14 октября состоялась небольшая онлайн-конференция HaxeIn 2020. Одним из докладчиков был Александр Кузьменко — разработчик компилятора Haxe.
Доклад Александра — это отчет о работе, проделанной с февраля 2020 (когда состоялся HaxeUp Hamburg, организованный компанией Inno Games). Предлагаю вашему вниманию расшифровку его выступления.

Что же было сделано за прошедшее время?
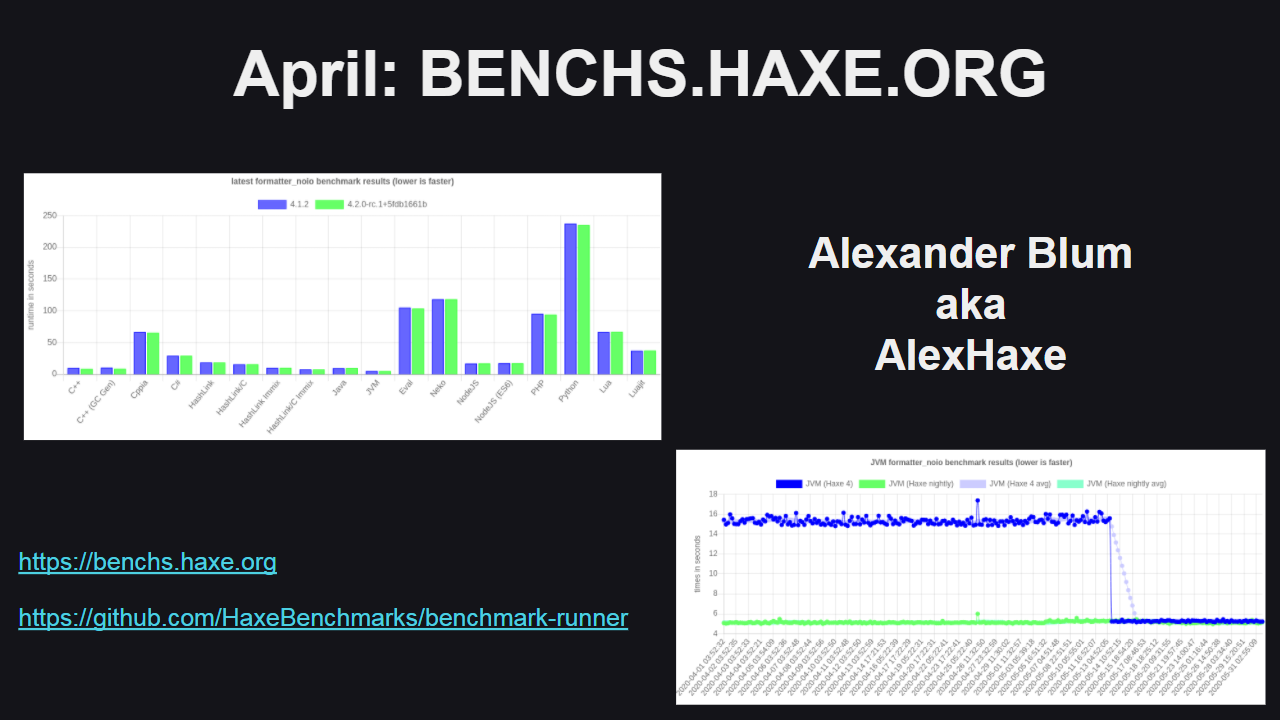
benchs.haxe.org
В апреле была выпущена первая версия пакета для сравнительного анализа производительности кода, сгенерированного Haxe. Автором проекта является Александр Блум, также известный как AlexHaxe.
Результаты работы тестов производительности доступны на подсайте https://benchs.haxe.org/, а исходный код — на github.
Имеющиеся тесты дают хорошее представление о работе кода на поддерживаемых платформах, о сильных и слабых сторонах каждой из платформ. Данный инструмент используется для отслеживания изменений в поведении кода при внесении изменений в компилятор Haxe — как можно увидеть на нижнем графике на слайде, скорость работы кода под JVM в какой-то момент значительно увеличилась (это произошло, когда Саймон Кражевски реализовал новый механизм работы с анонимными функциями и замыканиями). Аналогично данный инструмент позволяет оперативно находить регрессии в скорости работы кода, точно определять причины подобных изменений и исправлять найденные проблемы до того, как они смогут попасть в релизную версию компилятора.
Haxe 4.1
В мае состоялся релиз Haxe 4.1 (то есть спустя полгода после выхода Haxe 4.0). Основными изменениями версии 4.1 были:
- официальная поддержка JVM (до этого поддержка JVM имела экспериментальный статус). Саймон не был уверен в целесообразности поддержки данной платформы, чуть подробнее об этом будет сказано далее.
- поддержка SSL для интерпретатора макросов Haxe (eval-таргет)
- новый механизм обработки исключений. До этого для каждой из платформ использовался свой код для работы с исключениями, теперь же для этого используется единый код. Подробнее об этом также будет сказано далее.
- автоматическая оптимизация хвостовой рекурсии, позволяющая сократить количество рекурсивных вызовов функций во время исполнения программ, что позволяет избегать в некоторых случаях переполнения стека и сократить потребление памяти.
Кроме того, Haxe 4.1 включает более сотни других изменений, улучшений, оптимизаций и исправлений ошибок. И хотя среди них нет других существенных изменений (если сравнивать с перечисленными выше), Haxe 4.1 можно считать довольно удачным релизом с точки зрения улучшения стабильности и поддержки работы с IDE.

dts2hx
Буквально спустя 2 дня после релиза Haxe 4.1 Джордж Корни выпустил dts2hx — инструмент для автоматического конвертирования определений типов TypeScript в Haxe-экстерны, которые можно использовать при написании проектов под JavaScript. Таким образом, отпадает необходимость написания вручную экстернов для JavaScript-библиотек.
Работа Джорджа была спонсирована Haxe Foundation, благодаря чему работа над dts2hx была доведена до логического конца (ранее предпринимались попытки создания подобного инструмента, однако по тем или иным причинам они не увенчались успехом).

