
Недавно на Хабре вышли две статьи про новую корпоративную почтовую систему Mailion от МойОфис (1, 2) — уникальную российскую разработку, которая отличается беспрецедентными возможностями масштабирования и способна работать в системах с более чем 1 миллионом пользователей.
Несложно подсчитать, что для обслуживания такого числа пользователей потребуется колоссальный объем дискового пространства вплоть до десятков петабайт. При этом почтовая система должна уметь быстро обрабатывать эту информацию и надежно хранить её. Сегодня мы объясним общие принципы организации хранения данных внутри почтовой системы Mailion и расскажем, к каким оптимизациям мы прибегли, чтобы значительно снизить количество операций ввода/вывода и сократить требования к инфраструктуре.
Хабр, привет! Меня зовут Виталий Исаев, я занимаюсь разработкой объектного хранилища почтовой системы Mailion. Этой статьёй мы открываем цикл публикаций, посвящённых архитектуре нашего хранилища, его масштабированию, отказоустойчивости и устройству его внутренних подсистем.
Немного истории
Структура электронного письма формировалась в течение последних пятидесяти лет. Этапы её развития зафиксированы несколькими стандартами. Первое электронное письмо было отправлено между компьютерами системы ARPANET ещё в 1971 г. Но разработчикам стандартов потребовалось ещё 11 лет на разработку RFC 822, который стал прообразом современного представления электронной почты. В нём был описан общий коммуникационный фреймворк текстовых сообщений. В это время электронное письмо рассматривалось просто как набор текстовых строк, а передача структурированных данных (изображений, видео, звука) не подразумевалась и никак не регламентировалась.
Примерно в середине 1990-х родилась концепция специальных расширений MIME (RFC 2045, RFC 2046, RFC 2047), которые позволили включать в состав электронного письма бинарные форматы данных в закодированном виде.
В 2001 году новый стандарт RFC 2822 отменил некоторые устаревшие положения RFC 822, и ввёл понятие частей сообщения — message parts, или, проще говоря, «партов». А благодаря MIME появилась возможность создавать multipart-письма, которые могли бы состоять из множества частей различных типов. Наиболее актуальным стандартом электронной почты является RFC 5322, он был разработан в 2008 году.
Структура электронного письма
На сегодняшний день типичное почтовое сообщение состоит из заголовка и «партов». В заголовке в структурированном виде хранятся метаданные, такие как идентификатор письма, электронные адреса отправителя и получателя, дата отправки и другие служебные поля. К «партам», которые составляют само тело письма, относятся основной и альтернативный текст, изображения, прикреплённые файлы. Объём заголовочной части письма редко превышает 1 килобайт текста, тогда как размер тела письма ограничен лишь лимитами почтовой системы и может достигать десятков и даже сотен мегабайт.
Когда письма поступают в Mailion по любому из транспортных каналов (SMTP, IMAP, API), они не сохраняются как единое целое, а разбиваются на составные части. В Mailion мы извлекаем информацию о структуре письма и некоторые другие служебные данные, и затем сохраняем их в хранилище метаинформации. «Парты» писем, которые составляют основной объем данных, направляются в объектное хранилище.
