В весьма впечатлившей меня книге «Информация. История. Теория. Поток» Джеймса Глика, о которой я уже упоминал ранее, страннейшим образом обойдён вопрос о том, как возник феномен «Big Data». В той же книге упоминается первый авторский словарь английского языка, составленный в начале XVII века неким Кодри, а далее развивается идея о том, что феномен концептуализируется в языке после того, как попадает в словарь – в английской культуре таким словарём является оксфордский.
Тогда я попробовал проверить, когда же в английском и русском языке закрепилось понятие «Big Data» и, соответственно, «большие данные». Распространено мнение, что выражение «Big Data» впервые было употреблено в 2008 году в статье Клиффорда Линча «Big data: how do your data grow?», опубликованной в журнале «Nature», но даже это небольшое исследование подсказывает, что всё гораздо сложнее.
Наша цивилизация переживала, как минимум, три информационных взрыва, когда объём доступных данных резко увеличивался. Речь о возникновении письменности (около 5000 лет назад), изобретении книгопечатного станка (40-е годы XV века) и возникновении Всемирной Паутины (1989 год). Но по-настоящему «большими» данные становятся после того, как скорость их накопления начинает серьёзно превышать скорость их обработки, и для извлечения смысла из этих данных требуется не столько опыт в предметной области, сколько статистика и обобщения.
В Оксфордском словаре большие данные определяются как «исключительно большие
множества данных, поддающиеся вычислительному анализу для выявления паттернов,
трендов и ассоциаций, в особенности применительно к человеческому поведению и контактам». Сегодня этот термин вполне закрепился и употребляется при описании
развивающихся систем управления данными. «Большие данные» — концепция по
определению очень зыбкая, и в зависимости от контекста. В частности, бизнес
старается собирать информацию о привычках клиентов, чтобы увереннее
прогнозировать их действия и оптимизировать производительность. Известно, что
постоянно записываются и агрегируются транзакции, история поиска, активность в
социальных сетях и пр. Также развивается анализ временных рядов. Эта технология относится к большим данным, но на фоне прочих стоит особняком, так как обрабатываемые ею множества данных постоянно растут и обновляются. Тем не менее, эти данные ничуть не хуже других подходят в качестве материала для машинного обучения. Именно развитие
алгоритмов машинного обучения диктует растущие потребности в накоплении больших
данных. Однако так было не всегда. Веками мы просто не понимали, что делать с
растущими объёмами данных, притом, что данные постоянно детализировались. В XIX
и XX веках, до изобретения компьютеров, такие данные пытались классифицировать
и сделать более компактными.
Что такое Big Data
Big data – это большие и разнохарактерные информационные ресурсы, накопление которых идёт по экспоненте. В докомпьютерную эпоху даже эффективное хранение данных было трудоёмким делом, а об их постоянной опережающей обработке говорить не приходилось. Но в настоящий «поток» данные превратились только в середине 2000-х с возникновением «Веб 2.0» — целого поколения сайтов и приложений, пользователи которых могли свободно выкладывать в интернете собственный контент, сначала тексты, а затем изображения, аудио и видео. К середине 2000-х аналитик Дуг Лэйни (Doug Laney) перечислил три важнейших «показателя на V», характеризующих большие данные.
Объем (Volume): объём анализируемых данных постоянно растёт; более того, растут требования к актуальности и скорости обновления многих видов данных. Кроме множеств данных из Веб 2.0, упомянутых выше, постоянно растёт объём бизнес-транзакций, данных от интернета вещей (IoT), показаний промышленного оборудования и пр. Умножение таких данных ранее приводило к развитию хранилищ и средств обработки, среди которых стоит особо отметить озёра данных и Hadoop, но скорость обработки этих данных оставалась невелика.
Скорость (Velocity): показатель, не менее важный, чем объём – ведь данные устаревают. Многие данные быстро теряют актуальность, либо постоянно обновляются; таковы, например, показания RFID-меток, сенсоров и счётчиков.
