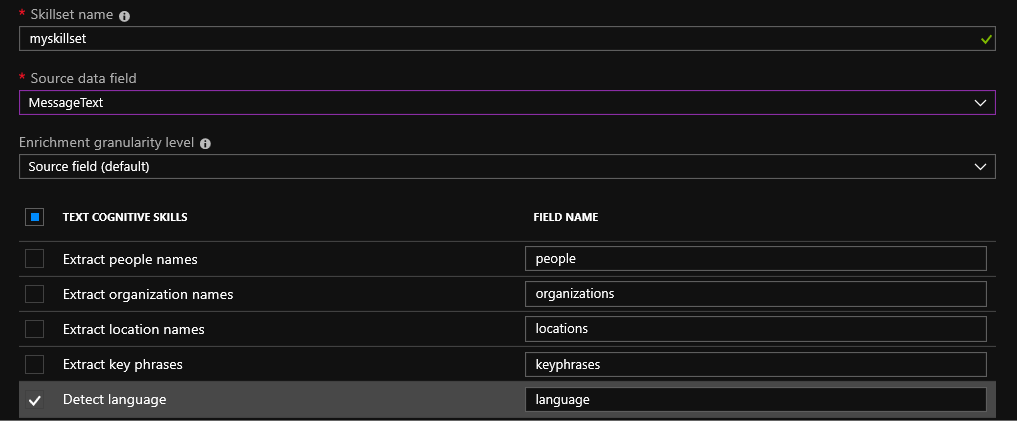
Пару месяцев назад мне наконец пришлось признать, что я недостаточно умён, чтобы пройти некоторые уровни головоломки Snakebird. Единственным способом вернуть себе часть самоуважения было написание солвера. Так я мог бы притвориться, что создать программу для решения головоломки — это почти то же самое, что и решить её самому. Код получившейся программы на C++ выложен на Github. Основная часть рассматриваемого в статье кода реализована в search.h и compress.h. В этом посте я в основном буду рассказывать об оптимизации поиска в ширину, который бы потребовал 50-100 ГБ памяти, чтобы он уместился в 4 ГБ.
Позже я напишу ещё один пост, в котором будет описана специфика игры. В этом посте вам нужно знать, что мне не удалось найти никаких хороших альтернатив грубому перебору (brute force), потому что ни один из привычных трюков не сработал. В игре множество состояний, потому что есть куча подвижных или толкаемых объектов, при этом важна форма некоторых из них, которая может меняться со временем. Не было никакой пригодной консервативной эвристики для алгоритмов наподобие A*, позволяющих сузить пространство поиска. Граф поиска был ориентированным и заданным неявно, поэтому одновременный поиск в прямом и обратном направлении оказался невозможным. Единственный ход мог изменить состояние множеством несвязанных друг с другом способов, поэтому не могло пригодиться ничего наподобие хеширования Зобриста.
Приблизительные подсчёты показали, что в самой большой головоломке после устранения всех симметричных положений будет порядка 10 миллиардов состояний. Даже после упаковки описания состояний с максимальной плотностью размер состояния составлял 8-10 байт. При 100 ГБ памяти задача оказалась бы тривиальной, но не для моей домашней машины с 16 ГБ памяти. А поскольку Chrome нужно из них 12 ГБ, мой настоящий запас памяти ближе к 4 ГБ. Всё, что будет превышать этот объём, придётся сохранять на диск (старый и ржавый винчестер).
Как уместить 100 ГБ данных в 4 ГБ ОЗУ? Или а) состояния нужно сжать в 1/20 от их исходного, и так уже оптимизированного размера, или б) алгоритм должен иметь возможность эффективного сохранения состояний на диск и обратно, или в) сочетание двух вышеприведённых способов, или г) мне нужно купить больше ОЗУ или арендовать на несколько дней мощную виртуальную машину. Вариант Г я не рассматривал, потому что он слишком скучный. Варианты А и В были исключены после proof of concept с помощью gzip: фрагмент описания состояний размером 50 МБ сжался всего до 35 МБ. Это примерно по 7 байт на состояние, а мой запас памяти рассчитан примерно на 0,4 байта на состояние. То есть оставался вариант Б, даже несмотря на то, что поиск в ширину казался довольно неудобным для хранения на вторичных накопителях.