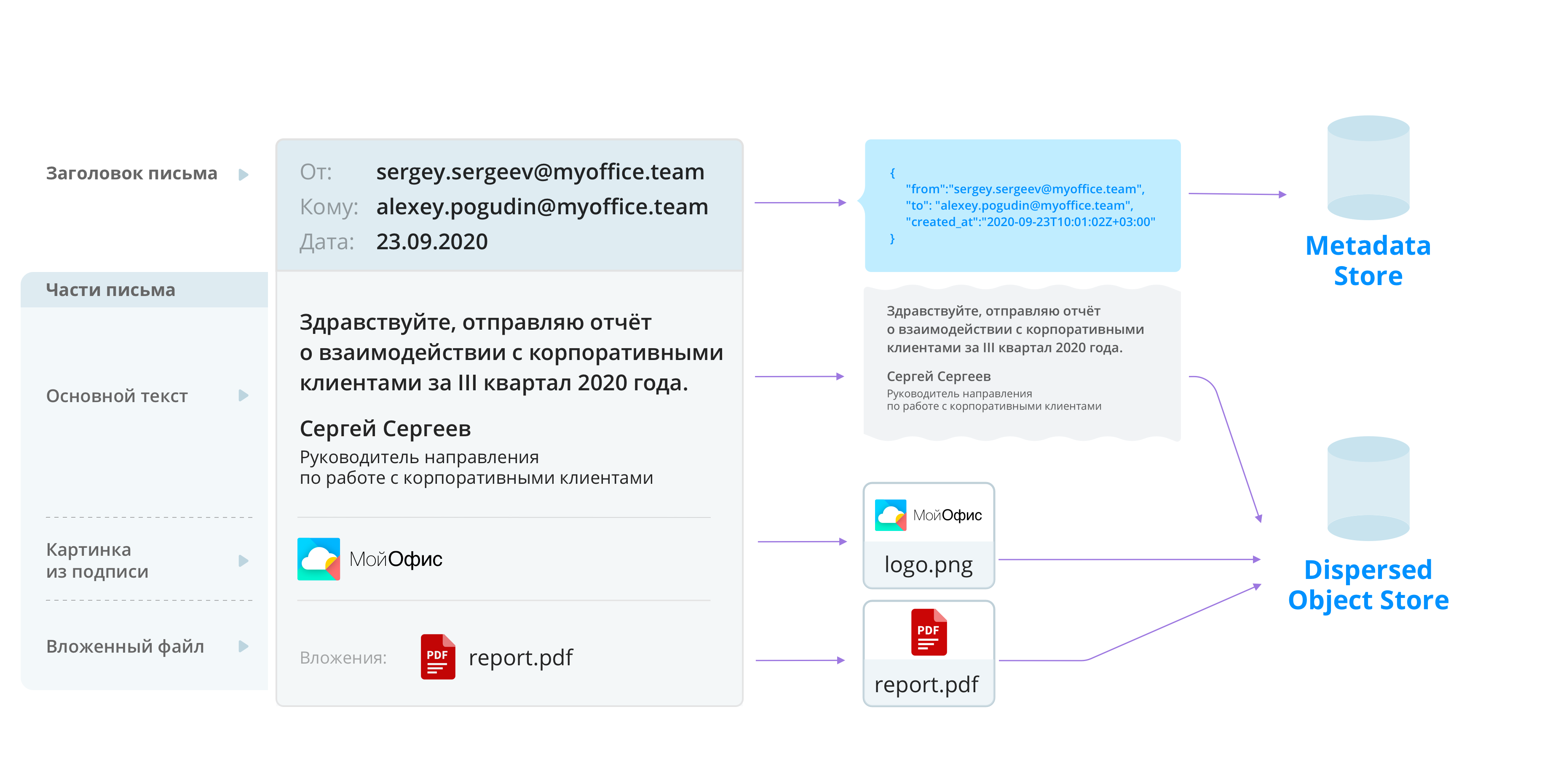
Рис. 1. Разбиение электронного письма на фрагменты и сохранение по частям в хранилище метаданных и объектном хранилище.
Поток данных, который проходит через почтовую систему, отличается следующими важными особенностями:
-
Письма часто пишутся и ещё чаще читаются. Работа пользователей с почтовой системой порождает огромное количество операций ввода-вывода в хранилище.
-
Письма иммутабельны — однажды отправленное или полученное письмо хранится в почтовой системе в неизменном виде на протяжении всего своего жизненного цикла. Черновики писем могут редактироваться, но сами письма — никогда.
-
Многие письма частично совпадают по содержимому. Например, в длинной цепочке писем могут встречаться взаимные цитирования. Это порождает совпадающие фрагменты текста. Пересылка писем со вложениями приводит к дублированию вложенных файлов. Кроме того, всеми сотрудниками одной компании используется в подписи идентичная картинка с логотипом. В корпоративной среде помимо этих совпадений бывают и другие, которые создаются информационными системами предприятия, например, шаблонными письмами с ответами календаря или системы управления задачами.
-
В корпоративной среде часто встречаются полные дубликаты писем. Это связано как с широким применением рассылок (например, отправка новостей компании всем сотрудникам), так и с практикой использования «копий» и «скрытых копий». Наконец, у каждого письма всегда есть минимум две копии — для отправителя и получателя, и в случае внутрикорпоративной переписки обе копии хранятся в одной и той же почтовой системе.
