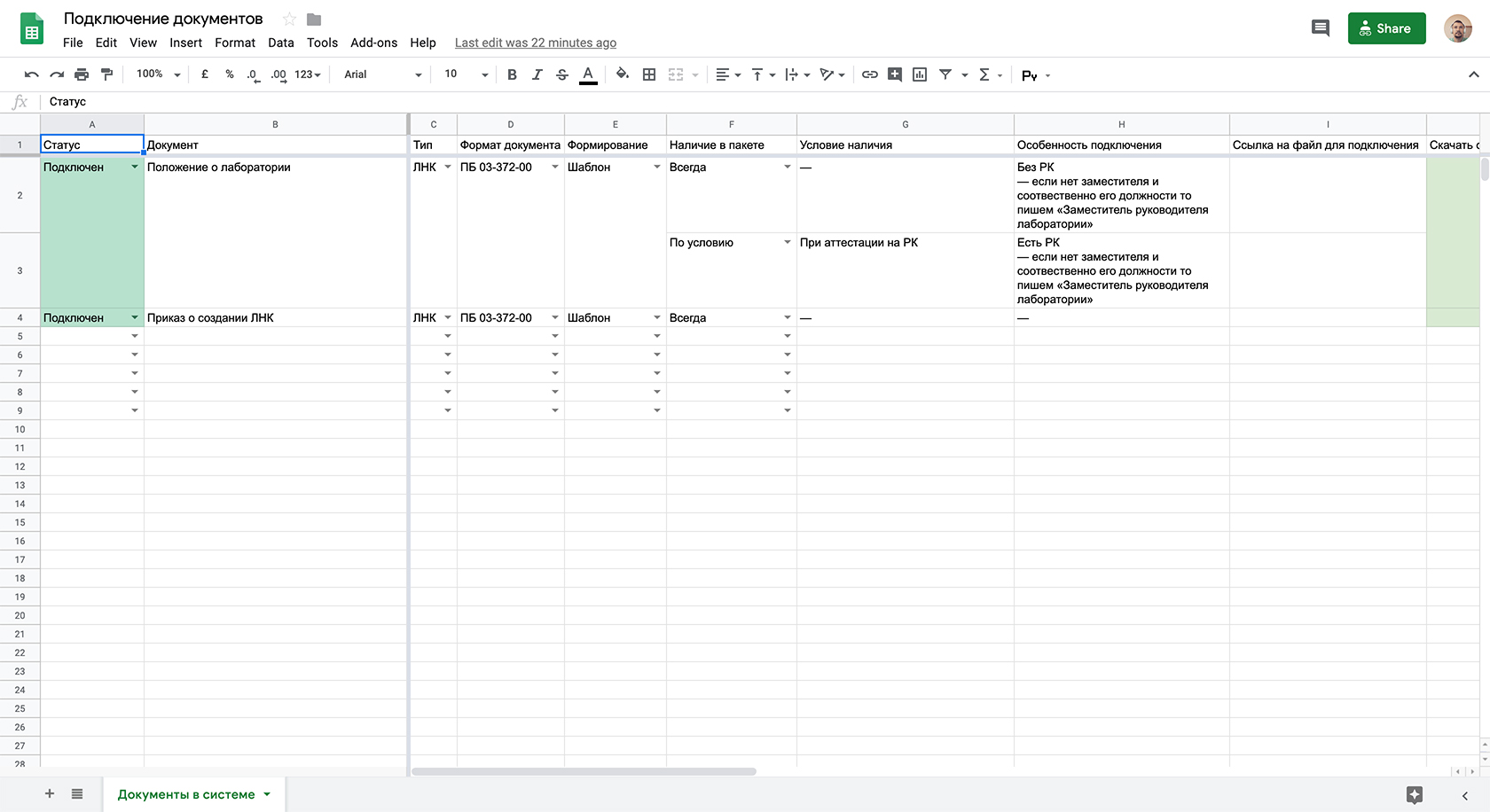
Мой друг жил в маленькой деревушке (1к человек),

хорошо учился в школе, был отличником и безусловно получил бы золотую медаль (хотя кому они сейчас нужны), если бы не тотальная родовая ненависть руководства школы к его семье и как следствие к нему (отличный пример для пояснения принципа ООП — «наследование»).
