В электронике есть множество проводных полудуплексных асинхронных последовательных интерфейсов типа общая шина. Это 1-Wire, RS485, 10BASE2(thin Ethernet), LIN, K-Line , CAN, I2C, MIL-STD-1553, ARINC 429.
Во всех этих shared-bus интерфейсах так или иначе возникает задача сканирования шины.
Всем кто работал с i2c известна процедура сканирования шины. Там можно просто методом перебора просканировать шину. Так как длина адреса всего 7 бит, то можно просканировать шину просто за пару секунд.
Результат сканирования шины I2C1 в UART-CLI
В CAN задачи сканирования вообще не стоит так как там коллизии разруливаются на аппаратном уровне физических трансиверов или вовсе MAC периферии. В CAN достаточно подключится в любом месте и через мгновение в утилите CAN-Hacker будет понятно кто там живет на шине CAN. В CAN все ноды постоянно flood(дят) «Hello!» пакетами.
В Lin сеть узлов обычно полностью 100% статическая и прошивается во время производства. Это и понятно, ведь в автомобильной двери во время езды не появится новая кнопка. В салоне автобуса по маршруту не вырастет новый поручень с кнопкой остановки.
Как обстоят дела со сканированием в остальных проводных интерфейсах: 1-Wire, 10BASE2(thin Ethernet), K-Line, MIL-STD-1553, ARINC 429 я, честно, не знаю. Если кто в теме, то напишите, пожалуйста, в комментариях.
Как обычно выглядит сеть RS485?
шпаргалка по шине RS485
В чем трудность сканирования шины RS485?
1—Трудность в том что адреса устройств RS485 имеют существенно более высокую разрядность, как правило это 32 бита (4байта) или MAC адреса по 48бит (6 байт). Предположим узлы на шине RS485 имеют 32битный адрес и если сканировать шину RS485 как в I2C то китайский калькулятор покажет что надо «подождать и потерпеть» 14 лет!
2—В шине RS485 нет механизма разрешения коллизий подобно CAN(у). Если 2 ноды начнут передавать одновременно, то данные в витой паре исказятся и мастер прочитает мусорный пакет с поврежденной контрольной суммой.
3—Все устройства на шине RS485 могут вообще работать на разных битовых скоростях 110, 300, 600, 1200, 2400, 4800, 9600, 14400, 19200, 38400, 57600, 115200, 230400, 460800, 921600 бит/c. Я работал в трех конторах и у каждой была своя стандартная битовая скорость шины RS485. И у всех разная! Если устройство работает на битовой скорости 460800 бит/c то оно не будет отвечать на пакеты которые ей посылают на битовой скорости 115200 бит/c.
Как же просканировать шину RS485?
Перед тем как приступить к объяснению сути алгоритма сканирования шины RS485 хочется привести аналогию из жизни. Аналогия эта про то как медвежатники отмычками взламывают навесные замки. Первой отмычкой создается момент силы, который фиксирует положение одного из пинов. Затем второй отмычкой находят пин, который движется туго и медленно и аккуратно подбирают положение упирающегося пина пока не услышат тихенький щелчок. Первая отмычка дрогнет. Затем начинает упираться другой пин. Аналогично двигают следующий пин до такого же щелчка. И так до тех пор пока все пины точно не встанут на нужные положения. Тогда замок откроется.
Как работает отмычка
Тут ситуация аналогичная. Вместо пинов — биты, вместо щелчка — сигнал подтверждения.
Прежде чем двигаться дальше надо договориться о терминологии.
Терминология
—Адрес устройства — это либо MAC адрес, серийный номер (SN), либо аналог IP адреса или любой другой ID(шник) уникальный для каждого экземпляра устройства на шине RS485. Важен тот момент, что адрес широкий много битный. Пусть это, например, 32х битный адрес.
—Маска адреса — это часть адреса устройства, которая начинается с наименьшего значащего бита LSB и увеличивается в сторону старшего бита. Имеет смысл расширять маску от младших битов ибо младшие есть у всех адресов, а вот старших единичных битов может и не быть. Вот пример нескольких реальных масок:
№
Пример маски для адреса
Длина маски, [бит]
1
xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xxxx
0
2
xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xxx0
1
3
xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xx00
2
4
xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xx01
2
5
1000_0100_0000_1111_1111_0001_1101_0011
32
6
xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xx10
2
7
xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xx10_1110
6
—Сигнал подтверждения— это когда ведомое устройство на RS485 берет пин UART_TX, переводит его в режим GPIO PUSH-PULL, устанавливает 0V, ждет T_ack секунд (например 10ms) и после этого снова подключает к пину UART_TX контроллер. Всё это и называется сигналом подтверждения. По сути устройство на время прижимает шину в ноль вольт. При этом совершенно не опасно, если несколько устройств одновременно прижмут шину в ноль. Эффект будет как от одного. То есть получается логическое ИЛИ. У мастера на UART_RX будет 0V.
—Пакет mute — это такой бинарный пакет получив который ведомое устройство перестает что- либо отправлять в общую шину RS485 и не будет даже испускать сигналы. Устройство будет только слушать шину. Mute пакет может содержать параметр включить или отключить Mute режим.
Словесное описание алгоритма сканирования шины RS485
1—Мастер устройство объявляет что сейчас все ведомые устройства переходят в режим сканирования.
2—мастер отправляет маску адреса, например Mx=xx…xx0 или Mx1=xx…xx1 и просит, чтобы откликнулись те устройства чей адрес совпадает с маской. То есть у кого нулевой бит равен нулю.
3—мастер переводит пин UART_RX в GPIO input, устанавливает подтяжку к питанию и непрерывно смотрит за напряжением на проводе UART_RX. Тут есть два исхода.
a) У мастера на проводе UART_RX появился 0.0 V. Значит, что на шине RS485 присутствует как минимум одно ведомое устройство у кого адрес совпадает с маской Mx.
b) У мастера на проводе UART_RX остался 3,3V. Значат что на шине RS485 нет ни одного устройства у кого бы адрес совпадал с маской Mx. Это значит, что дальше мы с этой маской Mx не работаем и просто отбрасываем её в сторону как заранее неправильный путь. Причем мастер ожидает не бесконечно, а строго определённой время таймаута, которое общее для всех устройств, например 20ms.
4—В случае 3.a) маска расширяется на 1 бит влево. Тут тоже есть два варианта. Либо мы к маске обнаруженного устройства приписываем префикс 0 либо 1. Надо идти по обоим путям: 1 и 2.
№
Маска
Пояснение
Пример
1
xx…x0[PREV_ACK_MASK]
увеличили на 0
x…x00
2
xx…x1[PREV_ACK_MASK]
увеличили на 1
x…x10
Тут прослеживается рекурсия или элементы динамического программирование. Каждый шаг порождает 2 шага: c префиксом 0 и с префиксом 1.
Далее шаги 2-3-4 можно повторять снова и снова пока маска не достигнет длинны 32 бита. Как только это произойдет это станет означать что найдено одно устройство на шине. Но как найти остальные N-1 устройство?
5—Как только маска будет совпадать с 32 битами то мастер устройство отправляет команду заглушить устройство по определённому адресу. Master отправляет mute пакет.
Шаги 2-3-4-5 это по сути одна итерация. На следующей итерации мастер обнаружит другое устройство. И так до тех пор пока все маски перестанут выдавать сигнал подтверждения. После этого шина RS485 будет полностью просканирована.
К слову, на маску длинной ноль (xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xxxx_xxxx) отвечают установкой сигнала подтверждения все не заглушенные узлы RS485 сети. Поэтому данный пакет установки маски может служить критерием окончания сканирования сети.
Справедливости ради можно добавить что надо проделать все то же самое для всех возможных битовых скоростей RS485: 9600, 115200, и проч. Однако как правило RS485 сеть собирают из устройств у которых уже прописана битовая скорость по умолчанию.
Время сканирования на одной битовой скорости займет
Вариант
Время
Пояснение
лучший случай
32*N*dt
подтверждение при первом увеличении маски
Худший случай
32*N*2*dt
подтверждение при втором увеличении маски
где dt — это время отклика на адресную маску
Алгоритм сканирования общей шины можно изобразить в виде вот этой диаграммы обмена пакетами
Плюсы этого метода
1++Простота.
2++эффективность
3++Быстрота работы в сравнении с перебором.
4++нет нужды в дополнительных проводах. Всё что надо это одна витая пара интерфейса RS485.
Минусы
1—Master устройство должно быть микроконтроллером с полноценным драйвером GPIO и UART. Не получится просто взять первый попавшийся китайский переходник USB-RS485, подключить его к PC и написать консольное Windows приложение, которое выполнит сканирование RS485 шины. Надо чтобы была не просто возможность читать\писать байты в RS485, но и переключать функции пинов с GPIO на UART и обратно. Причем надо переключать функции пинов быстро чтобы успеть принять сигналы от Slave nodes.
2—Нужна программная поддержка этого простенького протокола сканирования RS485 как на стороне master так и на стороне slave устройств.
Вывод
Этот простой алгоритм сканирования адресов на общей шине подойдет не только для RS485. Его можно реализовать для любого другого интерфейса с топологией общая шина. Это может быть и 1Wire, LIN или даже вовсе беспроводные интерфейсы типа LoRa или UWB.
Современное естествознание приходит к выводу о том, что все системы, существующие в окружающей нас природе – от микромира до Метагалактики, – имеют фрактальную структуру.