Дедупликация
После детального анализа особенностей потока данных мы сформулировали основной принцип проектирования хранилища: оно должно эффективно проводить дедупликацию почтовых сообщений. Правильная работа с дубликатами позволяет экономить не только дисковое пространство, но и операции ввода-вывода за счёт кэширования наиболее часто встречающихся фрагментов данных. Недорогие, но ёмкие HDD-накопители не отличаются высокой пропускной способностью, их показатели IOPS часто являются лимитирующим фактором для производительности всей системы. Благодаря дедупликации данных увеличивается не только экономическая эффективность хранилища, но и его производительность.
Пример расчета ресурсов системы хранения
Представьте, что вам необходимо выполнить массовую рассылку письма по компании с 1000 сотрудников. В подписи отправителя письма находится картинка с логотипом компании, её размер составляет 256 Кб. Давайте оценим затраты ресурсов на чтение рассылки всеми сотрудниками компаниями.
В классических почтовых системах mbox-формата, в которых копии писем разных пользователей хранятся в разных файлах, данная операция будет порождать поток произвольных чтений (random read) с диска. Стандартные HDD в этом режиме работы выдают производительность около 100 IOPS. При размере блока в 4 Кб чтение картинки в худшем случае, когда блоки файла при записи не были размещены последовательно, потребует 64 операции чтения. Следовательно, для чтения всех писем с картинками будет необходимо выполнить 64000 операции (64 операции * 1000 пользователей). Для того, чтобы обработать данную операцию за 1 секунду, потребуется 640 HDD одновременно. Если же в системе присутствует только один накопитель, то он будет работать со 100% утилизацией более 10 минут.
Дедупликация позволяет обойтись лишь однократной загрузкой картинки с диска, после чего она попадёт в кеш и при дальнейших запросах будет отдаваться напрямую оттуда. Экономическая эффективность системы с дедупликацией многократно превышает эффективность системы с классической архитектурой.
Накладные расходы дедупликации
Безусловно, дедупликация не бесплатна и сильно усложняет процесс записи и чтения, налагает дополнительные расходы на CPU и RAM. Однако иммутабельность данных частично компенсирует этот рост сложности. Благодаря неизменности писем, можно не поддерживать операцию записи по смещению (при необходимости его можно реализовать по принципу copy-on-write) и сохранять интерфейс хранилища максимально простым. На данный момент он состоит из записи, чтения, удаления данных и ещё пары вспомогательных методов.
Известные решения с дедупликацией
На момент старта проекта Mailion ни в одном из известных нам объектных хранилищ с открытым кодом подобные оптимизации не были реализованы. Например, в Minio отказались от реализации дедупликации ещё в 2017 г. Попытки доработки других готовых решений, таких, как Elliptics, Riak или Swift, при очевидных и значительных трудозатратах также не гарантировали успеха. ZFS в течение долгих лет не поддерживалась в Linux и по причине лицензионных разногласий официально не может поставляться в дистрибутивах, отличных от Oracle, да и к производительности дедупликации в этой файловой системе есть вопросы.
В Ceph дедупликация появилась в 2019 г., но Ceph имеет репутацию сложного для эксплуатации хранилища с большим количеством историй неуспеха. Многим известны истории отказа Ceph в Росреестре и DigitalOcean и даже потеря бизнеса компанией DataMouse. В багтрекере Ceph можно найти большое количество тикетов с зависаниями, сегфолтами и другими ошибками. Причем некоторые баги, даже в статусе Immediate, могут не устраняться по полгода и больше. Это наводит на мысли о том, что Ceph дорог не только с точки зрения эксплуатации, но и с точки зрения разработки: ресурсы разработчиков будут уходить на стабилизацию самого Ceph, а не на разработку собственного продукта.
Что такое DOS и как это работает
Мы убедились в отсутствии подходящих для наших задач продуктов с открытым исходным кодом, и решили разработать собственное хранилище с поддержкой дедупликации в самом ядре системы. Мы вдохновились программной статьей аналитиков из компании Storage Switzerland, в которой кратко описываются принципы проектирования современных программно-ориентированных хранилищ, и решили назвать наш продукт Dispersed Object Store (DOS). Код DOS написан на языках Go (95%), C и C++ (5%).
Модель данных и метаданных
Иерархия сущностей DOS включает в себя четыре уровня:
-
документы;
-
версии документов;
-
чанки (chunks);
-
сегменты.
