
Вступление
Однажды я подумал, насколько трудно и дорого в наши дни сделать голосового помощника, который будет впопад отвечать на вопросы.
А если конкретнее, то веб-приложение, которое записывает аудио с вопросом, расшифровывает аудио в текст, находит подходящий ответ, тоже текстовый, и возвращает аудио версию ответа — вот функциональные требования, который я себе набросал.
Клиентская часть
Я создал простой React проект с помощью create-react-app и добавил компонент “RecorderAndTranscriber”, который и содержит весь функционал клиентской части. Стоит отметить использование метода getUserMedia из MediaDevices API чтобы получить доступ к микрофону. Дальше этот доступ достаётся MediaRecorder, через который уже и записывается аудио. Для таймера я использую setInterval.

Пустой массив необязательным параметром в React hook — useEffect, чтобы он вызывался только раз, при создании компонента.
useEffect(() => { const fetchStream = async function() { const stream = await navigator.mediaDevices.getUserMedia({ audio: true }); setRecorderState((prevState) => { return { ...prevState, stream, }; }); } fetchStream(); }, []);Сохранённый поток используем для создания экземпляра MediaRecorder, который я тоже сохраняю.
useEffect(() => { if (recorderState.stream) { setRecorderState((prevState) => { return { ...prevState, recorder: new MediaRecorder(recorderState.stream), }; }); } }, [recorderState.stream]);Дальше я добавил блок для запуска счётчика секунд, прошедших с начала записи.
useEffect(() => { const tick = function() { setRecorderState((prevState) => { if (0 <= prevState.seconds && 59 > prevState.seconds) { return { ...prevState, seconds: 1 + prevState.seconds, }; } else { handleStop(); return prevState; } }); } if (recorderState.initTimer) { let intervalId = setInterval(tick, 1000); return () => clearInterval(intervalId); } }, [recorderState.initTimer]);Hook срабатывает только при изменении значения initTimer, а callback для setInterval обновляет значение счётчика и останавливает запись если длина записи 60 секунд. Дело в том, что 60 секунд и/или 10Mb это ограничение Speech-to-Text API на аудио файлы, которые можно расшифровать, отправляя файлы напрямую. Большие файлы нужно сначала загружать в файловое хранилище Google Cloud Storage. Подробнее про ограничения можно прочитать тут.
Следующий момент, который стоит упомянуть, это как происходит запись.
const handleStart = function() { if (recorderState.recorder && 'inactive' === recorderState.recorder.state) { const chunks = []; setRecorderState((prevState) => { return { ...prevState, initTimer: true, }; }); recorderState.recorder.ondataavailable = (e) => { chunks.push(e.data); }; recorderState.recorder.onstop = () => { const blob = new Blob(chunks, { type: audioType }); setRecords((prevState) => { return [...prevState, { key: uuid(), audio: window.URL.createObjectURL(blob), blob: blob } ]; }); setRecorderState((prevState) => { return { ...prevState, initTimer: false, seconds: 0, }; }); }; recorderState.recorder.start(); } }Для начала я проверяю, что экземпляр класса MediaRecorder существует и его статус inactive, один из трёх возможных. Дальше обновляется переменная initTimer, чтобы создать и запустить interval. Чтобы контролировать запись я подписался на обработку двух событий ondataavailable и onstop. В обработчике для ondataavailable сохраняется новый кусочек аудио в заранее созданный массив. А по срабатыванию onstop, из кусочков создаётся blod файл и добавляется к списку готовых записей. В объекте записи я сохраняю url на аудио файл, чтобы использовать в DOM элементе audio, как значение для src, а поле blob, чтобы отправлять на серверную часть.
Серверная часть
Для поддержания работы клиентской части я выбрал связку Node.js и Express. Создал файл index.js, в котором и собрал API с методами:
а) getTranscription(audio_blob_file)
б) getWordErrorRate(text_from_google, text_from_human)
с) getAnswer(text_from_google)
Чтобы вычислить Word Error Rate я взял скрипт на python из проекта tensorflow/lingvo и переписал его в js. По сути это просто решение задачи Edit Distance, плюс расчёт ошибки по каждому из трёх типов: удаление, добавление, замена. Я получил не самый интеллектуальный метод сравнения текстов, но достаточный, чтобы в дальнейшем можно было добавлять дополнительные параметры к запросам к Speech-to-Text.
Для getTranscription я взял готовый код из документации к Speech-to-Text, а для перевода текста ответа в аудио файл — из документации к Text-to-Speech. Немного запутанным оказалось создание ключа доступа к google cloud с серверной части. Для начала нужно было создать проект, потом включить Speech-to-Text API и Text-to-Speech API, создать ключ доступа и, наконец, добавить путь к ключу в переменную GOOGLE_APPLICATION_CREDENTIALS.