Разнообразие (Variety): прямо следует из предыдущих двух пунктов. Данные очень разные, как по объёму, формату, так и по скорости обновления и по вариантам анализа. Очень сложно привести к «общему знаменателю» такие данные как электронная почта, финансовые транзакции, видеоролики и последовательности сигналов.Поэтому такое разнообразие требует сочетать различные инструменты для обработки данных.
В наше времявэтотрядпринято добавлять четвёртое и пятоеV, а именно «Veracity» — «достоверность» и «Value» (ценность).
Достоверность (Veracity)
Достоверность данных напрямую связана с их качеством и точностью. В собранных данных могут быть пробелы, неточности, либо содержащийся в них шум может начисто перекрывать слабый сигнал. Достоверность позволяет судить, насколько заслуживают доверия собранные данные.
Данные требуется структурировать, иначе они быстро превращаются в путаницу и приобретают противоречивость. Первые попытки обработки больших данных были связаны именно с их структурированием (об этом поговорим далее, возможно, такая деятельность восходит к XV веку) и со стремлением выявить тренды и выбросы. От качества данных зависит их информативность.
Ценность (Value)
Последний пункт тривиален. Данные тем ценнее, чем очевиднее и быстрее их можно применить на практике. Многие данные могут быть недооценены из-за недостатка или отсутствия вычислительных мощностей для их обработки, однако некоторые множества данных ценны по определению, поэтому ещё в докомпьютерную эпоху их кропотливо собирали и пытались анализировать. В викторианской Англии особенно ценными считались массивы метеорологических наблюдений и социоэкономические показатели, сбор которых в XIX веке сопровождал каждую перепись населения. Стихийным изучением больших данных из разных предметных областей более иных прославились Френсис Гальтон (двоюродный брат Чарльза Дарвина, скомпрометировавший себя как изобретатель и поборник евгеники) и Чарльз Бэббидж. Джеймс Глик приводит в своей книге такой исторический анекдот, позволяющий судить о круге интересов Чарльза Бэббиджа:
Hidden text
“Высокий джентльмен в углу, — сказал мой собеседник, — настаивал, что вы по части скобяных изделий, а полный джентльмен, который сидел рядом с вами за ужином, был вполне уверен, что вы продаёте спиртное. Другой из той же компании заявил, что они оба ошибаются и вы представитель крупной фабрики железных изделий”.
“Ну, — отреагировал я, — вы, как мне кажется, знаете про мои дела лучше, чем наши друзья”.
“Да, — ответил тот, — я прекрасно знаю, что вы торгуете ноттингемским
кружевом”
«Разностная машина» (первый механический компьютер, сконструированный Чарльзом Бэббиджем в виде прототипа) – отдельная тема, выходящая за рамки этой статьи. О ней подробно рассказано на Хабре в блоге Александра Семилетова @elmm в серии из трёх публикаций: первая часть, вторая часть, третья часть.
О структуре больших данных
Любые данные можно определить как структурированные, неструктурированные и полуструктурированные.
Структурированные данныеподдаются хранению, доступу и обработке в фиксированном формате. Поскольку такие форматы хорошо известны и могут быть взяты на вооружение бизнесом, именно из структурированных данных извлекается информация, важная для принятия решений. Сегодня структурированные данные производятся в промышленных масштабах и уже исчисляются зеттабайтами.
Неструктурированные данные – такие, форма или структура которых неизвестна. Кроме того, неструктуированные данные обычно являются неоднородными (гетерогенными) и могут содержать произвольные комбинации текстовых файлов, изображений, видео, т.д. Проще всего анализировать метаинформацию о таких данных, но и такая информация может обладать значительной ценностью, поддаваться классификации и прогнозированию.
Полуструктурированные данные – это множества, состоящие одновременно из структурированных и неструктурированных данных. Типичным примером полуструктурированных данных является веб-сайт. Структурированная часть информации с сайта хранится на сервере, будучи заключена в базе данных. Однако, на сайте постоянно накапливается и большой объём неструктурированных данных; таковы файлы логов, история транзакций, пользовательские взаимодействия с мэшапами и пр.
Исходя из вышеизложенного, работа с большими данными – это, прежде всего, статистика. Для получения репрезентативной статистики необходимо накопить большой объём данных. Соответственно, при грамотной работе с большими данными количество, как правило, перетекает в качество.
