
Всем привет, меня зовут Игорь Сидоренко. Одной из основных сфер моей работы, а также моим хобби является мониторинг. Я расскажу о Zabbix и о том, как с его помощью замониторить необходимую нам информацию о томах NetApp, имея доступ только по SSH. Кому интересна тема мониторинга и Zabbix, прошу под кат.
Изначально мы мониторили тома, монтируя их к определенному серверу, на котором висел специальный шаблон, отлавливающий NFS-маунты на ноде и ставящий их на мониторинг, по аналогии с файловыми системами базового шаблона Linux. Маунт надо было прописать в fstab и примонтировать вручную — из-за этого многое терялось и забывалось.
Потом мне пришла в голову прекрасная идея: надо всё это автоматизировать. Было несколько вариантов:
Есть готовые шаблоны, работающие с SNMP, но доступов нет.Получение списка томов и автоматический маунт на ноде: надо создавать папку, прописывать fstab, маунтить вот это всё, слишком много геморроя.Есть же великолепный API, но в нашей версии ONTAP он урезан и не дает пользователю нужную информацию.- Как-то использовать доступ по SSH для получения томов и постановки их на мониторинг.
Выбор пал на SSH-агент.
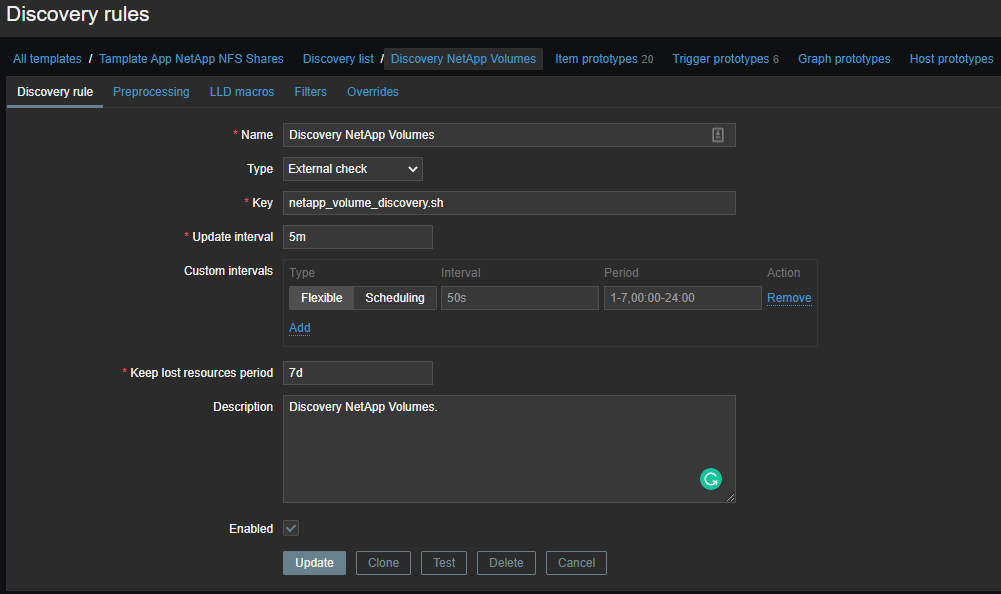
Низкоуровневое обнаружение (LLD)
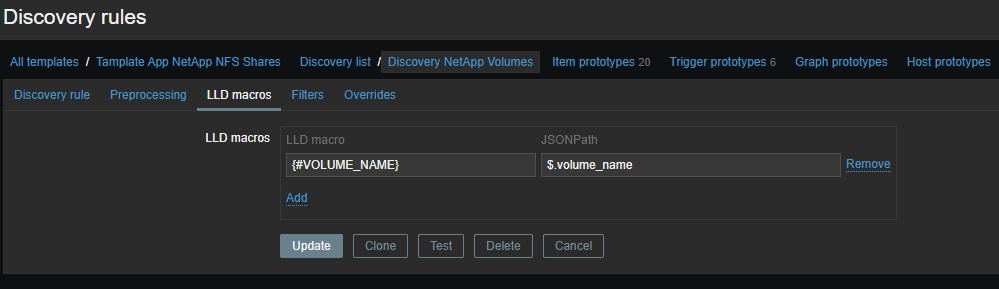
Для начала нам необходимо создать низкоуровневое обнаружение (LLD), это будут названия наших томов. Всё это необходимо для того, чтобы вытащить конкретную информацию по нужному нам тому. Сырые данные выглядят примерно так (на момент написания их 114):
set -unit B; volume show -state online 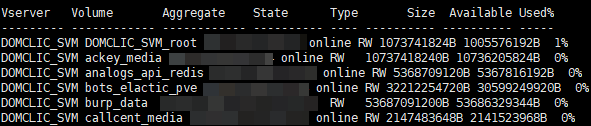
Ну как же без костылей: напишем однострочный bash-скрипт, который будет выводить названия томов в формате JSON (поскольку это внешняя проверка, cкрипты лежат на Zabbix-сервере в директории /usr/lib/zabbix/externalscripts):
#!/usr/bin/bash SVM_NAME="" SVM_ADDRESS="" USERNAME="" PASSWORD="" for i in $(sshpass -p $PASSWORD ssh -o StrictHostKeyChecking=no $USERNAME@$SVM_ADDRESS 'set -unit B; volume show -state online' | grep $SVM_NAME | awk {'print $2'}); do echo '{"volume_name":"'$i'"}'; done | jq -s '.

