Интернет-платформы вроде Amazon Mechanical Turk позволяют компаниям разбивать работу на небольшие задачи и предлагать их людям со всего света. Демократизируют ли они работу, или же эксплуатируют беспомощных?

Каждое утро после пробуждения Кристи Миланд [Kristy Milland] запускает свой компьютер в Торонто, логинится в Amazon Mechanical Turk и ждёт, когда раздастся сигнал звоночка.
Amazon Mechanical Turk (AMT), существующий уже более 10 лет, это онлайн-платформа, где люди могут за деньги выполнять небольшие задачи. Миланд ищет публикации с предложениями задач – в системе они называются «HIT» – и уведомления сообщают ей, когда задачи соответствуют её критериям. «Уведомления приходят раз в минуту,- говорит Миланд. – Я отрываюсь от своих дел и смотрю, хороший ли это HIT, перед тем, как принять предложение о работе».
Иногда встречаются групповые HIT-задания. «Если подбирается группа, а сейчас обед, или у меня визит к врачу, или надо выгуливать собаку,- говорит Миланд,- я бросаю всё и выполняю задачу. Я привязана к компьютеру. Если только так вы можете прокормить своих детей, уйти у вас не получится». Она занимается этим уже 11 лет.
Миланд – одна из более чем 500 000 «туркеров» – контрактных работников, выполняющих небольшие задачи на цифровой платформе Amazon, которую они зовут mTurk. Количество активных работников, живущих по всему свету, составляет от 15 000 до 20 000 ежемесячно, согласно Паносу Ипеиротису [Panos Ipeirotis], профессору информатики из бизнес-школы Нью-Йоркского университета. Туркеры работают от нескольких минут до 24 часов в день.
Кто такие туркеры? Согласно Ипеиротису, в октябре 2016 года американскими туркерами были в основном женщины. В Индии это в основном мужчины. Если брать всю планету, то их годы рождения будут лежать в промежутке от 1980 до 1990. 75% — американцы, 15-20% — из Индии, 10% — из других стран.
Реквестеры – люди, компании, организации, дающие работу на аутсорс – назначают стоимость каждого задания, и эти задания очень широко варьируются. Среди них встречается:
• Категоризация данных;
• Проставление метатэгов;
• Распознавание символов;
• Ввод данных;
• Сбор емейлов;
• Смысловой анализ;
• Размещение рекламы в видео.
К примеру, одной из недавних задач Миланд была транскрипция содержимого чека. Компания, заказавшая эту работу, продаёт информацию маркетологам и исследовательским отделам из компаний типа Johnson & Johnson, P&G, и т.п. За эту задачу платили 3 цента (около 2 рублей).
Ранние годы AMT
Миланд называет себя жителем цифрового мира. «Половую зрелость я встретила с интернетом», говорит она. Она говорит, что «всегда подрабатывала в интернете», используя платформы типа eBay для получения дополнительного дохода. И когда она наткнулась на статью о возможностях зарабатывать кликами после запуска Amazon Mechanical Turk в 2005 году, это казалось идеальным предложением.

Иконографика (англ) по развитию подобного типа работы (кликабельно)
В ранние годы Миланд казалось, что это больше эксперимент, чем реальная работа. Но во время кризиса 2008-2009 всё поменялось. Миланд, руководившей детским садом, пришлось переехать, и она потеряла доход. В то же время потерял работу и муж. Она начала работать с АМТ на полную ставку. Для неё это означает 17 часов в день ежедневно. «Мы начали смотреть на это, как на работу. И мы начали спрашивать с этого, как с работы».
Рошель Лаплант [Rochelle LaPlante] из Лос-Анджелеса, работает в АМТ полный день с 2012 года. Лаплант соглашается с Миланд в том, что работа непредсказуемая. «Неизвестно, когда опубликуют задачу. Это может быть 3 утра. А в 9 утра вообще нечего делать».