Первое пришествие больших данных
Статистика как наука зарождается примерно в конце XV века, когда стали кодифицироваться методы бухгалтерского учёта, опирающиеся на развитие математической теории. В 1494 году Лука Пачоли создал трактат «Сумма арифметики, геометрии, отношений и пропорций», в котором впервые описал ведение бухгалтерии методом двойной записи затронул множество других прикладных проблем, в частности, подбор ставок в азартных играх. В течение нескольких столетий эта книга оставалась классическим пособием по бухгалтерии, в частности, по сведению дебета с кредитом. В течение XVI века накапливался корпус навигационных наблюдений, а также коммерческих и демографических данных. К середине XVII века рост городов и сопутствующие вспышки инфекционных болезней в Европе потребовали изучать соотношение рождаемости и смертности. Именно этой теме была посвящена вышедшая в 1662 году книга Джона Граунта (John Graunt) «Естественные и политические наблюдения над списками умерших» (Natural and Political Observations Made upon the Bills of Mortality). Граунт опирался на статистику о крестильных и погребальных церемониях, проведённых в Лондоне, рассчитав на основе этих данных население города.
Также, анализируя смертность в городах, он смог предсказать динамику распространения бубонной чумы в Европе – ранее никакой анализ данных в таком масштабе не осуществлялся. Вскоре после выхода его книги, в феврале-марте 1666 года, первая полноценная перепись населения была проведена во французской части Канады. Ещё ранее, примерно в 1605-1606 годах, неудачные попытки переписи населения предпринимались в других французских колониях. Эта инициатива объяснялась утилитарными причинами: заморская колония была малонаселённой, требовалось конкретизировать, сколько человек не хватает для потенциальной защиты территории от английской экспансии, для восполнения потерь после эпидемий и для обработки земли. Первая перепись показала, что в 1666 году в Канаде обитало 3215 белых обоих полов и всех возрастов. Впоследствии в XVII и XVIII веках переписи населения также проводились для уточнения налогообложения и для подсчёта выживших и трудоспособных людей после регулярно случавшихся эпидемий (в частности, после эпидемий холеры в Англии в 1831, 1848 и 1853 годах).
К 1700 году уже были изучены многие принципы теории вероятности. В частности, в 1713 году Якоб Бернулли дал слабую формулировку закона больших чисел. В начале XIX века работы по теории вероятности шли одновременно с мальтузианскими демографическими построениями о том, сколько человек может прокормить Земля без возникновения глобального голода. Крупнейшим достижением начала XIX века в области теории вероятности был метод наименьших квадратов, разработанный Карлом Фридрихом Гауссом в 1809 году в рамках исследований нормального распределения, а также центральная предельная теорема, опубликованная Лапласом в 1810 году. Синтез идей Гаусса и Лапласа впервые позволил комбинировать разнородные данные и количественно оценивать ошибку.
В течение XIX века предпринимались попытки применить такой анализ при переписи населения, но только к 1890 году, к началу очередной переписи в США, пришло осознание, что традиционными методами эту перепись можно только провести, а своевременно обработать данные уже не удастся. На обработку данных переписи-1880 ушло 8 лет, а на обработку данных переписи-1890 требовалось уже лет 10. Таким образом, обработка была бы завершена не ранее, чем к переписи 1900, и прошла бы впустую. Решая эту проблему, американский инженер Герман Холлерит изобрёл «табулятор» — первую машину для обработки больших данных.

Это была первая машина, в которой данные автоматически перегонялись в табличный формат. Машина сочетала функции табулятора и сортировщика. Автор постоянно совершенствовал её, и основная разработка пришлась на период с 1890 по 1896 год. В машине Холлерита активно использовались перфокарты, ранее нашедшие промышленное применение только в 1804 году в станке Жаккарда, автоматически наносившем на ткань заданный узор. Впрочем, Холлерит мог прийти к идее перфокарт и независимо. Он упоминал, что решил оформить индивидуальную учётку участника переписи в форме перфокарты, так как обратил внимание на работу кондукторов, заносивших информацию о пассажирах на карточку в форме таблицы.