Теперь необходимо создать шаблон и на основе полученных данных создавать элементы данных:
Элементы данных
Для автоматического создания элементов данных необходимо сделать прототип элементов данных:
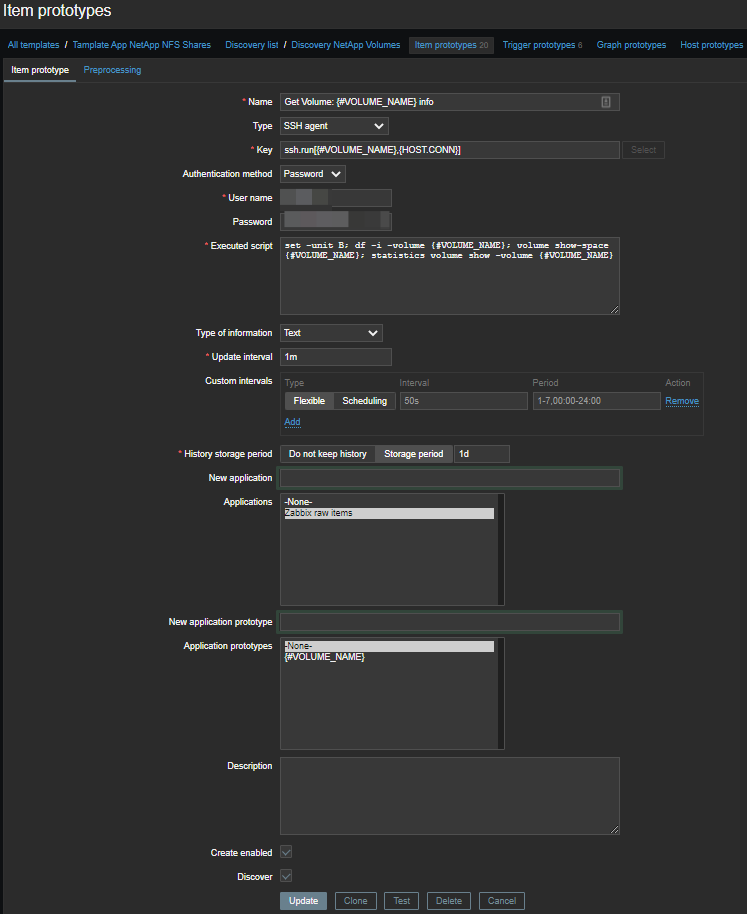
Мы будем использовать мастер-элементы и несколько зависимых от них элементов. Таким образом, для каждого тома создается один мастер-элемент, в котором выполняется набор команд по SSH:
set -unit B; df -i -volume {#VOLUME_NAME}; volume show-space {#VOLUME_NAME}; statistics volume show -volume {#VOLUME_NAME}Получаем вот такую простыню:
Last login time: 9/15/2020 12:42:45 Filesystem iused ifree %iused Mounted on /vol/ackey_media/ 96 311191 0% /ackey_media Volume Name: ackey_media Volume MSID: 2159592810 Volume DSID: 1317 Vserver UUID: 46a00e5d-c22d-11e8-b6ed-00a098d48e6d Aggregate Name: NGHF_FAS2720_04 Aggregate UUID: 7ec21b4d-b4db-4f84-85e2-130750f9f8c3 Hostname: FAS2720_04 User Data: 20480B User Data Percent: 0% Deduplication: - Deduplication Percent: - Temporary Deduplication: - Temporary Deduplication Percent: - Filesystem Metadata: 1150976B Filesystem Metadata Percent: 0% SnapMirror Metadata: - SnapMirror Metadata Percent: - Tape Backup Metadata: - Tape Backup Metadata Percent: - Quota Metadata: - Quota Metadata Percent: - Inodes: 12288B Inodes Percent: 0% Inodes Upgrade: - Inodes Upgrade Percent: - Snapshot Reserve: - Snapshot Reserve Percent: - Snapshot Reserve Unusable: - Snapshot Reserve Unusable Percent: - Snapshot Spill: - Snapshot Spill Percent: - Performance Metadata: 28672B Performance Metadata Percent: 0% Total Used: 1212416B Total Used Percent: 0% Total Physical Used Size: 1212416B Physical Used Percentage: 0% Logical Used Size: 1212416B Logical Used Percent: 0% Logical Available: 10736205824B DOMCLIC_SVM : 9/15/2020 12:42:51 *Total Read Write Other Read Write Latency Volume Vserver Ops Ops Ops Ops (Bps) (Bps) (us) ----------- ----------- ------ ---- ----- ----- ----- ----- ------- ackey_media DOMCLIC_SVM 0 0 0 0 0 0 0
Из этой простыни необходимо отобрать нужные нам метрики.
Магия регулярных выражений
Изначально для препроцессинга я хотел использовать JavaScript, но как-то не осилил, не зашло. Поэтому остановился на регулярках, да и использую их практически везде.
Количество используемых инод
Отберем информацию только о инодах по каждому тому в два этапа:
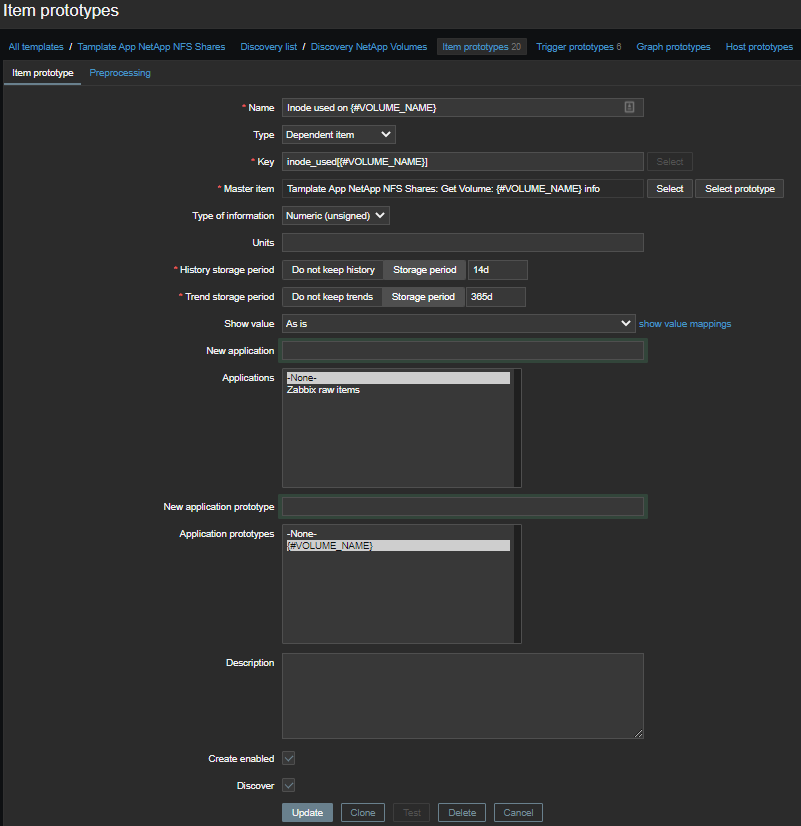
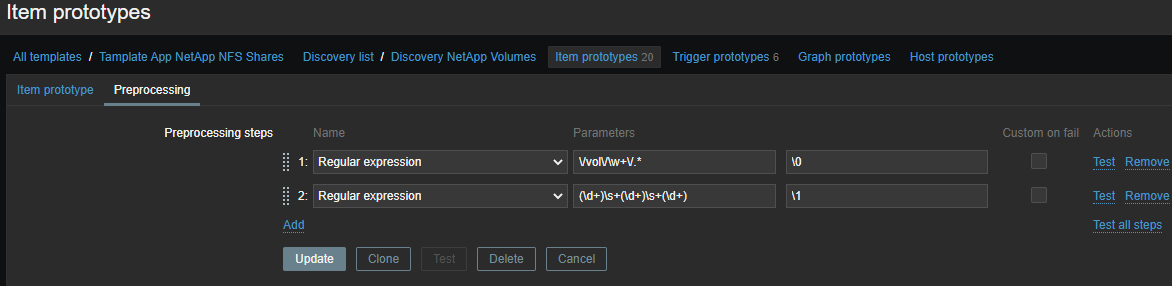
Сначала вся информация:
\/vol\/\w+\/.* 

Потом конкретно по метрикам:
(\d+)\s+(\d+)\s+(\d+) 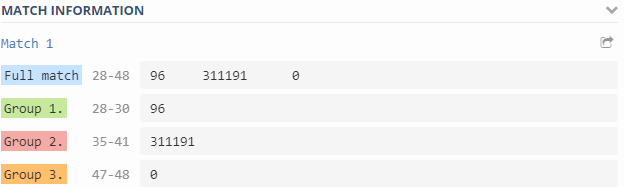