Содержание
Это довольно длинный пост, поэтому вот краткий обзор последующих разделов:
- Поиск в ширину «по учебнику» — какова обычная формулировка поиска в ширину (breadth-first search, BFS), и почему она не подходит для сохранения частей состояния на диск?
- BFS с сортировкой и слиянием — изменение алгоритма для эффективного пакетного избавления от избыточных данных.
- Сжатие — снижение объёма используемой памяти в сто раз благодаря сочетанию стандартного и собственного сжатия.
- Ой-ёй, я сжульничал! — в первых разделах я кое о чём умолчал: нам недостаточно просто знать, где находится решение, а нужно точно понимать, как его достичь. В этом разделе мы обновляем базовый алгоритм, чтобы он передавал достаточно данных для воссоздания решения из последнего состояния.
- Сортировка + слияние со множественным выводом — хранение большего количества состояний полностью сводит на нет преимущества сжатия. Алгоритм сортировки + слияния необходимо изменить, чтобы он хранил два набора выходных данных: один, хорошо сжатый, используется во время поиска, а другой применяется только для воссоздания решения после нахождения первого.
- Своппинг — своппинг в Linux намного хуже, чем я думал.
- Сжатие новых состояний перед слиянием — до данного момента оптимизации памяти работали только со множеством посещённых состояний. Но оказалось, что список новых сгенерированных состояний намного больше, чем можно было подумать. В этом разделе показана схема для более эффективного описания новых состояний.
- Экономия пространства на родительских состояниях — исследуем компромиссы между использованием ЦП/памяти для воссоздания решения в конце.
- Что не сработало или может не сработать — некоторые идеи казались многообещающими, но в результате их пришлось откатить, а другие, которые предполагались рабочими из исследований, интуитивно мне кажутся неподходящими в данном случае.
Поиск в ширину «по учебнику»
Как выглядит поиск в ширину, и почему в нём не стоит использовать диск? До этого небольшого проекта я рассматривал только варианты формулировок «из учебников», например, такие:
def bfs(graph, start, end): visited = {start} todo = [start] while todo: node = todo.pop_first() if node == end: return True for kid in adjacent(node): if kid not in visited: visited.add(kid) todo.push_back(kid) return False
В процессе создания программой новых узлов-кандидатов каждый узел проверяется с хеш-таблицей уже посещённых узлов. Если он уже есть в хеш-таблице, то узел игнорируется. В противном случае он добавляется и в очередь, и в хеш-таблицу. Иногда в реализациях информация «visited» заносится в узлы, а не в стороннюю таблицу; но это рискованная оптимизация и она совершенно невозможна, если граф задан неявно.
Почему использование хеш-таблицы проблематично? Потому что хеш-таблицы склонны к созданию совершенно случайного паттерна доступа к памяти. Если они этого не делают, то это плохая хеш-функция, и хеш-таблица скорее всего будет иметь низкую производительности из-за коллизий. Этот случайный паттерн доступа может вызывать проблемы с производительностью, даже если данные умещаются в памяти: доступ к огромной хеш-таблице с большой вероятностью будет вызывать промахи кэша и буфера ассоциативной трансляции (TLB). Но что если значительная часть данных находится на диске, а не в памяти? Последствия будут катастрофическими: что-то порядка 10 мс на одну операцию поиска.
При 10 миллиардах уникальных состояний только для доступа к хеш-таблице нам понадобится около четырёх месяцев ожидания дискового ввода-вывода. Это нам не подходит; задачу совершенно точно нужно преобразовать так, чтобы программа могла обрабатывать большие пакеты данных за один проход.
BFS с сортировкой и слиянием
Если бы мы стремились максимально объединять операции доступа к данным в пакеты, то какой бы была максимально достижимая приблизительность? Поскольку программа не знает, какие узлы обрабатывать в слое глубины N+1 до полной обработки слоя N, кажется очевидным, что нужно выполнять дедупликацию состояний по крайней мере один раз за глубину.
Если мы одновременно работаем с целым слоем, то можно отказаться от хеш-таблиц и описать множество visited и новые состояния как какие-нибудь отсортированные потоки (например, как файловые потоки, массивы, списки). Мы можем тривиально найти новое множество visited с помощью объединения множеств потоков и столь же тривиально найти множество todo с помощью разности множеств.
