Данная статья написана с целью продемонстрировать как с помощью технологии CUDA можно смоделировать простое взаимодействие заряженых частиц (см.
Закон Кулона). Для вывода статической картинки я использовал библиотеку
freeglut.
Как пишут частенько на Хабре:
Ещё во времена Turbo Pascal и Borland C 5.02 меня интересовал процесс симуляции простых физических явлений природы — будь то силы гравитационного притяжения или кулоновского взаимодействия. К сожалению, мощности одного процессора с несколькими сотнями МГц не хватало для простых математических операций, коих множество было велико.
Хоть я и не погроммист, мне захотелось однажды вспомнить далёкое детство, да и подучить основы JavaScript, и я как-то смоделировал гравитационное взаимодействие любого разумного числа материальных точек. Так, например, частичка ниже крутится вокруг «солнца» пользуясь Ньютоновским законом:
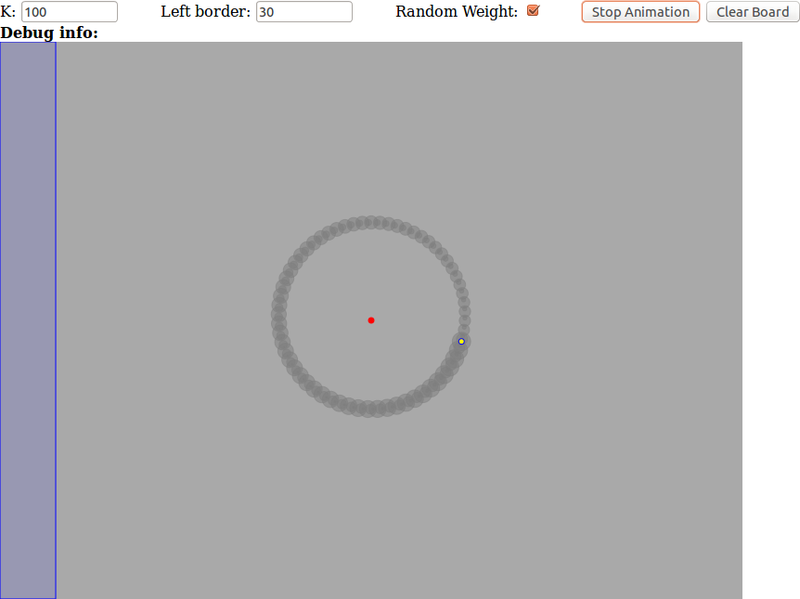
Если вам будет интересно, и меня не оставит энтузиазм, то я опишу вам создание такой вот демки, чтобы вы смогли написать своих злых птиц в вакууме.
Итак, хватит ностальгировать, давайте погромпрограммировать. Моя платформа — это ноутбук с Ubuntu и видеокартой GeForce GT 540m и установленным CUDA Toolkit 5.0. Если вы начинаете знакомство с CUDA, то могу вам посоветовать интересную книгу CUDA by Example.
Для начала создайте проект из шаблона Nsight и подключите к нему freeglut используя библиотеки GLU, GL, glut. Это позволит нам отобразить полученное векторное поле, которое мы рассчитаем. Приблизительная структура нашего файла с функцией main будет следующая:
#include <stdio.h> #include <stdlib.h> int main(int argc, char** argv) { // Initialize freeglut // ... // Initialize Host and Device variables // ... // Launch Kernel to render the image // Display Image // Free resources return 0; }
Для начала, всё выглядит просто. Давайте, сперва, отобразим окно нужного нам размера ну и срендерим чёрный экран. Кстати, скажу вам очевидную вещь: если какая-то функция вам незнакома, то просто погуглите.
Инициализация окна
Так как я, когда задумывал приложение, не планировал динамическое изменение размера окна, то я решил указать его декларативно, используя глобальные константы:
const int width = 1280; const int height = 720;
Ах да! Не судите строго за смешивание стилей C++ и C99. Некоторые вещи, типа перегрузки, я порой нахожу полезным, но и от malloc я не отказался, чтобы хоть как-нибудь следовать стилю приложениям с CUDA.
Само отображение окна, обработка клавиши Escape и простой рендер можно осуществить следующим кодом:
#include <GL/freeglut.h> #include <GL/gl.h> #include <GL/glext.h> // ... void key(unsigned char key, int x, int y) { switch (key) { case 27: printf("Exit application\n"); glutLeaveMainLoop(); break; } } void draw(void) { glClearColor(0.0, 0.0, 0.0, 1.0); glClear(GL_COLOR_BUFFER_BIT); // glDrawPixels(width, height, GL_RGBA, GL_UNSIGNED_BYTE, screen); glFlush(); } // ... // Initialize freeglut glutInit(&argc, argv); glutInitDisplayMode(GLUT_SINGLE | GLUT_RGBA); glutInitWindowSize(width, height); glutCreateWindow("Electric field"); glutDisplayFunc(draw); glutKeyboardFunc(key); glutSetOption(GLUT_ACTION_ON_WINDOW_CLOSE, GLUT_ACTION_CONTINUE_EXECUTION); // ... // Display Image glutMainLoop();
При запуске этого кода, вы ничего кроме чёрного экрана не увидите. Так что я опущу здесь скриншот. Обратите внимание на следующие моменты:
glutLeaveMainLoop — когда нажат Escape, то freeglut позволяет прервать главный цикл, чтобы мы смогли освободить ресурсы приложения. Если хочется, то можно использовать и atexit;glDrawPixels — позже я создам буфер из unsigned byte, где я буду хранить все пиксели (их цвета) и потом отображать в окне;glutSetOption — это мне позволить продолжить выполнение кода в main, чтобы очистить ресурсы в виде динамической памяти.
