И вот мы в третий раз завершили конкурс IT-статей «ТехноТекст». 2020 год получился безумным необычным: довольно трудным, изоляционным, дистанционным, но притом вполне айтишным. В этом смысле конкурс статей о технологиях, придуманный контент-студией Хабра, не только уникален, но и показателен. Подробности о его итогах под катом.
Мы не устаем повторять, что техноавторство для нас — особый вид искусства, а для действительно хорошего технического текста нужно совмещать в себе технаря, лирика, гуманитария и физика. Словом, быть человеком Возрождения. Судя по всему, эта концепция становится всё более популярной в IT-среде. Для сравнения:
-
в прошлом году было 213 заявок, в этом — 633;
-
в прошлом 12 номинаций и 13 лауреатов, в этом — 23 и 25 соответственно (по традиции в некоторых номинациях — в этом году «Просто о сложном» и «Сделай сам» — сообщество могло выбрать своих победителей);
-
в прошлом церемония награждения проходила в традиционном формате, в этом, как и многое в 2020-м, — на удалёнке.
23 декабря мы наградили победителей. Как и всегда, ограничения на приём заявок были минимальны: мы не принимали переводы, статьи в соавторстве и тексты, опубликованные до 18.11.2019 и после 09.11.2020. Критерии отбора ー любая связь с информационными технологиями, 1 автор ー 1 текст, заявка подается самим автором, подходят все жанры.
Вот уже который год я читаю в комментариях рассказы о том, что Хабр — не торт и о том, что корпоративные блоги — зло. Так вот, я хочу опровергнуть оба этих тезиса. Уровень статей, которые я оценивал для конкурса, — очень высокий, и это касается в том числе текстов из корпоративных блогов. Конечно, стоит сделать скидку на то, что моя специализация — не совсем айтишные темы, но, например, в номинации «Просто о сложном» были именно что классные корпоративные айтишные тексты. Что-то я уже читал в течение года, что-то увидел впервые и был очень рад возможности наверстать упущенное и ещё раз убедиться, что Хабр — это то место, где можно найти и интересное, и полезное чтение. Отдельно меня порадовало то, что в этом году исправился сильный перекос научно-популярных статей в космическую тематику. Нет, статей про космонавтику не стало меньше, но стало и больше отличных текстов на другие темы, причем более близкие к научным основам IT — от квантовых вычислений до совсем фундаментальной математики. Отрадно и то, что авторы стали меньше стесняться с научной стороной, делая именно «научно-популярные», а не «популяризаторские» тексты.
Хочу сказать огромное спасибо всем авторам и отдельно попросить тех, кто всё ещё думает, стоит ли оно того: пишите, пожалуйста, пишите о том, что вам интересно и о чем вы можете рассказать окружающим. Ваша собственная заинтересованность в теме — это главное, что нужно для того, чтобы статья получилась хорошей.
Валерий Шунков (@amartology), коллективное сознательное Хабра
Кухня конкурса
По традиции наше жюри было представлено наиболее компетентными и дотошными экспертами:

О каждом подробнее:
-
Денис Крючков — человек за
занавескойвсем Хабром, положивший начало главному IT-ресурсу для техноавторов. -
Екатерина Горелова — руководитель контент-студии Хабра, мегаэксперт в области контент-маркетинга, натива, креатива, оформления и подачи и ещё много чего.
-
Ирина Лосева — шеф-редактор контент-студии, знает все тексты конкурса вдоль и поперёк. Чёрный пояс по техническим текстам.
-
Андрей Фильченков — доцент университета ИТМО и ФИТиП, спец по ИИ, машинному обучению и настоящий экспертный эксперт по научным и техническим публикациям и работам.
-
Коллективное сознательное Хабра — отдельно хотим отметить последнего судью. Он был особенно суров.
Как и в прошлом году, критериев оценки было 5:
-
актуальность темы (+теме);
-
техническая грамотность;
-
лаконичность;
-
подача (стиль, уровень вовлечения читателя, оформление);
-
вау-эффект (общее впечатление от работы).