Фрактал-это множество, обладающее свойством самоподобия (объект, в точности или приближённо совпадающий с частью себя самого, то есть целое имеет ту же форму, что и одна или более частей) (Википедия)
Если присмотреться, фракталы повсюду — веточки имеют подобие деревьев; берега, скалы, облака при приближении масштаба имеют самоподобные очертания, реки и артерии человека самоподобны независимо от размера, биржевые графики разных таймфреймов подобны друг-другу и подчиняются одинаковым законам, кривые спроса и предложения микроэкономики подобны кривым совокупного спроса и предложения макроэкономики… список бесконечен.
Открыт даже «Фрактал человечества»: атом — (совокупность атомов) клетка — (совокупность клеток) человек — (совокупность людей) { отдел — (совокупность отделов) организация — (совокупность организаций)} страна — (совокупность стран) планета — (совокупность планет) Вселенная — (совокупность Вселенных) ммм… такого слова ещё не придумали. Этот фрактал открыт мной и хочу заметить, что все перечисленные объекты подчиняются одинаковым законам… интересно? об этом наблюдении будет следующая статья. Считайте, что сделал анонс.
Наблюдение, которым хочу поделиться, также базируется на фрактале, хотя в таком ракурсе объект исследования пока не рассматривался (или мне об этом не известно) — исследоваться будет организационная структура организации в рыночной экономике.
Грядет революция в менеджменте (ниже привожу логические доводы по данному громкому заявлению) и как ярый сторонник «живых» организаций, agile-методологии, холакратии и т.д. данной статьёй хочу ускорить её наступление. Для популяризации современных методологий управления в статье попытаюсь создать в вашем воображении картинку работающего «живого» предприятия, имеющего в основе «самоорганизующуюся» систему (поэтому подумайте прежде чем читать, ведь вам потом с этим жить, шутка), а также отвечу на часто задаваемые вопросы на которые отвечаю, когда с кем-то делюсь данной методологией. Итак, поехали…
Экономический взгляд на организацию, построенную на традиционной иерархии
Согласно экономической теории — организационная структура предприятия (построенного на традиционной иерархии) имеет ряд издержек:
значительную часть явных издержек, в виде: зарплат менеджерскому составу (поскольку необходимо содержать всю иерархию менеджеров, достигающую значительных масштабов при росте организации; при этом имеющих повышенные в сравнении с работниками зарплаты) и работникам (нагрузка которых часто происходит неравномерно по штатному расписанию, учитывающего приблизительную нагрузку; которые могут быть недомотивированы, поэтому работающие только «за зарплату» не в полную отдачу);
а также неявные трансакционные издержки — в виде отсутствия гибкости при перестройке структуры организации и её бизнес‑процессов под быстроменяющиеся рыночные условия (и чем больше организация, тем больше фактор гибкости усугубляет ситуацию).
Данные издержки как «слон в посудной лавке» (он большой, на него тратится много ресурсов, а он всё равно неповоротлив) с которым смирились и даже пытаются его расшевелить через различные ухищрения, придумав различные опции — функциональное управление, процессное управление, матричное управление, которые добавляют функциональности (по факту — добавляют дополнительной работенки сотрудникам, которые и так бывают перегружены) и при этом добавляют затрат на управление данными процессами и усложнению организационной структуры.
При этом «рынок» требует быстрых решений и реакций, которые традиционная иерархическая организация обеспечивает с трудом (или вообще не обеспечивает) — при очередном изменении рыночной ситуации для реакции на неё со стороны организации сверхконтроль вынуждает проходить процедуру согласования решений по ряду уровней иерархии, что порождает дополнительные обсуждения, принятия решений (или отсутствие принятий решений, поскольку все управленцы боятся и затягивают процесс), написание приказов, их исполнение т.д., то есть имеет множество трансакционных издержек, связанных с принятием и исполнением распоряжений. А рынок не ждет… в результате — запаздывание реакции на очередной шок или спад, потеря прибылей, убытки там, где их можно было бы избежать.
Возникает ощущение, что «дедушка» хочет угнаться за «молодежью», но как бы не старался, не успевает.
Отсюда хочу сделать первое «революционное» заключение:
Медленные традиционные иерархические системы не успевают за ритмом быстрой рыночной экономической системы.
Идеальная модель организации в рыночной экономике, какая она?
Ответ на данный вопрос даст курс развития всех предприятий мира, т.е. тот самый научно-технический прогресс, который сдвигает кривую совокупного предложения LRAS, а значит увеличивает ВВП страны (привет знатокам макроэкономики!). Интересно, кто-то задавался таким вопросом? Хочу поделиться своими наблюдениями.
В экономической теории выделяют несколько видов экономических систем:
традиционная (в основе которых — традиции, а не законы; например — организация быта в племенах или малоразвитых странах);
плановая (про плановую экономику СССР известно многим, идея проста — обеспечить всех равными благами под жёстким контролем государства); в современном мире данная экономическая система не зарекомендовала себя, знаю, что в текущее время существует в Северной Корее и на Кубе;
рыночная (в ней мы и живём, идея та же — обеспечить всех благами, но через мотивацию «заработай и купи», а значит — развивайся, проявляйся, конкурируй и т.д.).
Учитывая то, что сложные системы (которыми являются и экономические системы) почти всегда имеют фрактальную структуру, найдем фракталы нижнего уровня каждой из перечисленных систем. Тогда:
традиционной экономической системе в макроэкономике будет соответствовать семейный бизнес в микроэкономике (объединяет их отсутствие приказов и жёстких иерархий — только традиции и негласные правила);
плановой экономической системе в макроэкономике будет соответствовать иерархическое предприятие в микроэкономике (у обоих систем в основе План: «Госплан» и «План выпуска предприятия»; в обоих системах имеется жесткий контроль результатов на всех уровнях иерархии с процедурой согласования действий у вышестоящих руководителей/ведомств);
рыночной системе экономики должна соответствовать организация, которая бы успевала подстроиться под быстрый рыночный ритм, т.е. имела возможность быстро адаптироваться к экономическим циклам и шокам, имеющая в своей структуре схожие с рыночным регулированием механизмы, т.е. внутри организации необходима система с неким прототипом управления, схожим с рыночным… традиционная иерархическая организация под данное описание не подходит. Данные системы абсолютно различны — имеют разную природу и принципы работы (как было описано выше: традиционная иерархическая система фрактальная плановой экономики), получается что фрактал нижнего уровня рыночной экономики потерялся…
Запишу сделанный вывод:
Традиционная иерархическая система организации никак не соотносится с рыночной экономической системой, а значит не является её фракталом. Получается, что фрактал нижнего уровня рыночной системы потерян…
Это и объясняет почему организации построенные на традиционных иерархических системах не успевают за рынком — они просто не являются их продолжением. И это происходит повсеместно, практически во всём Мире (отличаются только японские методологии управления, построенные по принципам Деминга, но и там улучшения направлены на росте эффективности за счет улучшения комфорта работников, а не на соответствии рынку). Представьте масштаб… ПРАКТИЧЕСКИ ВЕСЬ МИР РАБОТАЕТ НЕЭФФЕКТИВНО!
Из написанного делаю ещё один вывод:
Что бы успеть за рынком, внутри организации необходима система, имеющая механизмы, схожие с рыночными.
Структура предприятия фрактальная рыночной экономике, миф или реальность?
Что бы успеть за быстроменяющимися рыночными условиями сейчас набирают популярность методологии «самоорганизующихся» организаций, бизнес-процессы которых устроены таким образом, что структура организации самостоятельно подстраивается под новые условия (как «живой» организм).
Идея утопическая, поэтому многие не верят в подобные системы и даже не погружаются в принципы её работы. В своё время я очень подробно изучил данный процесс (даже нарисовал BPMN схему, что в своём роде эксклюзив, которым поделюсь ниже) и постараюсь его объяснить максимально просто, давая экономическое обоснование, создав картинку работы такого предприятия в воображении (чтобы лучше запечатлелось и снилось потом во сне, шутка). Начнём…
Структура «живой» организации
Представьте иерархическую организацию с тремя уровнями управления: топ-менеджер — начальники отделов — работники. Добавляем компании Миссию, по Миссии формируем Видение и для достижения Видения задаём Цели и их цифровой аналог — План/KPI (таким образом мы определили направление развития организации и обозначили цели в цифровом виде — всё согласно стратегического менеджмента).
Учитывая то, что в заданном Плане/KPI организации каждый отдел выполняет определенную функцию, — для каждого из отделов руководителями отделов (сотрудниками, которые посвящены в верхнеуровневые процессы организации) задаются:
1) Видение отдела (т.е. организация озвучивает свою роль на рынке, отдел озвучивает свою роль в организации, повторяет фрактал), его Цели и Планы/KPI, показывающие направление развитие отдела и требуемые показатели, которые не противоречат Плану/KPI организации (условно — план организации выпустить и продать не менее 100 табуреток, тогда план отдела снабжения — заказать не менее 400 ножек и 100 сидушек; для производства — выпустить не менее 100 табуреток; для отдела продаж — реализовать не менее 100 табуреток со своими KPI отделов для самооценки работы). Таким образом — организация становится прозрачна, каждому сотруднику становится понятно, как направление развития компании, так и направление развития каждого отдела с возлагаемыми на отдел и организацию целями и планами, выраженными количественными показателями.
2) Роли сотрудников, зоны их ответственности и обязанности — своеобразное штатное расписание отдела (не всей компании!), где указывается не только количество сотрудников, но также их зоны ответственности (для администратора — аппаратная инфраструктура, для программиста — конфигурация 1С или код HTML, для бухгалтера — первичные документы, проводки 1С) и обязанности (понятный вариант должностной инструкции, где тезисно записаны выполняемые Ролью функции).