Разбиение вычисление на блоки и потоки
Побаловавшись с примерами, я смог для себя уяснить, что представляет собой такое понятие как блок и поток, и что делать с их размерностью. В принципе, если опустить технические детали, то блок — это клетка, в которой есть некоторое количество потоков. Когда происходит вычисление целой сетки блоков, то в какой-то момент времени каждый блок выстреливает свои потоки, дожидается их завершения и передает управление другому блоку. Так, например, вы можете нагенерить блоки в одномерную полоску, или в двухмерную сетку.
Потоки, в свою очередь, тоже могут располагаться в блоке в виде одномерной полосы, или двухмерной таблицы. Кстати, возможны варианты с тремя измерениями, но я их упущу, так как они пока не вписываются в мою задачу.
Я могу разбить экран на большие квадраты (блоки), внутри которых пиксели будут рендериться отдельным потоком. Такая задача — оптимальное использование графической карты, но чтобы разбить экран на блоки, придется применить простую арифметику — я узнаю число потоков дозволенного мне в пределах блока, и затем поделю размер окна на количество потоков по горизонтали и вертикали.
Чтобы узнать количество потоков внутри блока, воспользуемся функцией cudaGetDeviceProperties:
int threadsCount(void) { int deviceCount = 0; cudaGetDeviceCount(&deviceCount); if (deviceCount <= 0) { printf("No CUDA devices\n"); exit(-1); } cudaDeviceProp properties; cudaGetDeviceProperties(&properties, 0); return properties.maxThreadsPerBlock; }
Моя карта возвращает число 1024. К сожалению, я не могу использовать все потоки, потому что в режиме отладки, при делении float чисел, я получаю ошибку cudaErrorLaunchOutOfResources. Я так и не смог отыскать, почему мне не хватило ресурсов (или регистров, как пишет интернет), поэтому единственные три решения, что я смог найти — это снижение числа потоков на блок, использование release режима при компиляции, использование опции maxrregcount с любым числом больше нуля.
Если вы дочитали мою статью до этого момента, то я рад, что не зря сижу ночью перед компом. А если вы знаете ответ, как узнать в чем именно была моя ошибка, и сообщите мне его, то я буду рад вдвойне.
Теперь разобьём наше поле на блоки и потоки:
void setupGrid(dim3* blocks, dim3* threads, int maxThreads) { threads->x = 32; threads->y = maxThreads / threads->x - 2; // to avoid cudaErrorLaunchOutOfResources error blocks->x = (width + threads->x - 1) / threads->x; blocks->y = (height + threads->y - 1) / threads->y; } // ... // Initialize Host dim3 blocks, threads; setupGrid(&blocks, &threads, threadsCount()); printf("Debug: blocks(%d, %d), threads(%d, %d)\nCalculated Resolution: %d x %d\n", blocks.x, blocks.y, threads.x, threads.y, blocks.x * threads.x, blocks.y * threads.y);
Результат будет следующим (я заведомо увеличил количество блоков на единицу в тех случаях, когда размер экрана не кратен числу потоков):
Debug: blocks(40, 24), threads(32, 30) Calculated Resolution: 1280 x 720
Теория и практика
Заряды, расстояния, кулоны и коэффициенты — это звучит хорошо. Но когда дело доходит до моделирования, то тут мы не можем уже пользоваться супер-маленькими значениями, потому что они могут пропасть в процессе вычисления. Поэтому мы упростим задачу:
Заряд — это структура с координатами (как на экране).