Ну вы и задали нам задачку…С каждым годом уровень статей, которые мы получаем в заявках, растёт. Да, нам гораздо сложнее их оценивать — но мне нравится та высокая планка, которую вы задаете и нам, и сообществу в целом.Мы ждали около 500 заявок, вы прислали 633 — и это на самом деле много. Чтобы избежать субъективности, нам пришлось немного усложнить систему отбора во 2-й тур и финал — так чтобы дать каждому тексту несколько шансов. Во многих номинациях разрывы были минимальны (
да-да, будем честными, где-то я тоже расстроилась, но против цифр не пойдешь). Пишите, творите, делитесь экспертизой с сообществом и публикуйте новые крутые статьи — все, что вышло после 9 ноября, мы примем на «ТехноТекст-2021».Ирина Лосева, шеф-редактор контент студии Хабра
А вот и статистика
Пик заявок в этом году пришёлся на август — когда на конкурс за месяц заявили 312 статей. В уже почти завершенном 2020-м мы решили предоставить авторам полную свободу в выборе номинаций, надеясь, что те самостоятельно решат, куда статья подходит лучше. Как следствие многие (для верности) решили «запульнуть» везде, поэтому в будущем, скорее всего, выбор будет слегка ограничен.
В третий раз закинул старик невод, и пришёл невод полон рыбы. Рекордное количество участников — это несомненный признак успеха прекрасного начинания. Я очень благодарен организаторам за все их усилия в развитии нашего техносообщества, но мне кажется, что не все осознают, насколько это трудозатратно. Я думаю, что сейчас самый момент, чтобы само сообщество поучаствовало в дальнейшем развитии «ТехноТекста», нужны новые идеи, нужны добровольцы, которые возьмут на себя часть организационных обязанностей. Если у вас есть идеи, большие или маленькие, не стесняйтесь писать напрямую организаторам!
Ну и, разумеется, без хороших текстов это всё не имеет смысла. Даже не говоря о самом конкурсе: делитесь сокровенным — и вас оценят! Если у вас есть любимый проект, будь то выращивание пингвинов или постройка глобальных фреймворков, не дайте вашей страсти угаснуть. Для читателя самая интересная статья именно о том, что трогает за душу автора — унылые дайджесты никому не нужны. А что это даёт автору? Ведь облечь туманность мыслей в голове в стройные слова — это нелёгкий труд. Но именно это позволяет структурировать мысли, пишите статьи как если бы вы их писали именно для себя, и эти усилия воздадутся сторицей. Положительный отклик сообщества послужит отличным стимулом к новому витку полёта мысли.
Дмитрий Соколов (@haqreu), коллективное сознательное Хабра
Поднимая непростую тему гендера, можем сказать, что в этом году большинство претендентов оказалось мужчинами: 571 человек или 90,2 %. Считаем, что эта несправедливость выправится вместе с растущим ежегодно числом желающих посостязаться в мастерстве технического писательства. Основной костяк текстов пришёлся на внутренний ресурс Хабра: 570 заявок пришли с портала (из которых 183 — из блогов компаний), тогда как извне прилетело лишь 63.
В этом году я попал в жюри конкурса и участвовал в оценке статей в номинациях «Программирование» и DevOps. Приятно удивил спектр статей: начиная от задачи ускорения вычисления поколений в Game of Life, заканчивая добавлением кастомного кода в MBR. Во всех статьях чувствовалась увлечённость авторов. Это один из ключевых моментов, когда ты проникаешься идеей авторов, читать статью становиться интересно не только из технических соображений — добавляется эмоциональный окрас. Стоит отметить огромный конкурс в категории «Программирование». Два десятка статей добралось до финала, и все они написаны на очень высоком уровне как по техническому содержанию, так и с точки зрения вовлечения читателя. Мне бы хотелось дать один совет тем, кто хотел, но не решился поучаствовать в конкурсе. Очень часто нам кажется, что наша деятельность, наши исследования, увлечения, просто сложные баги в коде — это то, что никого не может заинтересовать, но это не так. За каждым багом в коде скрывается история. Попробуйте её рассказать и, возможно, в следующем году на конкурсе будут награждать именно вас.
