Светодиодная лампа за 169 рублей. Лампа антибактериальная. Производитель — именитый бренд Осрам, он же Ledvance.
Поверхность лампы покрыта некой пленкой из диоксида титана и Осрам утверждает, что рядом с этой пленкой из диоксида титана погибают все микробы, и расщепляются запахи в результате фотокаталитического эффекта. Но не ждите от меня, конечно, таких совершенно непонятных для меня тестов. Я не буду сыпать на колбу этой лампы какой-нибудь неизвестный белый порошок и уверять вас, что теперь, после того как лампа поработала с ним он стал абсолютно безвреденым, все микробы уничтожены.
В этом обзоре будут измерены реальные характеристики света, продемонстрированы возможности лампы, но не более.
Начнем с мощности. 220 Вольт в сети, включаю лампу — при первом включении 6,4 Ватта что-то не похоже на 8,5 Вт, ну просто никак.
Увеличу напряжение до 230 Вольт. Теперь 7.8 Вт. Коэффициент мощности 0,59.
Коэффициент мощности помогает соотнести величину активной полезной мощности с величиной реактивной, ненужной нам. Здесь коэффициент мощности 0,59, обычный стандартный коэффициент мощности для светодиодных ламп. Расходы за год 124 рубля при работе лампы 8 часов в день и при тарифе 5,38 рублей за Киловатт.
Оставляю лампу поработать в течение 15 минут. Мощность лампы 8 Ватт при объявленных 8,5 Ватт на упаковке, это результат неплохой. Хотя, конечно, для Осрам я ожидал что увижу честные 8,5 Ватт.
Лампа включена, убираю внешнюю подсветку. Стартую измерение характеристик света. Цветовая температура 3855, индекс цветопередачи 81,1.
Измерены координаты X и Y и по ним, видя точку на диаграмме цветности, и посчитав что дельта UV равно 0.0026, что меньше порога заметности 0.004, получаю оценку величины оттенка цвета в свете этой лампы. Точка между 4000 и 3000 Кельвина. Присутствует минимальное, незаметное глазом смещением вверх в область желто-зеленых оттенков.
Пульсации 14,3% на частоте 100 Гц. Высокий риск — в красной области. Да зачем же мне такая антибактериальная лампа, которая убивает микробы, устраняет запахи, но ломает мне глаза?! И при этом такие пульсации на 230 В. Именно там, где мощность лампы максимально приближена к объявленной производителем.
Лампа в метре над плоскостью стола включена и прогрета, на входе 220 вольт. Убираю внешнюю подсветку – 229 Люкс. А если увеличится до 250 вольт на входе? Нет, не заметим такого изменения освещенности.
При 170 Вольтах лампа практически погасла, сэкономив мне еще один эксперимент. Драйвер лампы от Осрам не позволяет использовать эту лампу там, где напряжение в розетках нестабильно.
Протестируем работу с выключателем с подсветкой. Подаю напряжение в сеть, загорелась красная лампочка подсветки, вроде бы не моргает, не мигает лампа. Убираю внешнюю подсветку, да, все хорошо. Включаю. Горит на полную яркость. Выключаю. Никаких проблем, все хорошо.
Размеры лампы: я получил — 112 мм и второй размер — 60 мм. На упаковке же 113 на 60.
Нагрев колбы 43 градуса Цельсия, ну а корпус традиционно нагревается сильнее, температура там — 75 градусов.
Перед тем как разобрать лампу, я снял диаграмму освещенности в темной камере и по 10 точкам измеренной освещенности посчитал световой поток. Диаграмму освещенности вы видите на своих мониторах. Световой поток, который я посчитал 685 Люмен, заметно меньше тех 806 люмен которые указал Осрам.
Разбираем. Корпус нас ничем особенно не удивит. Хороший качественный белый пластик от Осрам. Рассеиватель, поликарбонат матовый. Матовость достаточная, не видны светодиоды в выключенном состоянии. И форма правильная, больше полусферы и вперед, и назад будет распространяться свет.
Вот так выглядит светодиодная лампа со снятым рассеивателем: 12 корпусов светодиодов, каждый корпус размером 2,8 на 3,5 мм.
Электролит на 4,7 микрофарад. Под люминофором каждого корпуса угадывается 4 маленьких кристалла, но это не точно, надо будет еще проверить.
Все корпуса соединены последовательно – один выходит из строя и гаснет вся антибактериальная лампа. Здесь же на диодной плате вместе с корпусами светодиодов греется диодный мост, микросхема стабилизации тока, резисторы драйвера. Сюда же на диодную плату выведены 220 вольт от цоколя лампы. Такое ощущение, что там внутри корпуса совершенно пусто, но в этом мы убедимся, когда снимем диодную плату.
Самое время измерить температуру диодной платы со снятым рассеивателем. Выбрать точку подключения термопары, где температура диодной платы максимальна, поможет мне тепловизор. Включаю лампу. После того, как лампа поработала полчаса, тепловизор указал самую горячую точку.