Две операции со множествами можно объединить, чтобы они работали за один проход с обоими потоками. По сути мы заглядываем в оба потока, обрабатываем меньший элемент, а затем продвигаемся вперёд по потоку, из которого был взят элемент (или по обоим потокам, если элементы в их начале одинаковы). В обоих случаях мы добавляем элемент в новое множество visited. Затем продвигаемся вперёд по потоку новых состояний, а также добавляем элемент в новое множество todo:
def bfs(graph, start, end): visited = Stream() todo = Stream() visited.add(start) todo.add(start) while True: new = [] for node in todo: if node == end: return True for kid in adjacent(node): new.push_back(kid) new_stream = Stream() for node in new.sorted().uniq(): new_stream.add(node) todo, visited = merge_sorted_streams(new_stream, visited) return False # Merges sorted streams new and visited. Return a sorted stream of # elements that were just present in new, and another sorted # stream containing the elements that were present in either or # both of new and visited. def merge_sorted_streams(new, visited): out_todo, out_visited = Stream(), Stream() while visited or new: if visited and new: if visited.peek() == new.peek(): out_visited.add(visited.pop()) new.pop() elif visited.peek() < new.peek(): out_visited.add(visited.pop()) elif visited.peek() > new.peek(): out_todo.add(new.peek()) out_visited.add(new.pop()) elif visited: out_visited.add(visited.pop()) elif new: out_todo.add(new.peek()) out_visited.add(new.pop()) return out_todo, out_visited
Паттерн доступа к данным теперь совершенно линеен и предсказуем, на всём протяжении слияния нет никаких произвольных доступов. Поэтому задержка операций с диском становится нам не важной, и единственное, что остаётся важным — пропускная способность.
Как будет выглядеть теоретическая производительность при упрощённом распределении данных по 100 уровням глубины, в каждом из которых есть по 100 миллионов состояний? Усреднённое состояние будет считываться и записываться 50 раз. Это даёт 10 байт/состояние * 5 миллиардов состояний * 50 = 2,5 ТБ. Мой жёсткий диск предположительно может выполнять чтение и запись со средней скоростью 100 МБ/с, то есть на ввод-вывод в среднем уйдёт (2 * 2,5 ТБ) / (100 МБ/с) =~ 50к/с =~ 13 часов. Это на пару порядков меньше, чем предыдущий результат (четыре месяца)!
Стоит также заметить, что эта упрощённая модель не учитывает размер новых сгенерированных состояний. Перед этапом слияния их нужно хранить в памяти для сортировки + дедупликации. Мы рассмотрим это в разделах ниже.
Сжатие
Во введении я сказал, что в первоначальных экспериментах сжатие состояний не выглядело многообещающим, и показатель сжатия равен всего 30%. Но после внесения изменений в алгоритм состояния стали упорядоченными. Их должно быть намного проще сжать.
Чтобы протестировать эту теорию, я использовал zstd с головоломкой из 14,6 миллионов состояний, каждое состояние которой имело размер 8 байт. После сортировки они сжались в среднем до 1,4 байта на состояние. Это походит на серьёзный шаг вперёд. Его недостаточно, чтобы выполнять всю программу в памяти, но он может снизить время ввода-вывода диска всего до пары часов.
Можно ли как-то улучшить результат современного алгоритма сжатия общего назначения, если мы что-то знаем о структуре данных? Можно быть практически уверенными в этом. Хорошим примером этого является формат PNG. Теоретически сжатие — это просто стандартный проход Deflate. Но вместо сжатия сырых данных изображение сначала преобразуется с помощью фильтров PNG. Фильтр PNG по сути является формулой для предсказания значения байта сырых данных на основании значения того же байта в предыдущей строке и/или того же байта предыдущего пикселя. Например, фильтр «up» преобразует каждый байт вычитанием из него при сжатии значения предыдущей строки, и выполняя противоположную операцию при распаковке. Учитывая типы изображений, для которых используется PNG, результат почти всегда будет состоять из нулей или чисел, близких к нулю. Deflate может сжимать такие данные намного лучше, чем сырые данные.
Можно ли применить подобный принцип к записям состояний BFS? Похоже, что это должно быть возможно. Как и в случае с PNG, у нас есть постоянный размер строки, и мы можем ожидать, что соседние строки окажутся очень схожими. Первые пробы с фильтром вычитания/прибавления, за которым выполнялся zstd, привели к улучшению показателя сжатия ещё на 40%: 0,87 байт на состояние. Операции фильтрации тривиальны, поэтому с точки зрения потребления ресурсов ЦП они практически «бесплатны».
