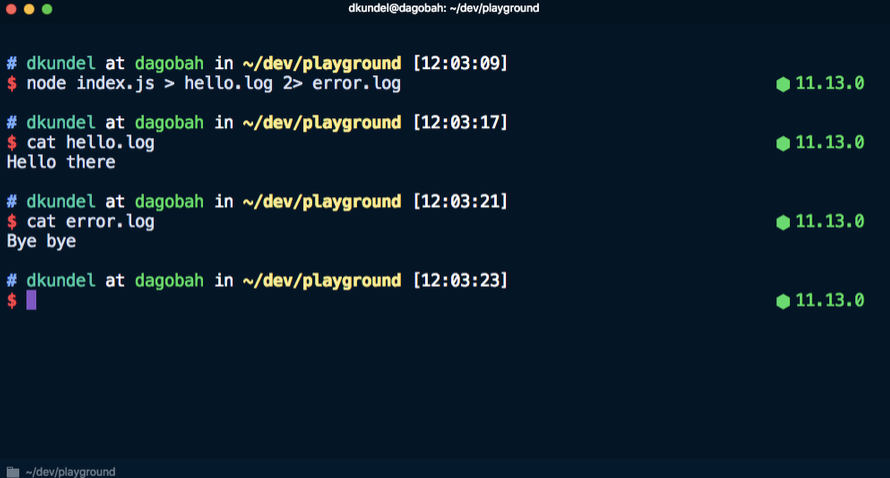
а затем выполнить его в терминале с помощью node index.js, то результаты выполнения команд будут располагаться один над другим:

Несмотря на то, что они кажутся похожими, система обрабатывает их по-разному. Если посмотреть раздел о работе console в документации Node.js, то окажется, что console.log выводит результат через stdout, а console.error – через stderr.
Каждый процесс может работать с тремя потоками (stream) по умолчанию: stdin, stdout и stderr. Поток stdin обрабатывает ввод для процесса, например нажатия кнопок или перенаправленный вывод (об этом чуть ниже). Стандартный поток вывода stdout предназначен для вывода данных приложения. Наконец, стандартный поток ошибок stderr предназначен для вывода сообщений об ошибках. Если нужно разобраться, для чего предназначен stderr и в каких случаях его использовать, прочитайте эту статью.
Если вкратце, то с его помощью можно использовать операторы перенаправления (>) и конвейера (|) для работы с ошибками и диагностической информацией отдельно от фактических результатов работы приложения. Если оператор > позволяет перенаправить вывод результата выполнения команды в файл, то с помощью оператора 2> можно перенаправить вывод потока ошибок stderr в файл. Например, эта команда отправит Hello there в файл hello.log, а Bye bye в файл error.log.

Когда необходимо записывать события в журнал?
Теперь, рассмотрев технические аспекты, лежащие в основе записи в журнал, перейдём к различным сценариям, в которых необходимо регистрировать события. Обычно эти сценарии относятся к одной из нескольких категорий:
- быстрая отладка при неожиданном поведении во время разработки;
- ведение журнала на базе браузера для анализа и диагностики;
- ведение журналов для серверных приложений для регистрации входящих запросов и возможные ошибки;
- ведение дополнительных журналов отладки для библиотек, чтобы помогать пользователям в решении проблем;
- ведение журнала для выходных данных интерфейса командной строки, чтобы выводить сообщения в консоли о ходе выполнения операции, подтверждениях и ошибках.
В этой статье рассматриваются только три последних сценария на базе Node.js.
Ведение журналов для серверных приложений
Существует несколько причин для логирования событий, происходящих на сервере. Например, логирование входящих запросов позволяет получить статистические данные о том, как часто пользователи сталкиваются с ошибкой 404, что может быть этому причиной или какое клиентское приложение User-Agent используется. Также можно узнать время возникновения ошибки и её причину.