Рассмотрим подробнее упомянутые изменения в Haxe 4.1:
Официальная поддержка JVM-таргета. Путь к ней нельзя назвать простым — в какой-то момент Саймон хотел полностью отказаться от ее поддержки (и даже создал специальный pull request для этого), т.к. был разочарован в скорости работы сгенерированного байт-кода — он работал гораздо медленнее старого Java-кода. Но благодаря другим членам команды (Даниилу Коростелеву и Йену Фишеру), которые убедили Саймона продолжать работу, и, конечно же, благодаря работе Саймона, теперь у нас есть возможность компилировать Haxe-код напрямую в JVM байт-код без использования компилятора Java. И JVM-таргет по мнению Александра — это один из лучших таргетов Haxe, и вот почему:
- развитая экосистема Java, развивающаяся в течение десятилетий, предоставляющая всевозможные библиотеки и инструменты
- быстрая компиляция Haxe в байт-код JVM, сравнимая по скорости с компиляцией в JavaScript-код
- автоматическая генерация экстернов компилятором без использования дополнительных инструментов. Все что для этого нужно — просто указать путь к jar-файлу
- JVM — это одна из наиболее производительных платформ, поддерживаемых Haxe. Кроме того, сборщик мусора, поставляемый с виртуальной машиной Java — один из самых быстрых из доступных (если не самый быстрый). Как видно из графика на слайде ниже, в тесте производительности formatter (тест производительности с использованием библиотеки formatter для форматирования исходного кода) JVM-таргет показывает лучшие результаты.

Поддержка SSL для eval-таргета (интерпретатор Haxe) позволяет выполнять https-запросы в макросах.
Кроме этого добавлен доступ к API библиотеки Mbed TLS для работы с SSL (данная библиотека используется самим компилятором Haxe для поддержки SSL).

haxe.Exception
Поговорим теперь об обработке исключений.
Ранее для создания исключений можно было использовать объекты любых типов (строки, числа, булевы значения, объекты пользовательских классов). В Haxe 4.1 это также возможно (т.е. обратная совместимость кода для работы с исключениями была сохранена), но теперь более предпочтительным является использование нового класса haxe.Exception (базового класса для исключений) или его классов-наследников.
Чтобы обработать исключение любого типа, следует указать класс haxe.Exception в качестве типа исключения. В таком случае, при вызове исключений с типом, не являющимся наследником haxe.Exception (например, строкой или целочисленным значением), компилятор самостоятельно "обернёт" это значение, и данное исключение будет обработано как если бы у него уже был тип haxe.Exception. Это поведение похоже на то, как обрабатываются исключения с типом Dynamic (т.е. исключения любого типа) в Haxe до версии 4.1.

Однако есть и некоторые отличия: для доступа к стеку вызовов в предыдущих версиях Haxe необходимо было использовать класс haxe.CallStack, теперь же стек вызовов доступен прямо из самого объекта исключения. Еще одним преимуществом нового механизма является возможность повторно сгенерировать исключение (rethrow exception), при этом новое исключение будет хранить стек вызовов изначального исключения. Также есть возможность генерации повторного исключения с новым стеком вызовов (из места повторной генерации исключения).
С точки зрения разработчика компилятора, преимуществами нового механизма обработки исключений являются:
- механизм обработки исключений унифицирован для всех поддерживаемых платформ. Поэтому, если возникнет необходимость внести какие-либо изменения в него (исправить ошибку или добавить новую функцию), то теперь не нужно изменять код для каждой из платформ, а достаточно изменить код только в одном месте
- для доступа к стеку вызовов теперь не используются глобальные переменные
- класс
haxe.Exceptionнаследуется от нативных типов исключений для каждой из платформ. Таким образом, при генерации исключений в Haxe вы генерируете нативное исключение - и это упрощает работу с исключениями при интеграции с нативным кодом. Например, в случае если вы скомпилировали свой проект на Haxe в jar и используете полученный jar в проекте на Java, то исключения, сгенерированные из Haxe-кода, могут быть перехвачены и обработаны в Java-коде без каких-либо дополнительных ухищрений.

Также в блоке catch теперь нет необходимости указывать тип обрабатываемого исключения — если опустить тип, то исключение будет обрабатываться как имеющее тип haxe.Exception.

Tail recursion elimination
Оптимизация хвостовой рекурсии (tail recursion elimination) автоматически преобразовывает рекурсивные вызовы функции в циклы.
Благодаря данной оптимизации, у вас есть возможность писать читаемый рекурсивный код, который после компиляции работает так же быстро, как если бы вы написали его в императивном стиле (с циклами).
Как можно понять из названия данной оптимизации, она работает только для случаев, когда рекурсивный вызов функции осуществляется в самом ее конце.

Оптимизация хвостовой рекурсии выполняется только при включенном статическом анализаторе (включается с помощью параметра компиляции -D analyzer_optimize).
При этом оптимизация осуществляется только в отношении либо статических, либо встраиваемых (inline), либо финальных (final) функций. Данная оптимизация не может быть применена к обычным методам объектов, которые могут быть переопределены в дочерних классах (и тогда эта оптимизация приведет к изменению поведения функции).
Отключить оптимизацию хвостовой рекурсии при включенном статическом анализаторе можно с помощью дополнительного параметра -D no_tre.

Среди других изменений в Haxe 4.1 следует отметить:
- улучшения в работе сервера автодополнения, который стал гораздо стабильнее при работе с большими кодовыми базами
- добавлен новый режим проверок для на Null-безопасность (Null Safety) — StrictThreaded, предназначенный для приложений, работающих в нескольких потоках. Strict-режим при этом рекомендуется использовать при разработке приложений, работающих в одном потоке.
- улучшен механизм переименования локальных переменных в сгенерированном коде, благодаря чему упрощается отладка кода (в особенности для JavaScript без Source Maps) — в сгенерированном коде создается существенно меньше локальных переменных.
- метод
Std.isобъявлен как устаревший (deprecated), вместо него рекомендуется использовать методStd.isOfType. В дальнейшем это поможет добавить новый операторis(планируется в Haxe 4.2).

Haxe Evolution 2020
В июне состоялось второе онлайн-совещание Haxe Evolution, на котором обсуждались предложения по развитию языка Haxe (некоторые из них были приняты, некоторые отклонены, а по некоторым не принято окончательного решения).
Свои предложения может внести любой член сообщества. При этом сначала рекомендуется создать issue в соответствующем репозитории, в рамках обсуждения которого можно будет собрать фидбек и подробнее детализировать предлагаемые изменения.

Первое из рассмотренных предложений — это возможность использовать Void как "единичный тип" (unit type). Такая возможность реализована во множестве языков, в особенности в функциональных: можно указать тип Void, означающий отсутствие данных, в тех местах, где ожидается какое-либо значение. Например, можно указать тип Void при создании промисов (Promise), которые не возвращают никаких данных. В настоящее время синтаксис промисов в Haxe не позволяет такого.
По данному предложению еще не принято окончательного решения, т.к. остается открытым ряд вопросов, например, сделать ли обязательным указание типа Void, или же добавить в компилятор возможность неявной подстановки типа в случаях, когда пользователь опустил аргумент типа Void.