Мне не было ясно, можно ли внести ещё какие-то улучшения, или это является практическим пределом. В данных изображений можно логично ожидать, что соседние байты одной строки будут схожи. Но в данных состояний такого нет. Но на самом деле чуть более сложные фильтры всё равно могут улучшить результаты. В конце концов я пришёл к такой системе:
Допустим, у нас есть соседние строки R1 = [1, 2, 3, 4] и R2 = [1, 2, 6, 4]. При выводе R2 мы сравниваем каждый байт с тем же байтом предыдущей строки, и 0 будет обозначать совпадение, а 1 — несовпадение: diff = [0, 0, 1, 0]. Затем мы передаём эту битовую карту, закодированную как VarInt, за которой следуют только байты, не совпавшие с предыдущей строкой. В этом примере мы получим два байта 0b00000100 6. Сам по себе этот фильтр сжимает эталонные данные до 2,2 байт / состояние. Но скомбинировав фильтр + zstd, мы снизили размер данных до 0,42 байт / состояние. Или, если сказать иначе, это составляет 3,36 бит на состояние, что всего немного больше наших примерных вычисленных показателей, необходимых для того, чтобы все данные уместились в ОЗУ.
На практике показатели сжатия улучшаются, потому что отсортированные множества становятся плотнее. Когда поиск достигает точки, где память начинает вызывать проблемы, показатели сжатия могут становиться намного лучше. Самая большая проблема заключается в том, что в конце мы получаем 4,6 миллиардов состояний visited. После сортировки эти состояния занимают 405 МБ и сжимаются по представленной выше схеме. Это даёт нам 0,7 бита на состояние. В конце концов сжатие и распаковка занимают примерно 25% от времени ЦП программы, но это отличный компромисс за снижение потребления памяти в сто раз.
Представленный выше фильтр кажется немного затратным из-за заголовка VarInt в каждой строке. Похоже, что это легко усовершенствовать ценой малых затрат ЦП или небольшого повышения сложности. Я попробовал несколько разных вариантов, транспонирующих данных в порядок по столбцам, или записывающих битовые маски более крупными блоками, и т.д. Эти варианты сами по себе давали гораздо более высокие показатели сжатия, но проявляли себя не так хорошо, когда выходные данные фильтра сжимались zstd. И это не было какой-то ошибкой zstd, результаты с gzip и bzip2 оказались похожими. У меня нет каких-то особо гениальных теорий о том, почему этот конкретный тип кодирования оказался гораздо лучше в сжатии, чем другие варианты.
Ещё одна загадка: показатель сжатия оказался намного лучше, когда данные сортируются little-endian, а не big-endian. Изначально я подумал, что так получается, потому что в сортировке little-endian появляется больше ведущих нулей при битовой маске, закодированной VarInt. Но это отличие сохраняется даже с фильтрами, у которых нет таких зависимостей.
(Есть множество исследований по сжатию отсортированных множеств целых чисел, ведь они являются базовыми строительными блоками поисковых движков. Однако я не нашёл много информации о сжатии отсортированных записей постоянной длины, и не хотел гадать, представляя данные как целочисленные значения с произвольной точностью.)
Ой-ёй, я сжульничал!
Вы могли заметить, что представленные выше реализации BFS в псевдокоде возвращают только булевы значения — решение найдено/не найдено. Это не особо полезно. В большинстве случаев нам необходимо будет создать список точных шагов решения, а не просто сообщить о наличии решения.
Поначалу кажется, что эту проблему решить легко. Вместо сбора множеств состояний нужно собирать связи состояний с родительскими состояниями. Тогда после нахождения решения можно просто вернуться назад по списку родительских решений от конца к началу. Для решения на основе хеш-таблицы это будет выглядеть примерно так:
def bfs(graph, start, end): visited = {start: None} todo = [start] while todo: node = todo.pop_first() if node == end: return trace_solution(node, visited) for kid in adjacent(node): if kid not in visited: visited[kid] = node todo.push_back(kid) return None def trace_solution(state, visited): if state is None: return [] return trace_solution(start, visited[state]) + [state]
К сожалению, это уничтожит все преимущества сжатия, полученные в предыдущем разделе; в основе их лежит предположение о том, что соседние строки очень похожи. Когда мы просто смотрим на сами состояния, это справедливо. Но нет никаких причин полагать, что это будет истинно для родительских состояний; по сути, они являются случайными данными. Во-вторых, решение с сортировкой + слиянием должно считывать и записывать все просмотренные состояния на каждой итерации. Для сохранения связки состояния/родительского состояния нам придётся считывать и записывать на диск при каждой итерации все эти плохо сжимаемые данные.