Имеются предопределенные роли сотрудников каждого отдела:
представитель от отдела, o который будет представлять интересы отдела в вышестоящем отделе. Данная роль — собирает проблемы, предложения, замечания, которые невозможно решить в рамках отдела и необходимо обсудить в вышестоящем отделе (да, в вышестоящем отделе на собраниях/совещаниях будут присутствовать два представителя: от менеджмента — начальник отдела, от отдела — представитель отдела);
фасилитатор (процедура проведения собраний/совещаний проводится по строгому алгоритму под контролем фасилитаторов, которые контролируют ход проведения совещаний, дают высказаться всем сотрудникам отдела, отсекают неконструктивные обсуждения и эмоциональные высказывания, подробнее об этом ниже);
секретарь — фиксирует результаты обсуждений, организует совещания.
Таким образом разрабатывается прототип или скелет отдела, но пока без сотрудников.
Пора нанимать сотрудников… для найма используется внутренняя биржа труда (да, сотрудники подыскиваются из числа работающих в организации!), куда подают заявки «соискатели» — т.е. сотрудники, имеющие свободное время для выполнения дополнительных функций; а также «работодатели» — отделы, в которых есть свободные Роли. А дальше как на рынке труда — за выполнение Роли назначается стоимость и начинает работать закон спроса и предложения из микроэкономики: чем выше будет назначена стоимость выполнения Роли (предложение) — тем больше будет желающих выполнять её обязанности (спрос); верно и обратное — чем больше желающих будет получить дополнительную роль (спрос) — тем дешевле будет стоимость ролей (предложение).
Пока сотрудник не найден, начальник отдела сам выполняет все незакрытые роли, поэтому заинтересован в быстром наборе сотрудников, а значит нужен пиар и позитивные отзывы работавших в отделе ранее… всё, как на рынке труда.
Итак, сотрудники набраны.
Основная задача отдела — выполнить назначенный план/KPI (во что бы то ни стало!). Если какая-то из Ролей не справляется со своей задачей (возникает «напряжение»), то вносится предложение по ускорению своей работы (решение по решению «напряжения»). Таким образом, предложения по решению «напряжений» собираются со всех сотрудников отдела по ходу выполнения рабочих обязанностей. После набора списка вопросов для обсуждения (или в установленный период времени) проводятся совещания (собрания), где собранные «напряжения» обсуждаются и принимаются решения. Совещания организуют секретари (см. предопределенные роли отдела выше).
Имеется два вида собраний:
управленческие, для решения вопросов реорганизации отдела, изменения или переназначения функций ролей, принятия решений о дополнительных ресурсах (да, эти вопросы обсуждают все сотрудники отдела, а не руководитель отдела единолично как в традиционных иерархических системах);
технические, для решения текущих оперативных вопросов (те самые «летучки», но проходящие по строгому алгоритму).
Формат обсуждения вопросов на собраниях строго регламентирован (ниже будет приведена схема обсуждений). Обсуждения сопровождают фасилитаторы, которые контролируют процессы обсуждения. Принятые в результате обсуждения решения, назначенные для выполнения Ролями работы, а также факты выполнения назначенных на предыдущих совещаниях работ фиксируются Секретарями (см. выше предопределенные роли) в протоколах.
Концепция обсуждений такая — если решение повышает эффективность отдела (то есть ни один из участников собрания не находит аргумента, который бы указывал на то, что принятие положительного решения ухудшает работу отдела), то принимается положительное решение, даже в ущерб другим сотрудникам (никаких альтернативных решений!). Сотрудники, получившие «ущерб» в результате принятия решения, могут внести очередное предложение для обсуждения как от внезапно пришедшего к ним «ущерба» («напряжения») избавиться… Таким образом — все напряжения прорабатываются и в процессе проработки напряжений отдел «развивается» (похоже на то, как в «Теории ограничения систем» находится и прорабатывается «узкое» место производство, что ведет к общей производительности предприятия, только в данном случае прорабатывается «напряжение»).
Если вопрос не может решиться в текущем отделе, то он выносится для обсуждения и принятия решения в вышестоящий отдел.
Как всё работает и почему организация приобретает статус «живой» и самоорганизующейся?
Топ-менеджер, изучив рыночную ситуацию, задаёт План/KPI организации на следующий торговый период. По Плану/KPI организации начальники отделов высчитывают и задают собственный План/KPI на отдел. Далее — начинается работа и все сотрудники работают на выполнение заданных показателей Плана/KPI.
Если нагрузка сотрудника в момент выполнения своей части работы стала очень высокой или просто возникла идея по повышению своей производительности или качества работы отдела (возникло «Напряжение»), то сотрудник подаёт предложение по оптимизации участка работы (см. рис. «Процесс разрешения напряжения», п.1):
Процесс разрешения напряжения (краткая схема)
Если для разрешения напряжения необходимо единичное действие (см. п.2.1), то формируется описание напряжения (см. п. 3.1) для добавления в список вопросов Тактического собрания (см. п. 4.1). В результате рассмотрения напряжения на Тактическом собрании (см. п. 5.1) принимается одно из решений:
рассмотрение напряжения передаётся для рассмотрения на Управленческое собрание (фиолетовый выход) — в случае, если при рассмотрении будет определено, что необходимо управленческое, а не тактическое решение;
рассмотрение напряжения передаётся для рассмотрения на Тактическое собрание верхнего или смежного Отдела/Круга (см. п.6.1) — в случае, если при рассмотрении будет определено, что в текущем Отделе/Круге решение по данному напряжению принять невозможно. Решение по напряжению от вышестоящего или смежного Отдела/Круга будет добавлено в обсуждения на очередном Тактическом совещании (см. п.6.2);
решения по напряжениям других Отделов/Кругов (см. п. 7.1) передаются в обратившийся Отдел/Круг (см. п. 7.2);
принимается положительное решение по разрешению напряжения и назначенное действие добавляется в чек-лист для проверки его выполнения на следующем собрании;
принимается отрицательное решение по предложению на разрешение напряжения.
Если для разрешения напряжения необходимо изменение структуры Отдела (Круга), т.е. необходимо пересмотреть полномочия участников и ожидания (см. п.2.2), то формируется описание напряжения с предложением о его разрешении (см. п. 3.1) для добавления в список вопросов Управленческого собрания (см. п. 4.1). Решений в данном случае может быть принято меньше:
рассмотрение напряжения передаётся для рассмотрения на Тактическое собрание (голубой выход) — в случае, если при рассмотрении будет определено, что необходимо тактическое, а не управленческое решение;
принимается положительное решение по разрешению напряжения, которое в последствии выполняется (т.е. Отдел/Круг реорганизуется, Ролям добавляются или снимаются функции и т.д.);
принимается отрицательное решение, которое не имеет какого-либо дополнительного продолжения.
По описанному алгоритму разрешаются все возникающие напряжения (см. п.9).
Вот полная схема (расширенная краткая схема, которая рассматривалась выше), где так же показаны этапы рассмотрения напряжений:
Процесс разрешения напряжения (полная схема)
Схема составлена по книгам:
Лалу, Фредерик.Открывая организации будущего. Москва : Издательство «Манн, Иванов и Фербер (МИФ)», 2014
Робертсон, Брайан. Холакратия. Революционный подход в менеджменте. Москва : Издательство «Эксмо», 2018
Соответственно, подробное описание каждого из этапов найдете в данных книгах, цитировать их в данной статье смысла не вижу.
Простая картинка показывающая смысл, заложенный в разрешении напряжений на собраниях:
Общая схема «живой» организации
Добавлю пару слов про нагрузку…
Если нагрузка на отдел растет и в результате управленческой встречи будет принято решение о создании новой Роли, то создаётся её прототип с описанием выполняемых функций и если желающих выполнять эту Роль в Отделе/Круге отсутствует, то подаётся заявка на внутреннюю биржу труда, где подыскиваются для выполнения функций Роли соискатели других Отделов/Кругов. Пока соискатель не найдет функцию роли выполняет Начальник отдела.
Если нагрузка на отдел сокращается, то есть нагрузка на Роли сократилась (или в результате управленческой встречи будет принято решение о ликвидации Роли), то сотрудники, у которых высвободилось время, подают заявки на внутреннюю биржу труда или предлагают себя в качестве исполнителей имеющихся на бирже Ролей.
Когда на бирже труда имеются только заявки на работу, без предложений от сотрудников, тогда нанимаются новые сотрудники, которые впоследствии заполняют Роли Отделов/Кругов и организация растет.
В результате, организация:
работает от Миссии, стремится достичь Видения за счет выполнения Целей, заданных Планом/KPI, т.е. имеет направление движения.
приобретает ясную прозрачную структуру, с понятными рабочими функциями, выполняемыми внутри Отдела/Круга;
легко управляется цифрами Плана/KPI (похоже на управление экономикой через ставку рефинансирования и регулирование лимитов банков в макроэкономике) без погружения в оргструктуру (задача мозгов — направлять человека в заданном направлении, а не думать за сердце — как правильно биться или за желудок — как правильно переваривать пищу… Думаю, что аналогия понятна);
максимально оптимизирована, поскольку нет «простоев» сотрудников — все зарабатывают деньги, выполняя максимальное количество возможных Ролей для получения максимального заработка, при этом имеют мотивацию к развитию — что бы впоследствии заполнить более дорогостоящие Роли;
имеющую синергетическую среду, поскольку нацелена на объединение сотрудников для выполнения поставленных целью (традиционные организации нацелены на разделение сотрудников с целью контроля их деятельности, поэтому синергии в таких организациях не возникает), а значит снова можно говорить о сокращении издержек за счет роста эффективности деятельности сотрудников;
легко масштабируется — под любой новый проект создаются Роли, на которые ищутся сотрудники (если сотрудник не находится, то увеличивается стоимость выполнения обязанностей Ролей до тех пор, пока желающие не найдутся), соответственно, не нужно будет принуждать сотрудников взять на себя дополнительные обязанности;
легко сокращаема во врем спадов — снижается План/KPI организации, после чего снижается План/KPI отделов, нагрузка на Роли сокращается и сотрудники начинают искать работу на внутренней бирже труда, где «разбирают» все Роли. Видя, что свободных Ролей нет, сотрудники принимают самостоятельное решение (а не менеджмент предприятия за сотрудников, как в традиционных иерархических организациях!) — работать со сниженной нагрузкой на имеющихся Ролях и зарабатывать меньше или пробовать искать работу в другом месте. В данной схеме, при массовых сокращениях — минимум трансакционных издержек, в сравнении с массовыми увольнениями в традиционной иерархической организации;
имеет максимально накопленный интеллектуальный капитал, созданный разумом всех сотрудников организации (а не несколькими менеджерами, как в традиционной иерархической системе);
имеет свободные каналы передачи информации без фильтрации и искажения менеджментом;
соответствует 14 принципам Деминга;
становится «бирюзовой».
