
Некоторое время назад мы рассказывали о сервере очередей, принципах его работы и внутреннем устройстве. Теперь же, наконец, пришло время перейти к рассмотрению очередей с более продуктовой точки зрения и рассказать об инфраструктуре, применяемой для обработки заданий. Давайте начнем чуть издалека, с того, на чем мы остановились в прошлой статье: для чего, собственно, очереди можно применять.
О пользе очередей
Конечно же, самый распространенный способ применения — для асинхронного выполнения операций, порождаемых в процессе обработки запросов пользователя, результаты исполнения которых не требуются немедленно для осуществления обратной связи. В нашем случае это, например, отправка почты и уведомлений, предложений дружбы, обновление поисковых индексов, сброс кешей, постобработка данных, полученных от пользователя (перекодирование видео, нарезка фотографий), отправка данных подсистемам, время реакции/надежность которых не гарантируется.
На практике выяснилось, что, обладая удобной инфраструктурой для распределенной обработки заданий, спектр применения существенно выше:
- В силу того, что каждое событие в сервере очередей обладает временем активации, можно использовать очереди в качестве планировщика отложенных заданий. Таким образом, например, у нас сделаны отложенные посты в группах. Вместо публикации в ленте группы пост укладывается во временное хранилище, а в очереди создается задание со временем активации, равным времени публикации поста.
- Используя время активации, можно размазывать нагрузку на базы данных во времени, откладывая выполнение некоторых неприоритетных заданий с пикового времени на ночное.
- Можно при помощи очередей ротировать контент, отображаемый группе пользователей. У нас применяется для социальной модерации фотографий. В специальную очередь складываются изображения, которые необходимо отмодерировать, а вебсервер при отдаче контента пользователю берет одну фотографию из очереди и показывает модератору.
- Очередь может встраиваться в качестве прослойки в API приема данных, например, push-нотификаций от коллег из соседнего проекта, для повышения надежности и сглаживания нагрузки.
- Для организации получения данных от внешних источников, например, путем скачивания некоторого контента со стороннего ресурса.
- Также можно осуществлять принудительную синхронизацию данных с дружественными проектами путем обхода нашей базы и отправки множества запросов к их API. Осуществлять это можно периодически и в течение длительного времени, регулируя нагрузку на API стороннего проекта при помощи ограничения количества обработчиков либо при помощи размазывания времени активации событий.
- Аналогичным же образом можно осуществлять обход собственных хранилищ с целью исправления данных, побитых вследствие логических ошибок в коде, либо с целью обновления структуры хранимых данных в новый формат.
- Очень удобно при помощи очередей осуществлять модификации распределенно хранящихся и связанных данных. Для примера можно взять такую операцию как удаление поста, которая также требует удаления всех комментариев и лайков. Соответственно, разбить ее можно на три отдельных очереди: одна отвечает за удаление поста, другая за удаление комментариев, третья за удаление лайков. Таким образом, получаем, что скорость разгребания каждой очереди зависит только от состояния конкретного хранилища и, например, проблемы с хранилищем лайков не повлияют на удаление собственно постов.
Инфраструктура обработки
Стоит признать, что некоторое время мы пытались обрабатывать задания из очередей без создания для этого специализированной инфраструктуры. По мере увеличения количества типов очередей становилось все более очевидным, что уследить за возрастающим количеством скриптиков и демоночков, весьма похожих, но немного разных, становится все сложнее. Нужно следить за нагрузкой и запускать достаточное количество процессов, не забывать мониторить их, при выпадении серверов своевременно поднимать процессы на других машинах. Появилось понимание, что нужна инфраструктура, которой можно сказать: «вот тебе кластер серверов-обработчиков, вот тебе серверы очередей, давай разгребай». Поэтому мы немного подумали, посмотрели, есть ли готовые решения, взяли Perl (потому что это один из основных языков, наряду с C, на котором мы разрабатываем) и понеслась.