Второе рассмотренное предложение — добавление поддержки метаданных для локальных переменных на уровне синтаксиса языка. На уровне AST данная возможность для локальных переменных уже поддерживалась. Поэтому команда просто приняла данное предложение и реализовала его.
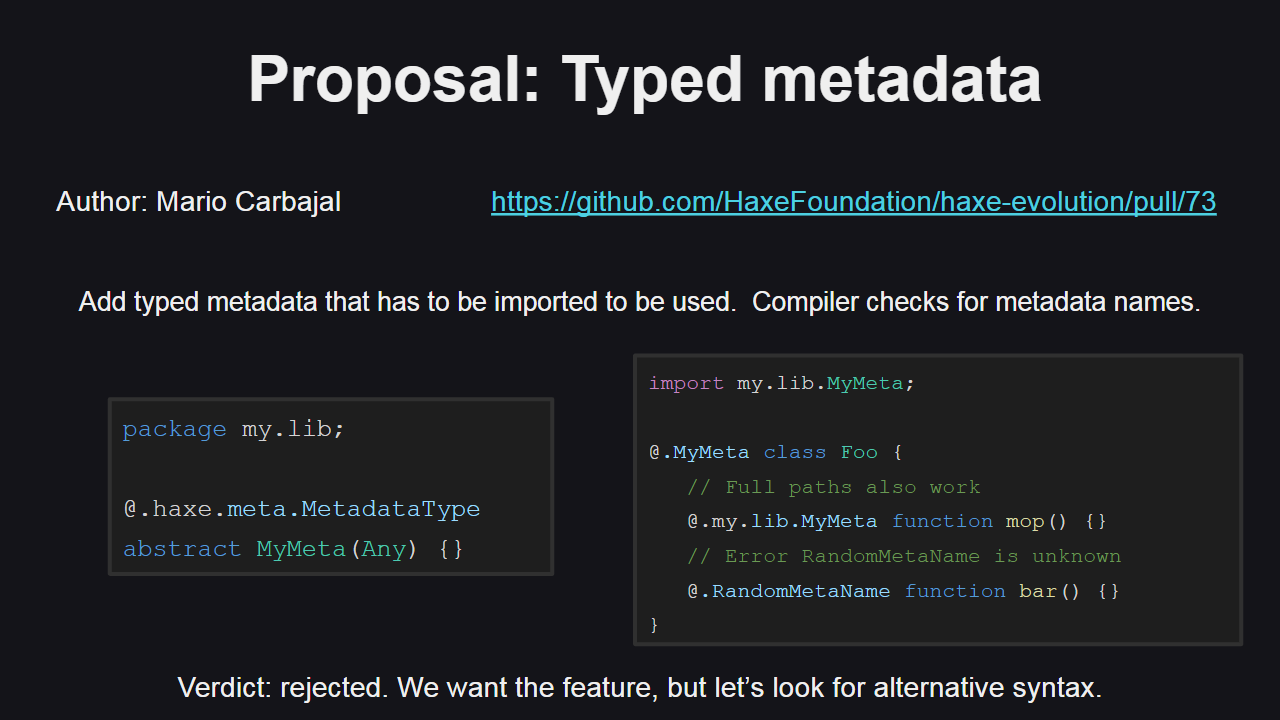
Как вы можете знать, в настоящее время в Haxe метаданные не типизированы, поэтому компилятор не отлавливает опечатки в именах метаданных — программистам нужно самостоятельно следить за правильностью их написания. Предложение по типизации метаданных должно было разрешить данную проблему. Для этого предлагался новый синтаксис, завязанный на систему типов: метаданные объявлялись бы как абстрактные типы, помеченные зарезервированным тегом @.haxe.meta.MetadataType, далее такой тип можно было бы импортировать и использовать в коде. Однако после обсуждений данное предложение было отклонено, т.к. предлагаемый синтаксис не подходит для решения всех проблем, связанных с отсутствием типизации метаданных — он решает только проблему с опечатками в именах метаданных, но не решает проблему с типами аргументов. Команда разработки все еще находится в поиске альтернативного синтаксиса, используя который можно было бы разрешить известные проблемы.
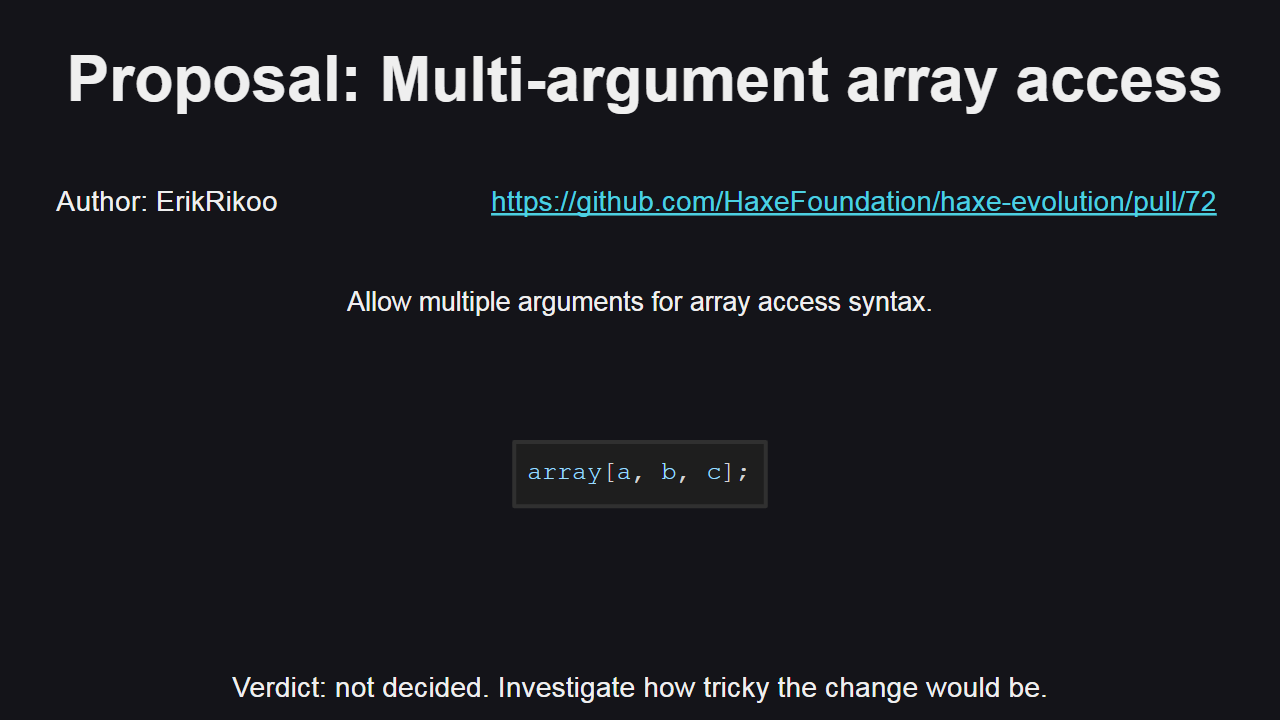
Следующее рассмотренное предложение — доступ к элементам массива с использованием нескольких аргументов. И хотя может показаться, что это относительно простая в реализации функция, все-таки остается неясным как реализовать ее в компиляторе, какие могут быть последствия, какие возможные конфликты могут проявиться при добавлении новых фич. В команде пока не приняли окончательного решения по данному предложению, необходимо дальнейшее исследование проблемы.
Предложение по добавлению в язык абстрактных классов (как в C# или Java) было принято командой. Таким образом, в Haxe появится возможность объявлять классы с частичной реализацией. От программиста потребуется реализовать объявленные абстрактные методы в дочернем классе, чтобы иметь возможность создать объект такого типа.