struct charge { int x, y, q; };
Напряжённость электрического поля в точке — это вектор, который мы выразим проекциями и функции, вычисляющей их (вот именно здесь я и получил свою ошибку):
const float k = 50.0f; const float minDistance = 0.9f; // not to divide by zero const float maxForce = 1e7f; struct force { float fx, fy; __device__ force() : fx(0.0f), fy(0.0f) { } __device__ force(int fx, int fy) : fx(fx), fy(fy) { } __device__ float length2() const { return (fx * fx + fy * fy); } __device__ float length() const { return sqrtf(length2()); } __device__ void calculate(const charge& q, int probe_x, int probe_y) { // F(1->2) = k * q1 * q2 / r(1->2)^2 * vec_r(1->2) / abs(vec_r(1->2)) // e = vec_F / q2 fx = probe_x - q.x; fy = probe_y - q.y; float l = length(); if (l <= minDistance) { return; } float e = k * q.q / (l * l * l); if (e > maxForce) { fx = fy = maxForce; } else { fx *= e; fy *= e; } } __device__ force operator +(const force& f) const { return force(fx + f.fx, fy + f.fy); } __device__ force operator -(const force& f) const { return force(fx - f.fx, fy - f.fy); } __device__ force& operator +=(const force& f) { fx += f.fx; fy += f.fy; return *this; } __device__ force& operator -=(const force& f) { fx -= f.fx; fy -= f.fy; return *this; } };
Задумка моя простая — я создам двухмерный массив из векторов напряжённостей. В каждой точке экрана, напряжённость будет равна сумме векторов кулоновских сил. Звучит заумно, но я иначе не смог сформулировать. Проще сказать, код будет вот таким (вы его прочтите, но не пишите ещё в свой проект):
force temp_f; for (int i = 0; i < chargeCount; i++) { temp_f.calculate(charges[i], x, y); *f += temp_f; }
Если мы попадём в заряд, то я пропускаю вычисление напряженности в этой точке (ибо делить на ноль нельзя). Так что на экране вы должны увидеть чёрную точку — заряд.
Теперь, когда мы создали инфраструктуру — давайте кодить под CUDA. Для начала создадим необходимые переменные хоста и устройства и освободим их!
Создаем и освобождаем ресурсы
Нам понадобятся следующие переменные:
- экран — хост — цветные пиксели;
- экран — устройство — они же;
- заряды — устройство — координаты и величины зарядов в постоянной памяти устройства.
Создаём:
uchar4* screen = NULL; // ... screen = (uchar4*) malloc(width * height * sizeof(uchar4)); memset(screen, 0, width * height * sizeof(uchar4)); uchar4 *dev_screen = NULL; cudaMalloc((void**) &dev_screen, width * height * sizeof(uchar4)); cudaMemset(dev_screen, 0, width * height * sizeof(uchar4)); // ... // Free resources free(screen); screen = NULL; cudaFree(dev_screen); dev_screen = NULL;
Заряды проинициализируем просто. Я не сбрасываю генератор случайных чисел, чтобы получить одну и ту же картину. Если вы хотите случайное поле каждый раз, то можете добавить вызов srand:
const int chargeCount = 10; __constant__ charge dev_charges[chargeCount]; const int maxCharge = 1000; const int minCharge = -1000; // ... void prepareCharges(void) { charge* charges = (charge*) malloc(chargeCount * sizeof(charge)); for (int i = 0; i < chargeCount; i++) { charges[i].x = rand() % width; charges[i].y = rand() % height; charges[i].q = rand() % (maxCharge - minCharge) + minCharge; printf("Debug: Charge #%d (%d, %d, %d)\n", i, charges[i].x, charges[i].y, charges[i].q); } cudaMemcpyToSymbol(dev_charges, charges, chargeCount * sizeof(charge)); } // ... prepareCharges();
Помните закомментированную строку, рендерящую экран? Теперь вы можете её раскомментировать:
glDrawPixels(width, height, GL_RGBA, GL_UNSIGNED_BYTE, screen);
Создадим ядро
Теперь создадим функцию, которую мы будем вызыватhttp://habrahabr.ru/sandbox/add/#ь в каждом потоке, чтобы срендерить каждый пиксель на экране. Эта функция будет выполнять следующее: она вычислит значение напряжённости поля, и вызовет другую функцию, чтобы сопоставить какой-нибудь цвет точке.
__device__ uchar4 getColor(const force& f) { uchar4 color; color.x = color.y = color.z = color.w = 0; float l = f.length(); color.x = (l > maxLengthForColor ? 255 : l * 256 / maxLengthForColor); return color; } __global__ void renderFrame(uchar4* screen) { // build the field and render the frame }
Чтобы вызвать ядро… а впрочем и так всё ясно:
// Launch Kernel to render the image renderFrame<<<blocks, threads>>>(dev_screen); cudaMemcpy(screen, dev_screen, width * height * sizeof(uchar4), cudaMemcpyDeviceToHost);
Теперь добавим немного кода в renderFrame и получим то, что нам нужно:
__global__ void renderFrame(uchar4* screen) { int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; force f, temp_f; for (int i = 0; i < chargeCount; i++) { temp_f.calculate(dev_charges[i], x, y); f += temp_f; } screen[x + y * width] = getColor(f); }
Вывод
Часто народ пропускает статью, потому что важен вывод. Мне здесь нечего сказать, кроме как опубликовать картинку, что у меня получилась. Ссылку на почти пустой репозиторий найдёте здесь.

В принципе, есть куда развиваться — можно например добавить анимацию, показывающую как меняется поле при перемещении зарядов. Но опять же, если это интересно.