При проектировании инфраструктуры для обработки очередей ключевыми были следующие характеристики:
- распределенность — задания одного типа могут выполняться на разных серверах;
- отказоустойчивость — выпадение десяти-двадцати процентов серверов кластера не должно приводить к деградации важных очередей;
- гомогенность — отсутствие какой-либо специализации серверов, любое задание может выполняться на любом сервере;
- приоритизация — есть критичные очереди, а есть те, которые могут и подождать;
- автоматизация — минимум ручного вмешательства (особенно админского): балансировка — перераспределение обработчиков каждого типа в зависимости от потребностей; адаптация к серверу — определение количества обработчиков на каждом сервере в зависимости от его характеристик, отслеживание потребления памяти и процессора;
- пакетная обработка — задания одного типа должны группироваться для возможности применения оптимизаций;
- статистика — сбор данных о поведении очередей, потоке заданий, количестве, наличии ошибок;
- мониторинг — оповещение о нештатных ситуациях и изменении стандартного поведения очередей.
Схему мы при этом применили достаточно классическую, выделив три компонента: менеджер, мастер и слот.

Слот — это собственно процесс-обработчик очереди (воркер). Слотов на каждом сервере может быть запущено множество, каждый слот характеризуется типом очереди, которую он в данный момент обрабатывает. Специализация слотов на очередях определенных типов повышает локальность данных, соединений к базам данных и внешним сервисам, упрощает отладку (в том числе на случай порчи памяти процесса и образования «корок»).
Мастер — это процесс-бригадир, ответственный за работу слотов на определенном сервере. В его обязанности входит запуск и остановка слотов, поддержание оптимального количества слотов на сервере в зависимости от его конфигурации, доступной памяти и LA, мониторинг жизнедеятельности слотов, уничтожение зависших и использовавших слишком много системных ресурсов слотов.
Менеджер — это процесс-руководитель кластера, запускается в одном экземпляре (под pacemaker’ом для надежности) и отвечает за весь кластер. Занимается микроменеджментом: на основе данных от сервера очередей и статистических данных от мастеров определяет необходимое количество слотов каждого типа и решает, какой конкретный слот будет заниматься заданиями какого типа.
Управление кластером
Определение необходимого количества слотов для обработки каждого типа очереди менеджером осуществляется на базе:
- конфигурационных параметров, в том числе: приоритет очереди; минимальное и максимальное допустимое количество обработчиков; количество заданий, обрабатываемых за одну итерацию;
- статистических данных за последнее время, в том числе: количество активных заданий в очереди; количество обработанных заданий; суммарное время обработки заданий; суммарное время жизни обработчиков.
При этом для исключения мигания слотов намеренно допускается некоторая неточность: если необходимое количество слотов незначительно отличается от текущего, то переконфигурации не происходит («незначительность» отклонения вверх и вниз определяется как функция от приоритета очереди). С этой же целью составление новой карты слотов всегда осуществляется на основании текущей. Это приводит к тому, что слоты стабильно занимаются обработкой одного типа заданий. Также при распределении слотов по серверам менеджер старается не допустить скапливания обработчиков одного типа и размазывает их по кластеру.
Следует признать, что подобрать формулу, хорошо балансирующую количество слотов каждого типа, нам удалось не с первого раза — сначала пытались обойтись меньшим количеством параметров и коэффициентов. В процессе подбора формулы нарисовали админочку менеджера, по которой можно проанализировать правильность его действий, а также посмотреть каким образом слоты определенных типов распределяются по серверам.