«Я не такая упорная, как некоторые,- говорит Лаплант,- поскольку я ценю сон». Другие, по её словам, ставят уведомления. «Если реквестер публикует запрос в 3 утра, компьютер издаёт сигнал, телефон издаёт сигнал, и они встают и выполняют работу. Они подчинены этому графику».
Ни у Миланд, ни у Лаплант, нет «обычного» рабочего дня. Обычно они задают себе планку по количеству заработанных денег. В нормальный день Лаплант может работать 8 часов. «Но это 10 минут там, 20 минут сям – и всё это накапливается», говорит она.
И сколько же в среднем зарабатывают туркеры? Сложно сказать. Эдриен Жабур [Adrien Jabbour] из Индии говорит, что «можно считать достижением, если ты заработал $700 за два месяца работы по 4-5 часов в день». Миланд говорит, что недавно за 8 часов она заработала $25, и для неё это было «неплохо». По данным Pew Research Center, немногим более половины туркеров зарабатывают меньше уровня минимальной заработной платы, установленного в США — $7,25 в час.
Лаплант рассказывает о трудных решениях, которые ей приходилось принимать, выбирая между работой и жизнью. «Мне нужно было решать – сделать работу или пойти на семейный ужин? Для людей, живущих на эти деньги, на грани выселения, такие решения бывают очень трудными».
Продвинутые туркеры
Грустная реальность работающих в АМТ людей состоит в том, что не все туркеры созданы равными. Система Amazon назначает некоторых работников «специалистами» [Master’s Level]. Когда новый реквестер размещает HIT, система автоматически ищет туркеров такого уровня. Это стоит больше для реквестера и приносит больше денег работникам. Если у вас нет этого уровня, вам достанется меньше работы. В один из будних дней марта, говорит Миланд, в системе было 4 911 задач. Она могла выбирать 393 из них – всего 8%.
А как же получить звание специалиста? Никто не знает. Миланд видела, как неквалифицированные люди – с малым количеством выполненных задач, с малым рейтингом, подставными или приостановленными учётными записями – получали это звание. «В этом не видно никакой системы», говорит она.
Amazon не публикует свои критерии для достижения этого уровня. На форумах туркеров водятся разные теории насчёт получения уровня специалиста. Иногда происходит публикация набора задач, и те, кто успешно справляются с ними, получают этот уровень. «Для этого требуется оказаться в нужном месте в нужное время», говорит Миланд.
Кроме уровня специалиста, существуют и региональные ограничения. Если вы находитесь не в США, это плохо – многие реквестеры ограничивают исполнителей этим регионом.
Зарплата
«Нет двух одинаковых туркеров,- говорит Лаплант. – Некоторые с этого кормятся, другие зарабатывают на карманные расходы».
Уильям Литл – модератор TurkerNation, онлайн-сообщества туркеров из Онтарио. Он получает с АМТ дополнительный доход. Он стремиться заработать $15 в день за три часа работы. «В большинстве случаев это достижимо,- говорит он,- и это лучше, чем заработок в начале карьеры». Но оплата – основная трудность для многих туркеров.
Сейчас деньги получают только туркеры из США и Индии. Другие, включая Миланд и Литла, получают подарочные карты Amazon.
Литл ездит на машине 45 минут до границы с США, где он может получить вещи с Amazon с бесплатной доставкой, и забирает свои покупки. Существуют обходные пути для тех, кто хочет получать зарплату деньгами, но обычно они связаны с уменьшением доходов. Разные веб-сайты, типа purse.io, могут конвертировать подарочные карты, например, в биткоины.
«Вы размещаете свой список желаний на purse.io. Я его вижу, и решаю купить какой-либо предмет. Я его заказываю и отправляю вам,- говорит Литл. – Биткоины хранятся в эскроу. Когда вы получаете покупку, я получаю биткоины». Потом Литл может их продать, получить деньги через PayPal и перевести их в банк. «Я дважды плачу за переводы, и это того не стоит».