Отмечаю данную точку на диодной плате. Сюда и буду подключать термопару. Термопара будет установлена в самую горячую точку диодной платы
После получасового прогрева температура диодной платы 72 градуса Цельсия. Под рассеивателем выше 100 градусов не будет, тем самым лампа подтвердила температурный режим, допустимый для длительной работы светодиодов.
Внутри каждого корпуса вижу абсолютно разное количество светлых пятен. Корпуса 6, 5, например – в них вижу 4 светлых пятна.
В корпусах 7 и 4, в них я наблюдаю 2 светлых пятна, 8 и 3 опять 4 пятна, и 9 – 4 пятна, а вот 2, 1, 12 и 10 – 2 пятна, 11 – 4 пятна. Неужели разное количество кристаллов внутри каждого корпуса. Это надо будет уточнить, измерив прямое падение напряжения на корпусах светодиодов.
Измеряю прямое падение напряжения на третьем, на том внутри которого я увидел четыре ярких пятна. 10,8 Вольт. Понятно.
Теперь измеряю на корпусе номер 2. Там, где я видел, два ярких пятна. 35,2 Вольта. В результате измерений прямого падения напряжения на корпусах светодиодов выяснили, что на диодной плате распаяно 6 сборок по 13 кристаллов в каждой и 6 сборок по 4 кристаллов в каждой.
Итого, на этой диодной плате последовательно соединены 102 маленьких кристалла светодиода. Как всегда, одно яркое пятно не обязательно значит один маленький кристалл светодиода.
Ток в цепи питания светодиодов 21,3 мА.
Разбираю лампу дальше. Здесь все ожидаемо, так же как в любых других светодиодных лампах, все привычно. Металлическая резьбовая часть цоколя снята. И внутри уже видно, что внутри ничего нет. Но давайте убедимся, выпрессуем диодную плату.
Хорошо запрессовано — хорошая теплопередача между диодной платой и радиатором корпуса. Внутри радиатора только предохранитель в цепи питания 220 Вольт, как я и ожидал.
Охлаждение. Диодная плата передает избыток тепла от элементов, распаянных на ней алюминиевой подложке. Алюминиевая подложка, в свою очередь, передает тепло радиатору, встроенному в корпус композит. Ничего оригинального здесь Осрам не предложил. Типовая схема охлаждения.
Мне давно хотелось узнать существуют ли программисты, которые понимают «делегирование» в рамках ООП так же, как я. А когда я случайно обнаружил что в Шаблонах проектирования (Design Patterns) в фундаментальных трудах признанных классиков концепций программирования пропущено описание для Делегирования, у меня появился повод написать эту статью.
Так получилось, что я сначала познакомился с этой техникой на практике разрабатывая DirectShow фильтры и COM-объекты, которые составляют эти фильтры и меня особо не интересовало как все это по-умному называется пока это все прекрасно работает. Проблемы возникают, когда ты пытаешься объяснить кому-то КАК это работает, или когда ты пытаешься предложить кому-то хотя бы попробовать использовать определенную технику программирования. Вот именно при таких попытках у меня получилось сопоставить что то, что я использую очень подходит под определение Design Pattern: Delegation.
Давайте посмотрим будет это поводом посмеяться или задуматься.
Должен предупредить что тем, кто воспринимает чужое мнение по техническим вопросам как оскорбление только потому, что он не согласен с этим мнением, не нужно читать эту статью.
Кто дочитает до конца найдет ответ на вопрос который задает название.
Статья от 2016 года и это перевод заметки какого-то неизвестного мне специалиста по программированию (видимо в области Ruby и Rails). Очень интересно было узнать, что и в 2012 году, и видимо в 2016, и, как мне кажется, и теперь существуют более или менее признанные специалисты по программированию которые нервничают(мне так показалось по крайней мере по Заметке) из-за того что не могут внятно сформулировать сначала проблему для решения которой будет использоваться Делегирование, как шаблон проектирования, а затем и саму технику реализации такого решения в терминах ООП. Конечно, перевод не может быть лучше, чем сама заметка, которая переполнена эмоциями на мой взгляд, но я хочу отметить один очень положительный момент в этом переводе. Там я увидел корректный перевод для словосочетания: «your business domain concepts» как «концепции логики работы приложения (приложения в разработке)». Дело в том, что я много раз слышал про какую-то непонятную «бизнес логику» в рассуждениях об архитектурных решениях для софта и вот здесь я понял, откуда берется эта «бизнес логика». В большинстве случаев это неправильный, вырванный из контекста перевод словосочетания со словом «business» и признак непонимания темы.
То, что изложено в той статье и в ее исходнике со всеми ссылками очень помогли мне построить эту статью, дали мне как бы опору для моей статьи. Далее я буду на нее ссылаться как на «Заметку».
Как же так получилось, что авторы фундаментального труда: «Design Patterns: Elements of Reusable Object-Oriented Software» (на который ссылается Заметка, далее упоминаю как «книга «Design Patterns» или просто Книга) пропустили (судя по таблице из википедии) один из шаблонов проектирования, который называется делегирование?