Чтобы json файл с ключом, нужно создать Service account для проекта.

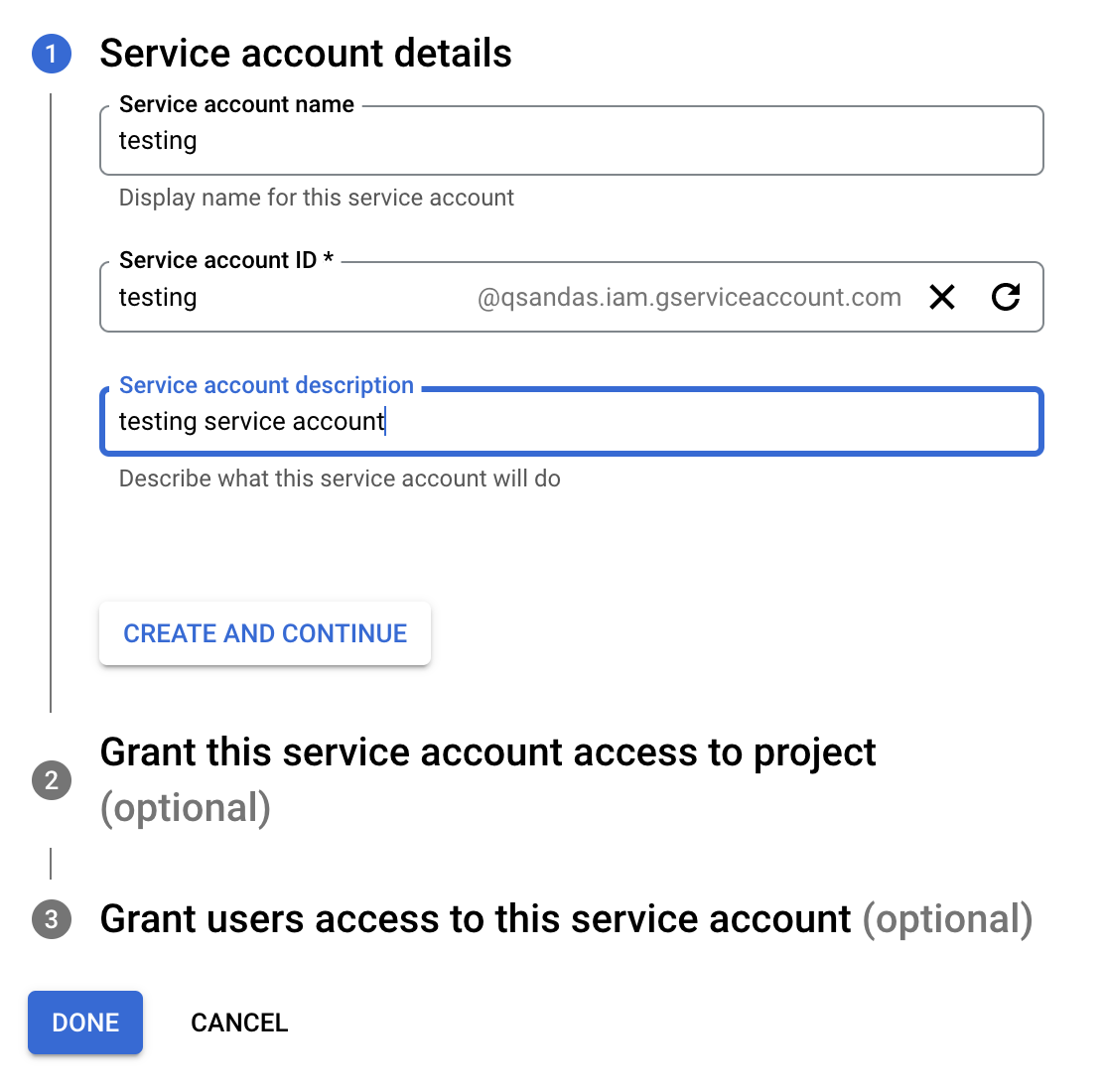
После нажатия Create and Continue и Done во вкладке Credentials, в таблице Service Accounts появиться новый аккаунт. Если перейти в этот аккаунт, на вкладке Keys можно нажать на Add Key, и получить json-файл с ключом. Этот ключ необходим, чтобы серверная часть могла получить доступ к Google Cloud сервисам, активированным в проекте.
На этом предлагаю закончить первую часть. Описание базы данных и моих экспериментов с ненормативной лексикой будет во второй части статьи.
ссылка на оригинал статьи https://habr.com/ru/post/655653/
Добавить комментарий