Версия документа является синонимом традиционного понятия «объект». Каждый успешный запрос на запись в DOS порождает новую версию определённого документа. В зависимости от бизнес-логики клиента каждый документ может обладать либо единственной версией, либо целой коллекцией версий. При этом версии одного документа могут быть упорядочены, например, по значению логического времени создания версии.
Каждый документ со стороны публичного API адресуется идентификатором, который состоит из пространства имён (namespace) и собственно ключа (key). В рамках одного пространства имён все ключи являются уникальными. Непосредственно в хранилище из внешнего идентификатора и с помощью криптографической хеш-функции генерируется внутренний ключ (storekey), который обладает свойством глобальной уникальности. Во внутренних API все документы адресуются уже через storekey.
В DOS применяется стриминговая запись. В рамках обработки одного запроса на запись поток данных, который поступает на сервер, частично буферизуется в оперативной памяти и только по накоплению определенного объёма сохраняется в персистентном хранилище. Полной буферизации крупных файлов не происходит никогда, поскольку это привело бы к чрезмерным расходам RAM. Частичная буферизация данных (но не только она) предопределяет в модели данных DOS появление чанков — крупных байтовых последовательностей. Каждая версия документа может состоять из одного или нескольких чанков.
Чанки, в свою очередь, с помощью специальных алгоритмов разделяются на сегменты — более короткие байтовые последовательности. Они выступают в роли элементарных единиц хранения в DOS. У сегментов тоже есть свои идентификаторы, ими являются хеши от их содержимого. В каком-то смысле, внутренним адресом данных в DOS являются сами данные (эта идея не нова и используется, например, в P2P-файловом хранилище IPFS).
Все документы, версии, чанки и сегменты в совокупности формируют внутренние метаданные DOS. Для персистентного хранения метаданных (документов и сегментов) вводятся индексы. В качестве хранилища индексов используется широко известная встраиваемая key-value база данных RocksDB. Индексы с метаданными должны размещаться на быстрых SSD дисках.
В свою очередь раздробленные на сегменты данные размещаются в бэкендах хранения на медленных HDD дисках. На ранних этапах разработки для этого использовался простой файловый бэкенд, в котором каждое тело сегмента хранилось в отдельном файле. Впоследствии был разработан более совершенный блобовый бэкенд, в котором сегменты объединяются в крупные файлы (блобы), тем самым экономятся файловые дескрипторы и снижается количество переключений контекста между пространством пользователя и пространством ядра.
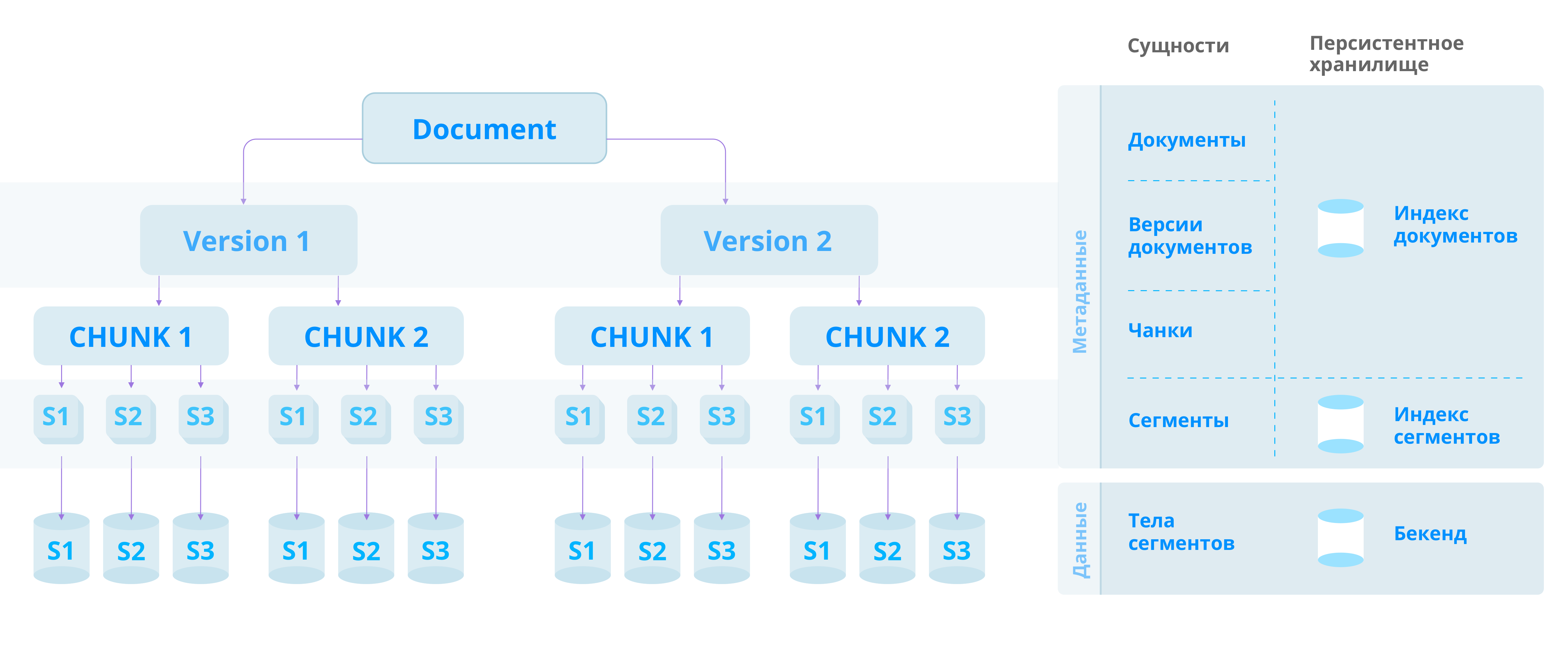
Рис. 2. Иерархия внутренних сущностей DOS.
Дедупликация в DOS
В нашей системе дедупликация реализована на двух разных уровнях: на уровне сегментов (блочная дедупликация); на уровне версий документов.