Вывод — шаблон форматирования вывода. \N (где N=1..9) — управляющая последовательность заменяется N-ной совпадающей группой. Управляющая последовательность \0 заменяется совпадающим текстом:
\1 - Inode used on {#VOLUME_NAME}— количество использованных инод;\2 - Inode free on {#VOLUME_NAME}— количество свободных инод;\3 - Inode used percentage on {#VOLUME_NAME}— использованные иноды в процентах;Inode total on {#VOLUME_NAME}— вычислямый элемент, количество доступных инод.
last(inode_free[{#VOLUME_NAME}])+last(inode_used[{#VOLUME_NAME}])
Количество используемого места
Здесь всё проще, данные и регулярки в более приятном формате:
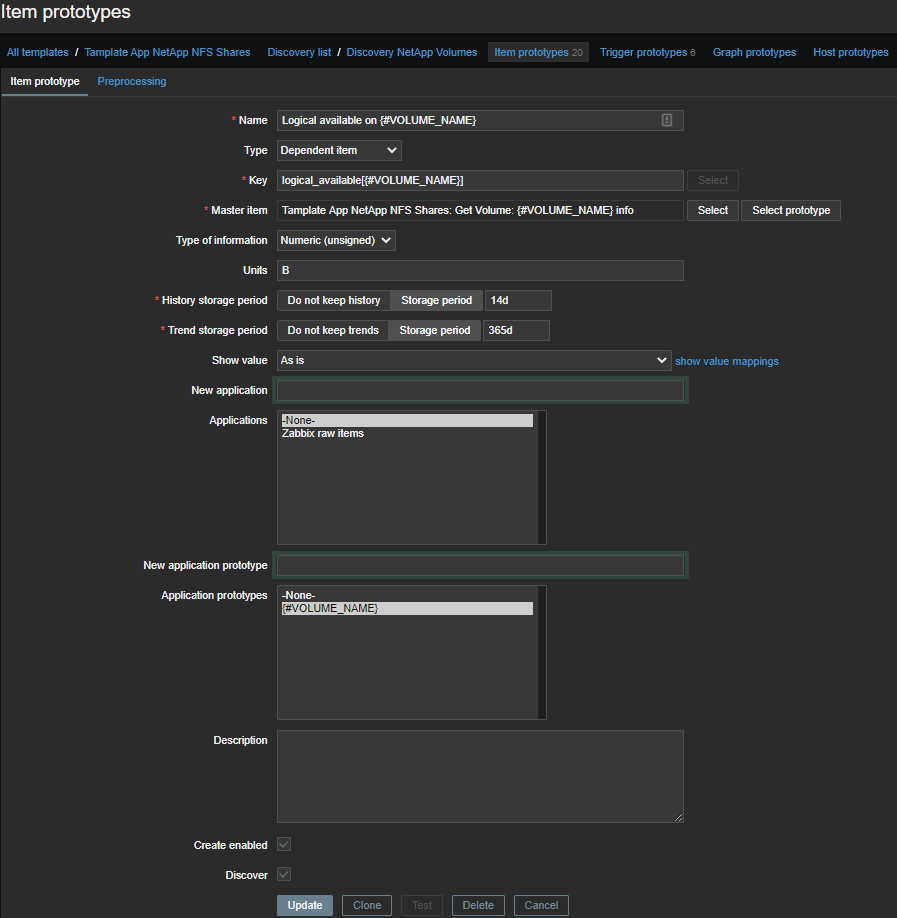
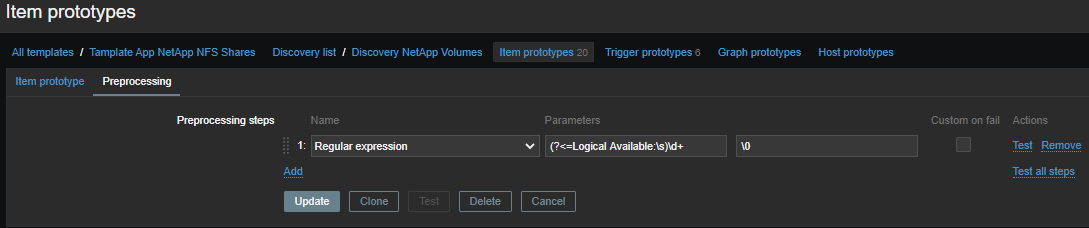
Выдергиваем нужную нам метрику и берем только число:
(?<=Logical Available:\s)\d+ 

Собираемые метрики:
Logical available on {#VOLUME_NAME}— количество доступного логического места;Logical used percent on {#VOLUME_NAME}— использованное логическое место в процентах;Logical used size on {#VOLUME_NAME}— количество использованного логического места;Physical used percentage on {#VOLUME_NAME}— использованное физическое место в процентах;Total physical used size on {#VOLUME_NAME}— количество использованного физического места;Total used on {#VOLUME_NAME}— всего использовано места;Total used percent on {#VOLUME_NAME}— всего использовано места в процентах;Logical size on {#VOLUME_NAME}— вычисляемый элемент, количество доступного логического места.