То, что описание для делегирования пропущено, тем более удивительно что COM (который Component Object Model) существует как минимум с середины 90-х, и еще (и уже) в начале 2000-х я активно пользовался инфраструктурой COM, которая позволяет делегировать разного рода ответственность (в частности, просто вызовы функций) к объектам, которые содержатся в объекте внешнего класса в виде полей, элементов внутренних массивов, списков, … чего угодно.
Чтобы не было проблем с интерпретацией того, о чем идет речь, я поясню что имеется в виду примером С++ подобного кода.
Пусть у нас есть класс А в котором определено поле fld1 объявленное с типом B:
Class A { B fld1; … public void a_func1(…){…} }
В этом случае можно сказать, что объект класса А «знает» некоторый объект класса В и более того поскольку объект класса В является полем класса А то очевидно что класс B является частью объекта класса A, то есть он занимает память внутри объекта класса А. (Обратите внимание: приходится всегда повторять это словосочетание «объект класса Х» так как написать без слова «объект» никак нельзя. Это кардинально ломает смысл-логику рассуждений!)
Пусть класс В определяет некоторый метод b_func1:
Class B { public void b_func1(…){…} }
Вполне логично предположить, что если в составе класса А есть объект класса В то при наличии объекта класса А и при необходимости выполнить работу которую умеют выполнять объекты класса В, будет вполне логичным обратиться к объекту класса А, если, и когда он уже есть в наличии как в псевдо коде ниже:
… A a_obj = <get somehow Class A object> ; … <нужно выполнить работу с помощью объекта класса В, например функцию b_func1> <почему бы не использовать объект класса В из состава объекта класса А: a_obj?> <А если нам запрещено создать новый объект класса В когда один уже создан?> …
Само собой здесь напрашивается каким-то образом получить объект или ссылку на объект класса В из класса А и это действительно прямой путь к возможному решению, только этот путь не учитывает некоторые очень важные возможности, которые очень нужны если мы рассматриваем код как расширяемый и хорошо поддерживаемый. Эти возможности не так просто осознать, поэтому я предлагаю пока забыть про то, что можно как-то получить ссылку на объект из состава сложного объекта (в некоторых описаниях это outer object, смотри далее).
Общеизвестный вид Делегирования
С точки зрения любого языка, который поддерживает классы, мне кажется логично различать два вида делегирования, первый и насколько я понимаю общеизвестный, когда метод (или методы) класса используют методы (сервисы) внутреннего объекта для реализации собственных методов. И это практически дословный перевод из COM Fundamentals документации: The outer object «contains» the inner object, and when the outer object requires the services of the inner object, the outer object explicitly delegates implementation to the inner object’s methods. That is, the outer object uses the inner object’s services to implement itself. Containment/Delegation — Win32 apps | Microsoft Learn
Если посмотреть, например на описанный в книге «Design Patterns»: ADAPTER (Адаптер, он же Wrapper) с этой точки зрения, то мы увидим, что получается, что Адаптер является частным случаем Делегирования, так как он описывает способ использования методов внутреннего объекта класса для реализации внешнего-адаптированного интерфейса вновь созданного класса.
В книге «Design Pattern» для иллюстрации шаблона Адаптера приведен такой пример (в том числе). Класс:
Кстати, почему внутренний объект (_text в примере) в виде поля с указателем на объект является более гибким решением чем объект того же типа в составе класса заданный через множественное наследование:
class TextShape : public Shape, private TextView {…
Обосновано так:
«For example, the object adapter version of TextShape (имеется в виду как раз версия в которой объект определен в виде члена класса-поля класса) will work equally well with subclasses of TextView—the client simply passes an instance of a Text View subclass to the TextShape constructor.»
Даже не буду переводить – все очевидно.
В реализации методов мы видим, что этот шаблон проектирования предлагает нам вызывать методы внутреннего объекта, как раз то, что в MS документации называется: «outer object explicitly delegates implementation to the inner object’s methods».
Далее если мы посмотрим, что же нам предлагают другие описанные в книге структурные шаблоны мы увидим, что в большинстве случаев они описывают разные техники вызова методов у некоторого объекта (объектов)-члена класса для реализации некоторого специального вида взаимодействия объектов этих классов. Посмотрите BRIDGE (Handle/Body), COMPOSITE, DECORATOR (тоже Wrapper), FACADE (про него вообще написано, что он delegates client requests to appropriate subsystem objects) все они определяют специальное поле(поля) реализуемого класса, которое(которые) инициализируется объектом, к которому, по сути, делегируются определенного вида вызовы.
И поэтому вполне логично заключить, как мне кажется, что рассмотренный здесь шаблон Адаптер как и остальные шаблоны которые по сути в каком то виде делегируют «реализацию реализации» (или «ответственность за реализацию») является частным случаем более общего шаблона Делегирования!
То же Делегирование для Behavioral шаблона
Интересный случай рассматривается для Behavioral шаблона State (Стейт). И именно этот случай упоминается в «Заметке».
