Интеграция сопровождалась борьбой буквально с каждой миллисекундой задержки, апгрейдом инфраструктуры и разработкой технологий доставки контента, которым нам пришлось самостоятельно придумывать названия. Рассказываем, с чем мы столкнулись в ходе работ, что получилось в итоге и зачем это пользователям.

Зачем вообще интегрировать облако с CDN
В первую очередь публичное облако — это масштабируемые мощности. Их можно использовать как угодно: для разработки и тестирования сервисов, а также хранения и обработки данных. Мы в G-Core Labs запустили облако в прошлом году и уже успели задействовать его в высоконагруженных проектах. Например, наш давний клиент — Wargaming — использует это решение сразу для нескольких задач:
- Тестирование новых фич и сервисов разных проектов;
- Подготовка тестовых прототипов с внешними разработчиками, которым нужен доступ к изолированным настраиваемым и контролируемым ресурсам;
- Работа онлайн-игры «Калибр» на виртуальных машинах.
Со всем перечисленным облако справляется на ура, но работа на этом не заканчивается. Для чего бы ни были задействованы те или иные мощности, результат их работы ещё нужно доставить до точки назначения. О чём бы ни шла речь — об онлайн-игре или настоящих военных соединениях — тут-то и возникает проблема: что многотонную боевую технику, что тяжёлые данные быстро доставлять в удалённые регионы крайне непросто. Упростить эту задачу позволяет интеграция облака с сетью доставки контента. С помощью CDN транспортабельную часть — статические данные — можно забросить «по воздуху» прямо к точке назначения, а из облака лишь останется отправить «негабаритные» динамические данные. С таким подходом можно смело начинать работу даже на других континентах, так как интеграция позволяет быстрее конкурентов доставлять тяжёлый контент по всему миру.
Сокращай, распределяй, ускоряй: как CDN помогает облаку
Перейдём к конкретике. Мы не понаслышке знаем, что доставлять тяжёлый контент в удалённые регионы прямо из облака выходит долго, а постоянно увеличивать мощность инфраструктуры согласно росту нагрузки бывает накладно. К счастью, помимо публичного облака у нас оказалась и своя CDN, которая даже вошла в Книгу рекордов Гиннеса, обеспечив бесперебойный опыт игры в World of Tanks в период пиковой нагрузки.