Добавление интерфейсов с реализацией методов по-умолчанию частично пересекается с абстрактными методами. Данное предложение не было принято по следующим соображениям: есть общепринятое мнение, что интерфейсы должны быть полностью независимы от реализации (то есть в интерфейсах должно присутствовать только объявление методов и свойств); также неясно как быть в случаях, когда какой-либо класс реализует несколько интерфейсов, в которых присутствует реализация одного и того же метода.

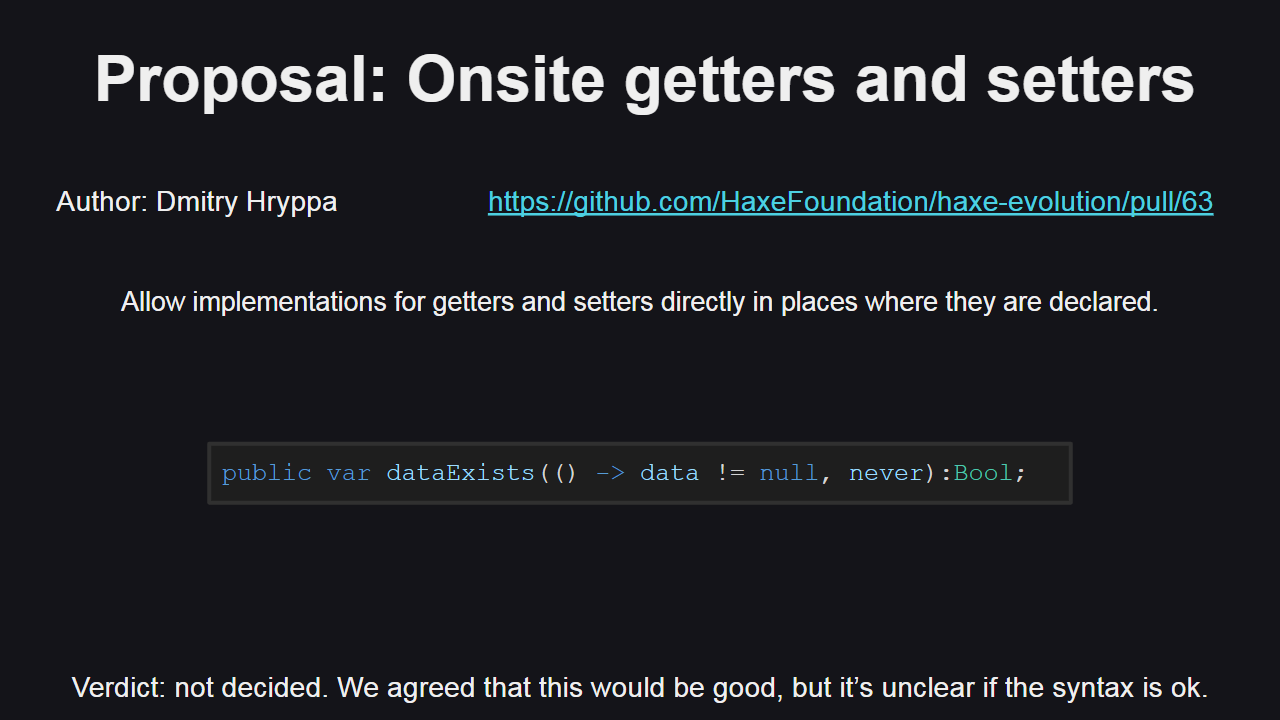
Следующее рассмотренное предложение — добавление нового синтаксиса для геттеров и сеттеров, позволяющего указывать их реализацию по месту объявления переменной. Синтаксис для геттеров и сеттеров в Haxe — это тема постоянных обсуждений, и совершенно ясно, что этот синтаксис требует эволюционных изменений. Однако предложенный вариант вызывает сомнения, поэтому обсуждение данного вопроса остается открытым.
Если вы работали с абстрактными типами в Haxe, то скорее всего сталкивались с необходимостью обращаться к полям абстрактного типа из его же методов. Однако, this для абстрактных типов возвращает объект базового типа (для которого абстрактный тип является оберткой). Для решения данной проблемы был предложен новый синтаксис, в котором задается дополнительный идентификатор при объявлении абстрактного типа. И хотя предложенная реализация решает указанную проблему, используемый синтаксис вызывает вопросы: в Haxe после ключевого слова as обычно ожидается имя типа, а не идентификатора, поэтому обсуждение предложения остается открытым.

