Последний учебный год, апрель месяц. Студента все чаще и чаще начинают посещать мысли о том, что надо бы заняться дипломной работой. Заняться — в смысле придумать, как быстро состряпать нечто, что будет хотя бы созвучно той теме, которую, вроде как, утверждали с научным руководителем. А, да, надо хотя бы на 80 страниц, еще и соблюсти ГОСТы там всякие… Понятное дело, самому столько связного текста уже не успеть набрать (да еще и могут начать в суть работы вникать, ну его!). Очевидно — надо брать готовую работу, которую уже защитили, работу качественную, проверенную и одобренную. Знакомая всем нам ситуация. Открытым остается единственный вопрос — как сделать так, чтобы работа прошла проверку на заимствования… Поиск в интернете и общение с коллегами по несчастью приводят студента к следующим вариантам решения проблемы:
Написать работу самому;- Перефразировать текст (дорого и сложно);
- Обхитрить систему с помощью «технических обходов».

Давайте посмотрим, какими бывают технические обходы, как мы их отлавливаем и почему их применение — не самая хорошая идея…
Перефразирование может помочь выдать чужой текст за собственный, если оно выполнено качественно. Однако, качественное перефразирование само по себе является очень трудозатратным процессом, на который у студента, скорее всего, нет времени и средств. Простые же способы перефразирования (например, синонимизация) дадут результат, который не только обнаружится системой «Антиплагиат», но и, вполне вероятно, развеселит научного руководителя и аттестационную комиссию.
Таким образом, мы подходим к самому творческому и самому популярному среди студентов средству — техническим обходам — преобразованиям документа, которые, не меняя отображения исходного документа, изменяют текст, извлекаемый проверяющей системой.