Для того чтобы поэкспериментировать с материалом, приведённым в этой части статьи, нужно создать новый каталог для проекта. В каталоге проекта создаём index.js для кода, который будет использоваться, и выполняем следующие команды для запуска проекта и установки express:

Настраиваем сервер с межплатформенным ПО, который будет регистрировать каждый запрос в консоли с помощью метода console.log. Помещаем следующие строки в файл index.js:
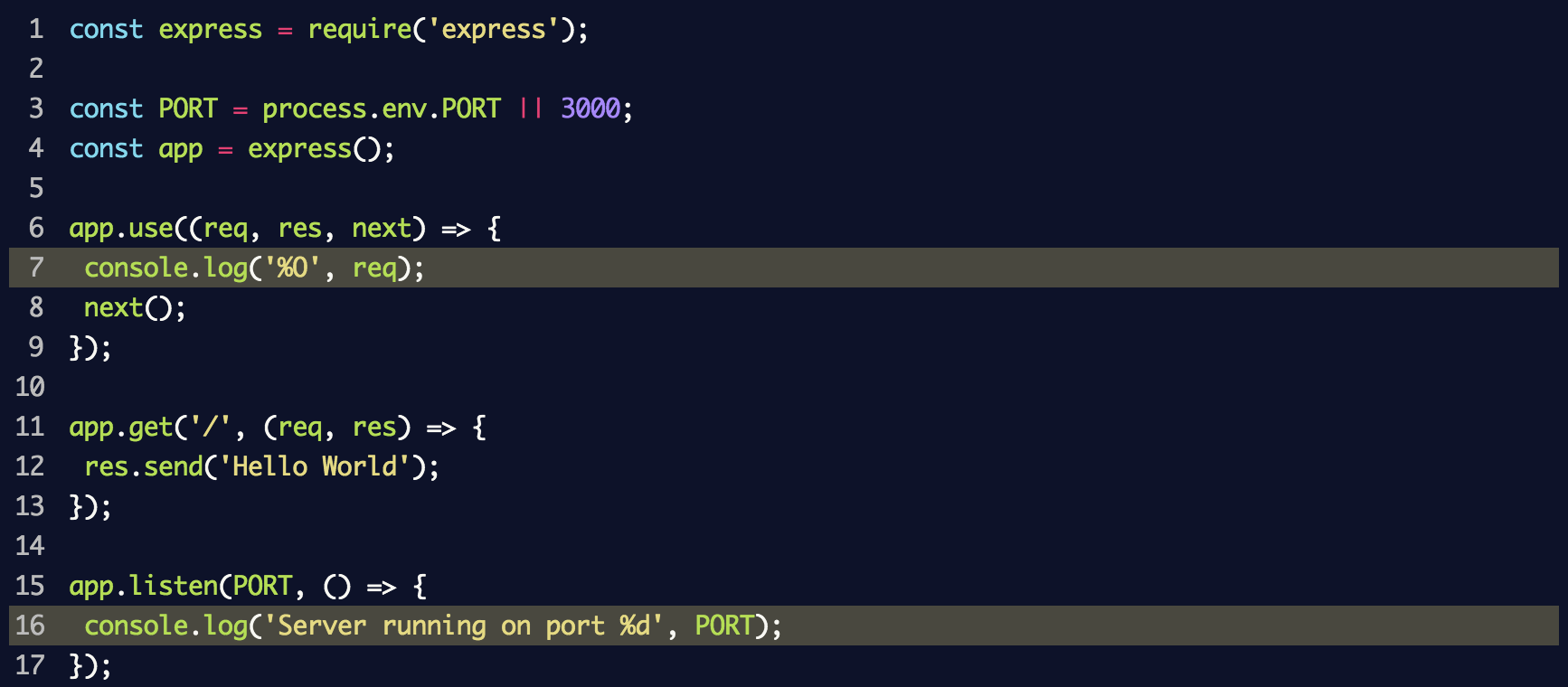
Здесь используется console.log('%O', req) для регистрации целого объекта в журнале. С точки зрения внутренней структуры метод console.log применяет util.format, который кроме %O поддерживает и другие метки-заполнители. Информацию о них можно найти в документации Node.js.
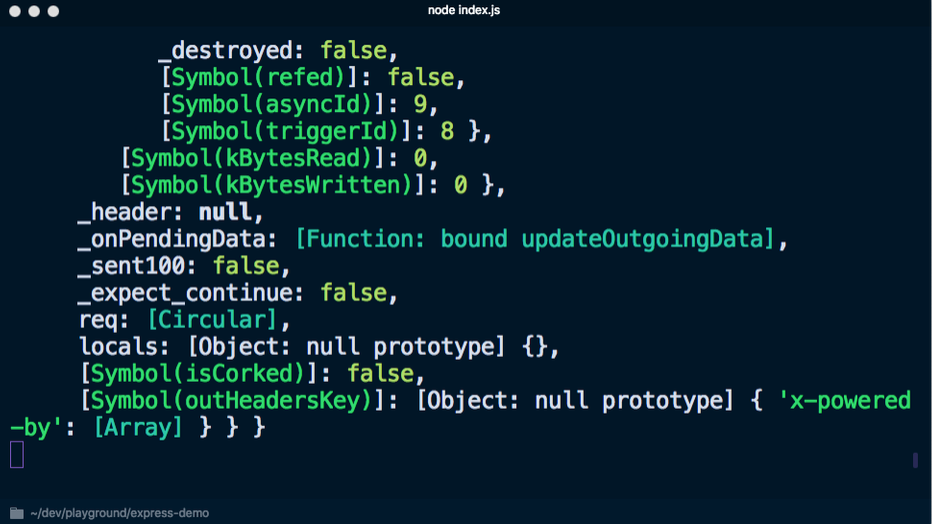
При выполнении node index.js для запуска сервера и переходе на localhost:3000 в консоли отображается много ненужной информации:
Если вместо этого использовать console.log('%s', req), чтобы не выводить объект полностью, много информации получить не удастся:
Можно написать собственную функцию логирования, которая будет выводить только нужные данные, однако сначала следует определиться, какая именно информация необходима. Несмотря на то, что в центре внимания обычно оказывается содержание сообщения, в реальности часто необходимо получить дополнительную информацию, которая включает:
- метку времени – чтобы знать, когда произошли события;
- имя компьютера/сервера – если запущена распределённая система;
- идентификатор процесса – если запущено несколько процессов Node с помощью, например,
pm2; - сообщение – фактическое сообщение с неким содержимым;
- трассировку стека – если ошибка регистрируется;
- дополнительные переменные/информацию.