Суть шаблона Стейт в том, что объект Контекст имеет поле-ссылку на объект Состояния и это текущий объект Состояния, который выполняет всю работу, так как Контекст делегирует всю работу, которая к нему приходит в виде вызовов функций к этому текущему объекту Состояния. И в том числе текущий объект Состояния отвечает за то, чтобы подменить указатель на текущий объект Состояния (то есть на себя самого) в поле объекта Контекст, так что следующий вызов функции, который придет к объекту Контекст будет делегирован к новому текущему объекту Состояния из внутреннего поля объекта Контекст и будет обработан этим другим объектом Состояния (объектом другого Состояния). В Книге так и написано: Context delegates state-specific requests to the current ConcreteState object.
Очень советую попробовать так сделать. Это очень хороший способ избавиться от SWITCH-ей в коде, с разными интересными бонусами!
Совсем коротко можно сказать, что мы создаем объект Контекст для вызова методов какой-то реализации объекта Состояния, с возможностью замены одной реализации объекта Состояния на другую внутри объекта Контекст.
Как видите, нет ничего проще, для тех, кто привык к таким диалектическим построениям в архитектуре софта.
Автора Заметки видимо очень впечатлила возможность сравнения возможностей языка Self с возможностями языка JS для, определенного конкретно в этом Behavioral шаблоне State, понятия о Делегировании. Я не думаю, что тот пример на JS имеет шансы кому-то что-то доказать, для меня этот пример важен, потому что он еще раз демонстрирует что Делегирование это все-таки какое-то общее понятие, которое сложно выделить как отдельный паттерн проектирования, это прием, который используется очень широко.
Другой вид Делегирования с реальным примером
Мне кажется, в СОМ технологии есть особый вид техники построения взаимодействия объектов, который мог бы быть описан как отдельный паттерн под именем Делегирование.
Для начала абстрактный-бытовой пример.
Представьте вы приходите в организацию за какой-то бухгалтерской справкой, куда вас направят? С большой вероятностью к бухгалтеру, особенно если вы точно знаете, что вам нужен бухгалтер. В терминах ООП можно сказать, что вы сообщите тип нужного вам интерфейса и вам напрямую выдадут интерфейс, который сможет принять и решить ваш вопрос, то есть запрос. Конечно, если в процессе не произойдет эксепшен по причине того, например, что версия выданного бухгалтера не поддерживает ваш тип запроса
Или.
Если вы ошиблись с интерфейсом – так бывает, что совершенно одинаковые по сигнатуре функции реализованы в разных интерфейсах.
Можно такой тип взаимодействия назвать делегированием? Я думаю, что можно! Только это другой тип делегирования. Тут мы делегируем не отдельные запросы или работы или вызовы внутрь объекта к его внутренним объектам, мы делегируем внутренний объект навстречу клиенту чтобы клиент и этот объект работали напрямую.
В основе COM технологии лежит возможность или скорее даже требование поддержки такого типа делегирования внутренних объектов СОМ объекта по запросам, использующего этот COM объект кода (по запросам клиента).
Это то, что реализуется через интерфейсную функцию:
Для тех, кто пишет на языках со встроенной сборкой мусора, возможно будет интересно проследить аналогию между интерфейсом IUnknown в СОМ и классом object в таких языках как Java, C#. В том и другом случае это корень иерархии объектов, который определяет способ контроля времени жизни объекта. Только в Java, C# подсчет ссылок добавляется автоматически компилятором, в СОМ можно написать свою реализацию интерфейса IUnknown, или скопировать стандартную. При этом в СОМ есть вот этот интересный бонус (для многих непонятный и странный, я подозреваю) в виде функции QueryInterface.
Я попробую пояснить смысл этого странного бонуса на практическом примере, который оказался у меня под рукой.
Если вы захотите реализовать проигрывание звука в своем приложении, вам понадобится циркулярный буфер, в который вы будете писать аудио семплы, а звуковое устройство и его драйвер будут проигрывать эти аудио семплы из этого буфера.
В терминах концепции DirectSound такой циркулярный буфер будет представлен набором функций для записи в этот буфер, этот интерфейс можно получить с помощью кода:
Заметим, что нам не обязательно знать конкретный тип устройства, NULL_DEVICE_GUID позволяет обращаться к текущему активному устройству в системе, представленному интерфейсом LPDIRECTSOUND8. Далее с помощь функции QueryInterface интерфейса IUnknown, мы получаем объект циркулярного буфера, который представлен интерфейсом LPDIRECTSOUNDBUFFER8. Мы не знаем когда был создан объект буфера, в момент обращения или в момент создания объекта устройства, но нам это и не надо знать.
Теперь мы можем передать данные в буфер и запустить проигрывание из буфера:
HRESULT hResult = m_lpDSB2->Lock(m_samplesTail, numBytes, &lpvAudio1, &dwBytesAudio1, &lpvAudio2, &dwBytesAudio2, 0); // Write to first pointer memcpy(lpvAudio1, audioBuffer, dwBytesAudio1); . . . // Release the data back to DirectSound hResult = m_lpDSB2->Unlock(lpvAudio1, dwBytesAudio1, lpvAudio2, dwBytesAudio2); HRESULT hResult = m_lpDSB2->Play(0, 0, DSBPLAY_LOOPING); if (FAILED(hResult)) { return hResult; } . . .
