
В этой статье я хотел бы познакомить сообщество с библиотекой JPAstreamer. Идея этой библиотеки очень проста, но в то же время гениальна — получать нужные нам сущности из бд так, как если бы мы просто обрабатывали поток сущностей в стриме.
Если интересно посмотреть, что может библиотека, то прошу под кат.
Итак, у нас есть проблема — в нашем приложении мы используем JPA и мы хотим каким-либо образом выполнять селекты на БД более эффективно. При этом хотелось бы интуитивно понятный интерфейс, такой как в Stream API.
Для решения подобной задачи были придуманы следующие технологии — Hibernate Query Language (HQL) и Java Persistence Query Language (JPQL). Но они предлагают довольно запутанные методы решения проблемы, которые не очень понятны сразу.
С библиотекой JPAstreamer подход к получению сущностей меняется. Она позволяет нам в stream-like манере записать наш селект для сущностей, который впоследствии будет выполнен на базе.
Давайте рассмотрим по порядку как это происходит.
Под капотом JPAstreamer использует annotation processor, такой же как, например, в lombok. Во время компиляции он анализирует наш код на наличие в нем JPA сущностей и генерирует для них метамодель. То есть если в нашем коде есть класс Book помеченный аннотацией @Entity для него будет генерировать класс Book$ с метамоделью. Найти этот класс можно тут — target/generated-sources/annotations, либо, если вы используете gradle — build/generated/sources/annotationProcessor.
Зачем нужны метамодели?
Так как в итоге мы хотим работать только с интерфейсом Stream, то мы должны дать понять библиотеке в какой момент мы передаем информацию о селекте и в какой момент мы уже обрабатываем полученный результат. Поэтому на основе нашей сущности создается метамодель, где присутствует описание каждого поля.
Соответственно, когда мы работаем с полями метамодели — мы описываем правила селекта сущностей. Когда же мы используем поля сущности — мы уже работаем с результатом, который вернул селект.
Собственно, рассмотрим это на примере. Для этого я создам проект на Spring Boot и добавлю в него пару сущностей.
Добавим в наш проект зависимости:
implementation 'com.speedment.jpastreamer:jpastreamer-core:1.0.2' annotationProcessor "com.speedment.jpastreamer:fieldgenerator-standard:1.0.2" implementation 'com.speedment.jpastreamer.integration.spring:spring-boot-jpastreamer-autoconfigure:1.0.2' Далее создаем сущности:
@Entity public class Book { @Id private UUID id; private String title; private int price; @ManyToOne(fetch = FetchType.LAZY) private Author author; } @Entity public class Author { @Id private UUID id; private String name; @OneToMany(mappedBy = "author") private Set<Book> books; } Сгенерированные библиотекой классы будут выглядеть так:
public final class Author$ { /** * This Field corresponds to the {@link Author} field name. */ public static final StringField<Author> name = StringField.create( Author.class, "name", Author::getName, false ); /** * This Field corresponds to the {@link Author} field id. */ public static final ComparableField<Author, UUID> id = ComparableField.create( Author.class, "id", Author::getId, false ); /** * This Field corresponds to the {@link Author} field books. */ public static final ReferenceField<Author, Set<Book>> books = ReferenceField.create( Author.class, "books", Author::getBooks, false ); } Теперь рассмотрим несколько примеров использования библиотеки.
Пример кода я загрузил на сюда.
Для того, чтобы получить все сущности просто выполним код:
var books = jpaStreamer.stream(Book.class).toList();Теперь попробуем отфильтровать книги старше 2020 года.
var books = jpaStreamer.stream(Book.class) .filter(Book$.year.greaterOrEqual(2020)) .toList();В консоли мы увидим следующий запрос:
Hibernate: select book0_.id as id1_1_, book0_.author_id as author_i5_1_, book0_.price as price2_1_, book0_.title as title3_1_, book0_.year as year4_1_ from book book0_ where book0_.year>=?А если фильтр сделать не через класс метамодели?
var books = jpaStreamer.stream(Book.class) .filter(x -> x.getYear() >= 2020) .toList();Получим в результате вывод на консоль следующего запроса:
Hibernate: select book0_.id as id1_1_, book0_.author_id as author_i5_1_, book0_.price as price2_1_, book0_.title as title3_1_, book0_.year as year4_1_ from book book0_Собственно, в данном случае мы уже использовали результат селекта при фильтрации, поэтому нужно обязательно использовать поля метамодели для создания эффективного селекта.
Мы можем комбинировать селекты:
var books = jpaStreamer.stream(Book.class) .filter(Book$.year.greaterOrEqual(2020)) .filter(Book$.price.in(1000.0, 1700.0)) .toList();Сортировать:
var books = jpaStreamer.stream(Book.class) .sorted(Book$.price) .toList();Соответственно запрос в БД:
Hibernate: select book0_.id as id1_1_, book0_.author_id as author_i5_1_, book0_.price as price2_1_, book0_.title as title3_1_, book0_.year as year4_1_ from book book0_ order by book0_.price ascСортировки можно делать и более сложные:
jpaStreamer.stream(Book.class) .sorted(Book$.price.reversed().thenComparing(Book$.title.comparator())) .toList();Мы также можем выполнять операции пагинации с помощью методов skip и limit:
var books = jpaStreamer.stream(Book.class) .sorted(Book$.price) .skip(3) .limit(3) .toList();Запрос в БД:
Hibernate: select book0_.id as id1_1_, book0_.author_id as author_i5_1_, book0_.price as price2_1_, book0_.title as title3_1_, book0_.year as year4_1_ from book book0_ order by book0_.price asc limit ? offset ?Мы можем создавать и более сложные запросы, например выполнять операцию JOIN.