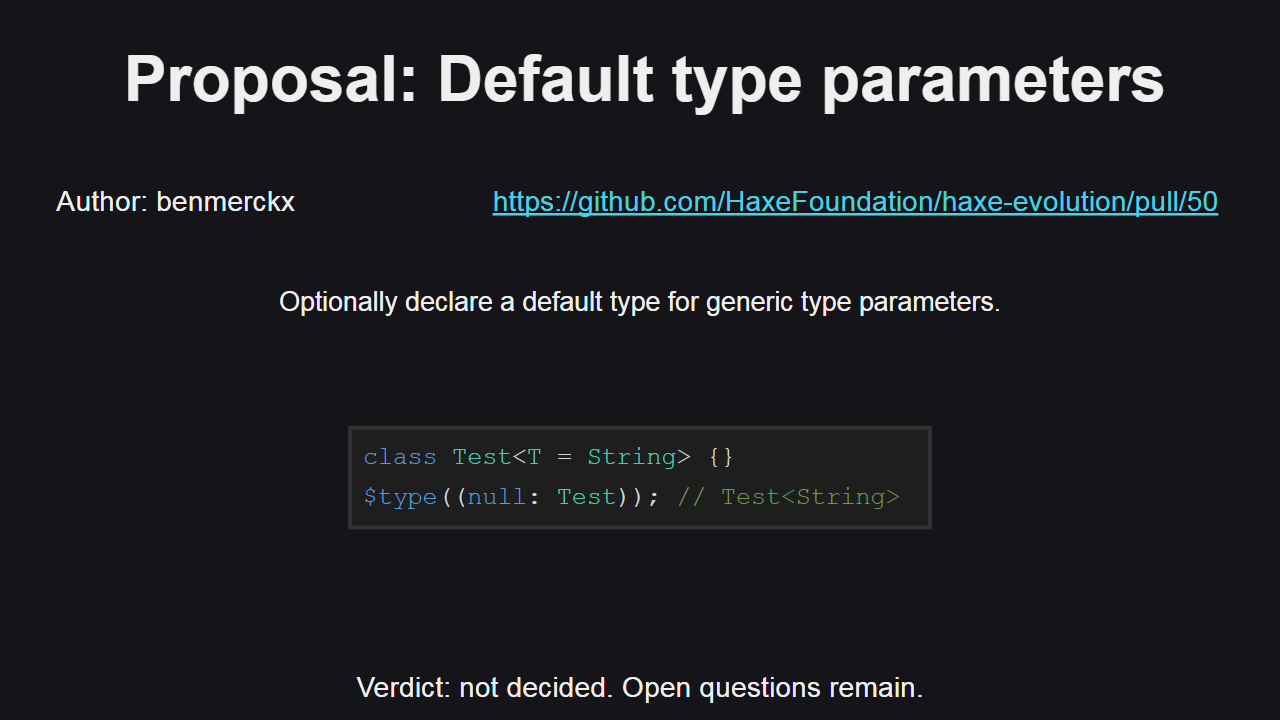
Параметры типов по-умолчанию позволяют использовать обобщенные типы (generic types) без необходимости явно указывать типы параметров. Такое изменение было бы полезным для случаев, когда для обобщенного типа (например, типизированного исключения или ошибки) обычно используется какой-либо один тип параметра (например, String). Да, в таком случае можно использовать typedef, однако, такой сценарий плохо масштабируется для случаев, когда у обобщенного типа есть несколько параметров.
Несмотря на то, что предлагаемая фича несомненно полезна и мы хотим реализовать ее, остается нерешенным ряд вопросов, например, как обрабатывать дефолтные типы параметров в конструкторе, где данные типы могут быть выведены из аргументов, и что делать в случаях, когда выведенные типы конфликтуют с дефолтными типами?
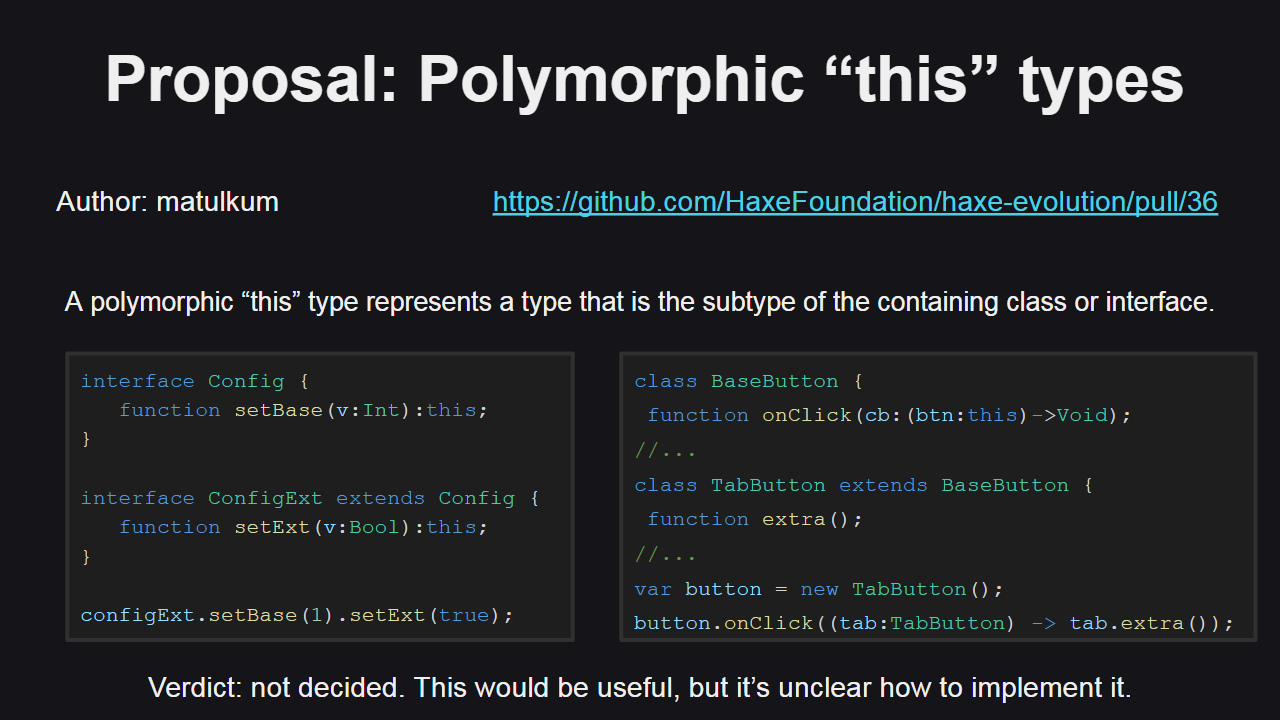
Полиморфный тип для this всегда представляет текущий тип, даже для методов, унаследованных от родительского класса или интерфейса. Такая функция в языке безусловно является полезной, т.к. позволит избавиться во множестве случаев от необходимости приведения типов. Однако пока нет четкого представления о том, как реализовать ее в компиляторе, поэтому нужны дальнейшие исследования.
Вариантность типов параметров для перечислений (type parameter variance of enum).
В настоящее время нельзя, например, передать enum с параметром типа Int, когда в качестве значения ожидается enum с параметром типа Float (как в примере на следующем слайде) — компилятор выдаст ошибку, что данные типы не совместимы. В общем случае это было бы правильно, например, нельзя массиву чисел с плавающей точкой присвоить значение в виде массива целых чисел, ведь в противном случае можно будет вставлять в такой массив числа с плавающей точкой. Но если тип параметра доступен только для чтения, то такая возможность вполне логична и полезна.
Однако предложение с данным изменением было отклонено, т.к. команда хочет реализовать его для более широкого применения — не только для enum, но и для любых других типов (классов, абстрактных типов). Возможно, что это будет реализовано в стиле C#, где есть in и out-параметры.