Чтобы убить двух зайцев одним выстрелом, нам нужно было интегрировать её с облаком. Тогда мы смогли бы предложить пользователям решение, которое обойдётся дешевле апгрейда инфраструктуры и позволит быстрее отдавать данные в удалённые регионы. Так мы приступили к первой фазе работ и решили ключевые проблемы:
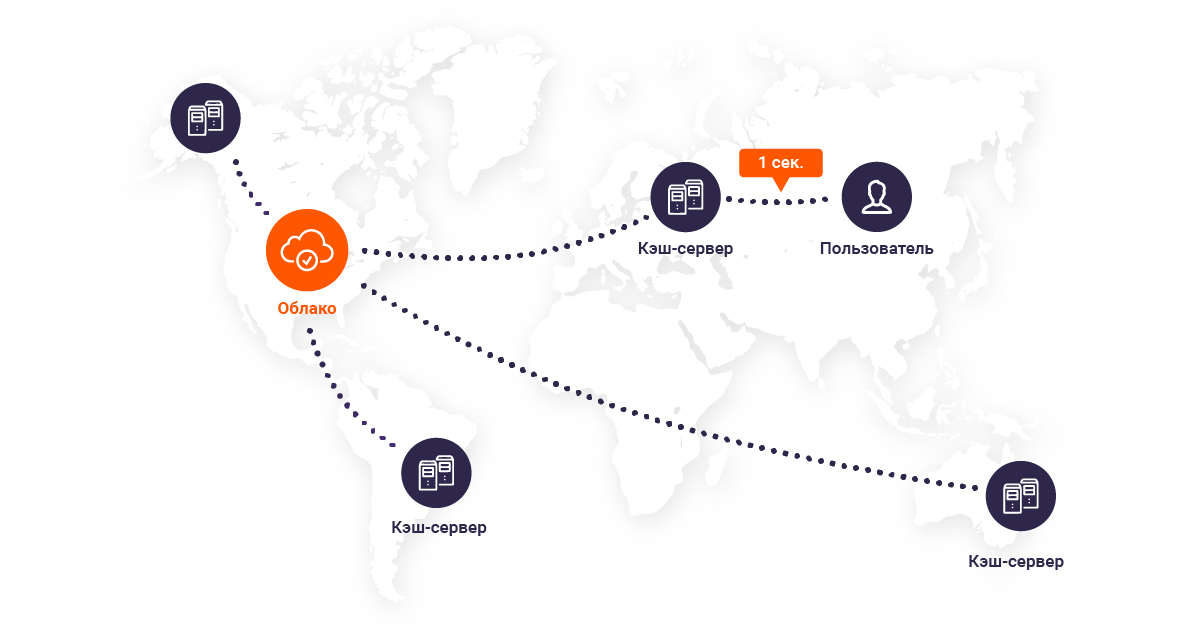
1. Облачные сервисы находились под постоянной нагрузкой. Пользователи высоконагруженных проектов регулярно запрашивали контент из облаков наших клиентов. Это приводило к высокой нагрузке и долгой отдаче данных. Требовалось решение, которое позволило бы легко сократить количество обращений к источнику. Для этого мы интегрировали серверы публичного облака и кеш-серверы CDN, а также сделали единый интерфейс управления этими сервисами. С его помощью пользователи могут выносить статические данные в нужные точки присутствия сети. Благодаря этому обращения к облаку происходят только при первых запросах контента. Работает это стандартно: CDN забирает данные у источника и отправляет их пользователю, а также ближайшему к нему кеш-серверу, откуда контент и раздаётся при последующих запросах;
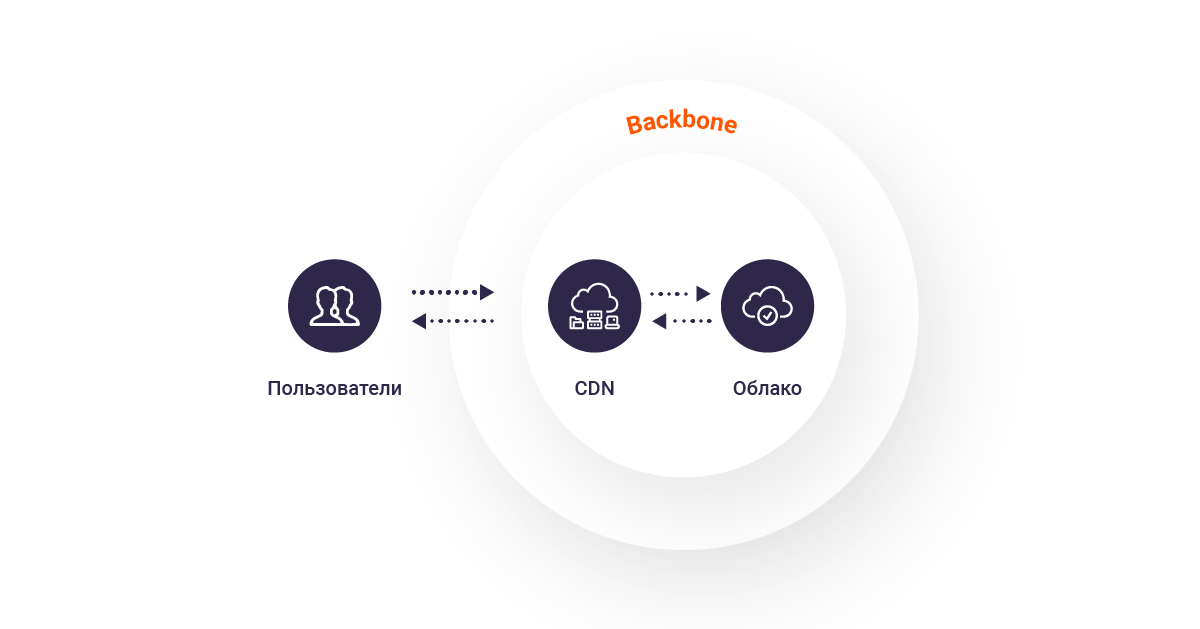
2. Данные долго передавались между облаком и CDN. Объединив облако с сетью доставки контента, мы заметили, что задержка при доставке данных могла бы быть меньше. Чтобы сохранить как можно больше драгоценных миллисекунд, пришлось реализовать обмен трафиком между кеш-серверами и облаком внутри опорной сети (backbone);
3. Нагрузка на источник оказывалась неравномерно. Даже после подключения CDN оставшиеся обращения к облаку распределялись неэффективно. Мы исправили это с помощью HTTP(S)-балансировщиков. Теперь в момент запроса контента они определяют из какого именно источника (виртуальной машины или бакета облачного хранилища) следует забирать данные для кеширования;
4. Тяжёлый контент долго шёл до пользователей. Чтобы сократить время ожидания, мы постоянно наращивали мощность и географию присутствия CDN. Теперь пользователям уже не приходится ждать, пока контент дойдёт до них через полмира — в момент обращения сеть доставки контента выбирает ближайшую из 100 точек присутствия на пяти континентах. В результате среднее время отклика по всему миру находится в пределах 30 мс.