Сортировка + слияние со множественным выводом
В самом конце, при возврате назад по решению, программе нужны будут только связки состояний/родительских состояний, Следовательно, мы можем параллельно хранить две структуры данных. Visited по-прежнему будет оставаться множеством посещённых состояний, как и раньше заново вычисляемым во время слияния. Parents — это по большей мере отсортированный список пар состояния/родительского состояния, которые не переписываются. После каждой операции слияния к parents добавляется пара «состояние + родительское состояние».
def bfs(graph, start, end): parents = Stream() visited = Stream() todo = Stream() parents.add((start, None)) visited.add(start) todo.add(start) while True: new = [] for node in todo: if node == end: return trace_solution(node, parents) for kid in adjacent(node): new.push_back(kid) new_stream = Stream() for node in new.sorted().uniq(): new_stream.add(node) todo, visited = merge_sorted_streams(new_stream, visited, parents) return None # Merges sorted streams new and visited. New contains pairs of # key + value (just the keys are compared), visited contains just # keys. # # Returns a sorted stream of keys that were just present in new, # another sorted stream containing the keys that were present in either or # both of new and visited. Also adds the keys + values to the parents # stream for keys that were only present in new. def merge_sorted_streams(new, visited, parents): out_todo, out_visited = Stream(), Stream() while visited or new: if visited and new: visited_head = visited.peek() new_head = new.peek()[0] if visited_head == new_head: out_visited.add(visited.pop()) new.pop() elif visited_head < new_head: out_visited.add(visited.pop()) elif visited_head > new_head: out_todo.add(new_head) out_visited.add(new_head) out_parents.add(new.pop()) elif visited: out_visited.add(visited.pop()) elif new: out_todo.add(new.peek()[0]) out_visited.add(new.peek()[0]) out_parents.add(new.pop()) return out_todo, out_visited
Это позволяет нам пользоваться преимуществами обоих подходов с точки зрения времени выполнения и рабочих множеств, но требует больше вторичного пространства хранения. Кроме того, оказывается, что в дальнейшем по другим причинам будет полезной отдельная копия посещённых состояний, сгруппированная по глубине.
Своппинг
В псевдокоде игнорируется и другая деталь: в нём нет явного кода для дискового ввода-вывода, а присутствует только абстрактный интерфейс Stream. Stream может быть файловым потоком или массивом внутри памяти, но мы игнорировали эту подробность реализации. Вместо этого псевдокод занимается созданием паттерна доступа к памяти, позволяющего оптимально использовать диск. В идеальном мире этого было бы достаточно, и остальным могла бы заняться подсистема виртуальной памяти ОС.
Но этого не происходит, по крайней мере, в Linux. В какой-то момент (до того, как рабочее множество данных удалось сжать до размеров памяти) я добился того, чтобы программа выполнялась примерно за 11 часов, а данные сохранялись в основном на диск. Затем я сделал так, чтобы программа использовала анонимные страницы, а не хранимые в файлах, и выделил на том же диске файл подкачки достаточного размера. Однако спустя три дня программа прошла всего четверть пути, и всё равно со временем становилась медленнее. По моим оптимистичным оценкам она должна была закончить работу за 20 дней.
Уточню — это был тот же код и точно тот же паттерн доступа. Единственное, что изменилось — память сохранялась не как явный дисковый файл, а как своп. Почти не требует доказательств тот факт, что своппинг совершенно рушит производительность в Linux, в то время как обычный файловый ввод-вывод этого не делает. Я всегда предполагал, что так происходит из-за того, что программы склонны считать ОЗУ памятью с произвольным доступом. Но здесь не тот случай.
Оказывается, что страницы с сохранением файлов и анонимные страницы обрабатываются подсистемой виртуальной машины по-разному. Они хранятся в отдельных кэшах LRU с разными политиками истечения срока хранения; кроме того, похоже, что они имеют разные свойства упреждающего чтения/загрузки.