Михаил Кумачёв (@Ceridan), коллективное сознательное Хабра
Говоря об ожидании/реальности и вспоминая ремарку об отсутствии ограничений на номинации для участника, стоит упомянуть, что самой амбициозной в этом году стала «Программирование», следом «Просто о сложном», далее «Лучшая подача», «Лучший кейс» и вниз по списку. В итоге получилась следующая интересная статистика по самым победоносным номинациям (важный момент: номинации могли корректироваться на усмотрение жюри):
-
Программирование (10%)
-
Сделай сам (7,2%)
-
Научно-популярное/Просто о сложном (по 6,8%)
Подробнее по всем тут:
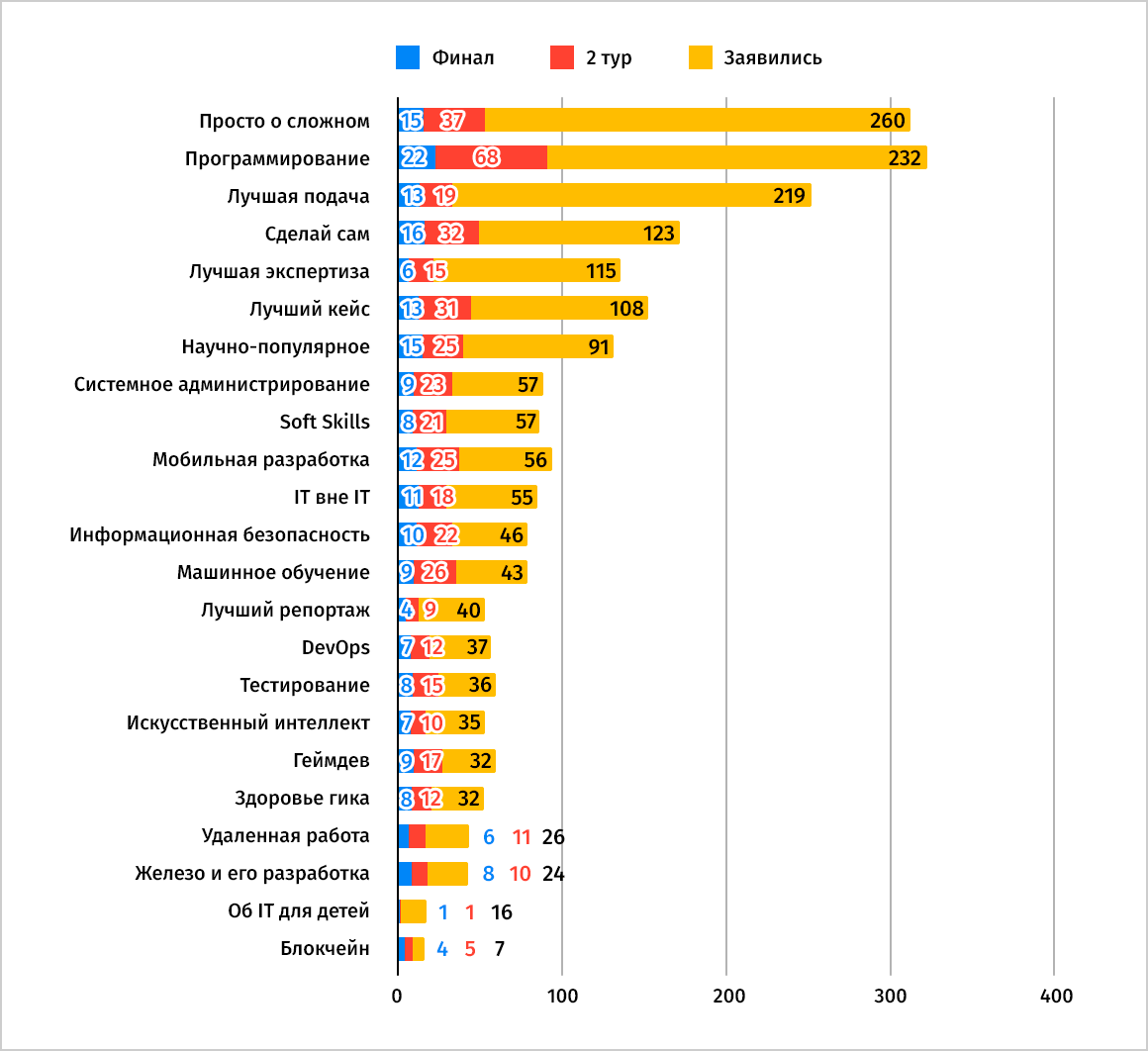
Таким образом, больше всего финалистов ожидаемо в самых популярных рубриках, но, вспоминая «Горца», в конце должен остаться только один.
Встречайте героев
Итак, не растекаясь мыслью по древу, сразу перечислим победителей по номинациям. Пожалуй, воспользуемся этой возможностью, чтобы ещё раз всех их поздравить.
ПРОГРАММИРОВАНИЕ — поздравляем Дениса Тишкова (@DenisT) его статья: «Вычисления на GPU – зачем, когда и как. Плюс немного тестов».