Как видите функция QueryInterface интерфейса IUnknown нужна нам только в самом начале чтобы получить доступ к объекту, о котором мы ничего не знаем, кроме того с помощью каких функций мы можем к нему обращаться, с ним работать. Заметьте, что мы получили эти функции напрямую и нам делегировал этот интерфейс объект внешний к тому, в котором эти функции реализованы. Получив этот интерфейс и работая с ним напрямую мы не несем никаких дополнительных издержек связанных с диспетчеризацией вызовов через промежуточные объекты как в других шаблонах проектирования, мы получили самый эффективный способ взаимодействия объектов!
Заключение
В заключение я перечислю основные идеи, которые я попытался обосновать.
Существует два способа делегирования: делегирование внутрь (просто делегирование, делегирование в общеизвестном смысле) и делегирование наверх
или
делегирование к внутренним объектам (просто делегирование) и делегирование самих объектов наружу.
Делегирование — это прием для построения взаимодействия объектов в коде. Он слишком общий или слишком простой чтобы его выделить и описать как отдельный шаблон проектирования. В Книге «Design Patterns» были описаны конкретные шаблоны, во многом основанные на делегировании.
Второй способ делегирования создает предпосылки для получения самого эффективного способа взаимодействия объектов.
Привет, я Вика Синельникова — руководитель отдела спецпроектов в KTS. Рассказываю, как еженедельно планировать команду на большой объем проектов и не сойти с ума.
Как планирование разработки работает в большинстве компаний
Большая часть команд разработки, даже внутри нашей компании, занимается проектами, длительность которых начинается как минимум от месяца, а то и трёх.
Когда общий срок проекта исчисляется месяцами, принято планировать работу спринтами. Например, в других отделах нашей компании, работают двухнедельными спринтами. Менеджеру и руководителю это даёт заранее известный и прогнозируемый загруз команды на месяцы вперед. Объём планирований при этом сокращается.
При работе спринтами основная часть планирования приходится на пре-старт самой разработки. Дальше весь объём задач нескольких месяцев планомерно разбивается этапами по пару недель. В процессе работы менеджер и руководитель следят за выполнением плана и при необходимости актуализируют его.
Как работает наш отдел
Основное отличие в том, что срок разработки некоторых типов проектов может быть всего несколько дней. Такие сроки сильно влияют на планирование загрузки всего отдела.
Проект для нас — как, думаю, и для многих команд — не заканчивается запуском, а переходит в статус поддержки. Нагрузка и аудитория этих проектов очень большая (за день работы проекта аудитория может достигать нескольких сотен тысяч человек). Поэтому поддержку тоже очень важно учитывать при планировании. Сразу отмечу то, что не планировать ничего кроме поддержки на человека или передавать поддержку другому разработчику — невозможно. В первом случае разработчик может быть недозагружен, так как объем проектов поддержки не позволяет переключить человека полностью. Во втором — нужно знать слишком много нюансов внутри проекта.
Также помимо проектной работы у нас есть дейлики, менторские встречи и внутренние задачи. Следовательно важно учитывать все эти задачи при планировании, чтобы не получилось так, что время разработчиков забронировано только на разработку новых проектов. И распределять всё это в рамках восьмичасового рабочего дня.
Первые попытки спланировать работу отдела
Пять лет назад я была единственным менеджером, который вёл разработку проектов с короткими сроками в KTS. Весь объём задач, сроки запусков проектов, загрузку разработчиков я хранила в чертогах своего разума и изредка выписывала их на бумагу.
Когда менеджеров стало больше, мы столкнулись с проблемой планирования разработчиков. Один и тот же разработчик мог отвечать за разные стадии проектов — например, и разработка и поддержка — у двух разных менеджеров. Мы попробовали решить эту проблему, создав по чату с менеджерами на каждого разработчика. Это было не идеально, но помогало и нам, и ребятам понимать приоритетность задач и время их решения.
Чем дальше мы росли, тем больше мы понимали, что нужна система планирования. Сначала мы попробовали отталкиваться от планирования контрольных точек на проекте. Это было нужно, чтобы знать, кто должен сделать что-то на определённом проекте в конкретный день и не быть загруженным другими задачами. Тогда, в 2019 году появилась наша первая таблица с говорящим названием «День грядущий». Ожидаемо, что сразу идеала не получилось и быстро стало ясно, что сам подход ошибочный.
Буквами «р», «з», «к» обозначены контрольные точки на проекте.
Эволюция набирает обороты
В 2020-й год мы вошли с новой табличкой и постарались сделать распределение загрузки более наглядной. Тогда казалось, что достаточно лишь добавить в неё разработчиков.
Это помогло, но не решило все проблемы планирования. Самым полезным в этой таблице было то, что мы стали заранее вносить проекты, которые могут подтвердиться.
Уже по таблице 20-го года можно заметить тизер надвигающейся проблемы: наслоение задач по разным проектам на одного человека. Мы немного изменили саму таблицу в 21-м году, стало получше, но она до сих пор не могла полноценно решить наших целей при планировании.