Теперь я знаю: своппинг в Linux скорее всего не будет хорошо работать даже в оптимальных условиях. Если части адресного пространства скорее всего будут выгружаться на какое-то время на диск, то лучше сохранять их вручную в файлы, чем доверять свопу. Я осуществил это, реализовав собственный класс векторов, который изначально работает только в памяти, а после превышения определённого порога размера переключается на mmap во временный отдельный файл.
Сжатие новых состояний перед слиянием
В упрощённой модели производительности мы предполагали, что на каждую глубину будет приходиться 100 миллионов новых состояний. Оказалось, что это не очень далеко от реальности (в самой сложной головоломке максимум 150 с лишним миллионов уникальных новых состояний на одном слое глубины). Но измерять нужно не это; рабочее множество до слияния связано не только с уникальными состояниями, но и со всеми состояниями, выведенными для этой итерации. Этот показатель достигает величины в 880 миллионов выходных состояний на слой глубины. Эти 880 миллионов состояний а) нужно обрабатывать при паттерне случайного доступа для сортировки, б) нельзя эффективно сжать из-за отсутствия сортировки, в) нужно хранить вместе с родительским состоянием. Это рабочее множество составляет примерно 16 ГБ.
Очевидное решение: использовать некую внешнюю сортировку. Просто записать все состояния на диск, выполнить внешнюю сортировку, провести дедупликацию, а затем как обычно выполнить слияние. Поначалу я использовал это решение, и хотя оно по большей мере устраняло проблему А, но никак не справлялось с Б и В.
В конечном итоге я воспользовался альтернативным подходом: собрал состояния в массив в памяти. Если массив становится слишком большим (например больше 100 миллионов элементов), то он сортируется, дедуплицируется и сжимается. Это даёт нам пакет отсортированных прогонов состояний, и внутри каждого прогона нет дубликатов, но они возможны между прогонами. Фундаментально код для слияния новых и посещённых состояний остаётся таким же; он по-прежнему основан на постепенном проходе по потокам. Единственное отличие заключается в том, что вместо прохода всего по двум потокам существует отдельный поток для каждого из отсортированных прогонов новых состояний.
Разумеется, показатели сжатия этих прогонов 100 миллионов состояний не так хороши, как у сжатия множества всех посещённых состояний. Но даже при таких показателях оно значительно снижает объём и рабочего множества, и требования к дисковому вводу-выводу. Нужно немного больше ресурсов ЦП для обработки очереди потоков с приоритетом, но всё равно это отличный компромисс.
Экономия пространства на родительских состояниях
На этом этапе подавляющее большинство пространства, занимаемого программой, тратится на хранение родительских состояний, чтобы мы могли после нахождения решения воссоздать его процесс. Скорее всего, их вряд ли можно хорошо сжать, но может быть, существует какой-то компромисс между ЦП и памятью?
Нам нужно связать состояние S’ на глубине D+1 с его родительским состоянием S на глубине D. Если мы сможем проитерировать все возможные родительские состояния S’, то у нас получится проверить, появляется ли какое-нибудь из них на глубине D во множестве visited. (Мы уже создали множество visited, сгруппированное по глубинам как удобный побочный продукт вывода связок состояния/родительского состояния при слиянии). К сожалению, для этой задачи такой подход не сработает; нам попросту слишком трудно сгенерировать все возможные состояния S для заданного S’. Впрочем, для многих других задач поиска такое решение может и сработать.
Если мы можем генерировать переходы между состояниями только вперёд, но не назад, то почему бы тогда не сделать только это? Давайте итеративно обойдём все состояния на глубине D и посмотрим, какие выходные состояния у них получаются. Если какое-то состояние на выходе даёт S’, то мы нашли подходящее S. Проблема этого плана в том, что он увеличивает общее потребление ресурсов процессора программой на 50%. (Не на 100%, потому что в среднем мы найдём S, просмотрев половину состояний на глубине D).
Поэтому мне не нравится не один из предельных случаев, но здесь, по крайней мере, возможен компромисс между ЦП/памятью. Существует ли более приемлемое решение где-то посередине? В конце концов я решил хранить не пару (S’, S), а пару (S’, H(S)), где H — 8-битная хеш-функция. Чтобы найти S для заданного S’, мы снова итеративно обходим все состояния на глубине D. Но прежде чем делать что-то другое, вычислим тот же хеш. Если выходной результат не соответствует H(S), то это не то состояние, которое мы ищем, и мы можем просто его пропустить. Эта оптимизация означает, что затратные повторные вычисления нужно выполнять только для 1/256 состояний, что составляет незначительное повышение нагрузки на ЦП, и в то же время снижает объём памяти для хранения родительских состояний с 8-10 байт до 1 байта.