В качестве заключения
Описанная система управления схожа с рыночной экономикой по ряду причин — в данной системе работают рыночные законы: при управлении через плановые показатели; при поиске работы на рынке труда; при назначении стоимости выполнения функций роли. Поэтому с уверенностью могу сказать, что описанная методология управления является «потерянным» фракталом экономической системы.
Переход на «самоорганизующиеся» методологии управления будет являться «революцией менеджмента», а значит — чем быстрее состоится переход, тем быстрее произойдет научно-технический процесс и организации начнут работать эффективнее, а значит — выпускать больше продукции с меньшей себестоимостью (за счет экономии на издержках и запуске сэкономленных таким образом денег в оборот), а значит — увеличивать ВВП и размер налогов в бюджет РФ, а значит — увеличивать расходы федерального и регионального бюджета, а значит — улучшать качество жизни граждан… а значит — увеличивать, набирающий популярность, «Международный индекс счастья».
Поэтому, хочу обратить внимание на данную методологию управления:
директоров предприятий, поскольку это реальная возможность экономить на издержках как материальных, так и временных…
топ-менеджеров, которых не совсем устраивает организация процессов в процессной, функциональной и матричной орг. структуре — в предложенном варианте структура прозрачна, масштабируема, управляема…
инвесторов, имеющих пакет непривилегированных акций (а значит имеющих слово на общих собраниях акционеров) — не мне говорить как оптимизация внутренних процессов компании влияет на стоимость акций…
министерств и ведомств, напрямую или косвенно связанных с ростом ВВП — предложенную методологию управления организаций можно отнести к научно-техническому прогрессу, что согласно классической экономической теории приводит к росту ВВП (поскольку сдвигает кривую совокупного предложения LRAS).
всем заинтересованным, поскольку внедрение предложенной методологии поменяет представление о работе, поменяет устой.
Хочу так же сказать, что я не предлагаю внедрений, платных консультаций или каких-либо других способов монетизации данной концепции, мне просто было интересно разобраться в менеджменте… если предложенная концепция заинтересовала, то у меня есть наработки по созданию автоматизированной системы на 1С, алгоритмам перехода с классической модели, кому интересно — пишите, поделюсь… так же, как и любым своим мнением по данной методологии управления — то, как её вижу и понимаю…
Всё, что тут написано — это теория, практикой поделиться не могу, так как пока не встретил владельца предприятия, согласного на эксперимент по переходу к «бирюзовому» управлению (был только небольшой опыт перехода к современным методологиям управления в команде разработки, которые описал в статье От «станков» к «растениям» или мой опыт перехода на agile)… может быть когда-нибудь организую свою «бирюзовую» организацию.
P/S: Хотелось бы красиво закончить, но обещал написать ответы на частые вопросы.
——————————————————-
— Если сотрудники управляют отделом без руководителя, то получается, что система анархична, бесконтрольна, а значит неуправляемая?
— Нет, получается, что система отчасти «анархична» (слово имеет негативный оттенок, что сбивает с толку, но по факту получается положительный эффект: группа принимает коллективное, а значит более эффективное решение, при этом каждое решение — своебразный мозговой штурм; возможность изменить что-либо в работе отдела добавляет сотруднику ответственности; появляется командная работа, синергетический эффект…), но при этом управляемая (цель — достичь поставленной цели в виде показателей, учитывая заданные организацией ограничения). Семьи, в рыночной экономике, — такая же анархическая бесконтрольная система, непонятно — кто там главный и кто за что отвечает…
——————————————————-
— Получается, что программист сможет работать и бухгалтером, вбивая первичку, и в отделе кадров и за станком в производстве? Как-то необычно…
— А почему нет, если имеются компетенции и позволяет энергия и время?
——————————————————-
— Какие основные проблемы могут возникнуть при переходе с традиционной иерархической системы к «самоорганизующейся»?
— Жесткие зарплаты; авторитарные руководители и безынициативные сотрудники; отсутствие фасилитаторов; отсутствие автоматизации… в долгосрочном периоде все эти проблемы решаемы, но в краткосроке с этим придется «повоевать».
———————————————————
— Возможно ли в традиционной иерархической системе один из отделов сделать по предложенной методологии?
— Можно (в книгах написано нельзя!), при условии, что директивность традиционного управления не будет касаться данного отдела (данный отдел будет как Лесото в ЮАР), что может не устроить традиционных менеджеров.
Мы уже не раз писали о том, что в Китае проблема с литографическими машинами и компонентами к ним. Какие-то меры по завозу принимаются, да и производители оборудования ищут возможности обойти санкции. Но Поднебесной нужно много оборудования. И сейчас, похоже, оно появилось — компания SMEE из КНР представила собственный 28-сканер.
Что это за система?
По данным Bloomberg, китайская компания Shanghai Micro Electronics Equipment Group (SMEE), которая занимается выпуском не самых современных литографических машин, представила свой первый 28-нм сканер. По словам аналитиков, если китайцы поставят производство такого оборудования на поток, им удастся избежать зависимости от иностранных производителей. Конечно, 28-нм — техпроцесс не самый современный, но для большого количества оборудования 7-нм и 5-нм чипы не нужны.
Стоит отметить, что SMEE — одна из компаний, которые получили поддержку государства. Ранее Поднебесная выделила свыше 1,5 трлн долларов для развития электронной промышленности в стране. Несмотря на некоторые проблемы, такая грандиозная программа все же показывает определенные результаты. И один из них — новый литографический сканер. Стоит отметить, что для SMEE выпуск такой машины — очень заметный успех, поскольку она ранее выпускала литографические машины для производства 90-нм чипов.
Сканер получил название SSA/800-10W, его преимущество для Китая в том, что в ходе производства используются лишь китайские компоненты. Импорта из-за рубежа нет, так что санкции повлиять на производство не могут. Во всяком случае, прямо. Конечно, Китаю нужны и более современные чипы, но 28-нм производство — уже успех по сравнению с тем, что было ранее. Скорее всего, компоненты производят Mloptic, Kingsemi и Castech — производители оптических систем из КНР. Сканер начнет работу в конце 2023 года.
К сожалению, особых подробностей пока нет — китайцы до последнего момента хранили в секрете выпуск такой системы. Только сейчас о ней узнали, так что более подробная информация, вероятно, появится несколько позже. В частности, неясно, сколько таких машин может произвести SMEE в единицу времени и хватит ли этого для покрытия нужд Китая в ближайшем обозримом будущем.
28-нм — это же совсем старая технология?
Да, конечно, это техпроцесс прошлых лет, но в Китае он до сих пор широко используется. В частности, компания SMIC, один из крупнейших контрактных производителей чипов в Китае, большую часть дохода получает от продажи 28-нм чипов.
Та же SMIC не так давно заявляла о том, что освоила 14-нм производство, но с 2022 года, когда был сделан анонс, так и не прояснилось, кто производит оборудование для выпуска таких чипов, и что это за машины. Не известно и то, в каком объеме выпускается такое оборудование.
Что касается SMEE, то эта компания работает на рынке производства литографических машин достаточно давно — примерно с 2022 года. Но до 2023 она не выпускала ничего современнее сканеров, рассчитанных на выпуск 90-нм чипов.
Кроме этой компании, в Китае есть и другие производители подобного оборудования. Но, к сожалению, после анонсов новые машины так и не были представлены. Конечно, можно предположить, что все это секретная информация, и рано или поздно КНР начнет производить большие объемы собственных чипов. Но пока об этом ничего не известно.
Тем не менее, в 2022 году AMEC заявила о разработке собственного оборудования по производству 5-нм чипов. Эта же компания заявила о предоставлении оборудования для обработки 300-мм кремниевых подложек, которое может применяться для широкого спектра техпроцессов — от 65 нм до 5 нм.
Компания HSMC начала разворачивать производственную инфраструктуру по выпуску 14-нм процессоров, говорилось и о 7-нм техпроцессе.
Совместная компания Via Technologies и правительства Китая компания выпустила процессоры KaiXian KX-6780A и KX-U6880A. Плюс еще один чип — процессор KX-6640MA X86 с частотой работы ядра 2,1 ГГц с возможность разгона до 2,6 ГГц.
Ну а Huawei начала строить собственный завод по производству современных чипов. Для начала — процессора, который получил название Kirin 9006C, он выполнен по 5-нм техпроцессу. Это восьмиядерный чип с частотой работы ядра 3,13 ГГц. Фабрику Huawei строит совместно с SMIC, еще одной достаточно известной компанией из КНР.