Таблица-космолёт для планирования
После предыдущего опыта мы поняли, что:
нам критично важно понимать не только планирование разработчика на день, но и на каждый час в дне. Это может звучать пугающе, но когда мы анализировали, почему не хватает времени на какие-то задачи, мы заметили, что в рамках дня у всех есть мелкие переключения (например, сходить на встречу) — и стали это учитывать;
нам нужен учёт сопутствующих расходов. Это, например, встречи с менторами или внутренние задачи;
нам нужно учитывать не только разработку, но и поддержку и ревью проектов;
команда выросла и важно было никого не забыть;
с таблицей могли работать не только менеджеры, но и лиды разработки в отделе;
нужна быстрая аналитика загрузки для принятия решения по новым заявкам и для сверки плана экономики отдела.
То, что у нас получилось может подойти командам, где необходимо вести работу над всеми проектами одновременно, например, небольшим агентствам.
Как теперь выглядит наша таблица
У таблицы есть два формата: свёрнутый вид с графиками для быстрого анализа загруженности отдела и развёрнутый вид, где показаны детали по каждому из ребят в отделе.
Свернутый вид
На картинке ниже видно, что мы освоили графики внутри ячеек и, что большинство ребят в отделе распланированы. Их запланированные часы суммируются и подсвечиваются зелёным внутри диаграммы. Красный остаток рассчитывается относительно рабочего времени, учитывая разный формат работ (фуллтайм/парттайм). Также, сразу видно сводную информацию по загрузке всего отдела, кто и когда идет в отпуск. Этот вид помогает быстро принять решение о подтверждении сроков для новых заявок и сверять соответствие бизнес-плану.
Здесь большая часть часов уже распланирована.
Развёрнутый вид
В развёрнутом виде представлена разбивка возможных типов задач по каждому отдельному разработчику. Все задачи разбиваются на проектные — это разработка, поддержка и ревью — и непроектные. К последним относится обновление статусов, менторские встречи и внутренние задачи по отделу.
В своем планировании мы стараемся уделять время на развитие, но так как это внутренние расходы, нам важно, чтобы их объем не превышал 10% в месяц.
Справа — столбец с именем сотрудника и перечнем проектов, над которыми он работает. Сверху — количество рабочих часов.
Анализ загрузки отдела
Помимо оперативного доступа к структурированным данным в таблице есть и опция с быстрым анализом. Там указаны запланированные часы, незапланированные и их процентное соотношение.
Результаты
Главными результатами работы с нашим «космолётом» стали:
Сократилось время на планирование
Конечно, эта таблица не панацея и есть много других сервисов для планирования (их мы тоже рассматривали, даже внутри нашего таск-трекера), но они не до конца решали наши задачи, поэтому мы сделали удобный «инструмент»и под себя, который заметно упростил работу с планированием.
Понимание реальных сроков, в которые будет готова задача
После перехода на почасовое планирование в рамках дня, мы наглядно стали видеть, какие задачи могут влиять друг на друга, и точнее определять срок их сдачи.
Бóльшая независимость команды
Быть незаменимой легко, сложнее — выстроить работу так, чтобы даже без моего участия все знали, что они делают. С помощью таблички стало возможным делегировать процесс планирования на других менеджеров и лидов разработки. Без моего присутствия планирование может идти дольше, но уже не блокируется мной.
Вовлечение лидов разработки в процесс планирования
Предыдущие таблицы были слишком неструктурированные, поэтому подключить тимлидов к работе в них было тяжело.
Сейчас на встрече, помимо менеджеров, всегда есть тимлиды каждого направления разработки. Из планирования они понимают свои задачи, задачи других разработчиков и будущее планирование проектов.
К тому же таблица способна решать не только наши текущие проблемы, но и будущие, когда, например, у разработчиков появятся свои стажёры и им нужно будет планировать их рабочий день.
Делиться — значит заботиться
Эта таблица снизила неопределённость в планировании и разногласия среди менеджеров. Возможно, она поможет вам также как и нам.
Я скопировала нашу табличку, убрала лишнее и продублировала все месяцы на год вперед. В таблице есть пометки с тем, как ей пользоваться и примеры заполнения на разных участников команды: ссылка на неё.
Не стоим на месте
За время работы над этой статьёй, мы в команде пришли к следующей задаче, которую будем решать — удобное планирование менеджеров проекта. Казалось бы, звучит как то же планирование ресурса, но на деле оказалось не так просто. Но это уже совсем другая история..
Хотя… Если у вас есть своя боль и решение такой же задачи — буду очень рада, если поделитесь.
Если вам нужна помощь с решением ваших бизнес-задач, можно написать мне в телеграм и наша команда поможет придумать игровое решение.
Все чаще бизнесу приходится резервировать текущую инфраструктуру, чтобы повысить свою отказоустойчивость и качество предоставляемых услуг. Как правило, резервируется целая машина с нужным сервисом или кластер по схеме N+N. Но, что, если серверов много, а данные, которые нужны для полного восстановления сервиса, весят меньше мегабайта?