Что не сработало или может не сработать
В предыдущих разделах мы рассмотрели последовательность высокоуровневых оптимизаций, которые сработали. Я пробовал и другие вещи, которые не сработали, или которые я нашёл в литературе, но решил, что в этом конкретном случае они не подойдут. Вот их неполный список.
На этом этапе я не вычисляю повторно всё множество visited при каждой итерации. Вместо этого оно хранилось как множество отсортированных прогонов, и эти прогоны время от времени ужимались. Преимущество такого подхода заключается в меньшем количестве записей на диск и ресурсов ЦП, затрачиваемых на сжатие. Недостаток — повышенная сложность кода и пониженный показатель сжатия. Изначально я думал, что подобная схема имеет смысл, ведь в моём случае операции записи более затратны, чем считывание. Но в конечном итоге показатель сжатия оказался больше в два раза. Преимущества такого компромисса неочевидны, поэтому в результате я вернулся к более простому виду.
Уже проводились небольшие исследования о выполнении объёмного поиска в ширину для неявно заданных графов во вторичном хранилище, начать изучение этой темы можно с этой статьи 2008 года. Как можно догадаться, идея выполнения дедупликации совместно с сортировкой + слиянием во вторичном хранилище не нова. Удивительно в этом то, что открыта она была только в 1993 году. Довольно поздно! Существуют более поздние предложения по поиску в ширину во вторичном хранилище, которые не требуют этапа сортировки.
Одно из них заключалось в том, чтобы привязать состояния к целым числам, и хранить в памяти битовую карту посещённых состояний. В моём случае это совершенно бесполезно, потому что размеры кодируемых по сравнению с действительно достижимыми пространствами состояний очень отличаются. И я очень сомневаюсь, что существуют интересные задачи, в которых подобный подход сработал бы.
Ещё одна серьёзная альтернатива основывается на временных хеш-таблицах. Посещённые состояния хранятся без сортировки в файле. Сохраняем выходные данные, полученные из глубины D в хеш-таблицу. Затем итеративно обходим посещённые состояния и ищем их в хеш-таблице. Если элемент найден в хеш-таблице, то удаляем его. После итеративного обхода всего файла в нём останутся только недублируемые элементы. Затем их добавляют к файлу и используют для инициализации списка todo для следующей итерации. Если количество выходных данных так велико, что хеш-таблица не помещается в памяти, то и файлы, и хеш-таблицы можно разбить на части, пользуясь одинаковым критерием (например, верхними битами состояния), и обрабатывать каждую часть по отдельности.
Хоть и существуют бенчмарки, показывающие, что подход на основе хешей примерно на 30% быстрее, чем сортировка + слияние, но, похоже, что в них не учитывается сжатие. Я просто не увидел, как отказ от преимуществ сжатия может оправдать себя, поэтому не стал даже экспериментировать с такими подходами.
Ещё одной стоящей внимания областью исследований показалась оптимизация запросов к базе данных. Похоже. что задача дедупликации сильно связана с join баз данных, в котором тоже есть совершенно такая же дилемма «сортировка против хеширования». Очевидно, что некоторые из этих исследований можно перенести и на задачу поиска. Разница может заключаться в том, что выходные данные join баз данных являются временными, в то время как выходные данные дедупликации BFS сохраняются до конца вычислений. Похоже, это меняет баланс компромиссов: теперь он касается не только наиболее эффективной обработки одной итерации, но и создания наиболее оптимального формата выходных данных для следующей итерации.
Заключение
На этом я завершаю изложение того, что я узнал из проекта, который в общем случае применим и к другим задачам поиска грубым перебором. Сочетание этих трюков позволило снизить объём решений самых сложных головоломок игры с 50-100 ГБ до 500 МБ и плавно увеличивать затраты, если задача превышает доступную память и записывается на диск. Кроме того, моё решение на 50% быстрее, чем наивная дедупликация состояний на основе хеш-таблиц даже для головоломок, помещающихся в памяти.
Игру Snakebird можно приобрести в Steam, Google Play и в App Store. Рекомендую её всем, кому интересны очень сложные, но честные головоломки.