В 14 лет у него появился компьютер, и первые игры, но к слову сказать это не значило ровным счетом ничего, не проснулось тяги к компьютерным наукам, программированию и развитию в этом направлении.
В 16 его «поступили» в институт. Именно «поступили», потому что ему самому было абсолютно плевать, что будет дальше, на дворе было лето, а ему 16 и у него первая любовь.
По счастью, мать моего друга угадала и устроила его в технический институт, это был Екатеринбуржский институт связи, где он благополучно учился последующие 5 лет.
Отличительной чертой того времени можно отметить практически 90 процентов бесполезности получаемого материала, который не пригодился на практике, от слова «совсем», но тут пытливый читатель скажет что мол «получил общее развитие, учился, а не деградировал» и я соглашусь.
Из чего-то связанного с программированием на тот момент мой друг мог бы отметить первый курс и один семестр лекций по программированию на делфи, в конце курсовая (которая была куплена на 200р, на дворе был 2010 год), на этом все.
После института и армии мой друг пошел работать по специальности, ощущая себя крайне полезным, по почему-то совсем никому не нужным кадром. Очень долго искал работу (возможно сказались отголоски экономического кризиса 2008г) и в итоге устроился в фирму сотового оператора, местного значения, получив должность «Инженер» и жалование в 12 000р (2011г).
Тут, наверное, второй раз покачнулись его представления о жизни и правильности всего того что в ней происходит (первый раз при разводе родителей).
Работа инженером, о которой 5 лет рассказывали в институте разительно отличалась от работы в пользу местного сотового оператора: друг занимался эксплуатацией базовых станций, которые, как все наверняка знают, стоят по городам и селам и трассам преимущественно в металлических контейнерах, 2*3 метра, снаружи вышка с антеннами, внутри драгоценное (в прямом смысле

Была в этом всем романтика, которая поначалу очень грела душу и закрывала глаза на неудобства: разъездная работа, часто в пути (можно поспать), часто можно сделать работу быстрей чем положено (и поспать), все самые вкусные и дешевые столовки в Екб и области он знал как свои 5 пальцев.

Летние бонусы особо приятные: поехал на объект — заехал искупаться, а можешь взять в магазине мясо (а можешь и пиво)и поехать на работу со своим обедом, благо мангал всегда был в машине водителя.
Говоря о тех днях, мой друг отмечает, что на тот момент было четкое ощущение того, что он на своем месте и все у него хорошо, денег хватает, работа «не сидячая, не заскучаешь», ну и в коллективе его уважали. А вы представляете какой там коллектив? Люди простые… и уважение в таком коллективе очень важно.
Он женился и постепенно жизнь скатилась в один глобальный «день сурка», который он называл позже «зона комфорта». Работа — дом — жена — пиво — сериальчики — World Of Warcraft (чтобы жена не мешала играть, он ее тоже подсадил на варик) — выходные — долгие красивые разговоры с тестем о светлом будущем (непонятно на каком основании), под коньячок.
Спустя пару лет его подозвал начальник и сказал: «готовь свои амбиции и пожелания о ЗП к должности старшего инженера», это был второй «подвиг» на работе (первый — это закончившийся за 1 месяц исп. срок), он им очень гордился тогда, там было много коллег, которые работали значительно дольше, но должность старшего инженера они не получили.
Факт карьерного роста и рост (незначительный) ЗП только укрепили ощущение что «все идет по плану».
2015 ознаменовался разводом с женой, дикой депрессией, пьянством, впервые за свои 27 лет мой друг закурил, говорит что скорее всего, поводом к этому если покопаться в душе, стала жалость к себе и ничего более, способ привлечь внимание к тому как его ломало, а ломало его сильно.
В разгар этого периода, одногруппник моего друга, который на тот момент трудился разработчиком, начал рассказывать как это круто. В доказательство он приводил цифры (а начинал он таким же инженером в той же компании), рассказывал про java и показал какую-то простенькую программу.