Ещё одна проблема – неоплаченный труд. Вашу работу могут отвергнуть без объяснений. Кроме того, туркеры тратят время на оценку работы, ищут репутацию реквестера. Загружают скрипты, добавляют инструменты, проверяют статистику.
Рабы компьютеров
Миланд и Лаплант участвуют в невидимой онлайновой рабочей силе – а именно такая сила всё больше востребована для тренировки умных машин. Умные системы постепенно проникают в повседневный быт, ИИ всё больше используется обществом. Под управлением сегодняшних ограниченных версий ИИ находится всё, от голосовых виртуальных помощников, типа Amazon’s Alexa и Microsoft’s Cortana, до систем компьютерного зрения, лежащих в основе автопилота в автомобилях Tesla.
Эти системы обучают выполнять задачи, исторически бывшие слишком сложными для компьютеров, и они варьируются от понимания произносимых вслух команд до распознавания пешеходов на дороге.
Часто для обучения ИИ-систем решению этих сложных задач используют большое количество помеченных примеров. Им скармливают огромное количество данных, заранее размеченных на предмет критичных для задачи характеристик. Например, это могут быть фотографии, снабжённые примечаниями о наличии на них собак, или предложения, в которых отмечено, относится ли слово «ключ» к замкам или к родникам. Процесс обучения машин на примерах называется контролируемым обучением, и проставлением ярлыков обычно занимаются туркеры и другие онлайн-работники.
Такое обучение требует огромных объёмов данных, некоторым системам требуются миллионы примеров для эффективного выполнения работы. Эти наборы велики, и постоянно растут. Google недавно рассказал о наборе Open Images Dataset с 9 миллионами изображений, а в репозитории YouTube-8M содержится 8 миллионов помеченных видеороликов. В ImageNet, одной из самых ранних баз данных этого типа, содержится более 14 миллионов изображений, разбитых по категориям. Два года её создавало 50 000 человек – большинство из которых было нанято через АМТ. Они проверяли, сортировали, помечали почти миллиард изображений из потенциальных кандидатов.
Из-за масштабов этих наборов данных, даже распределённых среди множества работников, каждому из них приходится повторять одно и то же действие сотни раз. Это работа чёрная, и крайне утомительная умственно.
Кроме раздачи ярлыков, туркеры и другие работники часто подчищают наборы данных, используемых для машинного обучения. Убирают дубликаты, заполняют пустоты и т.п.
С повальным распространением ИИ каждая технологическая фирма вовлекает людей в выполнение таких микрозадач, связанных с машинным обучением. Amazon, Apple, Facebook, Google, IBM и Microsoft – все крупнейшие технологические компании – либо обладают собственной платформой для краудворкинга, либо отдают эти задачи на аутсорс по контракту внешним компаниям. Из этих компаний крупнейшими являются Amazon Mechanical Turk и CrowdFlower.
Внутренние платформы для микроработы, такие, как Universal Human Relevance System (UHRS) от Microsoft или EWOK от Google, используются довольно активно. Около пяти лет назад, после запуска UHRS, было известно, что платформа используется в поисковике Bing и в других разнообразных проектах Microsoft, обрабатывая при этом 7,5 миллионов задач в месяц.
Согласно Мэри Грэй [Mary Gray], главному исследователю Microsoft, UHRS очень похожа на Amazon Mechanical Turk. Грэй утверждает, что компания использует UHRS для набора работников в тех регионах, где «влияние Amazon Mechanical Turk представлено недостаточно полно», или же в случае чувствительных секретных заданий.
«Каждая компания, заинтересованная в автоматизации услуг, обращается к какому-либо аналогу платформ типа АМТ. И на самом деле многие из них используют непосредственно АМТ», говорит она.
Крис Бишоп [Chris Bishop], директор исследовательской лаборатории Исследовательского центра Microsoft в Кембридже, говорит, что UHRS позволяет компании быть «чуть более гибкой» по сравнению с внешними платформами, например, с той же АМТ. Он говорит, что фирма использует ИИ для автоматического определения сильных и слабых сторон работников, таких, как относительный уровень экспертных знаний, что помогает компании назначать результатам работы этих людей различные оценки важности.