В этой статье мы рассмотрим базовую механику резервирования хостов по схеме N+k, где N — количество основных серверов, k — резервных.
Если вы решите создать свою сигнальную среду, эта статья для вас.
Предметная область
Сейчас я работаю на проекте, который специализируется на транскодировании и потоковой передаче видео в реальном времени. Движок поставляется в виде серверного ПО по лицензии. Имеет поддержку популярных протоколов передачи видео данных и большой набор различных решений для бизнеса — шифрование видеопотоков, наложение логотипов, blackout (перекрытие эфира), поддержку меток (SCTE, DTMF). К основной части ПО отдельно поставляется UI. Это весомый плюс, который сыграет в последствии нам на руку.
Известно, что ПО приобретают как единичными экземплярами, так и разворачивают на целые кластеры. Те, кому позволяют возможности и инфляция приобретают сразу дублирующие лицензии и заводят зеркальные серверы (схема резервирования N+N). Другие, скорее, отказываются полностью от резервирования. И таких преимущественно больше…
Учитывая стабильность работы кодирующего ПО, статистику выхода из кластера (недоступности) машин и данные, которые нужны для восстановления (а их действительно меньше 1 МБ), мы с командой решили подготовить сервис, позволяющий применять клиентам схему резервирования N+k.
Рецепт транскодирования
Собственно рецепт транскодирования в реальном времени сводится к четырем основным компонентам:
где кодировать (сервер),
что кодировать (источник сигнала). Чаще всего: UDP, MPEGTS-over-IP, SRT, RTMP,
по каким правилам (конфигурационный файл),
что получить на выходе (результирующий поток(и)). Чаще всего HLS, DASH, SRT, RTMP, UDP, MPEGTS-over-IP.
Тогда для восстановления системы потребуются:
источник сигнала,
конфигурационный файл,
в частных случаях периодически требуемые файлы для работы сервиса (видео файлы, изображения, расписание),
и, собственно, «живой» сервер с работающим ПО.
Кодирующее ПО включает 3 части:
streambuilder — главная часть, транскодирует потоки,
streambuilder-api — программный интерфейс, позволяющий управлять транскодером по сети, всегда ставится с основной частью.
streambuilder-ui — визуальная часть проекта или интерфейс управления пользователя. Позволяет удобно создавать конфигурации, просматривать статус сервисов и т.д. Идет как дополнительная часть, нужно устанавливать отдельно.
UI необязательно ставить вместе с основной частью, можно использовать вообще любую машину, имеющую сетевой доступ к серверам с API. Это дало ключевой вектор в решении текущей задачи. Именно к UI мы и решили добавить логику проверки серверов на доступность, сохранение бекапов конфигураций и перенос сервисов с одного хоста на другой.
Создаем логику бекапа сервисов
По практике проекта есть два типа пользователей — рядовые и продвинутые. Последние нередко управляют сервисами транскодирования напрямую через рутовую консоль в обход web-панели администратора.
Отсюда возникает вопрос: как синхронизировать такие конфигурации?
Решением стало создать периодическую задачу сравнения конфигураций. Как это работает: при создании конфигурации сервиса (канала/сhannel) мы добавляем его в базу данных. После чего, раз во время запрашиваем у хоста сравнение конфигураций.
Постоянная передача конфигураций по сети не является оптимальным решением. Вместо этого мы будем отправлять хосту название сервиса и хеш конфигурации. Если проверка проходит успешно, API возвращает «True». В случае несоответствия хешей, API возвращает отрицательный ответ, а также конфигурацию и её хеш, которые мы сохраняем в базе данных. Это позволяет быстро перенести конфигурацию на резервный хост и запустить сервис там, если основной хост становится недоступным.
Хорошо, мы успешно создали резервные копии сервисов, но как узнать, что хост действительно вышел из строя, а не просто возникла одноразовая сетевая ошибка?
Настраиваем проверки доступности серверов
На текущем этапе мы остановились на проверках двух типов: доступность API и доступность хоста.
Основной и первой работает проверка доступности API раз в . Если проверка не проходит, хосту назначается статус «обрати внимание». Здесь же запускается дополнительная вторая проверка, которая срабатывает мультикаст, если мы используем UDP. С выходом в UDP проблем тоже нет, отправляем вещать выход в мультикаст.
При использовании выходов с манифестами HLS или DASH всё немного сложнее — нужен DNS сервер. DNS должен иметь конечную точку, которая даёт возможность быстро изменить адрес сервера для конкретного имени, при смене сервера на котором работает сервис. Логика такая: клиент получает ссылку на плейлист (test_channel_host.com/live.m3u8), которая ведёт к серверу, где изначально находится сервис. При смене расположения канала система резервирования сигнализирует DNS серверу о том, что теперь выход с канала нужно забирать с другого сервера. Приняв запрос, DNS меняет записи в таблице на новые (например test_channel_host.com = 192.168.100.20 меняется на 192.168.100.52), что позволяет клиенту не менять адрес источника при смене сервера. Этот функционал сейчас находится в разработке.