Каждый из этих подходов имеет свои плюсы и минусы. Дедупликация на уровне сегментов достигается за счёт совместного использования одних и тех же сегментов различными версиями документов. Каждый сегмент поддерживает внутри себя счётчик ссылок (reference counter) со стороны версий документов. В момент записи новой версии документа поток входящих данных разбивается на сегменты. Для каждого из них по индексу выполняется проверка существования. Если подобный сегмент встречается впервые, то выполняется его запись в бэкенд. Если же сегмент уже сохранялся ранее, то он просто получает новую ссылку со стороны только что созданной версии документа. Тем самым обеспечивается хранение каждого сегмента в единственном экземпляре.
Этот способ дедупликации работает постоянно и позволяет обнаруживать совпадения между разными версиями документов, которые могут отличаться по размеру, времени создания, типу данных и другим параметрам. Он вносит значительный вклад в оптимизацию дискового пространства и операций ввода-вывода. Популярные сегменты, постоянно использующиеся при обработках запроса на чтение, почти наверняка окажутся в кешах.
Однако есть и минусы: существенные накладные расходы на поддержание счётчиков ссылок. Например, одна ссылка потребует от 8 до 40 байт, поэтому для очень популярных сегментов с сотнями тысяч ссылок такие счётчики могут достигать размера в несколько десятков мегабайт. Индекс сегментов раздувается, тяжёлые сегменты становятся слишком большими для пересылки по сети, в результате начинает возрастать время отклика. Для решения этой проблемы приходится вводить сложную систему шардирования счётчика ссылок.
В результате хеширования содержимого сегмента создается идентификатор, обладающий свойством глобальной уникальности. Коллизии идентификаторов сегментов неизбежно приведут к повреждению данных, поэтому для хеширования используется криптографическая функция BLAKE3. Она вносит весомый вклад в потребление CPU при обработке запроса на запись. В случае, если клиент готов ради экономии CPU пожертвовать глобальной уникальностью (например, для короткоживущих данных в небольших инсталляциях хранилища), он может выбрать более быстрые хеш-функции, не обладающие свойством криптографической стойкости.
Второй способ дедупликации несёт значительно меньше накладных расходов, но требует более глубокого вовлечения клиента. Внутрь версии документа встроена очень компактная структура счётчика копий (copy counter). Клиенту DOS предоставляются методы для проверки наличия версии документа и модификации её счётчика копий. Если бизнес-логика клиента позволяет выявить ранее записанную версию, то её повторная запись сводится лишь к дешёвой операции инкремента счётчика копий. В почтовой системе именно так реализовано сохранение «партов» письма: клиент использует хеш от содержимого «парта» для построения идентификатора документа, проверяет наличие документа с таким идентификатором и при его наличии просто увеличивает счётчик копий нужной версии на единицу. Иммутабельность данных версии документа даёт гарантию того, что все накопленные инкременты счётчика копий версии относились к одним и тем же данным.