ASML тоже не хочет терять прибыль
ASML ищет возможность не отказываться от денег китайских заказчиков. По данным DigiTimes, нидерландская компания готовит к выпуску специальную установку, которую можно будет поставлять в КНР без лицензии. Литографическая машина позволит выпускать чипы по 28-нм и более старым технологиям. Как раз примерно то, что сейчас научились делать и сами китайцы.
Речь идет об установке Twinscan NXT:1980Di, которую выпустили в 2016 году. Но она дает возможность выпускать чипы по 7-нм техпроцессу, что и делает тайваньская TSMC — именно с этим оборудованием. Есть опровержение от ASML, но формулировка, как верно заметили комментаторы на Хабре, очень обтекаемая.
Урезанная версия не позволит китайцам производить чипы по техпроцессу, более современному, чем 28-нм. Но и это неплохо, поскольку хотя бы по части чипов у китайцев снимаются проблемы… Принимая во внимание, что львиная доля доходов SMIC поступает от поставок 28 нм и менее современных чипов, вполне вероятно, что китайские компании по-прежнему будут заинтересованы в приобретении таких инструментов.
Последние экспортные правила обязывают американские фирмы и частные лица получать лицензии на экспорт инструментов и технологий, способных производить чипы по 14/16 нм техпроцессу и ниже, 3D NAND со 128 слоями или более и микросхемы памяти DRAM с 18 нм -шаг или меньше. Те же правила применяются к неамериканским компаниям, которые экспортируют компоненты из США, как в случае с ASML и Twinscan NXT:1980Di.
Как бы там ни было, дыма без огня не бывает. Китайцы вряд ли будут рассказывать на каждом углу об успехах без хоть какой-то реальной базы для такого успеха. Осталось подождать совсем немного и станет ясно, насколько масштабным может быть производство сканеров в КНР, а также в каком объеме страна сможет выпускать свои чипы, без оглядки на США и компании, которые зависят от Штатов.
Давайте разберём на примере мой любимый GPT-3.5 Turbo.
Вот его цена:
Model
Input
Output
4K context
$0.0015 / 1K tokens
$0.002 / 1K tokens
16K context
$0.003 / 1K tokens
$0.004 / 1K tokens
А теперь по порядку.
Что за разные Модели (Model)? Названия «4K context» и «16K context» обозначают, сколько символов может обработать на входе нейросеть. «4K context» — может обработать 4 тысячи токенов «16K context» — может обработать 16 тысяч токенов * что такое токены я расскажу ниже 4 тысяч или 16 тысяч это довольно большая разница! А цена увеличивается всего в 2 раза.
Input — цена за входящий запрос Output — цена за исходящий ответ Что они обозначают, мы поймём позже
И вот они, цены: «$0.003 / 1K tokens» Что такое $0.003 мы понимаем, но что такое 1K tokens, может быть совсем непонятным! Я изначально думал, что один Токен, это один запрос. (Как же я был наивен!)
Что такое токены?
Яндексим (ищем в интернете)
Токен — это цифровой актив (сертификат), который представляет определенную стоимость, функционирует на основе блокчейна или другой децентрализованной сети и гарантирует обязательства компании перед его владельцем.
Сложно и непонятно.
Спрашиваем Chat GPT
В контексте нейросетей, термин «tokens» (токены) обычно относится к минимальным единицам, на которые разбивается входной текст или последовательность символов перед подачей на обработку модели. Токеном может быть одна буква, одно слово или даже целая фраза, в зависимости от типа и задачи модели.
В итоге мы понимаем, что Токен, это какая-то плавающая единица измерения для нейросети.
Но как так, я ведь плачу за каждую эту единицу свои деньги! Почему я не могу быть точно уверенным в объёме.
Теперь вспомним про Input и Output в начале статьи. prompt_tokens — это число токенов затраченное на входные данные Input completion_tokens — это число токенов затраченное на выходные данные Output total_tokens — всего затрачено токенов, нам это не нужно. Таким образом мы можем узнать, сколько токенов было потрачено на наш запрос.
РАССЧИТАЕМ СТОИМОСТЬ ЗАПРОСА
РАССЧИТАЕМ СТОИМОСТЬ ЗАПРОСА
Что ж, мы узнали сколько токенов было затрачено на наш запрос, теперь рассчитаем, сколько он стоил.
Формула выглядит так: --------> (p / 1000) * mi + (c / 1000) * mo = d p — (prompt_tokens) затраченное число токинов на вход с — (completion_tokens) затраченное число токенов на выходе *делим мы их на 1000, так как цена за 1000 mi — цена за 1000 токенов указанная в прайсе Input mo — цена указанная в прайсе Output d — цена в долларах
Давайте рассчитаем по нашей формуле стоимость составленного запроса, используя gpt-3.5-turbo-16k:
Вот это уже нормальная сумма, 84 копейки за запрос.
Но будем честны, даже с курсом в 91 рубль за доллар, вы его за такую цену не купите, и я бы рассчитывал на 100 рублей за доллар.
ИТОГО, почти рубль за один неплохой запрос.
А теперь представим, что на каждый вопрос в 20 символов, бот будет нам отвечать в 230 символов, и в итоге каждый вопрос будет увеличивать число на 250 символов.
И приблизительно посчитаем, сколько будет стоить диалог в 10 вопросов боту. Применим формулу для расчёта: --------> (x * 10 + y * (n * (n+1) / 2) ) * (z / x) = r x — число символов в описание y — на сколько будет увеличиваться число символов за один вопрос n — число сообщений z — цена полученная при вычислении первого запроса (у нас 0,00932) r — цена за переписку в 10 сообщений
Не хило так, одна переписка на 10вопросов нам обходится в 10 рублей и 75 копеек.
И если переписку продолжать, то цена будет продолжать расти, так как мы каждый раз тянем в новом вопросе предыдущие ответы и вопросы, чтобы чат оставался в теме.
Ещё надо учесть, что этот расчёт сделан по текущему курсу, вы скорее всего заплатите больше, покупая доллары.
🛑 Прошу заметить, что за 10 сообщений, это очень примерный расчёт! Реальную сумму мы сможем получить, только прогнав вопросы и получив на выходе число затраченных токенов.
КАК СЭКОНОМИТЬ ТОКЕНОВ В ЗАПРОСЕ
КАК СЭКОНОМИТЬ ТОКЕНОВ В ЗАПРОСЕ
Недавно узнал, что Chat GPT тратит намного меньше токенов, если говорить с ним на Английском языке!
Давайте же проверим это) Просто переведём в Яндекс переводчике наше первое описание про Рому. Получаем: «I'm a Bot Novel. Very taciturn! I say no more than 5 words. I don't like people, especially you. Rude and untidy.»
Вопрос можем задать так же на русском и ответ получим на русском: «Привет) как дела?»
Получаем такие затраты токенов: «prompt_tokens»: 55 «completion_tokens»: 13
Давайте сравним:
Название
Число Токенов на Рус
Число Токенов на Англ
prompt_tokens
76
55
completion_tokens
18
13
Уменьшение стоимости вышло примерно на 18% Уже не плохо!
Но реальная экономия начинается, когда мы делаем большие запросы!:
Название
Число Токенов на Рус
Число Токенов на Англ
prompt_tokens
2968
1568
completion_tokens
104
133
Хоть и число на формирование ответа подросло, мы получаем экономию почти в 2 раза!!! При этом, сами вопросы мы оставляем на русском.
Итоги
Я подробно описал, как рассчитать стоимость одного запроса API Chat GPT в скрытом блоке РАССЧИТАЕМ СТОИМОСТЬ ЗАПРОСА.
Если обобщить весь блок и сказать очень примерную цифру. То за 3000 русских символов в запросе мы заплатим 81 копейку с курсом в 91 рубль за доллар. И очень грубо говоря: 3000 / 81 = 0,027 копеек за одни символ. Для точных расчётов ознакомьтесь с блоком расчёта цены!
А за один хороший запрос, примерно в 5000 символов, стоимость будет в районе 1 рубля. По этому, любой сервис написанный на Chat GPT, будет стоить около 1 —2 рублей за запрос.
По итогу, стоимость Chat GPT не такая уж и маленькая, особенно, когда мы хотим добиться от неё вразумительных для нас результатов.
Большая это цена или маленькая, решать вам.
Для какого-то бизнеса подобные затраты будут копейками, а в каких-то проектах, это поставит крест на идее внедрить себе Chat GPT.
Если вам было интересно, буду рад вашему отклику и фидбеку👋
Я и дальше продолжу изучать этот сложный мир нейросетей и делиться с вами своими открытиями!
В прошлом году мы впервые провели конференцию по системному и бизнес-анализу Flow. А теперь она возвращается, и в этот раз более масштабно. Flow 2023 будет идти целых четыре дня: 4–5 сентября в онлайне и 11–12 сентября в Москве (с возможностью удалённого подключения).
Нововведение этого года — экспериментальная секция про UX, подготовленная совместно с USABILITYLAB. А общие принципы программы остались прежними. Как и раньше, будут спикеры из известных компаний (Яндекса, Альфа-банка, VK, Магнита и других). Некоторым зрителям уже известны имена Александра Белина, Юрия Куприянова, Романа Бунина, Сергея Нужненко, Ирины Гертовской и многих других.
Сейчас уже известно, о чём именно пойдёт речь в их докладах — и здесь рассказываем об этом вам.
Оценка — это важная составляющая работы команды. Грамотная оценка требует от аналитика высокого уровня экспертизы, ответственности и объективности, чтобы:
оценка понравилась заказчику;
проект принес компании прибыль, а не убытки на «затыкание дыр»;
заказчик имел ориентир по срокам, стоимости и загрузке;
команда на основе оценки этапа аналитики могла оценить объем работ по разработке и тестированию;
была создана именно та документация и в том объеме, которые требует конкретный проект.