Машина Холлерита позволила обработать результаты американской переписи-1890 всего за три месяца, после чего приобрела огромную популярность во всём мире и использовалась, в частности, в 1897 году при проведении переписи населения в России. В целом же приведённые выше примеры демонстрируют, что в середине 2000-х мы столкнулись уже не с первой, а со второй волной больших данных. Остановлюсь подробнее именно на первой из этих волн, то есть, на истории XIX века.
Лавина чисел
Именно таким выражением канадский политолог Иэн Хакинг из Университета Торонто характеризует ситуацию, сложившуюся в Европе в 1820-1840 годах. Этот период, при всей технологической несопоставимости с началом XXI века, отличался очень схожими проблемами: резко увеличилось количество категорий таких данных, какие требовалось хранить и анализировать, но эти данные обладали слишком высокой сложностью для своего времени, и на тот момент отсутствовали технологические средства для извлечения ценной информации из них. В XIX веке «лавина чисел» была накоплением и одновременной детализацией сведений о промышленных товарах, а также продолжающимся усложнением метрик, учитываемых при переписи (трудоспособного) населения.
Бурное развитие демографической статистики в Великобритании в начале XIX века подпитывалось как частной инициативой, так и государством. Индустриализация сопровождалась урбанизацией, а концентрация людей в городах отчасти упрощала статистическую обработку данных о них. В 1837 году в Лондоне и Манчестере уже функционировали статистические агентства, в период с 1800 по 1850 были изобретены практически все известные сегодня варианты графиков и диаграмм – в ходе работы, называвшейся тогда «статистической графикой и тематическим картированием». Вот, например, составленная Флоренс Найтингейл диаграмма «причин смертности в армии на Востоке» за 1854 год:
{kind=link}
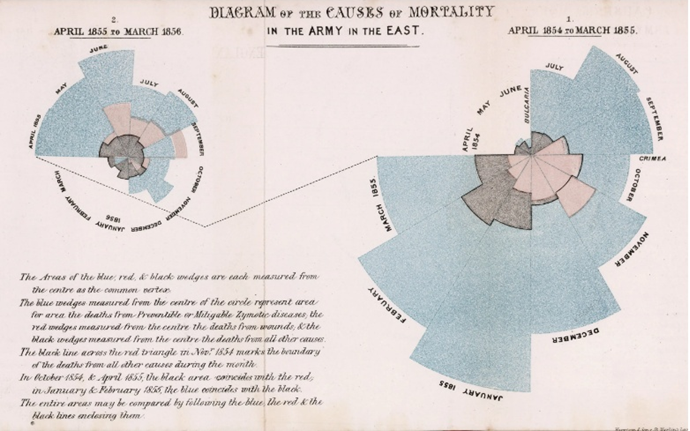
Именно к середине XIX века британская статистика отдаёт предпочтение таблицам над графикой, однако в примитивной форме диаграммы и графики с тех пор не уходили из социологической науки. Визуальное представление больших данных в особенности интересовало Фридриха Энгельса. В работе «Положение рабочего класса в Англии», опубликованной в 1845 году Энгельс пытался не только систематизировать, но и соотнести данные различных социологических служб, анализируя, как ожидаемая продолжительность жизни зависит от обращений к врачу, от питания в том или ином регионе или национальной общине, от условий труда и проживания. Энгельс впервые попытался подсчитать, какова для конкретного человека вероятность дожить до следующего дня рождения. Именно он указал, что в XIX веке на 10 000 населения в промышленных городах 5000 детей умирали в возрасте до 5 лет, а в сельских районах этот показатель составлял «всего» 3000. В этой же работе он пытался «раскрасить» районы промышленных городов по уровню жизни и вывести тенденции, например, для криминогенных характеристик района с изменением уровня жизни и этнической принадлежности населения.