Памятую о тех временах, мой друг рассказывает что начал читать первую java-книгу Я.Файн «Программирование для дедушек и бабушек» без особой веры в себя, если бы ему тогда сказали, что он станет разработчиком, он бы никогда не поверил. Было четко сформулированная уверенность!, что даже мысль, о том что можно стать программистом — абсурдна и примерно на том же уровне что мысль слетать в космос.
Дальше были первые стандартные вещи: калькулятор, крестики-нолики. И знаете что? Ни-че-го, не зацепило совсем. Это была забава (причем не самая веселая), не более.
Благо иллюзии по поводу своей нынешней на тот момент работы, уже прошли, как и тяга к юношеской романтике и приключениям, последней каплей была травма и больничный и мысли о том, что очень легко можно остаться без денег, работая руками, достаточно повредить эти самые руки и ты бесполезен.
Скорее от отчаянии, а не от глубоко осознания, и уж тем более не от тяги к программированию была куплена книга Head First Java издательства O`Relly, именно куплена, а не скачена с интернета, за 1800р, и так для него книга за такие деньги была очень дорогой покупкой было решено дочитать ее до конца, при любых обстоятельствах, чтоб хоть как то оправдать ее стоимость.
На тот момент в его голове уже был план, как жить дальше, почему то сама мысль о том, что можно зарабатывать не только руками, но и головой очень грела, стимулировала.
И тут повезло: удалось перевестись внутри компании на должность сопровожденца БД Oracle, по счастью произошло совпадение интересов, работодателю срочно нужны были люди, а моему другу хоть какая-то запись в трудовой и опыт, которые бы немного отличались от «запитывания БС дизельным генератором», для последующего устройства java-разработчиком.
Это бы определяющий шаг, и отчасти рискованный, так как познаний в SQL не было от слова «совсем», но было желание учиться, работать и зарабатывать(а еще была ипотека, которая не оставляет вариантов).
Период испытательного срока был особо напряженный, цитируя моего друга: «у меня каждый день закреплялось мнение что я идиот, и никогда не смогу разобраться в этом, не понимаю как я делал какие-то задачи. Приходя домой я сразу же ложился спать, было психологическое истощение».
Работа с SQL стала серьёзным подспорьем в развитии и становлении моего друга, во-первых, он начал зарабатывать деньги без помощи отвертки и плоскогубцев, во-вторых, довольно быстро прокачал свой SQL-скилл, так как охотно брался за сложные, (начальство их называло
Серьезным подспорьем стала удаленка и первый написанный самостоятельно веб-сервис (мой друг шутит, что ни за что на свете не хотел бы увидеть исходники этого сервиса). На руку сыграло то, что у работодателя был просто омут задач, которые можно было автоматизировать, а у моего друга — страстная тяга к автоматизации ручного труда.
В ход пошел spring, и работа над довольно функциональным web-сервисом, начиная писать который, мой друг совсем не понимал что такой spring, а заканчивая, спустя 2 месяца уже кое-что знал.
На тот момент он бросил пить и курить, ушел с головой в работу, все свободное время (не считая фитнес-клуба) тратил на книги и кодинг, подстегивал результат: сервисы, которые экономили часы ручной работы и благодарности коллег их других ведомств.
Он говорит что в какой то момент, мысль о том что он станет разработчиком стала нормой, перестала казаться нереальной, сформировалась четкая установка: «я этого не знаю, но это ПОКА».
Спустя еще год он устроился java-разработчиком, на приличную ЗП в приличный банк, вопреки скепсису коллег с первой работы («ботаник, куда-ты прешься, пошли накатим»), все получилось.
Думаю для тех кто еще сомневается, получится ли у него, важно знать, что «невозможно»- это всего лишь слово, а эта история всего лишь еще один маленький пример сказанного.
У вас есть такой друг? А может это Вы?
У меня он есть, а может это я…
ссылка на оригинал статьи https://habr.com/ru/post/465661/