Кроме того, учитывая, что в любом случае всё выводится в потоки stdout и stderr, возникает необходимость вести журнал на разных уровнях, а также конфигурировать и фильтровать записи в журнале в зависимости от уровня.
Этого можно добиться, получив доступ к разным частям процесса process и написав несколько строчек кода на JavaScript. Однако Node.js замечателен тем, что в нём уже есть экосистема npm и несколько библиотек, которые можно использовать для этих целей. К ним относятся:
Часто предпочтение отдаётся pino, потому что она быстрая и обладает собственной экосистемой. Посмотрим, как pino может помочь с ведением журнала. Ещё одно преимущество этой библиотеки – пакет express-pino-logger, который позволяет регистрировать запросы.
Установим pino и express-pino-logger:

После этого обновляем файл index.js, чтобы использовать регистратор событий и межплатформенное ПО:
В этом фрагменте создали экземпляр регистратора событий logger для pino и передали его в express-pino-logger, чтобы создать новое межплатформенное ПО для регистрации событий, с которым можно вызвать app.use. Кроме того, console.log заменили при запуске сервера на logger.info и добавили logger.debug к маршруту, чтобы отображать разные уровни журнала.
Если вы перезапустите сервер, повторно выполнив node index.js, то получите на выходе другой результат, при котором каждая строка/линия будет выводиться в формате JSON. Снова переходим на localhost:3000, чтобы увидеть ещё одну новую строку в формате JSON.
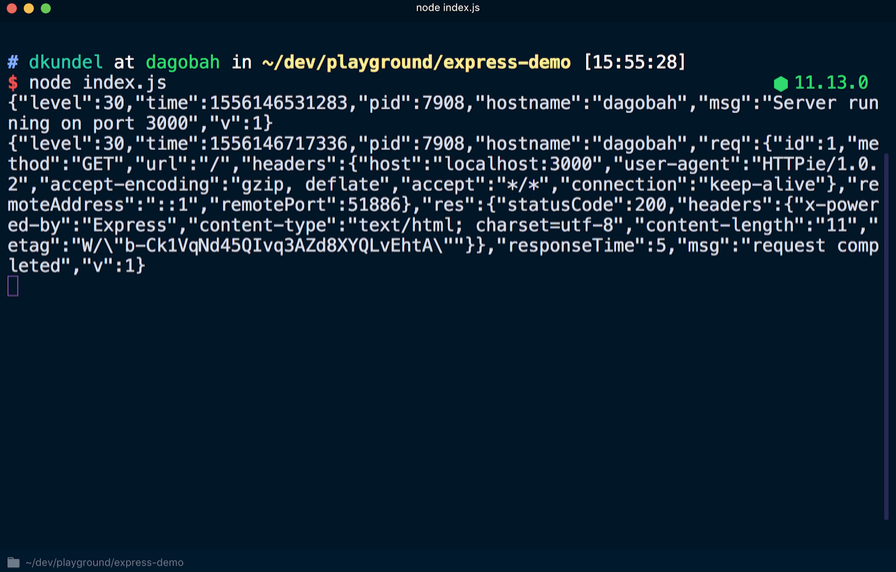
Среди данных в формате JSON можно обнаружить упомянутую ранее информацию, например метку времени. Также отмечаем, что сообщение logger.debug не было выведено. Для того чтобы сделать его видимым, необходимо изменить установленный по умолчанию уровень журнала. После создания экземпляра регистрации событий logger было установлено значение process.env.LOG_LEVEL. Это означает, что можно изменить значение или принять значение info по умолчанию. Запуская LOG_LEVEL=debug node index.js, изменяем уровень журнала.