Участников доклада ждет бонус: чек-лист оценки аналитики с выделенными типовыми фазами проектов с градацией по сложности.
Практически все, что мы анализируем или выполняем сами, выглядит как линейные процессы. Мы анализируем бизнес-проблемы, применяя техники Поиска Корневых Причин и это очень линейный подход, то есть «A потому, что B, B — потому, что С» и т. д. Анализируем возможные сопротивления проводимым сопротивлениям, например: «Менеджер А сопротивляется новому решению, потому что его отдел автоматизируют, и его сократят», что выглядит слишком упрощенно и прямолинейно.
Разрабатывая стратегию проведения изменений, мы определяем точки AS IS и TO BE и потом с завидным упорством, закрыв глаза, как танки прем по линии, соединяющей эти точки.
Но, работая с бизнесом, мы забываем, что любая организация — это, прежде всего, сложная система, то есть совокупность большого количества элементов и сложных взаимных связей. Поэтому, выполняя анализ, мы должны рассматривать систему во всей ее сложности и, что не менее важно, в динамике.
В докладе обсудим применение техник Системного Мышления в работе бизнес-аналитика.
Представьте мир, где все вокруг нас соединено и умеет «думать» — от холодильника до всего города. Это не научная фантастика, это реальность сегодняшнего дня, которую мы называем интернетом вещей (IoT). Добавьте в эту картину искусственный интеллект (AI) и машинное обучение (ML) — компьютеры, которые учатся и «думают» самостоятельно. Понимание новых технологий этого мира — новый аналитический вызов в IT.
Какие особенности в постановках задач? Как развивать свои компетенции? В докладе вы познакомитесь с примерами проектов, связанных с IoT, и узнаете, как системным и бизнес-аналитикам готовиться к встрече с новыми технологиями.
Результаты проектирования воспринимаются через артефакты. Ирина и Екатерина поделятся своим опытом и расскажут, почему подход к проектированию от артефактов губителен. Покажут, как связаны между собой проектные слои и почему любое новое требование порождает цепь изменений. Помогут сориентироваться, как контролировать, оценивать эти изменения и следить за качеством работоспособности всей модели.
В докладе рассмотрим:
три экзистенциальных вопроса разработки;
DDD — разумная коллаборация при проектировании;
нужные артефакты в нужных местах;
биогеоценоз (связей и зависимостей артефактов);
метрики — не «хайп», а индустриальный стандарт.
База повествования основывается на опыте как в продуктовой разработке, так и в «кровавом энтерпрайзе».
GameDev-область всегда приковывала к себе внимание специалистов, особенно в последние годы. И, как известно, в GameDev-команде нет ролей системных и бизнес-аналитиков. Но значит ли это, что анализ вообще отсутствует в разработке игр? А если он все-таки есть, то на каком этапе и в каком объеме?
Для ответа на эти вопросы, в докладе будут рассмотрены командные роли и этапы разработки игр через призму анализа и постановки задач. Также Всеволод расскажет об используемых гибких методологиях Getting Real и Crystal Agile на примере построения процессов в реальном GameDev-стартапе и об эволюции этих процессов.
Доклад будет полезен всем, кому интересен опыт организации работы в компаниях с нуля, и кто хочет посмотреть на пример построения стартапа изнутри в современных реалиях IT-индустрии в России.
По статистике, около 80% проектов внедрения ERP-систем являются неуспешными. Как бизнес-консультант, Татьяна готовила компании к внедрению ИТ-систем (обследование предприятия, описание процессов, обучение), осуществляла поддержку интегратора при внедрении и доработке ИТ-системы. Ее команда проанализировала бизнес-кейсы и выявила наиболее часто повторяющиеся ключевые ошибки, которые негативно влияют на проекты внедрения и часто недооцениваются ИТ-интеграторами.
Доклад будет интересен бизнес-аналитикам, разработчикам, IT-архитекторам и руководителям проектов.
Название профессии аналитика подразумевает, что он только разбирается в предметной области и выдает результат анализа. Но на практике системные и бизнес-аналитики занимаются не столько анализом, сколько проектированием системы — какие в ней должны быть функции, как пользователь будет выполнять свои задачи, как будет устроена база данных, какие будут API, интеграции и формы отчетов. Иногда они даже проектируют интерфейсы.
Эта работа часто не выделяется и даже не осознается аналитиком, а значит, не всегда проверяется и выполняется качественно.
В докладе Юрий рассмотрит процессы анализа и проектирования, чтобы понять: а нужно ли их принципиально разделять. Также он даст аналитикам инструменты и набор практик, которые позволят более осознанно подходить к процессу проектирования систем.
Татьяна Ошуркова
Росбанк
Регулярные выражения — известный инструмент с очень большими возможностями.
В докладе пойдет речь о регулярных выражениях, области их применения и правилах использования. Будет рассмотрена возможность использования регулярных выражений в работе системного аналитика и разобраны реальные кейсы решения задач с использованием регулярных выражений.
Материал будет полезен системным аналитикам различного уровня, работающим с различным технологическим стеком.
Анастасия расскажет о плюсах и минусах low-code платформы, предпосылках к переводу системы на новый стек, а также поделится опытом импортозамещения. Доклад будет полезен системным аналитикам, которые принимают участие в выборе архитектуры для новых проектов, а также занимаются развитием low-code платформы.
Рост роли данных при принятии решений растет, но при этом большинство компаний внедряет новые дата-продукты и масштабирует аналитические команды бессистемно. В результате то, что работало на малом масштабе, перестает работать с развитием команды данных.
В докладе разберем понятие data governance и ответим на вопрос: как компаниям идти в сторону data-driven, если внедрять все и сразу — невозможно?
Разберемся в целях инструментов дата-менеджмента, приоритизируем их внедрение в соответствии со стадией развития бизнеса, расскажем о глобальном тренде на гибридизацию хранилищ. Обсудим, как бизнесу и аналитикам научиться говорить на одном языке.
Аналитик работает с большим объемом информации, поэтому всегда хочется, чтобы она была структурирована и наглядна. Для этого используют различные инструменты визуализации. Один из них — Miro — сервис, который поможет в планировании, написании требований, проведении ретроспективы. Более того, важно, что этот инструмент позволяет работать удаленно для всей команды. Ольга расскажет на практических кейсах, как аналитики могут применять Miro и какие у него есть плюсы и минусы.
Что вы понимаете под «обратной разработкой», когда слышите эти слова? Что специалисты этого профиля знают значения падающих зеленых буковок в матрице? Или, может, вы вспоминаете кадры с Беном Аффлеком из «Часа расплаты», где герой скопировал проектор для голограммы?
Борис разберет виды обратной разработки, то, как они применяются в тех или иных сферах, а также некоторые результаты этого процесса, которые мы, возможно, используем каждый день. И как эти результаты могут помочь в развитии продукта и улучшении бизнес-процессов.
Генеративный AI наделал много шума и уже начал менять процесс разработки ПО. Хорошим примером являются специализированные средства для разработчиков типа GitHub Copilot и Tabnine, для тестировщиков — Testim и Diffblue.
Для системных и бизнес-аналитиков пока нет специальных тулов, но при правильном использовании приложений «для всех» типа ChatGPT можно сильно ускорить процесс разработки требований и спецификаций.
Екатерина расскажет, какие задачи системного и бизнес-анализа в разработке ПО можно решать уже сейчас, какие инструменты будут полезны и как ими пользоваться для получения лучших результатов.
Что, если перестать хранить документацию в привычном всем месте? И не только требования, но и пользовательские инструкции (user guides), и архитектуру, и логику работы продукта?
В докладе Наталья поделится опытом переноса документации в репозиторий, расскажет про markdown и красивое форматирование, а также обсудит инструментарий — Docsify, Git и новых «старых» друзей аналитиков.
Ксения расскажет, с какими сложностями сталкивается аналитик и продакт при разработке внутренних сервисов, используемых во множестве корпоративных продуктов одной компании, на примере VK.
У команды Ксении есть сервисы приема платежей, авторизации и ряд других, которые связывают продукты группы, а также позволяют оптимизировать процессы. Цель доклада — подсветить моменты, на которые стоит обращать внимание при разработке требований, чтобы получить:
контролируемые ожидания заинтересованных лиц,
систему, которую можно развивать и дальше масштабировать,
систему с контролируемыми границами,
систему, которая гармонично выстроится в существующее окружение.
При разработке требований к таким комплексным системам очень легко либо потерять требования и сделать ненужную систему, либо сделать все, что просят внутренние проекты компании, но система станет неподдерживаемой.
Доклад будет полезен аналитикам, работающим в крупных компаниях во внутренних продуктах, и аналитикам, работающим с b2b-сегментом в продуктах со множеством зависимостей или интеграций.
Когда в первый раз сталкиваешься с написанием требований безопасности, начинаешь по привычке выявлять их примерно так же, как и обычные функциональные требования. Только через какое-то время понимаешь, какой это на самом деле «крепкий орешек» в плане выяснения реальной потребности, и сколько подводных камней ты в первый раз упустил.
В докладе показаны самые частые препятствия, с которыми можно столкнуться на этом пути, и как эти препятствия можно обойти. Будут рассмотрены основные методы борьбы: законы и стандарты, модель угроз, затыкание дыр. Узнаем, как связаны требования безопасности с другими типами нефункциональных требований.
Доклад будет полезен всем, кому интересны требования безопасности вне зависимости от количества знаний в этой области. Особенно тем, кто сталкивался с проблемами в их формулировании.