Разобравшись с этими проблемами, мы уже было посчитали работу законченной. Но у облака с CDN на нас были иные планы.
Так закалялась сталь: модернизируем инфраструктуру
В один момент стало понятно, что эффект от всех наших усилий не мог проявиться в полной мере, пока мы использовали старую аппаратную конфигурацию. Чтобы серверы и размещённые на них приложения работали лучше, а контент передавался быстрей, требовался апгрейд инфраструктуры. Звёзды на небе сошлись в начале этого года: мы принялись за модернизацию, как только вышла линейка масштабируемых процессоров Intel Xeon Scalable второго поколения.
Сейчас стандартная конфигурация серверов выглядит следующим образом:
- Облачные сервисы работают на процессорах Intel Xeon Gold 6152, 6252 и 5220, имеют до 1 ТБ RAM, а также SSD и HDD с тройной репликацией;
- Кеш-серверы CDN оснащены Intel Xeon Platinum, виртуальными RAID на CPU и SSD D3-S4610.
В результате апгрейда производительность выросла настолько, что мы отказались от части серверов и сократили затраты на их эксплуатацию. Казалось, всего перечисленного с лихвой хватит для работы любого проекта. Но однажды и этого оказалось совсем недостаточно.
Шилдинг, шардинг и геораспределение: ускоряем доставку контента в экстремальных условиях
Беда не приходит одна. Это особенно актуально, когда речь идёт о глобальных проектах. Отсутствие географически распределённой инфраструктуры, высокие нагрузки из-за множества пользователей со всего мира и море разнородных данных, которые им нужно быстро доставлять, — одному нашему клиенту, крупному медиаресурсу, нужно было разом разобраться со всеми этими сложностями. Немного подробностей:
- Контент долго шёл до пользователей, а иногда и вовсе до них не доходил из-за высоких задержек и проблем в сети. Сложность заключалась в том, что весь большой пул серверов с данными размещался в одной географической точке;
- К источнику контента обращались пользователи со всего мира, что вызывало повышенную нагрузку на инфраструктуру и приводило к дороговизне обслуживания, а также медленной отдаче данных;
- Пользователям требовалось доставлять огромное количество постоянно пополняемого контента, уникального для каждого региона.
Базовыми возможностями интеграции облака с CDN тут было не обойтись. Мы взялись за разработку дополнительных решений.