Прежде чем это сделать, необходимо решить проблему выходного формата, который не слишком удобен для восприятия в настоящий момент. Этот шаг делается намеренно. Согласно философии pino, в целях производительности необходимо перенести обработку записей в журнале в отдельный процесс, передав выходные данные (с помощью оператора |). Процесс включает перевод выходных данных в формат, более удобный для восприятия человеком, или их загрузку в облако. Эту задачу выполняют инструменты передачи под названием transports. Ознакомьтесь с документацией по инструментам transports и вы узнаете, почему ошибки в pino не выводятся через stderr.
Чтобы просмотреть более удобную для чтения версию журнала, воспользуемся инструментом pino-pretty. Запускаем в терминале:

Все записи в журнале передаются с помощью оператора | в распоряжение pino-pretty, благодаря чему «очищаются» выходные данные, которые будут содержать только важную информацию, отображённую разными цветами. Если снова запросить localhost:3000, должно появиться сообщение об отладке debug.
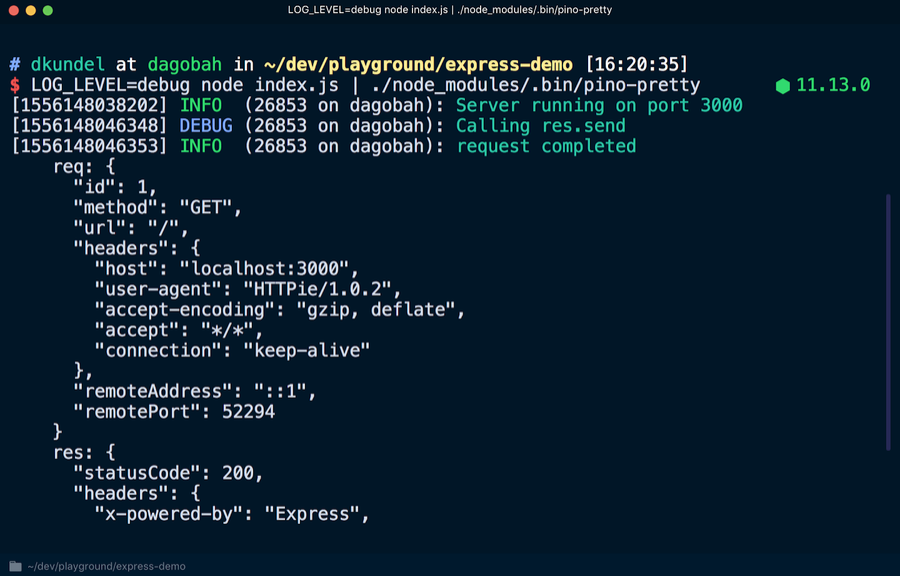
Для того чтобы сделать записи в журнале более читабельными или преобразовать их, существует множество инструментов передачи. Их даже можно отобразить с помощью эмодзи, используя pino-colada. Эти инструменты будут полезны для разработки в локальных масштабах. При работе сервера в продакшене может появиться необходимость передавать данные журнала с помощью другого инструмента, записывать их на диск с помощью > для последующей обработки или делать две операции одновременно, используя определённую команду, например tee.
В документе также говорится о ротации файлов журнала, фильтрации и записи данных журнала в другие файлы.
Ведение журналов для библиотек
Изучив способы эффективной организации ведения журналов для серверных приложений, можно использовать ту же технологию для собственных библиотек.
Проблема в том, что в случае с библиотекой может понадобиться вести журнал в целях отладки, не нагружая при этом приложения клиента. Наоборот, клиент должен иметь возможность активировать журнал, если необходимо произвести отладку. По умолчанию библиотека не должна производить записи выходных данных, предоставив это право пользователю.
