Если у Вас есть данные о связях людей в XML формате, то пора применять графовую аналитику.

Вы наверняка часто слышали об XML и вам известно хотя бы одно приложение, экспортирующее данные в этот формат. XML имеет большую совместимость и благодаря этому применяется для обмена данными между базами данных и пользовательскими компьютерами. Но как именно с ним работать и анализировать? В этой статье разберем практическую задачу с экспортированными данными в XML и визуализацией этих данных.
Некоторое время назад пришлось столкнуться с большим количеством данных контактов людей, полученных с мобильных телефонов. Для анализа данные были экспортированы в XML формат. Данные необходимо было проанализировать на наличие связей между людьми. В данном случае связью считалась запись контакта в мобильном телефоне. Зачастую все мошеннические схемы и преступные действия, производимые при помощи мобильных телефонов, а также с использованием транзакций в банке, производимых по номеру телефона, можно отследить по хранящимся данным, и для анализа возможно применение графовой аналитики. В случае признания судом тех или иных лиц преступниками не всегда возможно определить всех причастных лиц при помощи обычных методов анализа.
Перейдем к анализу социальных сетей. Сеть в простейшем виде представляет собой набор точек, соединенных попарно линиями. Точки называются вершинами или узлами, а линии — ребрами. Большинство реальных сетей, таких как транспортные, социальные или компьютерные сети, являются сложными. Социальная сеть, как правило, представляет собой сеть людей, хотя иногда это может быть сеть групп людей, таких как компании. Люди или группы образуют вершины сети, а края представляют собой какие-то связи между ними, например, дружба между людьми или деловые отношения между компаниями.
Объединение вершин в сообщества сети является частной характеристикой этой сети. Сообщества объясняют взаимодействие ближайших соседей вершин. В социальных сетях это объясняет, что если точка А связана с точкой B, а точка В – с точкой С, то в большинстве случаев это означает, что точка A, соединена с точкой C (обычно друзья наших друзей – это и наши друзья тоже).
Для объединения вершин в сообщества применяется кластеризация. Кластеризация выделяет из большого множества объектов подмножества, которые называются кластерами таким образом, что объекты, входящие в один кластер, были подобны друг другу больше в сравнении с объектами из другого кластера.
Про анализ социальных сетей и графовую аналитику есть несколько статей на сайте NTA, поэтому перейдем непосредственно к практической части. При анализе файлов XML были найдены теги, под которыми хранятся данные мобильных контактов. В результате для извлечения необходимых номеров была написана, следующая функция, на языке python:
import networkx as nx import os import re import sys import xml.etree.ElementTree as etree def import_contacts(root): # импортирует список контактов из XML (пустые значения отбрасываются) contacts = [] tag = root.find("./MobileDevice ") if tag is None: return None tag = tag.attrib if tag.get('Name') == 'PHONEBOOK': for phone in root.findall("./MobileDevice /Item/Field/[@Type='FLD_PB_NUMTYPE_MOBILE']"): if phone.text is None: continue else: contacts.append(phone.text) elif tag.get('Name') == 'AGGREGATED_CONTACTS': for phone in root.findall("./MobileDevice /Item/Field/[@Type='FLD_AGGRCONT_NUMTYPE_MOBILE']"): if phone.text is None: continue else: contacts.append(phone.text) else: return None return contactsПолученные данные необходимо было нормализовать к единому формату телефонных номеров, т.к. где-то они хранятся в написании с 8-ки, где-то с 7, где-то вообще цифры, не похожие на номера телефонов. Для преобразования была написана следующая функция:
def normalize_phones_list(phones_list): """ приводим № телефонов в единый формат (начинается с 7-ки вместо 8-ки) остальные отбрасываются """ i = 0 phones = [] while i < len(phones_list): phones_list[i] = phones_list[i].replace(u'\xa0', u' ') phones_list[i] = re.sub(r'[^0-9]', r'', phones_list[i]) if len(phones_list[i]) == 11: if phones_list[i][0] == '8': phones_list[i] = '7' + phones_list[i][1:] phones.append(int(phones_list[i])) i += 1 return phonesВсе данные были экспортированы в XML формат с названиями в виде номера телефона владельца, для того чтобы получить эту вершину (источник связей) с его контактами был написан следующий код:
def get_owner_phone_from_filename(filename): """ получает № тел. (исп. для указания телефона-владельца) из имени файла TXT\XML (имя файла должно содержать № тел) """ match = re.search(r'(\d{11})\.(xml|txt)', filename) if match is not None: owner_phone = match[1] else: owner_phone = None return owner_phone Для сбора списка контактов со всех файлов и преобразования к необходимому формату была написана следующая функция:
def xml_to_txt(pathname): """ конвертация всех XML файлов в папке pathname в TXT (каждый № тел. записывается в отдельную строку) возвращается список полученных № тел. с группировкой по номерам-владельцам """ filenames = [] owners_dict = dict() path = os.walk(pathname) for (dirpath, dirnames, files) in path: for filename in files: match = re.search(r'(\d{11})\.xml', filename) if match is not None: filenames.append(match[0]) break try: for filename in filenames: tree = etree.parse(pathname + '\\' + filename) root = tree.getroot() if root.tag == 'OFExport': contacts_list = import_contacts(root) contacts_list = normalize_phones_list(contacts_list) with open(pathname + '\\' + get_owner_phone_from_filename(filename) + '.txt', 'w') as f: for item in contacts_list: f.write("%s\n" % item) owner_phone = int(get_owner_phone_from_filename(filename)) owners_dict[owner_phone] = contacts_list except etree.ParseError as e: print("Ошибка при обработке XML-файла:", filename) print(e) print("Unexpected error:", sys.exc_info()[0]) return owners_dict Далее для формирования графа по вершинам-владельцам и их связям с контактами был написан следующий код:
def import_from_txt(pathname): """ загрузка № тел. из TXT файлов, расположенных в папке pathname и её подпапок имена подпапок используются в качестве установленных сообществ номер-владелец берется из имени файла (каждый № тел. в файле должен быть в отдельной строке, имя файла из 11 цифр № тел) возвращается список полученных № тел. с группировкой по номерам-владельцам """ case = 'without' contacts_list = [] G = nx.Graph() for dirName, subdirList, fileList in os.walk(pathname): if dirName != pathname: match = re.search(r'(TXTdata\\(\w+))', dirName) if match is not None: case = match[2] for filename in fileList: try: with open(dirName + '\\' + filename) as f: for line in f: contacts_list.append(line.rstrip('\n')) contacts_list = normalize_phones_list(contacts_list) owner_phone = int(get_owner_phone_from_filename(filename)) G.add_node(owner_phone, case=case) G.add_nodes_from(contacts_list, case=case) for phone in contacts_list: G.add_edge(owner_phone, phone) contacts_list = [] except etree.ParseError as e: print("Ошибка при обработке TXT-файла:", filename) print(e) except: print("Unexpected error:", sys.exc_info()[0]) return G И наконец запускаем весь скрипт для обработки всех файлов и сохраняем результат в формат graphml:
data = import_from_txt('TXTdata') nx.write_graphml(data, 'graph.graphml') sys.exit()По результатам экспорта все вершины и связи были сформированы при помощи библиотеки NetworkX, а результат записан в файл: «graph.graphml». Далее, вершины и связи были импортированы из файла в Gephi.
В результате импорта была получена социальная сеть, состоящая из 12084 вершин и 12752 связей. После того, как были отфильтрованы «листы» осталось 606 вершин и 1274 связи.
Далее, посредством алгоритма «Betweeness Centrality», был проведен анализ центральности, после чего, в соответствии с данной метрикой, устанавливался размер каждой вершины. Также социальная сеть была раскрашена в соответствующий цвет для каждого сообщества:
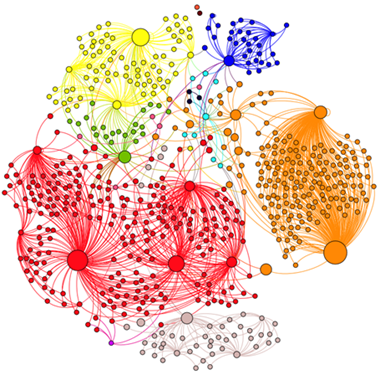
Для поиска сообществ (кластеризации) был применен метод Лувена, анализ при помощи данного алгоритма показал высокую скорость при большом количестве вершин. Этот метод имеет высокую точность при тестировании на известных сообществах. Метод использует иерархическую структуру, поэтому подходит для сетей различного масштаба.
Разберем, как работает алгоритм. Сначала каждая вершина образует отдельное сообщество. Итерация состоит из двух этапов. На первом этап для каждой вершины алгоритм пытается найти сообщество, перемещение в которое даст лучшее положительное изменение модулярности. Вершину переместить возможно только по смежным связям, то есть только в те сообщества, которым принадлежат вершины, смежные с данной. Итерация проверки всех вершин продолжается до тех пор, пока происходит хотя бы одно перемещение.
На втором этапе происходит сжатие сети: вершины, которые входят в одно сообщество, образуют новую супервершину с соответствующим преобразованием связей. Алгоритм останавливается, когда сеть перестает изменяться.
На следующем рисунке представлен результат применения этого метода.

Таким образом, собранные сведения показывают тесную связь между различными сообществами, хотя и присутствуют автономные компоненты связности. Для дальнейшего анализа полученных результатов данные были переданы аналитикам.
В результате анализа контактов с мобильных телефонов, которые предварительно экспортированы в XML формат, были построены связи владельцев мобильных телефонов с его контактами в записной книжке. Методы анализа социальных сетей и кластеризации помогли выявить изменения в заранее определенных сообществах. Этот метод анализа помогает выявить мошенников, которые были в связи с уже известными мошенниками.
ссылка на оригинал статьи https://habr.com/ru/post/669980/
Добавить комментарий