СИСТЕМНОЕ АДМИНИСТРИРОВАНИЕ — ура Евгению Парфёнову (@Sayanaro) с его работой «С Hyper-V на VMware и обратно: конвертация виртуальных дисков».
ТЕСТИРОВАНИЕ — с победой Павла Довгалюка (@Dovgaluk) его статья: «Обратная отладка виртуальных машин в QEMU».
МОБИЛЬНАЯ РАЗРАБОТКА — жмём руку (разумеется, дистанционно) Даниилу Субботину ( @subdan) — победила его статья «FigmaExport: как автоматизировать экспорт UI-Kit из Figma в Xcode и Android Studio проекты».
ЖЕЛЕЗО И ЕГО РАЗРАБОТКА — что называется, не софтом единым. Владимир Омелянчук (@power-link) — живое тому подтверждение с материалом «LED-драйвер со стоимостью BOM-а меньше 1$. Это возможно?».
ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ – поздравляем Дмитрия Ватолина (@3Dvideo) его статья: «Deep Fake Science, кризис воспроизводимости и откуда берутся пустые репозитории».
МАШИННОЕ ОБУЧЕНИЕ (эксперт-партнер в номинации — Glowbyte) – поздравляем с заслуженной победой Александра Кукушкина (@alexanderkuk) с его статьей — «Проект Natasha. Набор качественных открытых инструментов для обработки естественного русского языка (NLP)».
У статьи, претендующей на «лучшую» в «Машинном обучении», должна быть структура из которой будет понятен контекст статьи в мире ML. Статья должна быть концентратом с высокой плотностью и динамикой мысли. Не хочется видеть идеальный разбор с «консервативными» примерами из старых учебников. При этом хочется увидеть где-то глубину и если не ML-методов, то domain-области, где применение МL материально. В идеале хочется видеть разбор SOTA-методов, обсуждение лучших практик в индустрии, о которых, возможно, широко не рассказывают на arhiv.org или конференциях с книгами. На Хабре в этом смысле можно раскрыть интуицию и направление мысли, если коммерческая тайна не позволяет говорить слишком подробно про подход. В будущем хотелось бы увидеть статьи, больше отражающие тренды и их проекцию на действительность — interpretable AI, causal inference, операционализация моделей, байесовские методы, Federated ML. Обзоры методов, разработанных от FB,Google (не только NLP).
Александр Бородин, ведущий эксперт по моделированию финансовых рисков GlowByte Consulting
ИНФОРМАЦИОННАЯ БЕЗОПАСНОСТЬ — с победой Антона Лопаницына (@Bo0oM) с его выигрышной статьёй: «Фишеры icloud и где они обитают».
БЛОКЧЕЙН – поздравляем Андрея Сабельникова (@andrey_sabelnikov) с публикацией «Сколько нужно рома, чтобы получить новую кольцевую подпись?».
ПРОСТО О СЛОЖНОМ (наш экспертный партнер в этой номинации — dentsu Russia) – поздравляем Антона Жиянова (@nalgeon), его работа: «Юлия → Iuliia. Всё о транслитерации».
«Dentsu развивает технологии, которые помогают драйвить бизнес крупнейших потребительских брендов-рекламодателей и всю медиаиндустрию. Мы с удовольствием делимся деталями своих разработок и экспериментов, потому что верим, что только так можно сделать их еще лучше.
Здорово, что Хабр выступает проводником таких знаний и обратной связи, а компании любой категории делятся своим опытом, не делая его сакральным. Чем более открытыми являются изменения, которые происходят внутри самых разных бизнесов, тем ярче конкуренция и желание меняться.
В номинации “Просто о сложном» было много любопытных материалов – от чисто прикладных до бизнес ориентированных. Но всех объединяла тяга авторов к исследованию и желание поделиться результатами этого исследования. Статья-победитель о транслитерации написана не просто объективно и простым чистым языком, но и обладает прикладным смыслом, иначе бы это был научпоп (другая рубрика конкурса).
Рассказать просто может только настоящий эксперт-практик. Тема, в которой автор действительно разобрался, имеет наибольшую ценность. Но также важно потратить хотя бы какое-то время на то, чтобы понять, чем живёт аудитория, в которую вы целитесь, и зачем ей читать этот текст».