Хорошим примером этого является фреймворк express. Во внутренней структуре фреймворка express происходит много процессов, что может вызвать интерес к его более глубокому изучению во время отладки приложения. В документации для фреймворка express сказано, что к началу команды можно добавить DEBUG=express:* следующим образом:

Если применить эту команду к существующему приложению, можно увидеть множество дополнительных выходных данных, которые помогут при отладке:
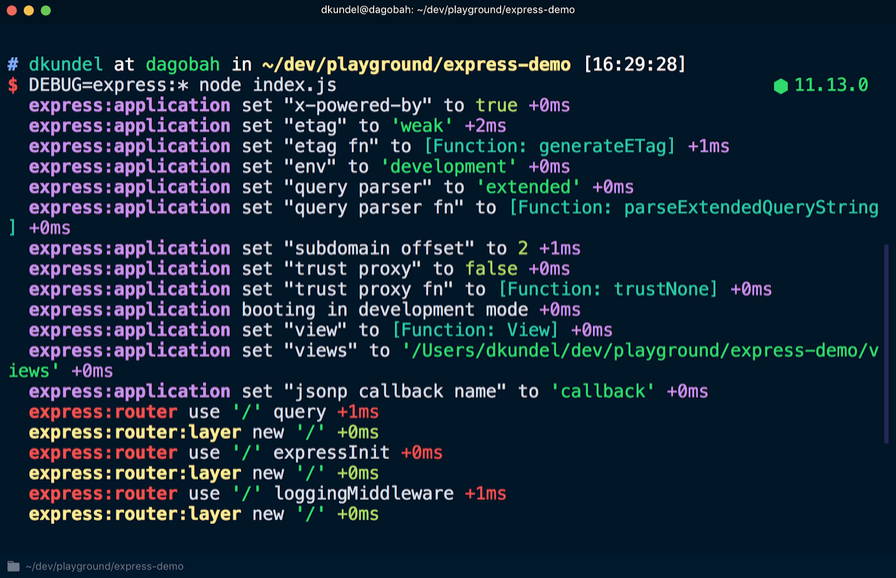
Эту информацию нельзя увидеть, если не активирован журнал отладки. Для этого существует пакет debug. С его помощью можно писать сообщения в «пространстве имён», и если пользователь библиотеки включит это пространство имён или подстановочный знак, который с ним совпадает, в их переменную среды DEBUG, то сообщения будут отображаться. Сначала нужно установить библиотеку debug:

Создайте новый файл под названием random-id.js, который будет моделировать работу библиотеки, и поместите в него следующий код:
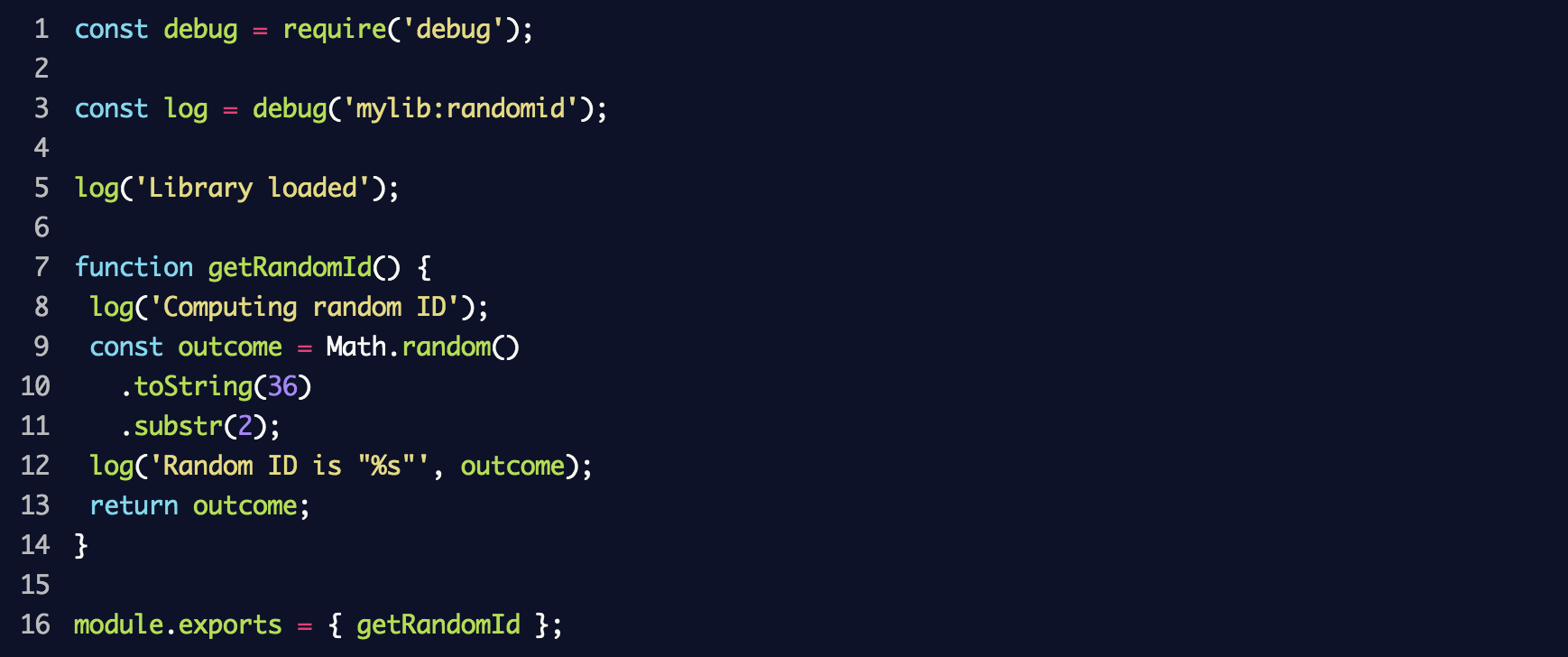
В результате будет создан новый регистратор событий debug с пространством имён mylib:randomid, в котором затем будут зарегистрированы два сообщения. Используем его в index.js из предыдущего раздела:
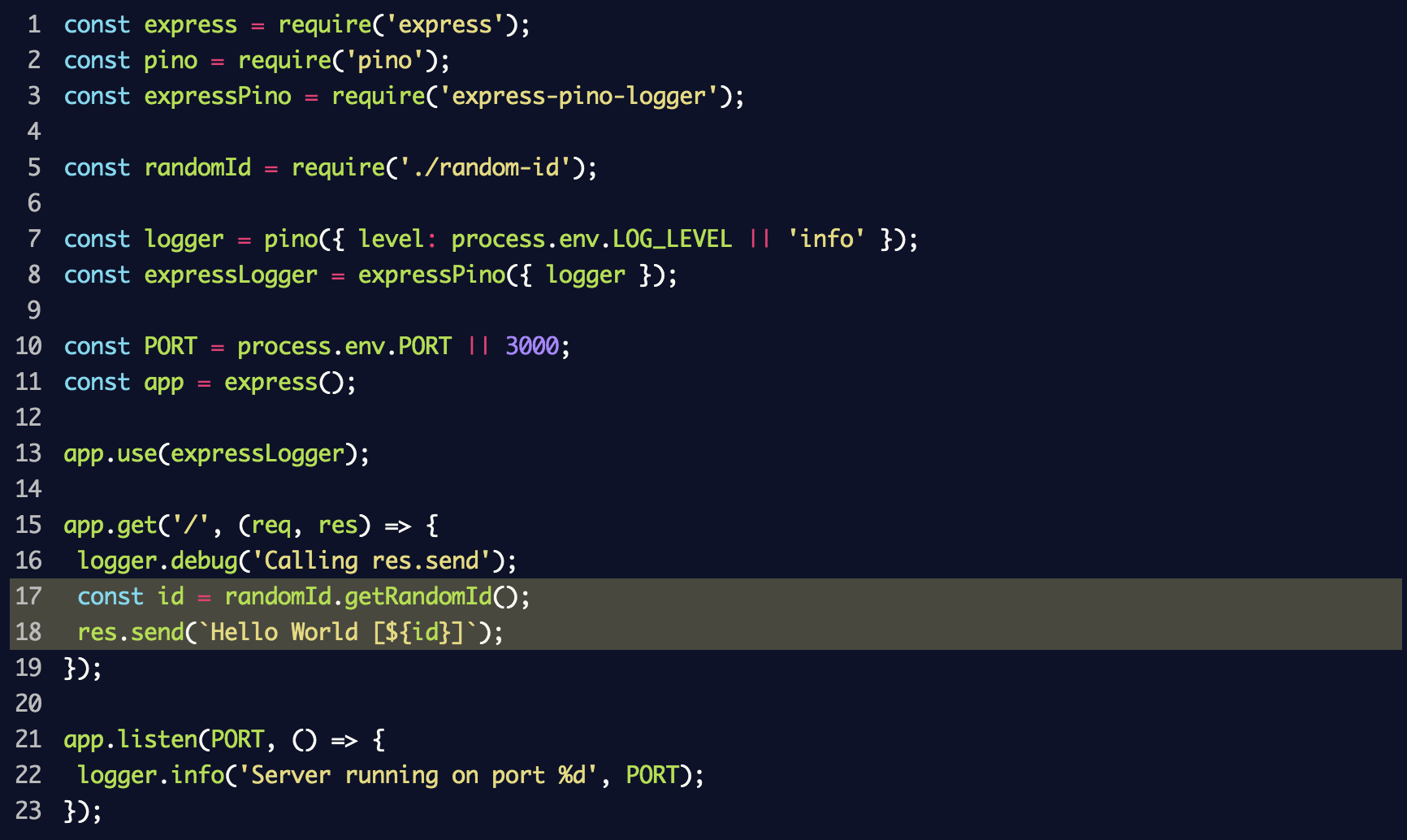
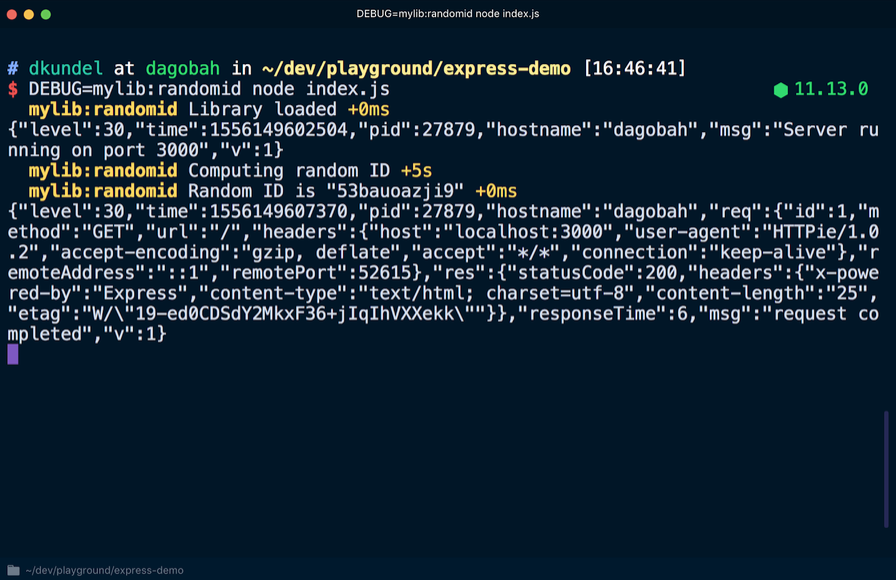
Если вновь запустить сервер, добавив в этот раз DEBUG=mylib:randomid node index.js, то отобразятся записи в журнале отладки для нашей «библиотеки»:
Если пользователи библиотеки захотят поместить информацию об отладке в записи журнала pino, они могут использовать библиотеку под названием pino-debug, созданную командой pino для корректного форматирования этих записей.