last(logical_available[{#VOLUME_NAME}])+last(total_used[{#VOLUME_NAME}])
Производительность томов
Почитав документацию и потыкав разные команды, я выяснил, что мы можем получать метрики по производительности наших томов. За это отвечает маленький кусочек:
statistics volume show -volume {#VOLUME_NAME} 
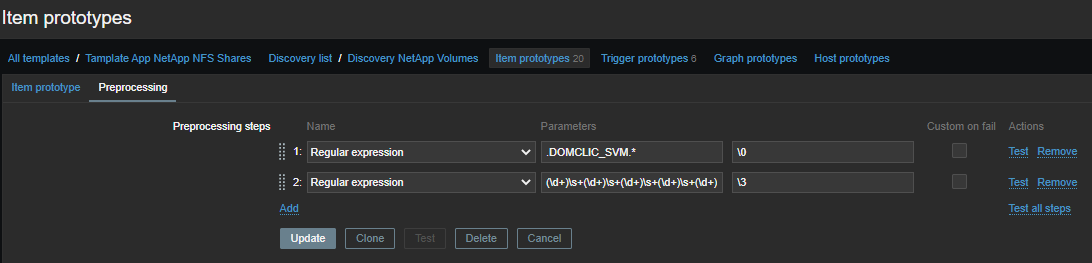
Из общей простыни первой регуляркой мы отбираем метрики по производительности:
.DOMCLIC_SVM.* 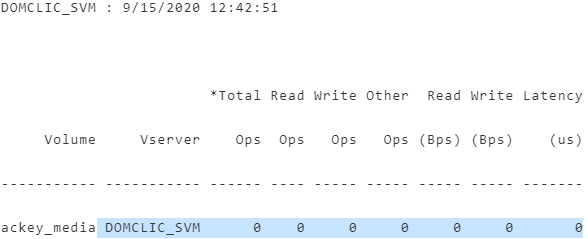

Второй группируем числа:
(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+) 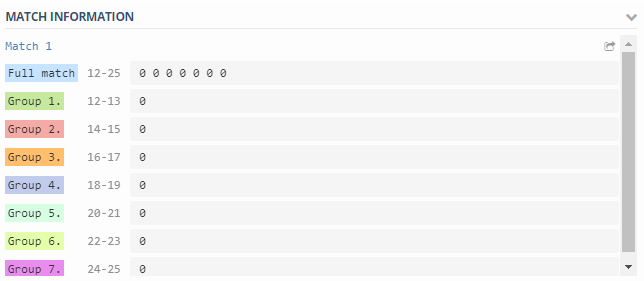
Где:
\1 - Total number of operations per second on {#VOLUME_NAME}— общее количество операций в секунду;\2 - Read operations per second on {#VOLUME_NAME}— операций чтения в секунду;\3 - Write operations per second on {#VOLUME_NAME}— операций записи в секунду;\4 - Other operations per second on {#VOLUME_NAME}— другие операции в секунду (не знаю, что это, но зачем-то снимаю);\5 - Read throughput in bytes per second on {#VOLUME_NAME}— скорость чтения в байтах в секунду;\6 - Write throughput in bytes per second on {#VOLUME_NAME}— скорость записи в байтах в секунду;\7 - Average latency for an operation in microseconds on {#VOLUME_NAME}— средняя задержка операций в микросекундах.