Юрий Лысенко, директор по стратегическим технологиям dentsu Russia
DEVOPS — с победой Ивана Осадчего (@iosadchiy) за статью «Оптимизация работы с PostgreSQL в Go: от 50 до 5000 RPS».
ГЕЙМДЕВ — с победой Алексея Лесового (@lesha_lesovoy) его статья: «Armored Warfare: Проект Армата. Хроматическая аберрация».
НАУЧНО-ПОПУЛЯРНОЕ — с победой Александра Дикарева (@AlekDikarev) — выигрышная статья «Как глубока Бездна Челленджера: измерение глубины».
СДЕЛАЙ САМ – поздравляем Дмитрия Дударева (@Dudarion) — его статья: «Как я делаю цифровую минигитару».
ОБ IT ДЛЯ ДЕТЕЙ — триумфатором этой номинации стал Александр Ночкин ( @nochkin) — статья «Начать заниматься роботами должно быть просто» понравилась всем, кто ее читал.
ПРОСТО О СЛОЖНОМ (ВЫБОР СООБЩЕСТВА) – сообщество избрало победителем Андрея Мелихова (@amel-true) с его статьей «Архитектура современных корпоративных Node.js-приложений».
СДЕЛАЙ САМ (ВЫБОР СООБЩЕСТВА) – победителем народного голосования оказался Гуменюк Иван (@Meklon) и его работа «Гидропоника. Выращиваем сверхострый чили и заставляем всех его есть».
SOFT SKILLS – с победой Руслана Закарьяева ( @RuslanZakariaev) за его «Советы руководителю от руководителя».
ЛУЧШИЙ РЕПОРТАЖ – поздравляем Веронику Самохину (@Aminopyrodin) ее репортаж: «ICFP Contest 2020 от идеи до воплощения. Как организовать контест и выжить».
ЛУЧШИЙ КЕЙС – выиграл Никита Славин (@Nslavin) его материал: «How old is this house. Как я делал карту возраста домов Петербурга»
ЛУЧШАЯ ПОДАЧА – победа Алексея Карамышева (@Ommand), его работа: «Равномерное перемещение объекта вдоль кривой».
ЛУЧШАЯ ЭКСПЕРТИЗА (партнёр-эксперт в этой номинации — «МегаФон») – тут победителем стал Роман Проскуряков ( @humbug) и его статья «C++ быстрее и безопаснее Rust, Yandex сделала замеры».
Какой должна быть статья, чтобы быть лучшей? Нет однозначного ответа на этот вопрос. Для себя я, наверное, сформулировал бы следующие критерии применительно к статье: она безусловно должна быть интересной, она должна вызывать реакцию со стороны сообщества, она должны вызывать эмоции, причём необязательно «ох, ну ничего себе» или «класс, надо попробовать», но вполне допускается и негативная коннотация, типа «да что вы там втираете». Эмоция, на мой взгляд, самое главное, что должно быть в подобном сообществе. Эмоции двигают вперёд, заставляют работать с собственным знанием и вступать в дискуссии. Также статья должна быть небанальной, содержать новое знание, личный опыт, и, немаловажно, подача материала должна нести в себе желание рассказать сообществу что-то новое, что улучшает общую базу знаний, общий опыт. Наверное, это ключевые критерии.
Леонид Чёрный, директор по управлению данными в компании «МегаФон»
УДАЛЁННАЯ РАБОТА – с победой Ларису Большакову ( @Lara_ball007) с её статьей: «Какие ошибки делают руководители на удалёнке».
IT ВНЕ IT – поздравляем Ярослава Сергиенко ( @pallada92) его статья: «Трехмерный движок в коде… ДНК».
ЗДОРОВЬЕ ГИКА – с победой Дмитрия Руднева ( @dmitriyrudnev) за его работу «Тёплый, ламповый и очень опасный».
Больше всего мне нравятся статьи из хаба DIY, потому что это настоящее творчество. В каждом проекте чувствуется душа. И некоторые проекты, помимо технической сложности, поражают масштабом!
Видно, что финалисты конкурса потратили не один месяц на свои разработки и вложили в проекты много сил. Это очень увлечённые люди, которые с удовольствием описывают свою работу, а такие статьи читать одно удовольствие.
Кажется, что за последнее время DIY-статьи выходят длиннее — возможно, это связано с тем, что инженеры стали больше времени уделять своим хобби, и это здорово!
Виталий Юркин (@aivs), коллективное сознательное Хабра
Аналогично прошлому году, в ближайшее время у всех победителей в профиле появятся значки «Лучший техноавтор-2020».