C точки зрения работы с техническими обходами (далее будем называть их просто «обходами») перед системой «Антиплагиат» стоят две задачи:
- Обнаружение потенциальных обходов и уведомление пользователя о них;
- Очистка проверяемого текста от обходов.
Общую схему обработки обходов можно описать следующим образом:
- Обнаружение обходов, сохранение информации о них;
- Очистка извлеченного текста от обходов;
- Определение «подозрительности» документа на основании найденных обходов;
- Отображение информации о подозрительности пользователю, отображение найденных обходов.
Вот как это выглядит на практике.
Документ в формате docx:
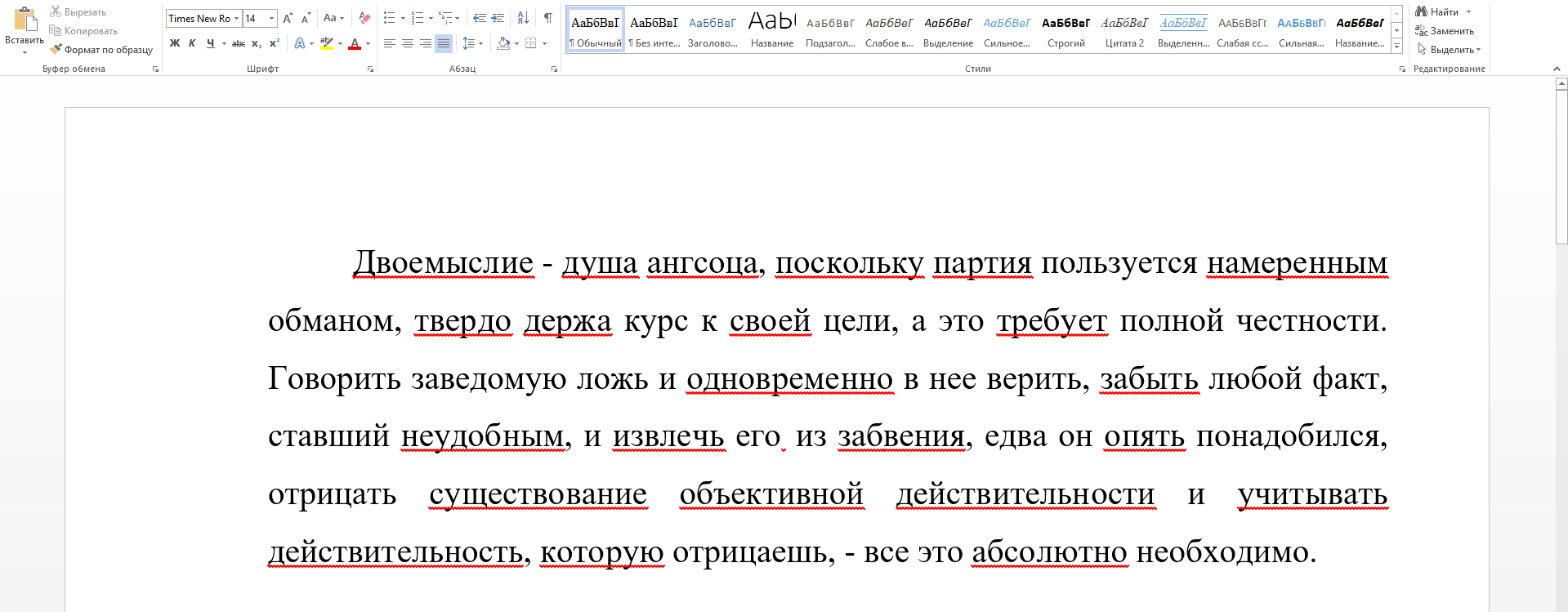
Проверяем документ без функционала обнаружения обходов:
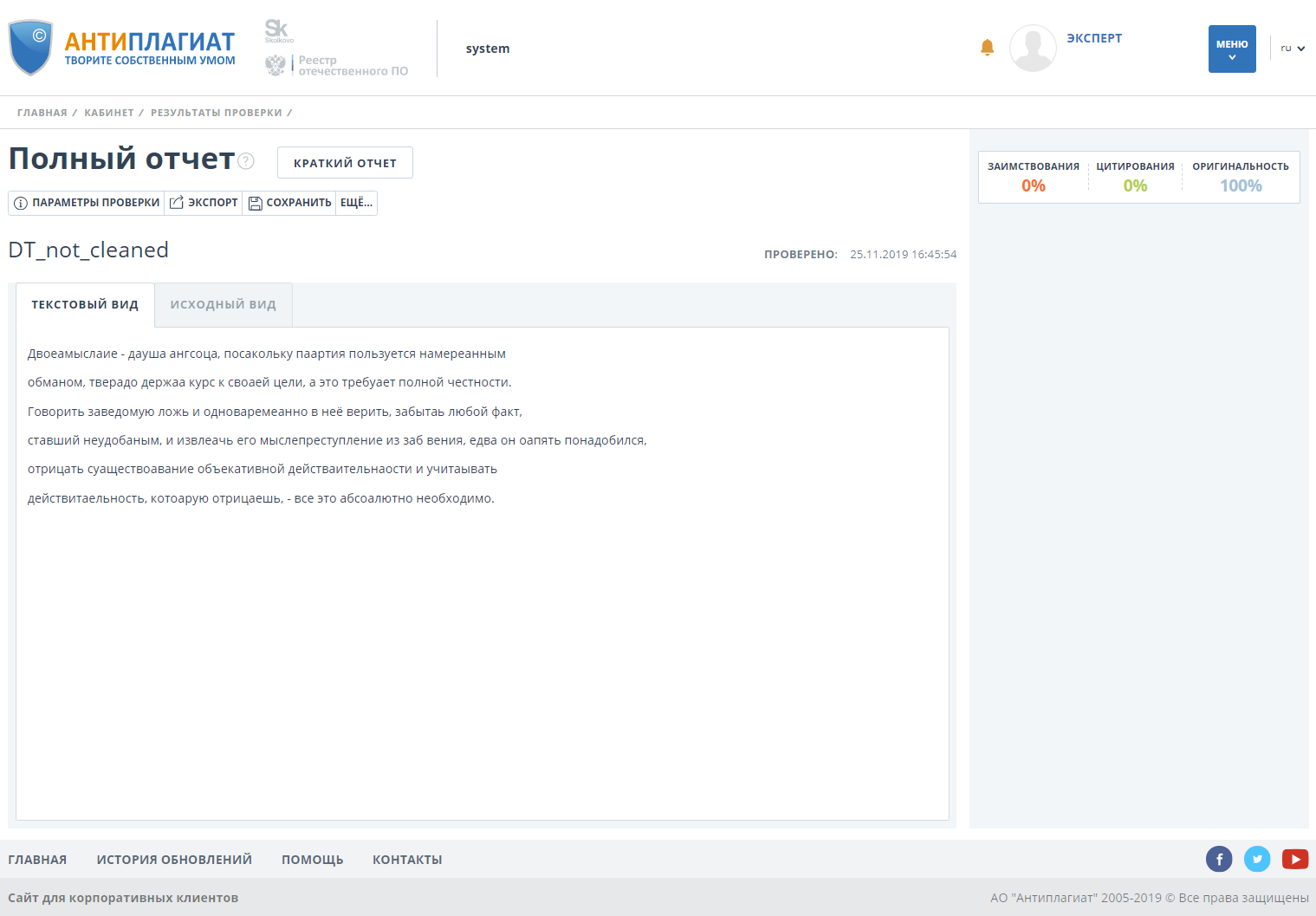
Документ имеет стопроцентную оригинальность.
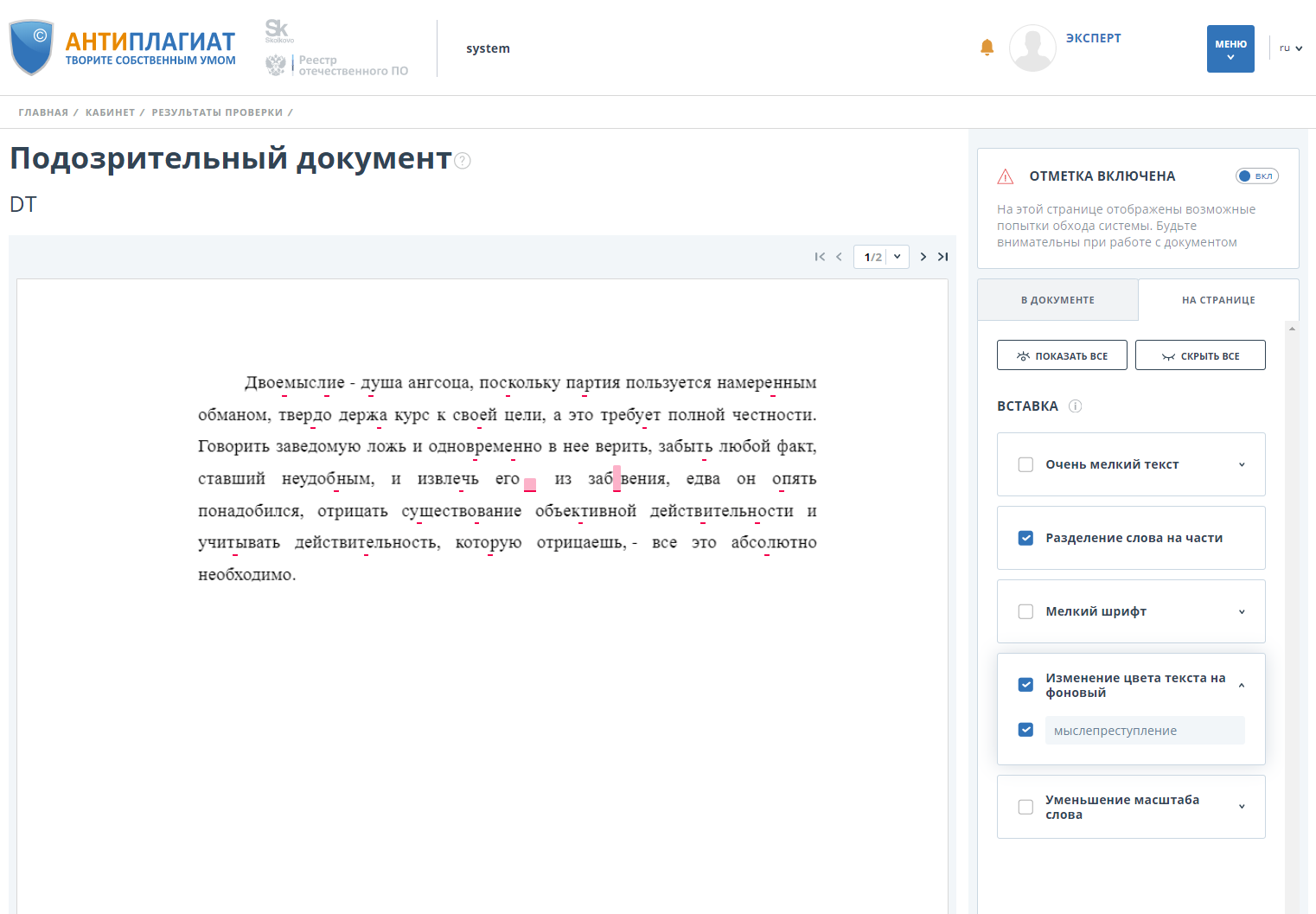
Проверяем документ с включенным функционалом обнаружения обходов и видим, что оригинальность падает до 0.