Алертинг
Набор триггеров стандартный, место и иноды:
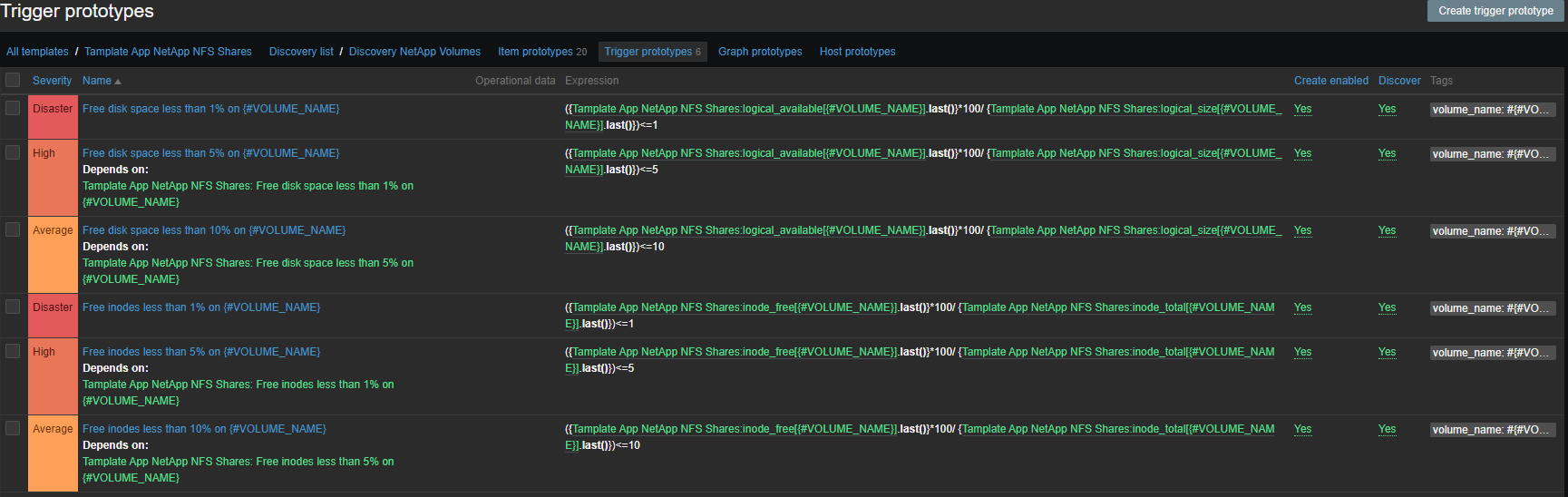
- Free disk space less than 1% on {#VOLUME_NAME}
- Free disk space less than 5% on {#VOLUME_NAME}
- Free disk space less than 10% on {#VOLUME_NAME}
- Free inodes less than 1% on {#VOLUME_NAME}
- Free inodes less than 5% on {#VOLUME_NAME}
- Free inodes less than 10% on {#VOLUME_NAME}
Визуализация
Визуализация приходится, в основном, на Grafana, это красиво и удобно. На примере одного тома выглядит примерно так:
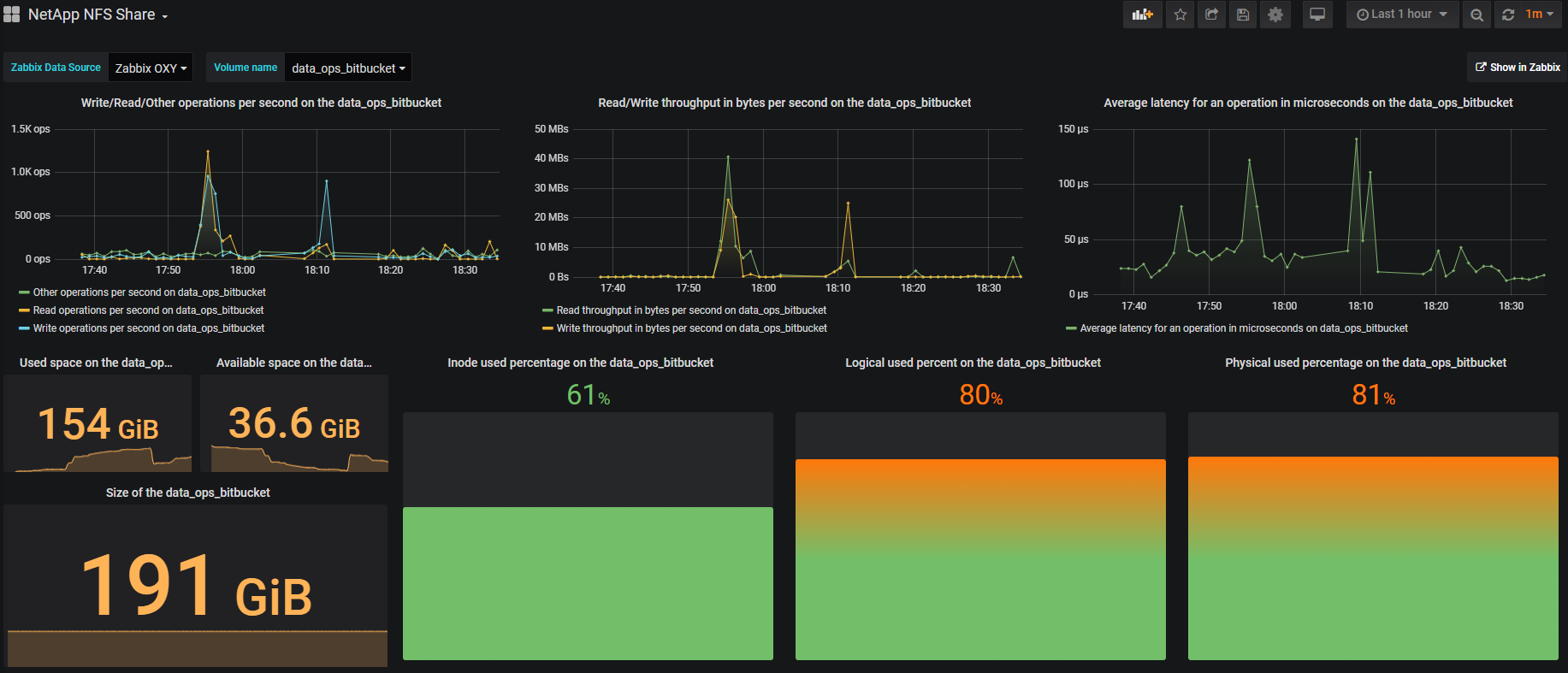
В правом верхнем углу есть кнопка Show in Zabbix, с помощью которой можно провалиться в Zabbix и увидеть все метрики по выбранному тому.
Итоги
- Автоматическая постановка томов на мониторинг.
- Автоматическое удаление томов из мониторинга, в случае удаление тома с NetApp.
- Избавились от привязки к одному серверу и ручному монтированию томов.
- Добавились метрики производительности по каждому тому. Теперь мы реже дергаем поддержку датацентра ради графиков с NetApp.
Скоро обещают обновить ONTAP и завезти расширенный API, шаблон переедет на HTTP-агент.
Шаблон, скрипт и дашборд
github.com/domclick/netapp-volume-monitoring
Полезные ссылки
docs.netapp.com/ontap-9/index.jsp
www.zabbix.com/documentation/current
ссылка на оригинал статьи https://habr.com/ru/company/domclick/blog/517206/