Устанавливаем библиотеку:

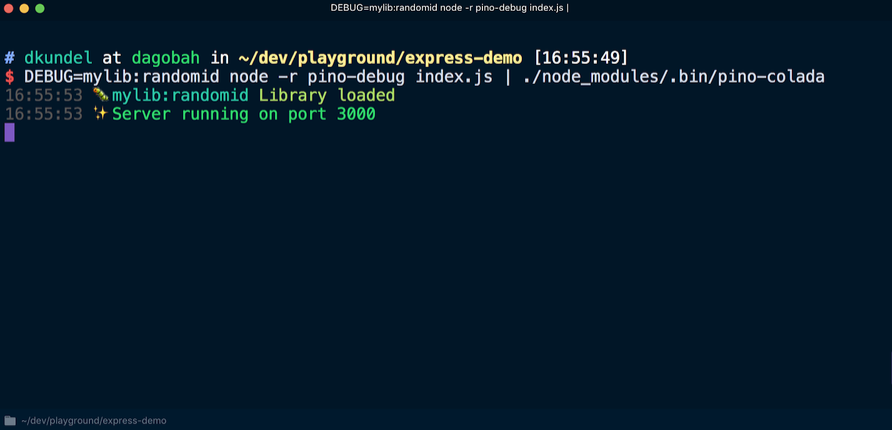
Перед первым использованием debug необходимо инициализировать pino-debug. Самый простой способ сделать это – использовать флаги -r или --require, чтобы запросить модуль перед запуском скрипта. Перезапускаем сервер, используя команду (при условии, что установлена pino-colada):

В результате записи журнала отладки библиотеки отобразятся так же, как и в журнале приложения:
Выходные данные интерфейса командной строки (CLI)
Последний случай, который рассматривается в этой статье, касается ведения журнала для интерфейса командной строки. Предпочтительно, чтобы журнал, регистрирующий события, связанные с логикой программы, вёлся отдельно от журнала для регистрации данных интерфейса командной строки. Для записи любых событий, связанных с логикой программы, нужно использовать определённую библиотеку, например debug. В этом случае можно повторно использовать логику программы, не будучи ограниченным одним сценарием использования интерфейса командной строки.
Создавая интерфейс командной строки с помощью Node.js, можно добавить различные цвета, блоки с изменяемым значением или инструменты форматирования, чтобы придать интерфейсу визуально привлекательный вид. Однако при этом нужно держать в уме несколько сценариев.
По одному из них интерфейс может использоваться в контексте системы непрерывной интеграции (CI), и в этом случае лучше отказаться от цветового форматирования и визуально перегруженного представления результатов. В некоторых системах непрерывной интеграции установлен флаг CI. Удостовериться, что вы находитесь в системе непрерывной интеграции, можно с помощью пакета is-ci, который поддерживает несколько таких систем.
Некоторые библиотеки, например chalk, определяют системы непрерывной интеграции и отменяют вывод в консоль цветного текста. Давайте посмотрим, как это работает.