Кроме того, система помечает документ как «Подозрительный» и показывает пользователю, где и какие именно обходы были обнаружены:
Поскольку целью технических обходов является повышение оригинальности документа, интересно классифицировать их по тому, каким образом они влияют на проверку документа. Исходя из того, что основным элементом проверки документа на заимствования являются слова документа, обходы можно разделить на следующие типы по их влиянию на извлекаемые слова документа:
- Изменение слова (слово в извлеченном тексте отличается от слова, отображаемого в исходном документе);
- Добавление слова (слово не видимо в исходном документе, появляется в извлекаемом тексте документа);
- Удаление слова (слово видимо в исходном документе, отсутствует в извлекаемом тексте документа);
- Разбиение слова (в исходном документе слово отображается нормально, в излеченном тексте оно разбито на две или более части);
- Слияние слов (в исходном документе отображается несколько слов, в извлеченном тексте они слиты в одно слово).
Давайте посмотрим, с какими обходами мы сталкиваемся. Начнем от простых и пойдем в сторону наиболее интересных.
Текстовые обходы
Обходы данного типа никак не привязаны к формату документа, они меняют строковое значение слов таким образом, что те продолжают выглядеть идентично исходным словам.
Омоглифы
Одним из первых зафиксированных нами способов обхода является замена букв на омоглифы — на визуально схожие с исходными буквами символы, имеющими иное значение. Омоглифия применялась с самых ранних дней существования системы «Антиплагиат», и, несмотря на то, что она нами давно уже отлавливается, мы все еще встречаем подобные обходы в студенческих работах.
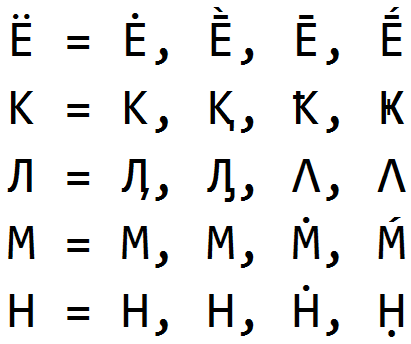
Омоглифы легко находить и очищать, когда известен язык каждого слова. Мы умеем достаточно качественно определять язык каждого слова текста, даже когда текст содержит несколько языков и большое количество «мусора» (омоглифов и прочих лишних символов). Как — это тема для отдельной статьи. Имея язык слова и список возможных омоглифов для языка, мы восстанавливаем буквы исходного языка и сохраняем информацию о найденных омоглифах.
Непечатные символы
Другим способом изменения строкового значения слов без существенного изменения их отображения является использование невидимых либо слабо видимых Unicode символов. Вставка таких символов в слово меняет строковое значение слова, при этом практически не меняя его отображение.
Много подобных символов находятся в Unicode категориях «Other, Control» и «Mark, Nonspacing».
Данные символы система просто удаляет и, при их большом количестве, оповещает пользователя о подозрительности документа, отображая очищенные непечатные символы в отчете.
Обходы в pdf
Как мы уже рассказывали ранее, ключевым форматом при обработке документов у нас является pdf. Все остальные типы документов мы конвертируем в pdf, благодаря чему основная логика обработки документов у нас становится унифицирована для всех поддерживаемых форматов. Таким образом, обходы, которые можно реализовать в pdf документах, для нас представляют особый интерес.
Мелкий текст
Способ обхода, который одним из первых приходит на ум — сделать что-то маленьким и невидимым. Полученный таким образом текст не виден при просмотре оригинального документа, однако извлекается системой. Реализация очень проста — выставить у текста минимальный размер шрифта, изменить цвет текста. Настолько же прост отлов обходов данного типа — просто проверяем размер шрифта текста и геометрические размеры отдельных слов. За счет маленьких размеров студенты часто добавляют целые абзацы такого скрытого текста на страницу:

Отображение обнаруженной попытки обхода:

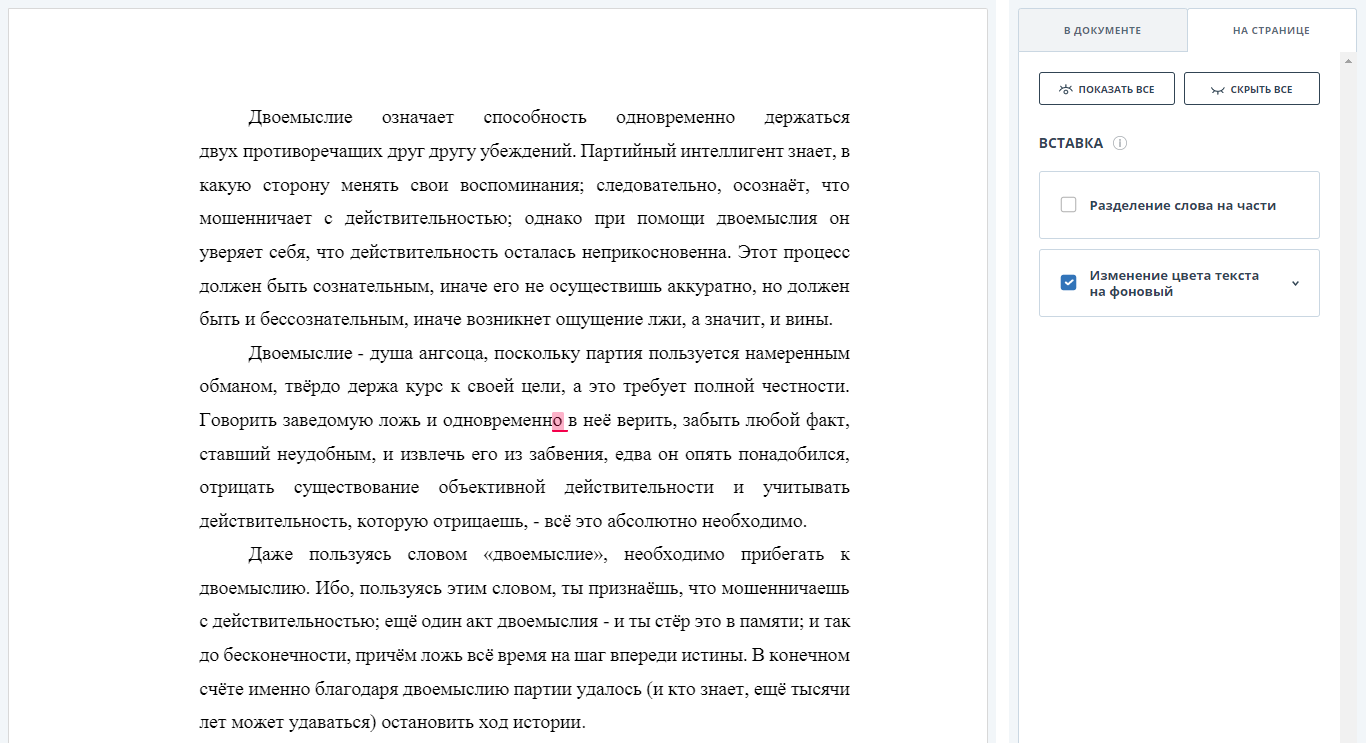
Изменение цвета текста на фоновый
Несмотря на то, что данный способ часто применяется в комбинации с предыдущим, более интересно его независимое использование. Дело в том, что нам для обнаружения и очистки обхода достаточно определения того, что хотя бы один параметр слова/символа имеет «подозрительное» значение. И, если определение маленьких размеров слова тривиально, то определение текста, цвет которого совпадает с фоновым, является более сложной процедурой.
Обнаружения невидимого текста осложнено следующими обстоятельствами:
- Из pdf не всегда возможно получить цвет конкретного символа;
- Фон слова может быть не белым. Более того, слово может находиться на фоне изображения;
- Слова и символы могут наезжать друг на друга.
Для устранения первых двух сложностей «невидимость» текста мы определяем посредством анализа отрендеренного изображения страницы документа:
- Определяем область страницы, содержащую слово;
- Вычисляем дисперсию полученной области. Если дисперсия ниже определенного порога — в анализируемой области имеем однородный цвет, никаких букв не видно. Следовательно, на лицо попытка обхода системы.
Слова и символы, спрятанные друг за другом
Невидимые символы невозможно обнаружить посредством анализа области, в которой они находятся, если эти символы скрыты за другими «видимыми» символами. Поэтому, для обнаружения подобных «спрятанных» символов у нас существует отдельная процедура, анализирующая пересечение областей символов и помечающая те символы, которые в значительной степени перекрываются другими.