Дорога к Haxe 4.2
Перейдем непосредственно к тому, что же происходит во вселенной Haxe в данный момент.
В настоящее время мы работаем над Haxe 4.2. К сожалению назвать дату релиза мы не можем, т.к. остается еще много работы, но многое уже сделано (посмотреть на текущее состояние работы, можно скачав ночную сборку).
Давайте рассмотрим реализованные изменения:
В ночных сборках уже доступны статические поля на уровне модулей (Module-level static fields), позволяющие объявить функцию или переменную, не являющуюся членом какого-либо типа. То есть можно создать модуль с неким набором вспомогательных функций, импортировать его в другой модуль и обращаться к функциям из импортированного модуля, не указывая имени этого модуля. Такая возможность особенно полезна при написании простых скриптов, когда нет необходимости в создании дополнительных классов.

Также реализованы абстрактные классы, упоминавшиеся ранее. Работают они как "классические" абстрактные классы в Java:
- компилятор не даст создать экземпляр такого класса напрямую, он потребует наличия реализаций абстрактных методов
- реализация абстрактных методов должна быть предоставлена в дочерних классах
На слайде представлен простейший пример абстрактного класса Shape, в котором объявлено API — все объекты типа Shape имеют метод vertices(), возвращающий набор вершин. И класс Square предоставляет реализацию данного метода.
Абстрактные классы могут наследоваться от других абстрактных классов, но в итоге потребуется создать класс-наследник с реализацией всех абстрактных методов, чтобы иметь возможность создания объектов данного типа.

sys.thread.Thread
В Haxe 4.2 проведена большая работа по улучшению поддержки многопоточности (данной области долгое время не уделялось должного внимания, но теперь наступило время исправить эту несправедливость) — мы добавили циклы событий (event loops) для потоков (они похожи на циклы событий в NodeJS и libuv):
- для основного потока всегда создается цикл событий
- для прочих потоков нужно либо явно указывать необходимость создания цикла событий при создании потока, либо самостоятельно создать цикл событий для уже существующего потока
- циклы событий позволяют запланировать выполнение кода в другом потоке. Например, можно создать поток исполнения и задать из основного потока функцию-колбек (callback) для исполнения в созданном потоке
- вы можете этого не знать, т.к. многопоточность не сильно использовалась в Haxe до версии 4.2, но на самом деле любой таймер, созданный в любом потоке, выполнял свой колбек в основном потоке. Но начиная с Haxe 4.2 таймер выполняет свой колбек из потока, в котором он был создан.

Для создания потока с циклом событий есть соответствующее API в модуле sys.thread.Thread — метод Thread.createWithEventLoop(), в который передается функция, которая будет выполнена в созданном потоке. Как только выполнение переданной функции будет завершено, в потоке начнется работа цикла событий, в котором будут обрабатываться все события, как в примере, представленном ниже:
из основного потока посылается событие с колбеком, в котором просто выводится сообщение:
secondary.events.run(() -> { trace(‘This is printed from the secondary thread’); });
Таким образом, переданный колбек будет выполнен после выполнения основной функции в потоке secondary.
Также, мы видим, что в коде, выполняемом в потоке secondary, тоже посылается событие, но уже в основной поток:
mainThread.events.run(() -> { trace(‘This is printed from the main thread’); });
Переданный в этом событии колбек будет выполнен в основном потоке (это произойдет после завершения выполнения всего кода в основном потоке).
Однако, т.к. в Haxe основной поток не ждет, когда закончится выполнение потока secondary, то нужно быть уверенным, что выполнение кода в основном потока не завершится до того, как мы пошлем событие из потока secondary. Поэтому в коде примера присутствует вызов Sys.sleep(2).

Потоки без циклов событий (например, созданные с помощью метода Thread.create(), или с помощью нативного API платформы) при попытке доступа к событиям, генерируют исключения sys.thread.NoEventLoopException.
В качестве примера рассмотрим код на следующем слайде: в этом примере поток secondary создается без цикла событий, мы можем послать из него события в основной поток, но при попытке послать в него событие из основного потока мы получим исключение в основном потоке (поток secondary при этом будет продолжать выполняться).
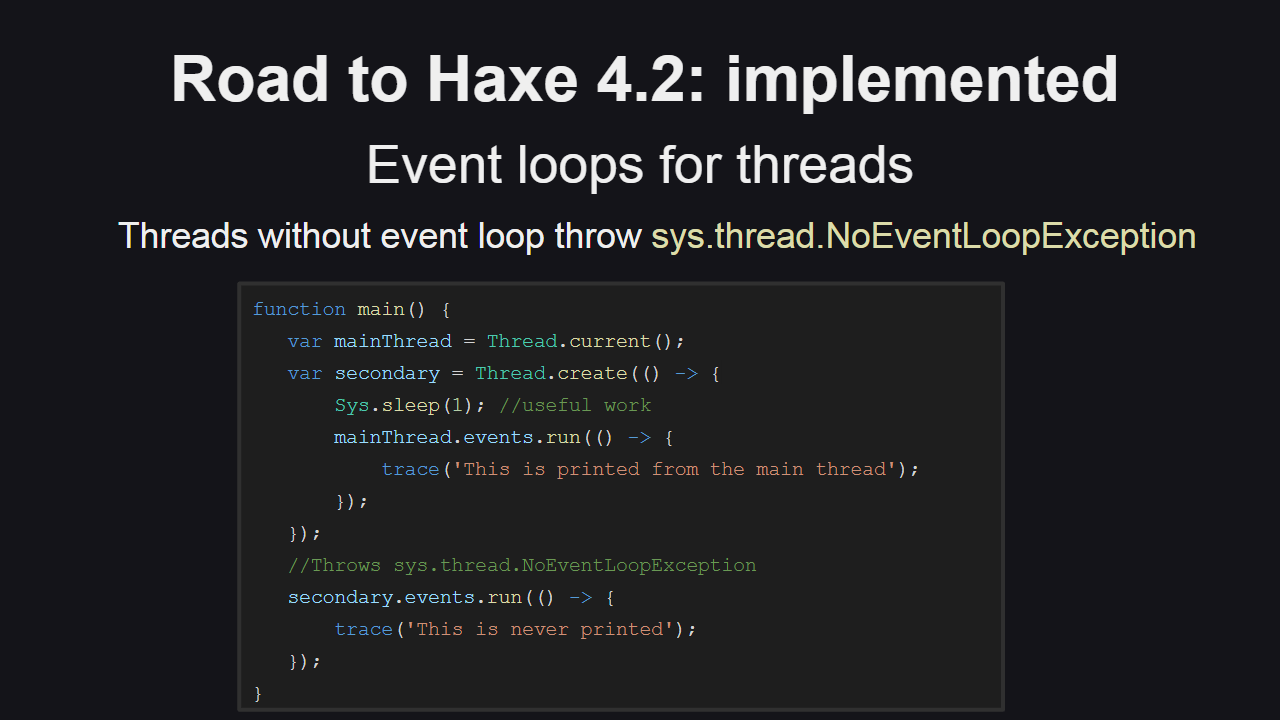
Также есть возможность отложить отсылку событий — можно "пообещать", что событие будет отослано, в таком случае цикл событий потока будет выполняться до тех пор, пока событие не будет отправлено.
На слайде приведен пример использования такой функции: в коде "вторичного" потока мы пообещали, что отошлем событие в основной поток, затем выполняем полезную работу в созданном потоке (которая может выполняться дольше, чем выполнение кода в основном потоке приложения) и только потом отсылаем событие в основной поток. Как видно, используя отложенные события, можно не беспокоиться, что выполнение кода в потоке завершится раньше, чем событие будет отослано, и нет необходимости в использовании вызова Sys.sleep(2) как в одном из предыдущих примеров — основной поток будет ожидать событие и завершит выполнение только после обработки этого события.