Установите chalk с помощью команды npm install chalk и создайте файл под названием cli.js. Поместите в файл следующие строки:

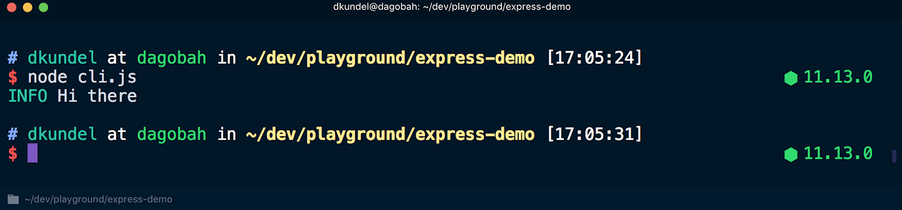
Теперь, если выполнить этот скрипт с помощью node cli.js, результаты будут представлены с использованием разных цветов:
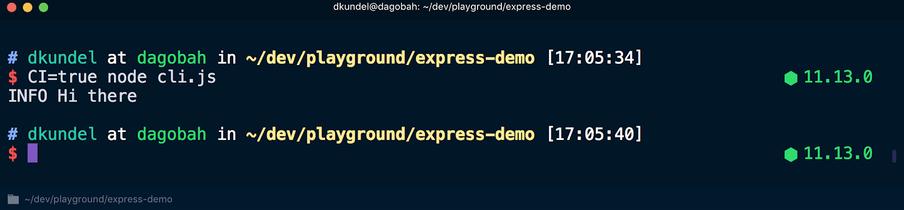
Но если выполнить скрипт с помощью CI=true node cli.js, цветовое форматирование текстов будет отменено:
В другом сценарии, о котором стоит помнить, stdout запущен в режиме терминала, т.е. данные выводятся на терминал. В этом случае результаты можно красиво отобразить с помощью boxen. В противном случае выходные данные, скорее всего, будут перенаправлены в файл или куда-то ещё.
Проверить работу потоков stdin, stdout или stderr в режиме терминала можно, посмотрев на атрибут isTTY соответствующего потока. Например, process.stdout.isTTY. TTY означает «телетайп» (teletypewriter) и в данном случае предназначен специально для терминала.
Значения могут различаться для каждого из трёх потоков в зависимости от того, как были запущены процессы Node.js. Подробную информацию об этом можно найти в документации Node.js, в разделе «Ввод/вывод процессов».
Посмотрим, как значение process.stdout.isTTY различается в разных ситуациях. Обновляем файл cli.js, чтобы проверить его:

Теперь запускаем node cli.js в терминале и видим слово true, после которого цветным шрифтом отображается сообщение:

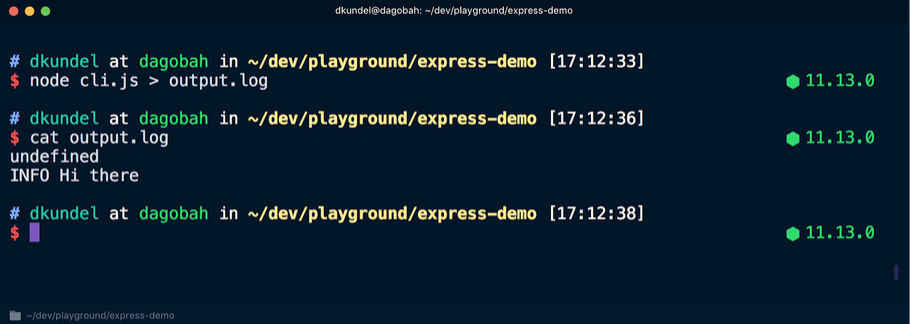
После этого повторно выполняем команду, но перенаправляем выходные данные в файл, а затем просматриваем содержимое:

В этот раз в терминале появилось слово undefined, за которым следует сообщение, отображённое бесцветным шрифтом, поскольку перенаправление потока stdout вывело его из режима терминала. Здесь chalk использует инструмент supports-color, который с точки зрения внутренней структуры проверяет isTTY соответствующего потока.
Такие инструменты, как chalk, выполняют эти действия самостоятельно. Однако, разрабатывая интерфейс командной строки, нужно всегда помнить о ситуациях, когда интерфейс работает в системе непрерывной интеграции или осуществляется перенаправление выходных данных. Эти инструменты помогают использовать интерфейс командной строки на более высоком уровне. Например, данные в терминале можно организовать более структурировано и, если isTTY имеет значение undefined, переключиться на более простой способ анализа.
Заключение
Начать использовать JavaScript и внести первую строчку в журнал консоли с помощью console.log довольно просто. Но перед тем как развернуть код в продакшене, следует учесть несколько аспектов использования журнала. Данная статья является лишь введением в различные способы и решения, применяемые при организации журнала событий. Она не содержит всего, что вам необходимо знать. Поэтому рекомендуется обращать внимание на удачные проекты с открытым кодом и отслеживать, каким образом в них решена проблема логирования и какие инструменты используются при этом. А теперь попробуйте сами вести логи без вывода данных в консоль.

Если вы знаете другие инструменты, о которых стоит упомянуть, напишите о них в комментариях.
ссылка на оригинал статьи https://habr.com/ru/company/funcorp/blog/461881/
Добавить комментарий