Кроме помощи в тренировке ИИ такие платформы, как АМТ, используются такими известными брендами, как eBay и Autodesk – они сбрасывают повторяющуюся и рутинную работу, которая вот уже много лет составляет большую часть всех заданий в АМТ.
Эта монотонная работа, не требующая навыков, включает множество задач: просмотр картинок и другого контента, созданного пользователями (иногда это приводит к неприятному опыту), маркетинговые и научные исследования, удаление повторяющихся записей, проверка описаний продуктов и изображений дли нтернет-магазинов. Amazon создала АМТ для себя, для управления ассортиментом, категоризации изображений и продуктов, создания описаний, извлечения имён из электронной почты, перевода текста, транскрипция текста из аудио и картинок, исправления правописания, проверки географического расположения, создания обратной связи по веб-дизайну, обзоров продуктов, выбора кадров, представляющих видео, и получение рекламными фирмами информации о том, на какую часть рекламы вы обратили внимание.
Как мы дошли до этого?
В идее о помощи, оказываемой людьми машинам в выполнении задач, которые иначе оказались бы для последних неподъёмными, нет ничего нового. Хотя недавний взлёт ИИ неимоверно увеличил запросы на категоризацию данных, такие микрозадачи, по словам Грэя, встречались ещё лет 20 назад, когда такая работа была связана с попытками улучшить проверку правописания текстовыми процессорами, такими, как Microsoft Word. В более широком смысле работа кликеров и выполнение микрозадач встречались ещё во времена подъёма интернет-магазинов во время пузыря доткомов, в конце 1990-х и начале 2000-х.
В 2001 году Amazon, выискивая новые пути в эффективной организации продуктов в своём быстрорастущем магазине и решения складских проблем, не поддававшихся компьютерам, запатентовала гибридную систему машина/человек. Через четыре года Amazon реализовала свою цель построения цифровой платформы для доступа к большому количеству онлайн-работников, запустив Amazon Mechanical Turk.
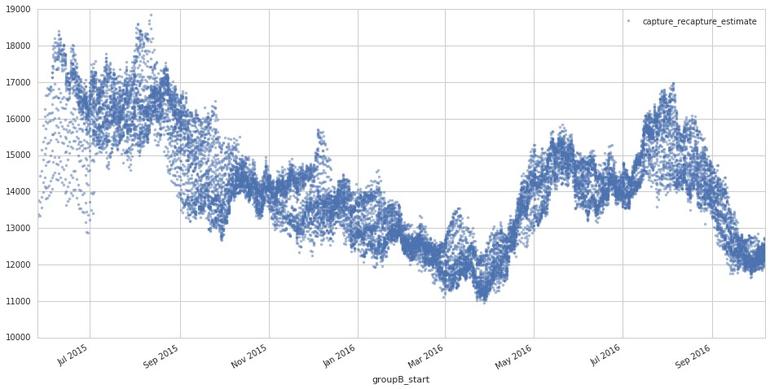
Примерное количество активных участников проекта АМТ, с июля 2015 до октября 2016
Идея о возможности доступа к «искусственному искусственному интеллекту», как описала Amazon свой проект, понравилась самым разным компаниям; все они, от интернет-магазинов до порносайтов, искали возможности недорогой сортировки своих продуктов.
В 2015 году ежедневно свои задачи на АМТ размещали в среднем 1278 заказчиков. И хотя количество выполняемой неутомимыми тружениками работы растёт, особенно у таких сайтов, как CrowdFlower, точные её объёмы неизвестны, поскольку довольно большая её часть ведётся без записей или же выдаётся повторно многим работникам.
И хотя, согласно информации с сайта Amazon, на работу в АМТ подписалось уже 500 000 человек, из этих цифр непонятно, как именно люди используют краудворкинговую платформу – как работу на полный день, или как подработку.