Дедупликация на уровне версий документов фактически обеспечивает ещё один (очень экономичный) вариант записи, при котором оптимизируется не только дисковое пространство и операции ввода-вывода, но ещё и CPU и RAM, а также снижается нагрузка на сеть за счёт облегчения запросов.

Рис. 3. Два уровня дедупликации данных в DOS.
Отказоустойчивость
Если сегмент существует в единственном экземпляре, то что произойдёт в случае его потери? Если диск, на котором хранится популярный сегмент выйдет из строя, будет ли это означать невозможность чтения всех ссылающихся на него версий?
Для борьбы с этой проблемой в хранилищах самых разных классов (компакт-диски, RAID-массивы, промышленные СХД) традиционно используются коды коррекции ошибок. Наибольшую популярность получили коды Рида-Соломона (Подробнее в статьях на Хабре: 1, 2, 3).
В DOS во время записи чанк разбивается на заданное количество сегментов равного размера (data segments, d). С помощью кодирования Рида-Соломона из сегментов данных генерируются избыточные сегменты (parity segments, p). При потере любые p из d + p сегментов могут быть восстановлены из имеющихся d с помощью обратной операции. Таким образом, отказоустойчивость приобретается путём дополнительных расходов дискового пространства. Конкретные значения параметров определяются на этапах внедрения и эксплуатации системы. Исходя из потребностей в отказоустойчивости инсталляции, пользователи могут выбирать между стоимостью хранения и возможностью восстановления (часто встречаются комбинации d + p = 2 + 1 и d + p = 5 + 2).
Для гарантии восстановления каждого чанка DOS размещает все входящие в его состав сегменты на бэкенды, которые находятся на независимых HDD. Таким образом, при выходе из строя одного диска не произойдет повреждение сразу нескольких сегментов одного чанка.
При чтении чанка выполняется вычитывание не только сегментов данных, но и избыточных сегментов. Если какие-то из сегментов оказались потеряны, удалены, либо была нарушена их целостность, выполняется попытка их регенерации и повторного сохранения.
Конечно, коды Рида-Соломона могут спасти далеко не всегда. Поэтому в DOS имплементирован ещё один способ восстановления данных: при запросе на инкремент счётчика копий клиент может получить ответ о том, что версия была повреждена и что надо заново записать точно такую же. В этом случае вновь записанная версия восстановит старые поврежденные.
Отдельного рассмотрения требует тема отказоустойчивости метаданных. Мы вернёмся к ней позже в публикациях, посвящённых кластеру DOS.
Конвейерная обработка данных
Во время обработки запроса на запись DOS буферизует первые несколько килобайт из входящего потока и отправляет их в библиотеку сигнатурного анализа файлов. Оттуда хранилище получает вычисленный MIME-тип данных. В контексте DOS все возможные MIME-типы подразделяются на группы форматов. Для каждой из групп в DOS организован отдельный конвейер преобразований (pipeline) и разные оптимизации.
Текстовые данные хорошо сжимаются. Для некоторых текстов с помощью алгоритмов ZSTD, Snappy, Brotli удаётся добиться более чем двукратного сжатия. Это существенная экономия дискового пространства и операций ввода-вывода, и она стоит дополнительных затрат CPU на компрессию и декомпрессию.
Для текстовых данных также можно повысить вероятность обнаружения дубликатов с помощью алгоритма content-defined chunking (CDC). Сущность алгоритма заключается в вычислении хеша Рабина в небольшом окне, скользящем по входящему потоку данных. В позициях, на которых вычисленный хеш принимает определённое значение, ставится граница между чанками. В результате поток разбивается на небольшие чанки разных размеров, однако при этом повышается вероятность обнаружения аналогичных чанков в других версиях с частично совпадающим содержимым.
В отношении данных бинарных форматов, по которым нет понимания, как правильно организовать оптимизацию, применяется подход к работе с обычной байтовой последовательностью. Такой поток данных быстро разбивается на крупные чанки одного размера и в неизменённом виде отправляется на хранение в бэкенд.