С приходом гибких практик нам стало казаться, что требования не нужны. Пользовательские истории — это не требования, и все остальное, что может лежать в бэклоге, — тоже.
Сергей расскажет, почему так получилось, с какими проблемами мы сталкиваемся, когда перестаем целенаправленно работать с требованиями, и что же теперь делать.
Доклад будет полезен всем, кто не застал начало Agile 20–25 лет назад, чтобы у них был выбор в организации работы. А те, кто все видел своими глазами, смогут подискутировать с Сергеем.
Для того, чтобы в компании не создавались дашборды на каждый чих, необходимо использовать структурированные подходы к проектированию системы отчетов. Если вам знакомы такие проблемы, как «невозможно найти, в каком отчете какая метрика», «расчеты между отчетами не сходятся», «а давайте сделаем еще один дашборд», то этот доклад поможет вам их избежать.
Специалисты по DS хорошо умеют пользоваться метриками для оценки качества своих моделей. Но очень часто эти метрики сложно отобразить на реальные потребности бизнеса. А иногда и сами DS-специалисты плохо могут объяснить их смысл. Попросите, например, их объяснить обычному человеку, что такое расстояние Кульбака – Лейблера, и они почувствуют, что и сами плохо это понимают.
При этом понимание того, как DS-метрики могут повлиять на итоговые бизнес-результаты — важнейший вопрос, который необходимо прояснить на самых ранних этапах проекта. Сделать это можно с помощью построения пирамиды метрик, которая поможет понять, как можно пересчитать эти нетривиальные ROC-AUC в реальную экономию фонда оплаты труда или другие важные бизнес-показатели.
В докладе на примерах из реальных проектов будут показаны шаги по построению таких связей. Для этого участникам предстоит неглубоко погрузиться в мир DS-метрик.
Собрать, проанализировать требования и спроектировать целевое решение — это, как известно, только верхушка айсберга. Важно довести решение до прода и попутно не заработать кучу седых волос для себя и команды.
Для этого аналитик должен уметь управлять скоупом и изменениями требований во время реализации. Об этих процессах спикер и расскажет.
Обсудим, какие инструменты аналитик может использовать для управления требованиями, как быть с конфликтами и как изменения могут восприниматься в разных командах в зависимости от методологий управления разработкой.
Александр расскажет, как его команда написала свой плагин на Java к Trino и использует его в связке с Apache Superset для эффективной аналитики данных через BI-коннектор к Битрикс24.
Александр поделится опытом многопользовательской настройки (multitenance), масштабирования решения, настройки мониторинга, проведения нагрузочных испытаний и конфигурации для подключения Trino к другим аналитическим платформам через JDBC/ODBC (на примере DBeaver). Подробно расскажет про тонкости безопасной настройки и развертывания Apache Superset с/без контейнеризации под различные задачи BI-аналитики и под различные нагрузки.
Data Science-специалисты обладают уникальными навыками анализа больших данных, машинного обучения и статистики, которые позволяют им извлекать ценные знания из огромных объемов информации.
В докладе рассмотрим некоторые примеры успешного использования Data Science в медицине. От прогнозирования заболеваний и ранней диагностики до индивидуального подбора лечения и анализа эффективности медицинских процедур. Data Science открывает новые возможности для улучшения здоровья и качества жизни пациентов.
Кроме медицины, Data Science находит применение в других предметных областях, таких как банковское дело и агрегаторы. Например, банки используют алгоритмы машинного обучения для обнаружения мошеннических транзакций, а агрегаторы данных помогают оптимизировать процессы и принимать обоснованные решения на основе больших объемов информации.
Системному аналитику при сборе требований необходимо учитывать наличие Data Science-специалиста в команде и уметь работать с его потребностями. Их сотрудничество позволяет определить цели проекта, установить необходимые данные и разработать эффективные алгоритмы для анализа.
Архитектура — это всеобъемлющее понятие, обязательным элементом которого являются требования. Хорошая архитектура возникает только на хорошо исследованном ландшафте, т. к. он становится базой для формулирования действительно значимых решений в ней.
Подход «Архитектура как код» позволяет интегрировать всех участников производственного процесса в единый, непрерывный конвейер. Он способен охватить производство от стратегических целей бизнеса до развертывания на продакшене. В идеальном случае — это цифровой двойник производства.
При таком подходе аналитик получает возможность исследовать архитектурный ландшафт, максимально приближенный к реальности и генерировать действительно актуальные и обоснованные требования с учетом реального положения дел. Он также получает в свои руки инструмент, способный реализовать все его потребности в управлении требованиями, и контроль их реализации.
С4 model — популярный подход к описанию архитектуры, который постепенно становится стандартом и получает поддержку в визуальных средствах проектирования.
Денис расскажет о своем опыте применения C4 model: в каких случаях каждая диаграмма будет полезна, какие средства позволяют рисовать диаграммы, в том числе, получать результат в виде кода, который можно положить в репозиторий для просмотра истории и аппрува изменений. А также о том, как прокачать свои скилы на каждом уровне, описанном в C4.
Сергей расскажет про распил большого монолита «Системы управления транспортом» в компании «Магнит». Данная система управляет планированием и контролем движения более 10 000 автомобилей в онлайн-режиме. Коротко пройдется по функциям, которые выполняет система. Расскажет, на каких технологиях был построен монолит, какие ошибки были совершены при его проектировании и какие проблемы возникли при его разрастании. Затронет тему образования команд и как им удалось добиться лучшей производительности. Расскажет про прототипирование и ошибки, которые допустила команда. Затронет тему прототипирования: как создали прототип и получили еще один дополнительный монолит, с которым теперь борются. Осветит архитектуру получившихся микросервисов: с чего начинали, куда пришли и от чего пришлось отказаться.
Поверхностное изучение материалов по корпоративной архитектуре (Enterprise Architecture) создает впечатление, что это что-то из области TOGAF, Zachman и ArchiMate. Но в реальности успешные архитектурные практики в организациях не имеют практически ничего общего со всеми этими «стандартами». В докладе анализируются наиболее популярные заблуждения про архитектуру предприятия и объясняется, как обстоят дела на самом деле.
Планирование сложных изменений в корпоративных информационных системах обычно сопровождалось разработкой и согласованием полноценного описания архитектуры такого изменения. Но рост количества изменений, потребность в сокращении сроков их осуществления и постоянный дефицит квалифицированных ИТ-архитекторов заставляет искать более простые альтернативы.
Максим расскажет, может ли такой альтернативой выступать запись архитектурного решения (architecture decision record), как его разработать, какие существуют форматы описания архитектурных решений и практики их подготовки.
В продолжение рассказа о преимуществах нотации ArchiMate, Дмитрий поделится практическими тактиками и практиками по моделированию и управлению архитектурой с применением метаданных и расширений этого языка. На примерах рассмотрим, как добавить дополнительных смыслов и получить больше, чем просто картинку.
В докладе рассмотрим, как построить современные команды разработки и, в частности, команды разработки мобильных приложений за счет привлечения системного аналитика. Обсудим компетенции, которыми должен обладать аналитик, чтобы команда работала наиболее эффективно с точки зрения взаимодействия с другими командами и клиентом, а также оптимально использовала имеющиеся ресурсы.
Максим расскажет о том, как создать среду и взаимодействие в командах, которые помогают прокачиваться аналитикам и со временем решать все более сложные задачи. Как постепенно пройти путь от новичка до solution-архитектора, а главное – как создать такую среду, в которой бы этот путь было комфортно проходить.
Аналитик владеет многими знаниями, но часто их не использует. Максим и Анна расскажут, как аналитикам осознать свое потенциальное лидерство и влиять на продукт, даже без официального титула.
Решения принимаются на основе данных. Вооружившись правильными коммуникативными навыками, аналитик сможет правильно воздействовать на команду и стейкхолдеров для достижения общей цели.
Александр расскажет про карьерные треки системных аналитиков. Ведь когда-то и они дорастают до ведущих и оказываются перед развилкой. Свой рассказ Александр построит так, чтобы мы прошли от типовых вариантов к эзотерическим:
руководство группой аналитиков;
роль тимлида в кросс-функциональной команде;
переход в технические продакт-менеджеры;
переход в архитектуру.
Рассказ будет строиться на личном опыте и примерах из практики Тинькофф, где Александр руководит большим юнитом (900+ человек), курирует архитектурные вопросы, а также видел все приведенные выше варианты или сам помогал им реализоваться.
Достаточно часто студенты спрашивают, как правильно описать задачу для разработчика, чтобы он ее понял и сделал так, как нужно.
На этот вопрос нет однозначного ответа. Все зависит от уровня аналитика, уровня разработчика, их вовлеченности в проект и от предметной области. Чтобы лучше разобраться, как разработчику понятнее и проще осознавать и делать задачи, Иннокентий с Максимом обсудят разные варианты постановок — от высокоуровневых User Story до подробнейшей спецификации — и разберут их плюсы и минусы.
Дмитрий расскажет о своей методике исследования пользователей: как в условиях жестких временных ограничений понять, чем они занимаются, из каких задач устроен их рабочий день и с какими трудностями они сталкиваются.
Сбор требований к продукту — важный этап, который определяет границы функциональности и формирует представление команды о том, как в итоге должна работать система. Требования могут быть описаны текстом, сопровождаться блок-схемами или набросками будущих экранов продукта. Полнота этих данных определяет качество продукта, и зачастую бывает так, что в требованиях упущен какой-то сценарий целиком или какой-то блок. Это все приводит к тому, что продукт надо будет доделать, переделать, исправить в нем дефекты или откатывать релиз.
Знакомая ситуация?
Алексей расскажет о том, какой подход к передаче требований они сформировали в АльфаСтраховании. Почему и как он помогает минимизировать риск возвращаться, чтобы переделывать или доделывать дизайн-макеты.