Отчёт от Всемирного банка, The Global Opportunity in Online Outsourcing [Мировые возможности в онлайн-аутсорсе], оценивает, что у двух крупнейших платформ для работы с микрозадачами, Amazon Mechanical Turk и CrowdFlower, совместные доходы составили порядка $120 млн в 2013 году. Профессор Вили Ледонвирта [Vili Lehdonvirta], адъюнкт-профессор и главный научный сотрудник в Оксфордском институте интернета предполагает, что эта сумма составляет от 5 до 10% мирового рынка труда, но указывает на трудности в получении реальных цифр занятости для платформ не на английском языке.
Прочая стоимость кликерства
Монотонность такой работы может иметь для выполняющих её людей нехорошие последствия. Она может серьёзно расстроить физическое и моральное здоровье некоторых из них.
«Я просыпаюсь, игнорируя всё остальное,- говорит Миланд. – Моя семья готовит мне еду и оставляет её, чтобы я могла есть во время работы. Я ем за компьютером, не вижу свою семью. Если моей дочери нужна помощь с домашним заданием, ей нужно обращаться к отцу. Дошло до того, что у меня в запястье развилась гигрома. У меня постоянно болели связки в руке. Мне повезло, что я работала так в то время, когда дома был и мой муж, когда у него не было работы. Если домашние слышали звонок с моего компьютера, обозначавший высокооплачиваемую работу, они говорили мне ‘Давай, давай, давай!’ ».
Туркер из южной Индии, Маниш Батия [Manish Bhatia], был модератором-волонтёром на форуме MTurk Forum почти два года, а сейчас модерирует два форума. Самое странное, что его просили сделать – снять себя лежащим в ванне в окружении лепестков роз. «Это было очень странно», говорит он. По поводу странных изображений он также жалуется на то, что иногда ему приходится видеть неприятные картинки. «Заранее ничего неизвестно,- говорит он. – Уклониться от работы можно потом». Но в этом случае вам не заплатят, и время будет потеряно.
Миланд тоже жаловалась на подобный опыт. «Люди говорят мне, ‘Ого, ты работаешь дома? Тебе повезло!’,- говорит она. – Нельзя рассказать им, что я сегодня назначала картинкам тэги, и все картинки были связаны с ИГИЛ. Там была, к примеру, корзина с отрезанными головами. И это я видела совсем недавно. Мне пришлось проставлять тэги к видео с горящим человеком. Платили по 10 центов за фото».
Не только Миланд приходиться ставить тэги к графике или непонятным изображениям. «Вчера на очередном наборе видео с YouTube,- говорит Лаплант,- было очень много обезглавливаний. Внизу есть галочка под названием „неподходящее содержимое“, и ты жмёшь „Отправить“. Это работа может быть важна для предотвращения появления неприятного контента в онлайне, но она же может наносить вред выполняющим её людям. Оплата работы не всегда соответствует ценности проделанной работы для YouTube или его пользователей.
Литл говорит, что ему часто приходилось ставить тэги к порнографическим видео или фотографиям. „И я делал исключения только в случаях, когда встречал детскую порнографию,- говорит Литл. – Я сообщал об этом реквестеру и в Amazon“. Но по поводу кровищи и издевательств Литл говорит, что это „часть работы“.
По завершению задачи невозможно узнать, что происходит с результатом. „Интересно, кто-нибудь будет это просматривать? Надеюсь, что об этом сообщат и удалят,- говорит Лаплант. – Кто-то наткнулся на детскую порнографию, отметил галочку, но кто-либо будет это проверять и расследовать? Мы не знаем“.
Реквестеры работают под псевдонимами, и никто не знает, кто заказал эту работу. Лаплант называет это „диким Западом“. И в то время, как реквестеры назначают туркерам рейтинги, туркеры не имеют возможности рейтинговать реквестеров.
»Ты отмечаешь лица в толпе, но может это кто-то готовит что-то с вредоносной целью, или что-то вроде этого,- говорит она. – Вы не знаете, чем занимаетесь, никакой информации нет".