Как награждали и что хотим сказать
В силу очевидных причин (откройте браузер / включите ТВ / посмотрите в окно) в 2020 году награждение просто не могло проходить по традиционной, так полюбившейся всем нам модели. Мы бы очень хотели лично пообщаться с номинантами, пожать руки победителям и вручить им награды, но пришлось оставаться в тренде и ограничиться онлайн-церемонией. Но мы и не думаем отчаиваться!
Было приятно увидеть такое большое количество участников, причём большинство статей действительно сильные. Сложно сказать, чего не хватает и чего хотелось бы почитать. Но Хабр как раз нравится тем, что на нём ежедневно можно встретить что-то такое, чего не ждёшь или о чём даже не думал, — эта жажда у многих неутолима. Как и многим читателям Хабра, мне бы хотелось видеть больше прикладных и общеобразовательных материалов — в принципе, и то и другое было среди работ участников, но, думаю, в целом у таких статей всегда больше шансов на победу.
Алексей @Boomburum Шевелев, главный над самым главным в пользовательской поддержке Хабра
Даже в новой реальности «ТехноТекст» показал себя намного бодрее, чем в предыдущем году. Больше участников, больше активности, больше мяса. В жюри конкурса — прошлогодние победители, и таким образом, мы, можно сказать, создаем и укрепляем традицию.
Два важных наблюдения внутри Хабра-2020 и конкурса «ТехноТекст-2020». Во-первых, я помнила статьи почти всех финалистов и это показательно: значит, аудитория и эксперты сходятся в оценках, это много говорит об уровне победителей — они нереально крутые. Во-вторых, этот год показал, насколько чувствительно Хабр реагирует на окружающие события, новые тренды, какие-то локальные айтишные факты. Это говорит о живости и включённости аудитории, о возможности эффективного диалога внутри ИТ-сообщества. Но всегда чего-то не хватает. Как ни парадоксально, лично мне как айтишнику не хватает хороших практических статей по ИТ-менеджменту, который реально приносит результат в компаниях. Увы, в этой среде пока либо теория, либо скудные редкие кейсы. Думаю, 2021 год принесёт свои тренды и будет много интересного контента. Пишите лаконично (не коротко, а осмысленно!), доказательно, иллюстрируйте публикации хорошими примерами, схемами, программным кодом — создавайте профессиональный контент, это бесценный вклад в жизнь всего ИТ-сообщества. И конечно, это ваш опыт, личная прокачка скилов. И да, участвуйте в «ТехноТексте», это интересно, полезно и важно для оценки себя как автора. Надеюсь, встретимся на награждении уже офлайн!
Виктория Гонгина (@Exosphere), один из главных модераторов Хабра
Ещё раз спасибо «коллективному сознательному» — экспертам и крутым техноавторам, которые помогали оценивать статьи: @ErmIg@haqreu @aivs @Loxmatiymamont @dmitrysamsonov @Ceridan @trashwind @amartology @Mofas @PatientZero @LukaSafonov
И отдельная благодарность нашим замечательным партнёрам — компаниям dentsu Russia, Glowbyte и «МегаФон».
А вообще, что хотим сказать. Мы верим, что следующий «ТехноТекст» получится ещё круче, что участников будет больше, а церемония пройдёт в офлайне. Хотя — как знать? В IT-сообществе быть затворником не зазорно.
У каждого свой Хабр. И мой Хабр — это конечно образовательное сообщество. Если смотреть на «отдачу» — от личного общения до маркетинговых исследований — эта образовательная константа-доминанта важна для многих. При чём здесь текст и «ТехноТекст»? Образование на Хабре — своего рода «текстовая ювелирка”. Каждый урок — единственный и неповторимый текст, когда важно не только что и зачем, но и как. Поэтому выбирая лучшие публикации, мы оценивали не только информативную ценность и профессиональный опыт, но и эрудицию и свободу автора, талант быть собой и не бояться выразить себя в словах. По большому счёту, именно знания и свобода — то лучшее в нас, что сделает и этот мир лучше. Пишите, скоро мы начнем новый «ТехноТекст».
Екатерина Горелова, руководитель контент-студии Хабра
Увидимся в следующем году! А если вы участвовали и не победили — отчаиваться не стоит. Пытайтесь снова, и все обязательно получится.
ссылка на оригинал статьи https://habr.com/ru/company/habr/blog/535722/