Как мы придумали «региональный шилдинг»
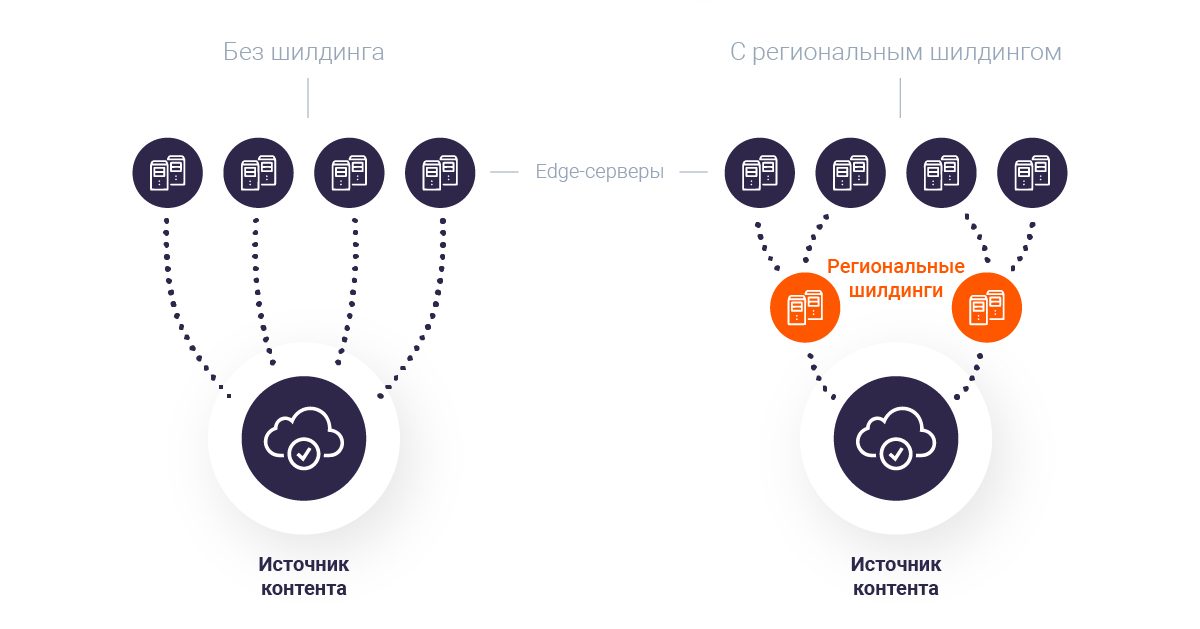
Это понятие, а теперь уже и действующую услугу, мы ввели специально для решения проблемы с удалённостью источника контента. Из-за того, что все серверы клиента находились в одной географической точке, данные от них долго добирались до пользователей из разных частей света. Ситуацию усложнял тот факт, что в разные регионы нужно было доставлять разный, постоянно пополняемый контент. Простое кеширование данных на edge-серверах проблему бы не устранило — они бы всё равно часто обращались к источнику через полмира.
Мы решили задачу, развернув большой пул кеш-серверов в популярных точках обмена трафика на разных континентах. «Региональные шилдинги» стали своеобразными прослойками между источником и edge-серверами в странах пользователей. Теперь весь востребованный в соответствующих частях света контент сначала попадал на них, а затем передавался кеш-серверам. Таким образом шилдинги разом снизили нагрузку на источник клиента и сократили задержки до конечных пользователей. Клиент, в свою очередь, сэкономил на размещении нескольких пулов серверов с одинаковым контентом в разных частях света, так как при таком принципе работы достаточно было одного источника данных.