«Это называется замещающей травматизацией,- говорит Джон Сулер [John Suler], профессор психологии в Университете им. Райдера, специализирующийся на поведении в киберпространстве. – То же происходит с людьми, первыми увидевшими ужасные изображения. Они получают травму». По его словам, мы не всегда понимаем психологические последствия этого. «Наше сознание становится невосприимчивым,- говорит Сулер. – Но подсознание этого не делает – оно всё впитывает. Мы недооцениваем то, как всё, что мы видим в онлайне, влияет на наше подсознание».
Работающие таким образом люди находят онлайн-форумы, чтобы связываться друг с другом и делиться историями, выражать сочувствие и поддерживать друг друга. «Вокруг оплаты и модерации контента возникает очень много вопросов», говорит Миланд. «И в таких местах можно найти социальную поддержку».
У каждой из общественных платформ есть свои особенности. Форум MTurk Forum похож на разговоры у офисного кулера. Напротив, по словам Миланд, Mturkgrind «кажется более сосредоточенным на продуктивности и эффективности». TurkerNation «концентрируется на ответах на вопросы и помощи новичкам в понимании системы».
Есть ещё закрытая группа в Facebook под названием Mturk Members, где уже 4436 членов. Они задают вопросы, хвалятся заработками и поддерживают друг друга.
Лаплант и три другие женщины создали форум MTurk Crowd, чтобы помогать туркерам находить нужные ресурсы и выполнять работу наилучшим образом. Есть ещё много всяких форумов, сабреддитов и других онлайн-платформ.
Существует сайт для работников WeAreDynamo.org. Именно там стартовала кампания "Дорогой Джеф Безос". Кампания пыталась очеловечить туркеров, дать право голоса людям, активно участвующим в жизни этой платформы. Они делились опытом и высказывали опасения по поводу сути своей работы.
Но это мало что поменяло. Хотя у работников из Индии открылась возможность получать зарплату безналичным переводом, ни Amazon, ни Джеф Безос не обращались к кампании напрямую.
Каким-то образом общаться с Amazon практически невозможно. «Отсутствие поддержки раздражает,- говорит Батия. – Нет ни чата, ни телефона». Единственный способ связи – это электронные письма, в ответ на которые приходят стандартные отписки.
«Я весьма озадачена теми решениями, которые они принимают,- говорит Литл,- и первое из решений – недостаток коммуникаций. Почему они не хотят заниматься этим? Вряд ли из-за возможностей исков, потому что их правила работы прямо запрещают такие вещи».
Миланд беседовала с юристами, но «никто из них никогда не поддержит работника в борьбе против Amazon», говорит она. Amazon отказывается общаться. «Ни по поводу отказов, ни по поводу улучшений, ни по поводу наших предложений об увеличении их прибыли – никак».
Лили Ирани [Lilly Irani], преподающая в Калифорнийском университете в Сан-Диего, изучает «культурную политику методов выполнения высокотехнологичной работы». Ирани участвовала в проведении исследования в 2013 году, во время которого учёные подробно изучали форумы туркеров. Исследование проводилось в попытках понять, как могут работать совместные действия – на примере таких проектов, как Dynamo, коллективная платформа туркеров, и Turkopticon, позволяющего туркерам писать обзоры заданий и ставить им оценки. В работе «Turkopticon: прерванная невидимость работников в Amazon Mechanical Turk» авторы отметили: «Мы утверждаем, что АМТ занимается построением инфраструктуры на основе своих работников и прячет их труд, превращая их в вычислительный ресурс для технологов».
Несмотря на плохие условия труда, Миланд и другие люди полагаются на доход от АМТ. Состояние здоровья Миланд не позволяет ей надеяться на традиционную работу. «Я пыталась устроиться в Макдональдс, и меня не взяли», говорит она.
Люди работают вместе с ИИ
Грэй из Microsoft считает, что такого рода трудоустройство по требованию постепенно перерастёт в системы человек+ИИ, в которых появится симбиоз людей и машин.