Для начала получим авторов всех книг:
var authors = jpaStreamer.stream(Book.class) .map(Book::getAuthor) .toList();На консоли увидим:
Hibernate: select author0_.id as id1_0_0_, author0_.name as name2_0_0_ from author author0_ where author0_.id=? Hibernate: select author0_.id as id1_0_0_, author0_.name as name2_0_0_ from author author0_ where author0_.id=? Hibernate: select author0_.id as id1_0_0_, author0_.name as name2_0_0_ from author author0_ where author0_.id=? Hibernate: select author0_.id as id1_0_0_, author0_.name as name2_0_0_ from author author0_ where author0_.id=? Hibernate: select author0_.id as id1_0_0_, author0_.name as name2_0_0_ from author author0_ where author0_.id=?Это не есть хорошо 🙂 Решим эту проблему через joining:
var configuration = StreamConfiguration.of(Book.class) .joining(Book$.author); var authors = jpaStreamer.stream(configuration) .map(Book::getAuthor) .toList();Теперь все работает замечательно.
Конфигурации JOIN можно настраивать — для этого есть перечисление:
public enum JoinType { /** Inner join. */ INNER, /** Left outer join. */ LEFT, /** Right outer join. */ RIGHT }Стоит упомянуть, что авторы в документации сделали приятную таблицу со списком операций SQL и их маппингом на стримы:
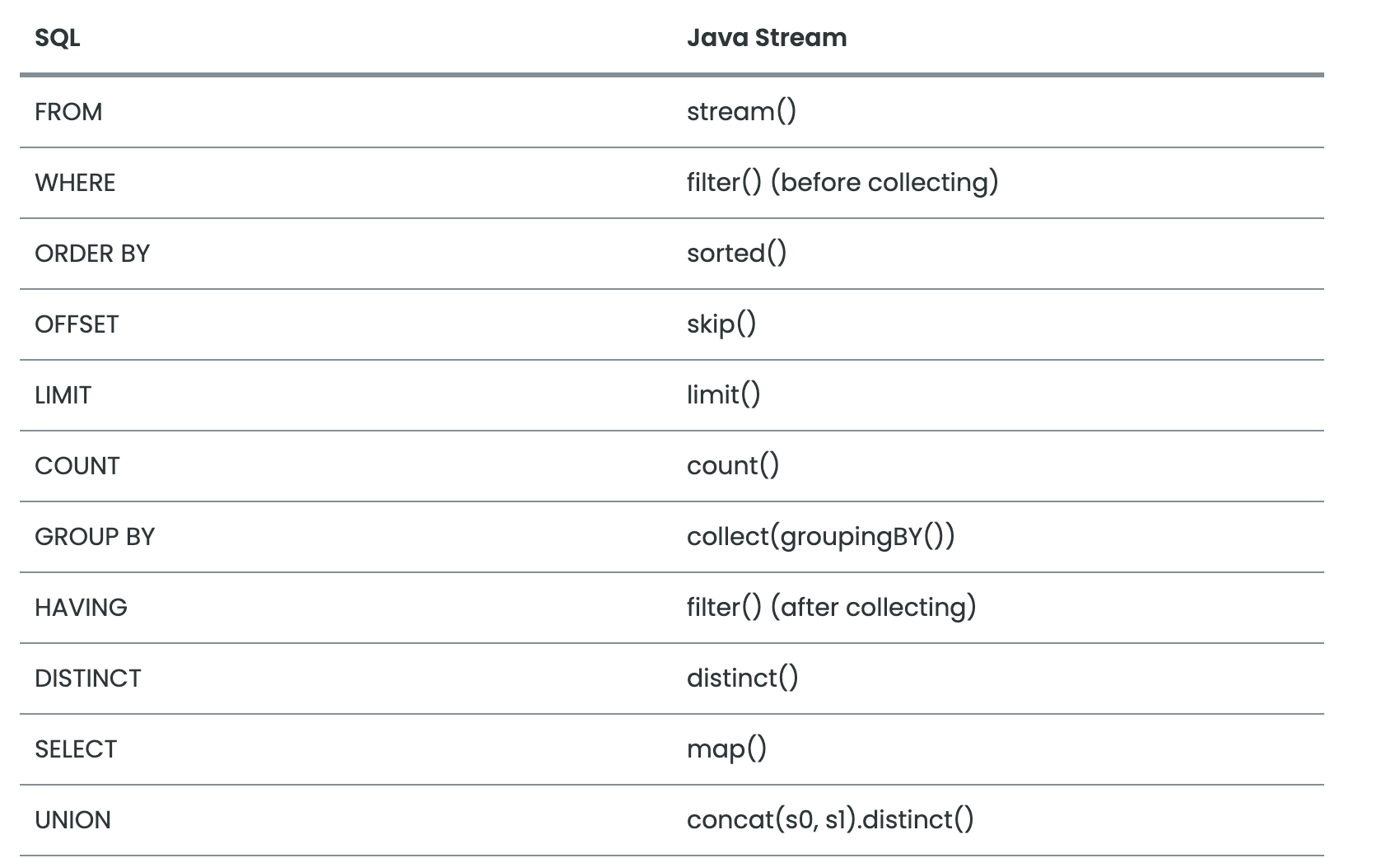
Заключение
Я очень люблю стримы и эта библиотека стала для меня приятным открытием. На мой взгляд, она позволяет более прозрачно и просто описывать нужную нам логику для запросов в БД. А это в свою очередь ведет к более надежным и легко поддерживаемым приложениям. Спасибо за внимание!
ссылка на оригинал статьи https://habr.com/ru/post/568794/
Добавить комментарий