Улучшения для абстрактных типов
Другим существенным изменением являются новый функционал для абстрактных типов (не надо путать с абстрактными классами):
- транзитивность (о ней мы поговорим чуть позже)
- передача вариантности (variance forwarding), позволяющая "наследовать" вариантность базового типа (underlying type) для абстрактных типов
- передача конструктора (constructor forwarding). В Haxe 4.1 и ранее нельзя передать конструктор для абстрактных типов с помощью метаданных (
@:forwardи@:forwardStatics), в Haxe 4.2 это можно будет сделать с помощью@:forward.new.
Перечисленные изменения появятся благодаря работе Дмитрия Маганова — за прошедшее лето он прислал порядка 40 пулл-реквестов.

Остановимся подробнее на транзитивности:
Для того, чтобы абстрактный тип поддерживал транзитивное приведение типов (transitive casting), следует использовать метаданные @:transitive. Для объяснения данной функции рассмотрим пример на следующем слайде.
Ранее транзитивное приведение типов поддерживалось только для строго определенных типов ("зашитых" в компиляторе). В Haxe 4.1 и ранее нельзя в качестве значения передать массив целочисленных значений (Array<Int>) туда, где ожидается значение типа Collection. Это ограничение в рассматриваемом примере обусловлено тем, что для типа Collection не объявлена возможность приведения от Array<Int> (а только для приведения из типа Items). Но в Haxe 4.2 такая возможность появится (и уже реализована в ночных сборках) — с помощью уже упомянутой меты @:transitive для типа Collection мы разрешаем те же приведения типов, что объявлены для типа Items и, таким образом, переменной с абстрактным типом Collection можно будет напрямую присвоить значение с типом Array<Int> (т.к. абстрактный тип Items поддерживает приведение из Array<Int>):
var collection:Collection = [123];
При этом транзитивное преобразование типов работает в обе стороны, то есть переменной с типом Array<Int> можно присвоить значение с типом Collection:
var array:Array<Int> = collection;

Передача вариантности (variance forwarding) обеспечивает вариантность в параметрах типов. Рассмотрим данную функцию на примере из следующего слайда:
В Haxe 4.1 и ранее нельзя было присвоить значение типа Array<Int> переменной с типом Array<Money>, где Money — это некий абстрактный тип, для которого базовым типом является тип Int. Но теперь, используя специальную мету @:forward.variance, разработчик может "подсказать" компилятору, что любой тип, построенный над Int, может быть использован как тип Money.
Следствием данного изменения также является возможность использовать тип Any в качестве параметра типа в случаях, когда ожидается любой тип. Ранее для этого приходилось использовать тип Dynamic, что менее типо-безопасно. Теперь же предпочтительно использовать Any.

Остальные менее существенные изменения, которые стоит упомянуть это:
- в Haxe 4.2 улучшена работа с оператором
is. В Haxe 4.1 он несколько ограничен — требуется использовать дополнительные скобки вокруг выражения с данным оператором. При этом выражения с операторомisпри компиляции преобразовываются в вызов методаStd.isOfType()(то есть сейчас это синтаксический сахар), но в будущем планируется сделать из него полноценный оператор. - для Python добавлена реализация кроссплатформенного API для работы с многопоточным кодом — класс
sys.thread.Thread. - улучшен механизм встраивания объектов (object inlining). Ранее встраивание объекта немедленно отменялось если происходило его присваивание локальной переменной. Теперь же встраивание объектов осуществляется в несколько проходов, и встраивание объекта не отменяется при присваивании его нескольким переменным, это происходит только если объект попадает за пределы контекста, в котором он был объявлен.
- улучшен механизм выведения типов. Это довольно обширная тема, и если вам интересны подробности, то рекомендую почитать статью в 2-х частях в официальном блоге Haxe (часть 1 и часть 2). Сейчас же скажу только, что это полезная функция компилятора в случаях, когда вы явно не указываете типы переменных, а полагаетесь на компилятор, что он самостоятельно определит их.