Зачем понадобилось шардирование контента
Проблему долгой доставки контента в разные части света региональные шилдинги решили сполна. Однако, теперь возникла новая сложность: поскольку данных у клиента было много и они постоянно обновлялись, их то и дело не оказывалось в кеше edge-серверов, к которым обращались пользователи. Это приводило к тому, что на региональные пулы постоянно сыпалась масса запросов от кеш-серверов, число которых в одной группе достигало 20–30 штук. Чтобы снять с шилдингов часть этой нагрузки и доставлять контент пользователям ещё быстрей, мы добавили возможность забирать нужные данные у ближайшего edge-сервера в пуле.
Теперь кеш-серверы в регионах присутствия начали обращаться к шилдингам лишь тогда, когда данных не оказывалось во всей группе. Причём даже в этих случаях контент сразу же запрашивался именно у того сервера, который его содержал — благодаря шардингу edge-серверы заранее «знали» где лежит конкретный файл, а не опрашивали для этого весь пул региональных шилдингов. Такой принцип работы снизил количество запросов к пулу и позволил эффективно распределять контент по нему вместо того, чтобы хранить копии данных на каждом сервере. В результате шилдинги вмещали больше контента и как следствие оказывали меньшую нагрузку на источник клиента.

Создание такой инфраструктуры не могло не повлечь за собой ещё одной сложности. Учитывая количество кеш-серверов в группах, было бы глупо предположить, что ни один из них не может выйти из строя. В такой ситуации, как и в случае добавления в пул нового сервера, кеш в группах нужно было перераспределять оптимальным образом. Для этого мы реализовали организацию шардированного кеша с алгоритмом консистентного хеширования в блоке upstream в nginx:
upstream cache_servers { hash $cache_key consistent; server edge1.dc1.gcorelabs.com; server edge2.dc1.gcorelabs.com; server edge3.dc1.gcorelabs.com; } Появление в пуле недоступных серверов также было чревато ещё одной проблемой: другие серверы продолжали посылать к ним запросы и ожидали ответа. Чтобы избавиться от этой задержки, мы написали алгоритм обнаружения таких серверов в пуле. Теперь, благодаря тому что они автоматически переводятся в состояние down в upstream-группе, мы больше не обращаемся к неактивным серверам и не ждём от них данных.
В результате этих работ мы снизили стоимость услуг для клиента, избавили его от серьёзных затрат на организацию собственной инфраструктуры и существенно ускорили доставку данных до пользователей, несмотря на все сложности.
Кому пригодилось облако с CDN
Работы по интеграции позади, а продуктом уже пользуются наши клиенты. Делимся, кто из них получает от этого наибольшую отдачу.
Скажем сразу, что решение пригодилось не всем. Другого мы и не ждали: кому-то достаточно одного лишь хранилища и виртуальных машин, а кому-то — сети доставки контента. Например, когда вся аудитория у проекта находится в одном регионе, CDN к облаку подключать практически незачем. Для минимизации задержек в этом случае хватит сервера, расположенного неподалёку от пользователей.
Во всей красе интеграция раскрывается, когда нужно быстро и далеко отдавать тяжёлый контент большому количеству пользователей. Вот пара примеров того, как облако с CDN помогает разным проектам:
- Стриминговые сервисы, критичные к задержкам и буферизации, добиваются стабильной работы и высокого качества трансляций;
- Сервисы онлайн-развлечений быстрее доставляют тяжёлые игры в разные точки мира и снижают нагрузку на серверы, в том числе при пиковых нагрузках;
- Медиапроекты ускоряют загрузку рекламы и сохраняют доступность при всплесках посещаемости;
- Интернет-магазины быстрее загружаются в разных странах, в том числе во время акций и распродаж.
Мы продолжаем наблюдать за тем, как именно они используют облако с CDN. Нам, как и вам, интересны цифры: как сильно снижается нагрузка на инфраструктуру, насколько быстрее пользователи получают контент в конкретных регионах и как сильно интеграция помогает сэкономить. Всем этим мы поделимся в будущих кейсах.
ссылка на оригинал статьи https://habr.com/ru/company/gcorelabs/blog/532534/
Добавить комментарий