Кстати, на этой картинке видна пара забавных эффектов, например, что количество слотов (в том числе среднее) может быть меньше минимального. Это означает, что время жизни слота не очень большое, скорее всего в силу интенсивного использования памяти, и они часто перезапускаются. Или то, что загрузка может быть сильно больше 100%, так как она учитывает не только обрабатывающиеся задания, но и те, которые накапливаются в очереди. Именно на основе этого показателя менеджер определяет, что количество слотов надо уменьшать или увеличивать (подсвечивается красным). Для некоторых типов очередей мы сознательно завышаем минимальное количество слотов этого типа. Это необходимо, чтобы обеспечить для этих очередей минимальное время реакции на событие и быть уверенными, что как только оно попадет в очередь, то моментально уйдет в обработку, не ожидая выполнения предыдущих заданий.

Местное самоуправление
Сервера, на которых запускаются мастера, разные по мощности: часть старые и так себе, часть новые и вполне ничего. Поэтому необходимо автоматически, без настроек со стороны админов, определять доступные ресурсы, текущие аппетиты слотов и подстраивать их количество. В нашем случае выяснилось, что самый ценный ресурс — оперативная память. Именно она определяет, сколько слотов можно запустить на сервере. Разумеется, для ее экономии мы постарались максимально использовать copy-on-write и загрузить весь необходимый для исполнения слотов код в мастере с тем, чтобы после форка слотов они всю эту память разделяли. Для того чтобы подсчитать допустимое количество слотов на одном сервере, стандартных VSZ и RSS недостаточно — они не содержат информации о том насколько память процессов расшарена между процессам. К счастью, в linux с некоторых пор имеется замечательный параметр PSS (Proportional Set Size), который для каждой страницы памяти обратно пропорционален количеству процессов, между которыми она пошарена (вычитать и высчитать PSS процесса можно из /proc/$pid/smaps). Сумма PSS мастера и всех слотов, разделенная на количество слотов, примерно соответствует среднему размеру слота (чуть больше, так как на мастер специально не делим). Добавив сумму PSS к свободной памяти и разделив на средний размер слота, можно получить их допустимое количество (минус некоторый запас на всякий случай).
В процессе работы слоты постоянно взаимодействуют с мастером, получая от него команды на изменение параметров слота и передавая ему статистическую информацию, которая впоследствии используется менеджером при планировании. Слот периодически подсчитывает количество памяти, которой он обладает эксклюзивно (Private_Dirty), и, если оно превышает заданный лимит, то завершает свою работу. Впоследствии такой слот перезапускается мастером с чистого листа. Это позволяет экономить память и не дает отдельным слотам нарушать функционирование сервера в целом.
Алгоритм обработки заданий
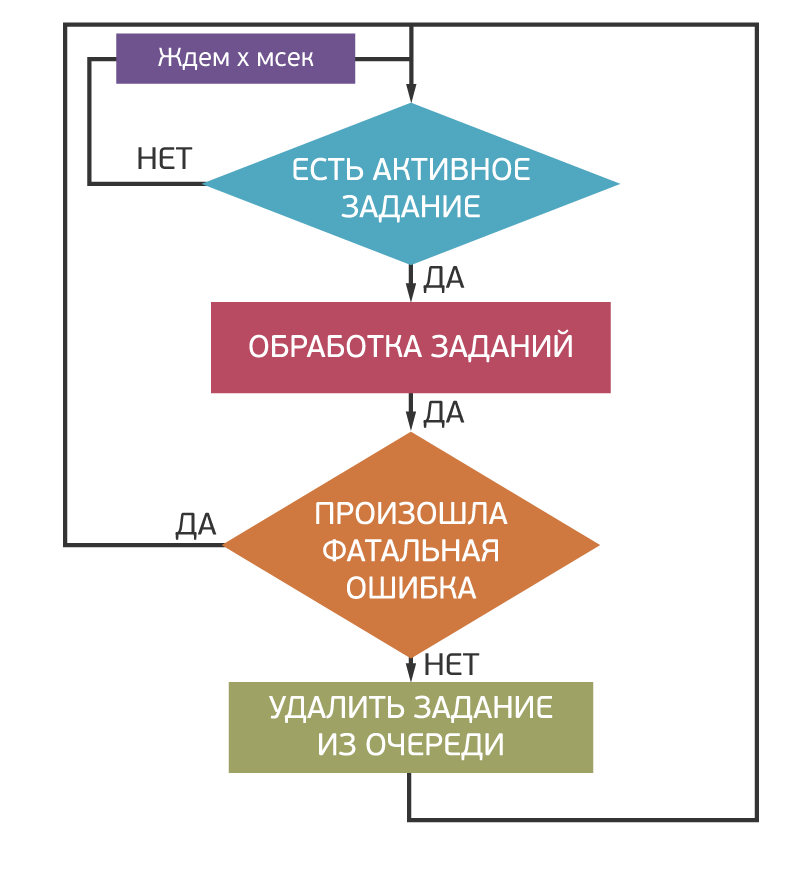