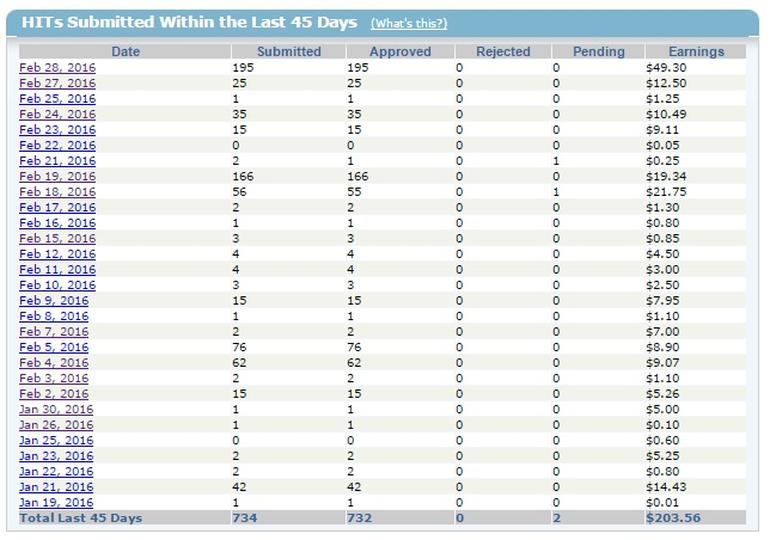
Таблица задач и оплаты Кристи Миланд. Submitted – выполненные, но ещё не признанные легитимными задания. Approved – оплачиваемые. Rejected – работа была выполнена, но реквестер не принял результаты или не оплатил их.
Она ссылается на появление виртуальных ассистентов, например, Facebook M, или чатботов поддержки, например, Amelia от IPsoft, где люди обрабатывают запросы при помощи ИИ, или ИИ обрабатывает запросы, а человек берёт управление в случаях, разобраться с которыми машине не по силам. Со временем такие системы обучаются на основе ответов людей и постепенно увеличивают спектр обрабатываемых ими запросов.
Появляется всё больше сервисов, использующих специализированный ИИ для выполнения простых задач и людей для более сложных. Один из главных центров краудсорсинга, CrowdFlower, недавно запустил платформу машинного обучения, призванную выполнять задачи, которые ранее решали бы люди. Людям остаётся "сконцентрироваться на более сложных случаях и помогать моделям МО обучаться". Такой подход автоматизирует гору ручной работы, но оптимистичные прогнозы утверждают, что хотя процент работы, выполняемой людьми, будет уменьшаться, общее количество рабочих мест уменьшаться не будет, поскольку будет возрастать количество запросов на использование систем человек+ИИ.
Как долго машинам ещё нужны будут люди?
Но как долго ещё людям будет необходимо тренировать умные системы? ИИ уже справляется с многими заданиями, которые ранее выполнялись людьми.
В 2006, через год после запуска АМТ, директор Amazon Джефф Безос сказал, что раньше, чтобы понять, есть ли определённое лицо на фотографии, нужен был человек, а теперь эту задачу может решить система глубокого обучения, нейросети, работающие в таких компаниях, как Baidu, Facebook, Google и Microsoft. Значит ли это, что микрозадачи, обеспечивающие людям занятость сегодня, завтра отойдут в область машин?
Ледонвирта не считает, что спрос на микрозадачи, связанные с ИИ, будет удовлетворён. Он предсказывает, что чем больше задач можно будет решать при помощи машинного обучения, тем больше данных необходимо будет обработать людям. «Это движущаяся цель. Вариантов задач так много, что я не думаю, что подобная работа закончится в ближайшее время», говорит он.