Доклад посвящен практике применения Customer Journey Map (CJM) в качестве языка коммуникации в продуктовой команде. Также поговорим о применении этого инструмента для личных целей.
Дизайн-система является неотъемлемой частью современных приложений. Она обеспечивает визуальную целостность и является ДНК приложения.
Команда Алевтины пришла к пониманию необходимости создания своей дизайн-системы и выделения под это отдельной команды, чтобы закрыть боли, которые возникли. В результате они выделили пять ключевых причин, почему дизайн-система необходима для приложений и должна стать неотъемлемым компонентом процесса разработки. Выработали процесс работы с командой, сформировали шаблон технических требований к UI-компонентам, на основе которых разработка компонентов стала проще и быстрее.
Для внутренних продуктов они разработали дизайн-систему «Фламинго», которая помогает командам разработки и дизайна быстро справляться с трудностями, обеспечивает единообразный стиль приложений и структуру компонентов и элементов дизайна.
Применение дизайн-системы способствует созданию приложений высокого уровня в кратчайшие сроки, снижает расходы на разработку и поддержку приложений. Она также помогает упростить процедуру обновления дизайна приложений и модернизацию приложений в целом.
Целевая аудитория доклада: PO, системные и бизнес-аналитики, дизайнеры, разработчики.
Михаил Греков расскажет про UX в емкой и доходчивой форме, понятной системным и бизнес-аналитикам. Будем говорить не про дизайн, а про пользовательский опыт и его измерение.
Последние пять лет Семен занимается заказной разработкой документации для российских IT-компаний. Разговор почти с каждым клиентом начинается с фразы: «Нам нужно всё задокументировать, помогите нам в этом».
Опыт показывает, что разные компании понимают под этой формулировкой довольно разные вещи, и «всё» в разных компаниях тоже отличается. В практике команды спикера эти просьбы сводятся к пяти направлениям работы:
Описание требований к уже существующей системе — реверс-инжиниринг требований.
Создание пользовательской документации.
Создание архитектурной документации, адресованной исключительно разработчикам.
Создание API-документации — причем обычно речь идет о вводных и обучающих статьях (howtos/tutorials), а не к непосредственному написанию аннотаций к методам.
Комментарии в коде — в стиле Javadoc или в свободном формате.
В докладе обсудим, что общего у этих направлений, чем они отличаются и что делать, если вам нужно решить одну из подобных задач. Доклад будет интересен всем, кто занимается разработкой документации, и всем, кто руководит или участвует в таких активностях.
Знакома ли вам ситуация, когда на вопрос «А где документация» твой наставник или руководитель гордо отвечает «Я и есть документация»?
Такое положение дел может доставить много хлопот, тем более если бизнес растет, а процессы укрупняются и усложняются. Здесь на помощь может прийти создание базы знаний — инструмента, который решает сразу несколько задач:
улучшить поиск нужной информации;
улучшить обмен знаниями и опытом;
уменьшить количество ошибок;
улучшить взаимодействие и координацию между разными командами.
Практик по созданию базы знаний много, поэтому решили агрегировать опыт сразу двух компаний — «Кошелёк» и Lamoda Tech — и поделиться сборным рецептом эффективного построения и управления базой знаний.
Приходите на доклад, чтобы получить концентрированную пользу сразу от двух экспертов: поговорим обо всех нюансах в формате живой дискуссии, и сведем все важные советы и инструкции в один большой чек-лист.
Классические методы анализа и проектирования информационных систем предполагают проведение этапов обследования предприятия, проведение серии интервью, моделирование бизнес-процессов, разработку требований и их согласование. Для среднего проекта эти работы могут занимать недели, если не месяцы.
Методика Event Storming позволяет существенно сократить сроки и трудоемкость аналитических работ за счет замены индивидуальных сессий работы и мучительных офлайновых согласований на контактную работу в формате специализированных очных или онлайн-семинаров.
Денис познакомит с этой техникой и покажет особенности ее применения в работе для повышения эффективности работы команд.
В настоящий момент одна из самых распространенных нотаций для графического описания бизнес-процесса — BPMN (Business Process Model and Notation). Но все ли используют этот инструмент по назначению? Какую из нотаций для описания процессов вообще выбрать? Большинство компаний, с которыми работает команда спикера, используют различные нотации для описания схем процессов только для того, чтобы включить их в нормативный документ. Но если мы говорим об указанных нотациях, они дают компаниям гораздо больше возможностей.
Дарья расскажет о том, какие нотации для описания процессов вообще существуют, в чем их принципиальное отличие и как их применять в разных контекстах: автоматизации бизнес-процессов, имитационном моделировании и функционально-стоимостном анализе, создании программных роботов.
Целевая аудитория доклада: руководители компаний, руководители департаментов, операционные директоры, HRD.
Process Mining — современная технология для анализа процессов на базе цифровых следов в информационных системах, сейчас активно набирает популярность среди бизнес-аналитиков, специалистов по управлению процессами, операционных менеджеров и внутренних аудиторов. Технология применима для анализа процессов из разных областей — продаж, закупок, логистики, бэк-офиса. Применение технологии позволяет удешевить процесс в среднем более, чем на 10%.
В мире существует большое количество коммерческих и open source-инструментов для пользователей разных уровней — от бизнес-пользователей до датасаентистов. Основные игроки на западном рынке process mining — SAP, IBM, Software AG, UI Path.
В Сбере технология process mining применяется с 2018 года. Реализовано более 200 проектов по анализу и оптимизации процессов. Применение технологии позволяет выявить узкие места в процессе, сформировать оптимальный сценарий выполнения и удешевить процесс в среднем более чем на 10%.
Сбер разработал два собственных инструмента: платформу Sber Process Mining для бизнес-пользователей и аналитиков и open source-библиотеку SberPM для датасаентистов. Оба инструмента активно применяются как Сбере, так и за его пределами.
Воркшоп для аналитиков, кто уже 100500 раз читал про Kafka и топики, но так и не разобрался, почему они организованы именно так. На практических примерах разберем ключевые концепции Kafka: топики, партиции, consumer-группы и репликацию.
Приходите, если готовы думать и рисовать, а не только слушать. Воркшоп будет полезен для аналитиков middle-уровня, имеющих общее представление о брокерах сообщений, но слабо знакомых с Kafka.
Большинство разработчиков создают и вносят изменения в различные API месяцами или годами, и это типичный сценарий, но что происходит, когда нужно удалить API? Вот тогда обнаруживаются различные проблемы, которые находятся за пределами контроля.
Артём расскажет, как его команда строила архитектуру мобильного приложения для сотрудников Альфа-Банка. Особенность заключалась в том, что нужно было объединить под капотом десятки корпоративных систем без огромного штата разработчиков.
Они выбрали микросервисную архитектуру: frontend на ReactJS, Middle-часть — на Node.js (NestJS). А сервисы внутри приложения разрабатывались с адаптивным вебом: сделали один раз — работает в вебе и мобилке.
Доклад будет полезен аналитикам, архитекторам, продактам, которые выбирают технологические решения для своих продуктов.
Напоследок
Напоминаем, что конференция — это не только доклады. Офлайн-часть — это всегда возможность вволю пообщаться, подойти к стендам компаний-партнёров, познакомиться с новыми людьми. Но даже онлайн-участники смогут как следует позадавать вопросы спикерам: для этого у нас существуют специальные «дискуссионные зоны» после каждого доклада». Так что приходите не просто послушать спикеров, но и как следует обсудить сказанное.
Конференция Flow 2023 пройдет 4–5 сентября в онлайне и 11–12 сентября в Москве (с возможностью подключиться удалённо и к московской части).
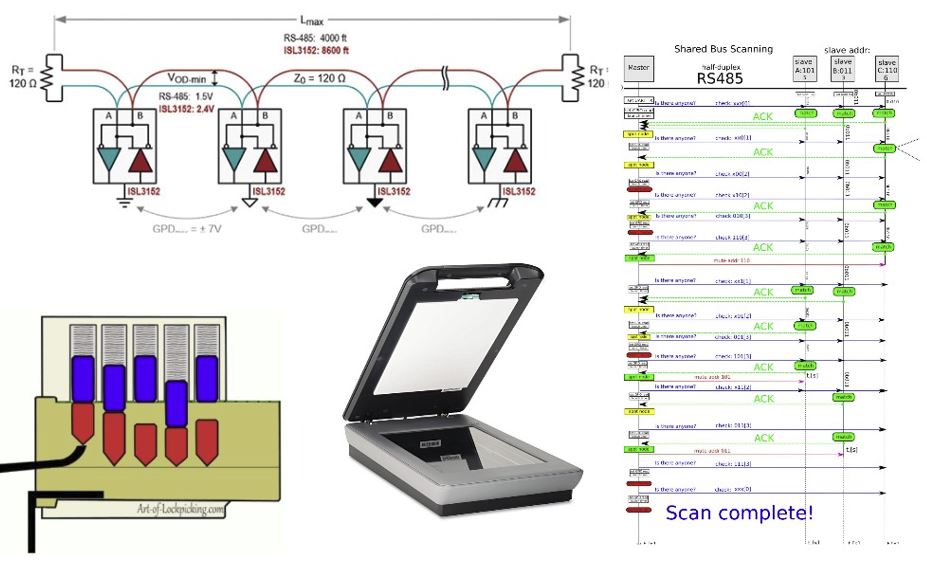





")
")
\", 2014")





























