WIP
Рассмотрим вкратце изменения в Haxe 4.2, еще находящиеся в работе:
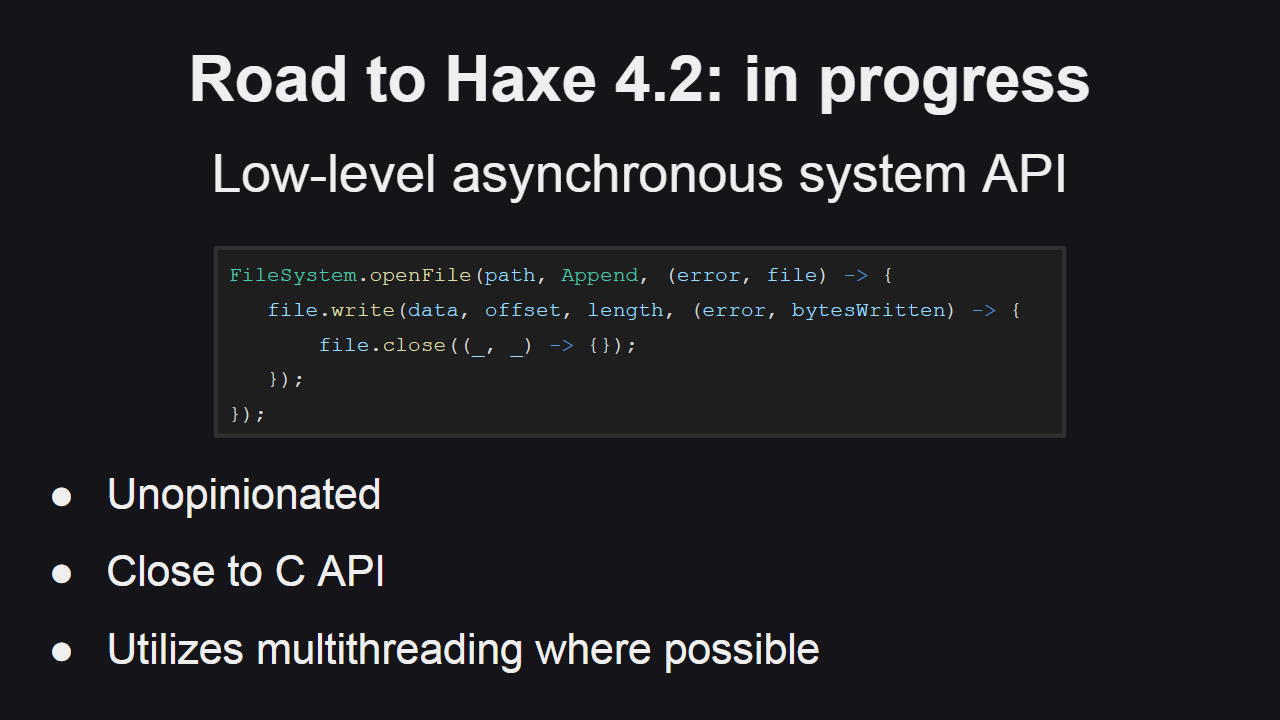
В настоящее ведется работа над низкоуровневым асинхронным API. Дизайн нового API с использованием колбеков может показаться устаревшим, однако он позволяет построить поверх него лучшее API.
Новое API близко к C API и, таким образом, добавляет лишь небольшой слой абстракции поверх нативного API и не несет с собой значительных дополнительных затрат вычислительных ресурсов.
Новое API использует многопоточность там, где это возможно.
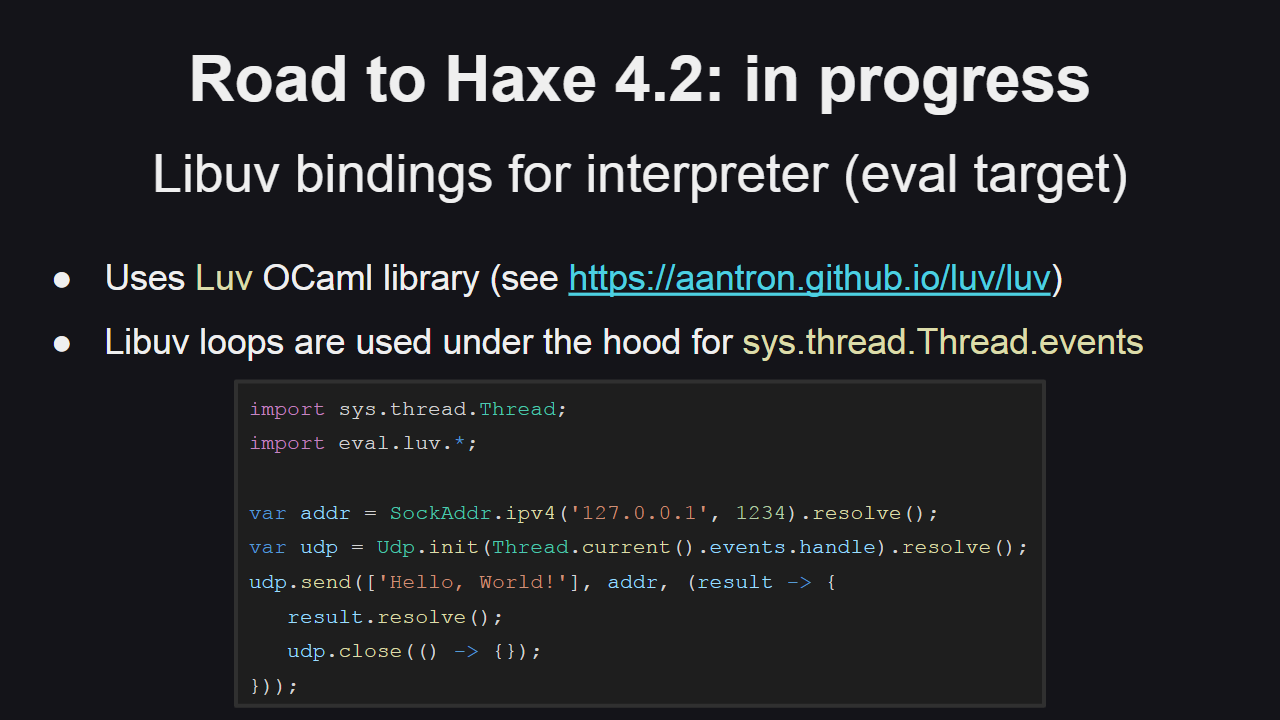
Для некоторых платформ новое асинхронное API под капотом будет использовать библиотеку Libuv, и в настоящее время ведется работа над биндингами для интерпретатора Haxe (eval-таргет), что позволит в полной мере использовать API Libuv при создании как клиентских, так и серверных приложений.
Для создания биндингов используется OCaml-библиотека Luv.
Также стоит отметить, что Libuv используется для работы циклов событий для потоков (о которых говорилось ранее).
Будущее
И совсем немного о будущих планах:
- в Haxe определенно появятся корутины
- появятся кроссплатформенные реализации целочисленных типов, таких как 8 и 16-битные целые числа, знаковые и беззнаковые и т.д.
- также появится поддержка методов с переменным числом аргументов (rest arguments). Работа над ними уже начиналась, однако, была отложена.

Спасибо за внимание! Надеюсь, что данный материал показался вам интересным.
ссылка на оригинал статьи https://habr.com/ru/post/530716/
Добавить комментарий