Рис. 4. Различия в конвейерной обработке бинарных и текстовых данных в DOS.
Таким образом, конвейер для бинарных данных настроен на повышение пропускной способности сервера и на снижение времени отклика. А конвейер текстовых данных оптимизирует уровень потребления дискового пространства и IOPS ценой повышенного потребления CPU. Насколько же эффективны эти оптимизации?
Производительность конвейерной обработки данных
Мы выполнили эксперименты с помощью генератора текстов, созданного коллегами из отдела разработки поискового ядра, и показали, что для характерного в корпоративной среде потока данных можно достичь примерно двукратного сокращения потребления дискового пространства.
Параметры эксперимента
В систему сохраняется 10000 писем. Письма состоят только из текста и не включают в себя какие-либо бинарные объекты. Медианный размер письма около 500 Кб. При этом 70% писем имеют 50% совпадающих данных, остальные полностью уникальны. Полностью эквивалентные письма отсутствуют, поскольку они дедуплицировались бы на уровне счётчиков копий и сильно завысили бы итоговый результат. Настройки кодирования Рида-Соломона d + p = 2 + 1, избыточность данных составляет 50%.
Результат эксперимента
При прохождении через текстовый конвейер объем данных изменяется следующим образом: Входящий поток разделяется на чанки и компрессируется со средним коэффициентом сжатия 2.3. Затем кодирование Рида-Соломона увеличивает количество данных в 1.5 раза. Дедупликация cегментов (блочная дедупликация) снижает полученный с учётом избыточности объем данных в 1.17 раза.
Итоговое отношение записанных данных к хранимым данным составляет 2.3 * 1.17 / 1.5 = 1.79. При этом в нашей модели количество метаданных составляет 0.2% от количества данных, однако этот показатель очень вариативен и сильно зависит как от настроек конвейера, так и от характера и количества самих данных.
Удаление данных
В условиях совместного владения сегментами удаление версии документа становится нетривиальной операцией. Её нужно проводить очень аккуратно, чтобы, с одной стороны, не удалить данные, которые ещё кому-то нужны, а с другой — не допустить утечек дискового пространства. Связи между всеми сущностями в DOS можно представить в виде большого ациклического ориентированного графа, в котором начальными вершинами являются документы, а конечными вершинами — сегменты. Также есть и промежуточный уровень версий документов. Для каждой из сущностей действуют свои правила удаления: Документ удаляется, если не содержит версий. Версия документа удаляется, если её счетчик копий равен нулю либо истекло время её жизни (TTL). Сегмент удаляется, если не имеет ссылок со стороны версий документов.
Клиент напрямую работает лишь с версиями документов; доступный клиенту метод удаления позволяет декрементировать счётчик копий у конкретной версии. Далее в действие приходят два асинхронных сборщика мусора (GC), один из которых проходит по индексу документов, а другой — по индексу сегментов. GC документов удаляет версии с обнулённым счётчиком копий или истекшим TTL, собирает пустые документы и очищает счётчики ссылок сегментов от идентификаторов удаляемых версий. GC сегментов удаляет сегменты с пустыми счётчиками ссылок. Оба GC запускаются в фоновом режиме в периоды, свободные от пользовательской нагрузки.

Рис. 5. Иллюстрация работы сборщиков мусора (1 — граф связей в исходном состоянии; 2 — клиент декрементирует до нуля счётчик копий у одной из версий; 3 — GC документов удаляет версию и владеющий ей документ, GC сегментов удаляет сегмент без ссылок; 4 — граф связей в итоговом состоянии).
Заключение
Хранение больших объёмов электронной почты — крайне непростая и ресурсоёмкая задача. Однако производительность и экономическую эффективность почтовой системы можно значительно увеличить, если реализовать дедупликацию и компрессию электронных писем. Если вам близка эта тема, и вы тоже хотите создавать уникальные российские программные продукты, то приходите на работу в МойОфис. Прямо сейчас нашей команде требуется разработчик бэкенда — откликайтесь, возможно, это именно вы.
В этой статье мы рассмотрели ключевые оптимизации, которые реализованы в объектном хранилище DOS. В дальнейших публикациях мы продолжим описание его архитектуры, а сейчас будем рады обсудить с вами возникшие вопросы в комментариях.
ссылка на оригинал статьи https://habr.com/ru/company/ncloudtech/blog/530722/
Добавить комментарий