Именно популяционная сторона статистики интересовала и упоминавшегося выше Френсиса Гальтона, однако, он попытался распространить статистический подход с демографии на метеорологию. В 1863 году вышла его книга «Meteorographica», в которой он впервые описал циклоны и антициклоны, а также попробовал охарактеризовать годичные флуктуации погоды на основе многолетних наблюдений. В 1875 году он составил первую известную метеорологическую карту, фиксировавшую погоду за прошедшие сутки, в данном случае, за 31 марта:
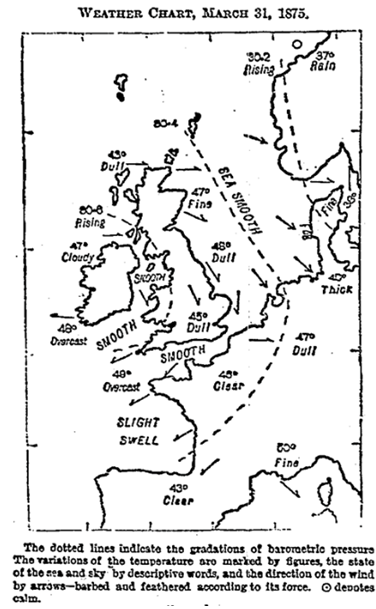
В этой работе Гальтон опирался на наблюдения Роберта Фицроя, капитана того самого корабля «Бигль», на борту которого совершил кругосветное путешествие Чарльз Дарвин. Роберт Фицрой пытался разработать такую карту, которая позволяла бы бегло оценивать вероятные изменения погоды, направление ветра и перепады температур. Тем не менее, Гальтон не смог разработать метода для оперативного составления прогнозов погоды, а лишь указал, что в метеорологии прослеживаются тенденции и закономерности, зависящие от климатического пояса и времени года. К сожалению, увлечение евгеникой и поиск откровенно расистских паттернов в области народонаселения во многом затмили метеорологические наработки Гальтона и не оставили ему самому времени на их развитие.
Большие данные — контроль или прогнозирование
Сравнивая нынешний всплеск интереса к большим данным и вышеописанную «лавину чисел», можно предположить, что статистические исследования Энгельса, Гальтона и других слишком опередили время, для них просто не нашлось адекватного программного и даже аппаратного обеспечения. На мой взгляд, наиболее интересные находки, сделанные во времена лавины чисел, связаны с попытками не только накапливать, но и соотносить данные, добиваться максимальной детализации доступных данных, искать выбросы и тенденции, а также объяснения для них. В XIX веке анализ больших данных оставался в основном гуманитарной, социоэкономической областью знаний, и разработка этих методов была продиктована в большей степени стремлением контролировать общество, а не извлекать новые знания о нём. В XIX веке фиксируются первые попытки снижения размерности данных. Среди таких попыток я бы отметил переход от бертильонажа (1880-е годы – начало XX века) к дактилоскопии (с 1892 года), а также постепенную унификацию и стандартизацию переписи населения в разных странах. В первую эпоху анализа больших данных ещё невозможно было представить себе машинное обучение и автоматическое извлечение таких паттернов, которые человек заметить просто не в состоянии. Сегодня большие данные всё сильнее превращаются из средства учёта в материал для машинного обучения, а такие технологии как GPS, IoT и анализ пользовательской деятельности в социальных сетях обеспечивают практически бесперебойный поток новых данных. Тем не менее, большие данные были и остаются скорее средством контроля и прогнозирования известных вещей, чем материалом для открытия неизвестных. Именно переизбыток однообразных данных приводит к переобучению нейронных сетей и создаёт почву для состязательных атак.
По-видимому, пять «V», упомянутые в начале этой статьи, были актуальны для статистических данных ещё в XIX веке, но именно с ростом объёма данных (первой V, «volume»), все остальные V становится всё сложнее поддерживать на приемлемом уровне. В наше время нужны не столько новые методы хранения, сколько методы детализации информации и очистки её от шума без потери качества. Кроме того, остаётся надеяться, что сбор больших данных будет направлен на совершение новых открытий и выявление полезных закономерностей, а не на наращивание тотального контроля – ведь, как показывает изложенная здесь история, именно во втором качестве анализ больших данных наиболее эффективен, и эта эффективность проверена временем.
ссылка на оригинал статьи https://habr.com/ru/post/718846/
Добавить комментарий