Обнаруженный обход:
Текст в виде изображений
Что будет, если взять и заменить часть текста изображениями, содержащими этот текст? При должной аккуратности внешне все будет выглядеть так, будто ничего в документе не изменилось, однако при извлечении текстового слоя, естественно, слова с картинок не извлекутся. Для закрытия данной бреши мы применяем оптическое распознавание текста.
Обходы, использующие особенности конвертации docx в pdf
Конвертация документов в pdf — нетривиальная задача. О том, как мы выбирали наиболее подходящее нам решение, можно почитать тут (https://habr.com/ru/company/antiplagiat/blog/458842/). К сожалению, даже наилучший из проанализированных нами вариантов не идеально конвертирует документы в pdf. Некоторые «особенности» конвертации активно используются при попытках обхода системы.
Формулы
Формулы и ряд других объектов, содержащих текст, «теряются» после конвертации в pdf. Таким образом можно попытаться скрыть целый абзац текста, или, например, каждое второе слово в тексте:

При конвертации в pdf получаем следующий результат:

Для обнаружения и очистки этого и других обходов, заточенных на особенности конвертации docx в pdf, мы анализируем и вычищаем исходный docx файл. В частности, при обнаружении существенного количества формул в документе мы их заменяем на простой текст, который сохранится при конвертации документа в pdf. Более того, мы запоминаем позиции формул, которые мы обработали, и при необходимости сообщаем пользователю о подозрительности проверяемого документа и подсвечиваем текст, который мы восстановили из формул.
Масштаб, маленькое межсимвольное/междустрочное расстояние
При конвертации в pdf не учитывается ряд свойств текста: масштаб, межсимвольное и междустрочное расстояния. Это позволяет добавлять невидимый в исходном документе текст (например, у него выставляется очень маленький масштаб), который в pdf становится нормальным, ничем не выделяющимся текстом. Реализация обхода (docx):

Результат конвертации в pdf (цвет мы меняли сами):

Единственная возможность отловить данный текст — найти его в docx и сохранить информацию о нем. Если мы обнаружили много такого текста в документе — помечаем документ подозрительным и показываем пользователю, где мы нашли в документе текст с подозрительными атрибутами.
Разбиение слова на части
Интересный частный случай применения свойств, описанных в предыдущем пункте — добавить в слово пробел и скрыть его. В исходном документе слово будет выглядеть нормальным, слитным, а после конвертации документа в pdf разобьется на две части, так как пробел станет полноразмерным. Отлавливаем подобный финт ушами примерно так же, как и в предыдущем пункте. Реализация обхода (docx):

Результат конвертации в pdf:

Отображение обнаруженного обхода:

Под старым каштаном, при свете дня, я предал тебя, а ты меня…
Мы рассказали об основных, но далеко не обо всех технических способах реализации обходов. Конечно, нам вряд ли когда-либо удастся сделать защиту абсолютной. Тем не менее, мы постоянно совершенствуем нашу систему, оставляя все меньше и меньше возможностей ее «обмануть». В сессию мы стараемся закрывать обнаруживаемые лазейки особенно оперативно — часто с момента обнаружения бреши до ее закрытия на проде проходит всего несколько дней. Именно поэтому немного смешно и, одновременно, грустно читать рекламные «обещания» компаний, готовых помочь студентам поднять оригинальность их работ и дающих гарантию на свою работу, порой достигающую 30 дней. Студент, тебя предадут! В лучшем случае эта «гарантия» может вернуть тебе стоимость услуг компании-обходчика, но она никак не поможет с проваленным дипломом и потенциальным отчислением из вуза…
Творите собственным умом!
ссылка на оригинал статьи https://habr.com/ru/company/antiplagiat/blog/480580/
Добавить комментарий