Кластерный анализ решает задачу разбиения множества на группы (кластеры) по принципу наибольшей однородности.
Подобные задачи возникают во множестве сфер деятельности, в частности это реклама и маркетинг. Ситуация, когда нужно выделить группы клиентов, максимально «похожих» друг на друга или определить локации, в которых преобладают определённые предпочтения.
Рассмотрю подобный пример и расскажу о способах решения вопроса средствами языка R.
Загружаю датасет из csv-файла. Задача следующая: разбить множества населённых пунктов, участвовавших в рекламной рассылке на сегменты по приоритету подписки на определённый журнал.
adv_dataframe <- read.csv('./advert_dataset.csv', header=T) head(adv_dataframe) --------------------------------------------------------------------------------------------------------------------------------- Город Всего_рассылок Кот_и_пёс Дача Увлекательная_геология Домашняя_выпечка Психология КаслРок 30000 200 10 9000 11000 500 ТвинПикс 15000 750 5 7000 6000 1000 СайлентХилл 10000 4500 0 650 15 4200 Харлоу 5000 1 1100 10 260 400 Гатлин 3000 1800 20 18 20 1000 КейпКод 1200 16 800 2 60 10 Вычисляю %-ное отношение числа подписок к общему количеству рассылок по городу для каждого журнала:
adv_dataframe$'Кот_и_пёс_%' <- 100 * adv_dataframe$'Кот_и_пёс'/ adv_dataframe$'Всего_рассылок' adv_dataframe$'Дача_%' <- 100 * adv_dataframe$'Дача'/ adv_dataframe$'Всего_рассылок' adv_dataframe$'Увлекательная_геология_%'<-100*adv_dataframe$'Увлекательная_геология'/ adv_dataframe$'Всего_рассылок' adv_dataframe$'Домашняя_выпечка_%' <- 100 * adv_dataframe$'Домашняя_выпечка'/ adv_dataframe$'Всего_рассылок' adv_dataframe$'Психология_%' <- 100 * adv_dataframe$'Психология'/ adv_dataframe$'Всего_рассылок' df4analysis <- subset(adv_dataframe, select = c('Город','Кот_и_пёс_%','Дача_%','Увлекательная_геология_%','Домашняя_выпечка_%','Психология_%')) Стандартизирую данные основного датасета. И следом получаю матрицу расстояний (distance_matrix).
pure_data <- df4analysis[,-c(1,1)] means <- apply(pure_data,2,mean) sds <- apply(pure_data,2,sd) norm_ <- scale(pure_data,center=means,scale=sds) distance_martix = dist(norm_)Рассмотрим иерархическую кластеризацию.
Построю дендрограмму на основе полученной матрицы расстояний.
df4analysis.hclust<-hclust(distance_martix,method="average") plot(df4analysis.hclust) rect.hclust(df4analysis.hclust , k = 3, border = 2:6) abline(h = 2.6, col = 'red')Визуально можно выделить 3 кластера. Так же дополнительно в построении дендрограммы провожу линию на уровне 3 и выделяю кластеры (rect.hclust) разными цветами.
Добавляю в наш основной датасет столбец с признаком принадлежности к кластеру.
cut_ <- cutree(df4analysis.hclust, k = 3) df4analysis.cut_ = factor(cut_)Теперь посмотрим и проанализируем результат:
head(df4analysis) ---------------------------------------------------------------------------------------------------------------------------------------- Город Кот_и_пёс_% Дача_% Увлекательная_геология_% Домашняя_выпечка_% Психология_% cut_ КаслРок 0.6666667 0.03333333 30.0000000 36.6666667 1.6666667 1 ТвинПикс 5.0000000 0.03333333 46.6666667 40.0000000 6.6666667 1 СайлентХилл 45.0000000 0.00000000 6.5000000 0.1500000 42.0000000 2 Харлоу 0.0200000 22.00000000 0.2000000 5.2000000 8.0000000 3 Гатлин 60.0000000 0.66666667 0.6000000 0.6666667 33.3333333 2 КейпКод 1.3333333 66.66666667 0.1666667 5.0000000 0.8333333 3Из получившегося распределения видно, что в кластере 1- два города с преобладанием новых подписок на журналы «Увлекательная геология» и «Домашняя выпечка», в кластере 2- это «Кот и пёс» и «Психология» и в кластере 3- города с преобладанием подписок на журнал «Дача».
Рассмотрим применение метода K-средних (k-means).
Воспользуюсь методом kmeans, а также добавлю наименования для строк. После применяю метод fviz_cluster библиотеки factoextra для визуализации.
library(factoextra) k_ <- kmeans(norm_, centers = 3, nstart = 25) rownames(norm_) <- df4analysis$'Город' fviz_cluster(k_, data = norm_)Результат получается следующим:
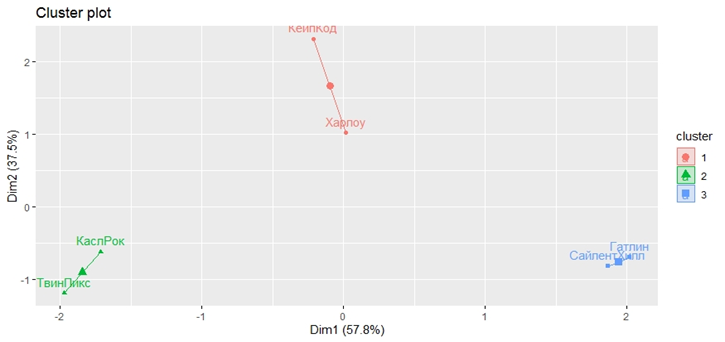
В данном случае происходит разбиение множества населённых пунктов на те же 3 кластера (аналогично предыдущему).
Для исследования на оптимум разбиения множества, можно использовать метод fviz_nbclust библиотеки factoextra.
fviz_nbclust(norm_, kmeans, method = <метод>) В качестве параметра method могут выступать значения «gap_stat» (Gap static method), «silhouette»(Silhouette method), «wss» (Elbow method). В качестве результата для анализа fviz_nbclust выдаёт соответствующий параметру method график.
Тема кластеризации невероятно обширна, и в данной статье я познакомил вас с некоторыми основными моментами при решении задачи кластеризации. Вместе с тем, я хотел отметить, как невероятно обширен инструментарий языка R, позволяющий решать эти задачи, зачастую очень небольшим числом строк кода.
ссылка на оригинал статьи https://habr.com/ru/post/685040/
Добавить комментарий