Бишоп считает, что в ближайшем будущем ИИ будут тренировать гибридно – как через контролируемое обучение под руководством людей, так и через неконтролируемое. Грэй считает, что участие людей будет необходимо ещё очень долго: «Более того, потребность в людях будет возрастать, потому что будет возрастать количество задач, подлежащих автоматизации,- говорит она. – Если взять за образец ранние примеры обработки естественного языка или распознавания образов, станет видно, что работы в системе более чем достаточно».
Доктор Сарвапали Рамчурн [Sarvapali Ramchurn], адъюнкт-профессор в департаменте электроники и информатики Саутгемптонского университета, использует пример распознавания изображений для иллюстрации объёма работ, которые ещё нужно выполнить людям. «Мы и близко не подошли к ограничениям. Разметка изображений всё ещё требует человеческого участия в любой области, в которой были собраны эти изображения».
Фотографии можно получать в таком огромном количестве типов окружения – на свету, в тени, частично заслонённые,- что «даже после классификации 50 миллионов изображений, лишь малая часть запечатлённых там предметов будет точно классифицирована во всех возможных контекстах», говорит он. И добавляет, что если расширить объём работ до распознавания речи, понимания естественного языка, распознавания эмоций и множества других областей, в которых применяют ИИ, будет видно, что поток работы не собирается иссякать. Кроме того, общество постоянно обнаруживает новые области применения ИИ. «Запросы, скорее всего, будут только расти, и мы увидим больше систем, комбинирующих работу людей и ИИ новыми способами с целью решения реальных задач».
Работа как сервис
Нужны ли будут люди для тренировки ИИ в будущем, или нет, рост популярности платформ типа АМТ отражает происходящий сдвиг в области рынка труда.
Грэй считает, что точно так же, как ускорение глобальных коммуникаций позволило отдавать на аутсорс всё больше бизнес-задач, так и краудсорсинговые платформы вкупе с обилием людей, обладающих широкополосным выходом в интернет, изменят рынок труда. «Мы смогли разбить работу полного дня на части с тем, чтобы её в круглосуточном режиме выполняли разные люди в разных часовых поясах из разных мест», говорит она. «Мы не то, чтобы упростили труд или понизили требуемую для его выполнения квалификацию, а, скорее, разбили его на модули, за которые могут браться разные группы людей». Грэй считает, что в будущем такой способ работы, переключение между микрозадачами, станет общепринятым.
Поскольку онлайн-платформы лучше научились быстро связывать заказчиков с исполнителями, имеющими нужный для выполнения задачи опыт, то и использование практики микроработы будет распространяться и расти, говорит она. «Мы наблюдаем индустрию работы, которая назначается, планируется, управляется, оплачивается и отправляет готовые результаты через API», говорит Грэй. «Всё это развивается со скоростью взрыва прямо у нас под носом».
Ледонвирта разделяет видение Грэй в том плане, что компьютерные системы всё чаще будут управлять распределением труда. «Такие вещи, как организация работы при помощи компьютера, использование специальных платформ для регулирования рабочих взаимоотношений, набирают популярность», говорит он.
С ростом количества подключённых к интернету людей и популярности краудсорсинговых платформ правительства должны начать обращать внимание на то, как это влияет на жизнь людей, говорит Грэй. «Нам ещё предстоит понять, как именно такой подход поменяет подход большинства людей к работе», говорит она. «Этот процесс идёт уже 30 лет. Мы не обращали на него внимания, поскольку он не затрагивал людей во власти и их детей».
ссылка на оригинал статьи https://geektimes.ru/post/284244/
 Пятница, вечер, 30 декабря, мы традиционно запилили развлекательный сервис «Новогодний колл-центр 2017». В этом году значительно расширили возможности по распознаванию речи у платформф и поэтому для демонстрации этих возможностей широкой публике сделали мини-игру для хабраюзеров. Каждый желающий может
Пятница, вечер, 30 декабря, мы традиционно запилили развлекательный сервис «Новогодний колл-центр 2017». В этом году значительно расширили возможности по распознаванию речи у платформф и поэтому для демонстрации этих возможностей широкой публике сделали мини-игру для хабраюзеров. Каждый желающий может