Собственно процесс обработки заданий построен по достаточно простому циклическому алгоритму. Слот постоянно посылает серверу очередей запрос на получение очередной пачки заданий. В случае наличия событий они обрабатываются. При этом по возможности все события из пачки обрабатываются совместно. Это позволяет уменьшить количество запросов к базам данных за счет группировки однотипных и посылки мультизапросов. Либо, в случае отсутствия поддержки мультизапросов со стороны хранилищ, ускорить общение с ними за счет параллелизации асинхронных запросов путем применения libev или libcoro. Логичным решением конечно же было бы вообще использовать асинхронную обработку заданий в рамках event-машины. Но на практике такое решение сопряженно со сложностями при разработке (необходимость выполнения одного и того же кода из-под синхронного веб-сервера и асинхронного обработчика очереди) и отладке.
Обработка ошибок построена максимально простым способом и использует особенность сервера очередей, который при выдаче заданий обработчику лочит их на некоторое время (как правило, на два часа, но это настраивается для каждой очереди). Все непредусмотренные разработчиком ситуации просто приводят к тому, что задание остается залоченным в очереди в течение двух часов и после этого подхватывается другим обработчиком. Такой подход позволяет однотипным образом реагировать как на проблемы в логике обработки, так и на ошибки в низкоуровневом коде, которые могут приводить к падению обработчика в «корку». Более-менее штатные ситуации при этом можно обрабатывать и более разумным способом, например, посредством откладывания времени активации события на более позднее время. В любом случае событие считается обработанным только тогда, когда обработчик пошлет серверу очередей команду на удаление.
Весь процесс обработки заданий аккуратно обложен отправкой статистической информации, рисованием разнообразных графиков и мониторингом. В качестве первичного мониторинга используется информация о количестве заданий в очереди и о том, сколько из них залочено. Увеличение количества залоченных событий явно говорит о том, что в очереди накапливаются события, которые не могут быть обработаны из-за наличия фатальных ошибок. Рост количества активных заданий говорит о том, что поступающий поток не успевает обрабатываться.
Заключение
В заключение хочется отметить, что описываемая инфраструктура используется в Моем Мире не первую пару лет и не требовала какого-либо существенного вмешательства или модификации за это время, даже несмотря на то, что ощутимо выросли и количество очередей, и количество используемых серверов. За это время нам удалось практически свести на нет зоопарк скриптиков и демоночков, переведя их на инфраструктуру менеджера очередей. Ее удобство привело к тому, что новые очереди появляются в проекте не реже, чем новые ajax-функции. И на текущий момент на кластере из 40 серверов (около 3500 обработчиков) за сутки обрабатывается порядка 350 миллионов заданий 150 разных типов.
P.S. Разумеется, сейчас уже появились такие готовые решения, как gearman, и если есть потребность в распределенной обработке заданий, то имеет смысл смотреть в их сторону. Но нам повезло озаботиться этой задачей чуть раньше, и мы получили массу удовольствия в процессе разработки собственного решения.
ссылка на оригинал статьи http://habrahabr.ru/company/mailru/blog/228131/
Добавить комментарий