Файлы, которые используются при кодировании потоков
Часто сервисы кодирования используют медиа файлы (видео, графика, расписание) — это могут быть сценарии, когда при кодировании накладывается логотип на видеопоток или, например, по расписанию добавляются возрастные метки на кадр видео или метки о вреде курения.
Для таких файлов предлагается использовать сетевое хранилище — сервис при запуске загружает нужные ему файлы по ссылкам указанным в конфигурации, что играет нам на руку и избавляет от необходимости:
перебрасывать медиа файлы по сети между хостами,
обновлять пути хранения файлов в конфигурациях.
Тесты и выводы
В итоге, мы имеем стабильную систему, которая при отказе работы основных хостов, позволяет максимально быстро восстановить работу сервисов транскодирования.
Максимальное время вычисляется как , где
период основной проверки, по умолчанию 5 секунд, — количество доп. проверок, умноженное на время задержки между попытками, по умолчанию 5 секунд и 5 проверок,
время на перенос каналов. Зависит от производительности хоста и сети, в среднем 10 сервисов в секунду, здесь считаем 10 сервисов.
— среднее время запуска сервиса, зависит от того, когда придёт ключевой кадр.
Получается 5+25+1+10 = 31 секунда, если использовать стандартные настройки, но это время можно уменьшить изменив настройки под конкретную сеть.
Минимально рекомендованные: позволяют сократить время до максимум 19 секунд.
Не рекомендуется делать эти значения меньше, так как, чем меньше эти настройки, тем более вероятна ситуация необоснованного перемещения сервисов. Например, в ситуации, когда моргнула сеть.
Конечно же, реализованная схема проигрывает по скорости переключения между хостами по схеме N+N, но учитывая стабильность системы, схема N+k может сильно сократить затраты на используемые серверные мощности и оптимизировать бюджет.
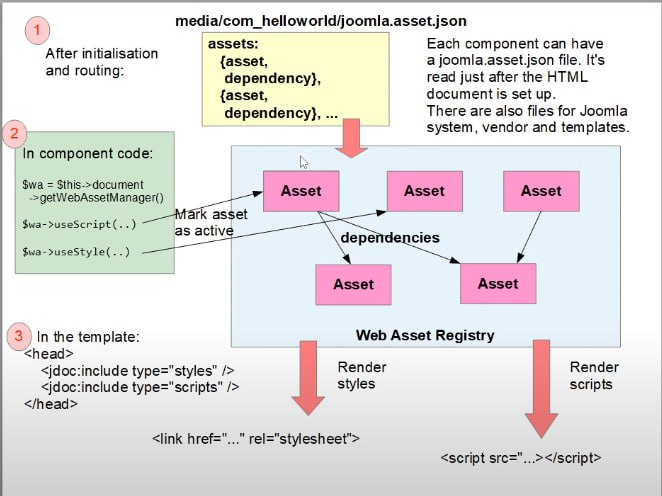
Все главные новости из мира Joomla с момента выхода предыдущего дайджеста 24 января 2023 года в одной статье. Традиционно наш дайджест обозревает новости, расширения, шаблоны и статьи из мира Joomla. Прошлый выпуск вы можете прочитать здесь.
Главные новости о Joomla
С момента выпуска предыдущего дайджеста вышло 7 стабильных релизов Joomla 4 (4.2.7-4.3.3) и один релиз Joomla 3 — 3.10.12. Обновление пакета локализации на русский язык Joomla 4.3.2.
Релизы безопасности Joomla
Релиз безопасности Joomla 4.2.7
Релиз содержит закрытие двух уязвимостей низкого уровня и другие исправления и улучшения.
Низкий приоритет — Низкое влияние — CSRF в сообщениях после установки (Joomla 4.0.0 — 4.2.6)
Низкий приоритет — Низкое влияние — Отсутствуют проверки ACL для компонента com_actionlogs
Также в этом релизе множество исправлений совместимости с PHP 8.2, исправлена ошибка автозагрузки namespaces для расширений типа library, в которых используется наименование библиотеки вида Vendor\Libraryname. Можно не создавать плагин, регистрирующий namespace библиотеки.
Релиз безопасности Joomla 4.2.8
Версия 4.2.8 — релиз безопасности с закрытием одной уязвимости высокого уровня. Настоятельно рекомендуем поддерживать версии CMS и расширений Ваших сайтов в актуальном состоянии.
низкого уровня — открытое перенаправление и XSS при мультифакторной авторизации. В Joomla 4.2.0-4.3.1.
среднего уровня, но критического воздействия — предотвращена возможность брутфорса на экране мультифакторной авторизации. Обе уязвимости помечены как имеющие низкую вероятность. Они возможны только в том случае, если Вы используете мультифакторную авторизацию на своих сайта. Но, тем не менее, рекомендуется поддерживать свои сайты в актуальном состоянии и своевременно обновлять версии движка и расширений.
Joomla 4.3
Вышла Joomla 4.3, главным новшеством которой стали Обучающие туры по панели администратора. Обзоры новой функции смотрите в разделе Статьи и видео этого дайджеста.
Также в этом релизе:
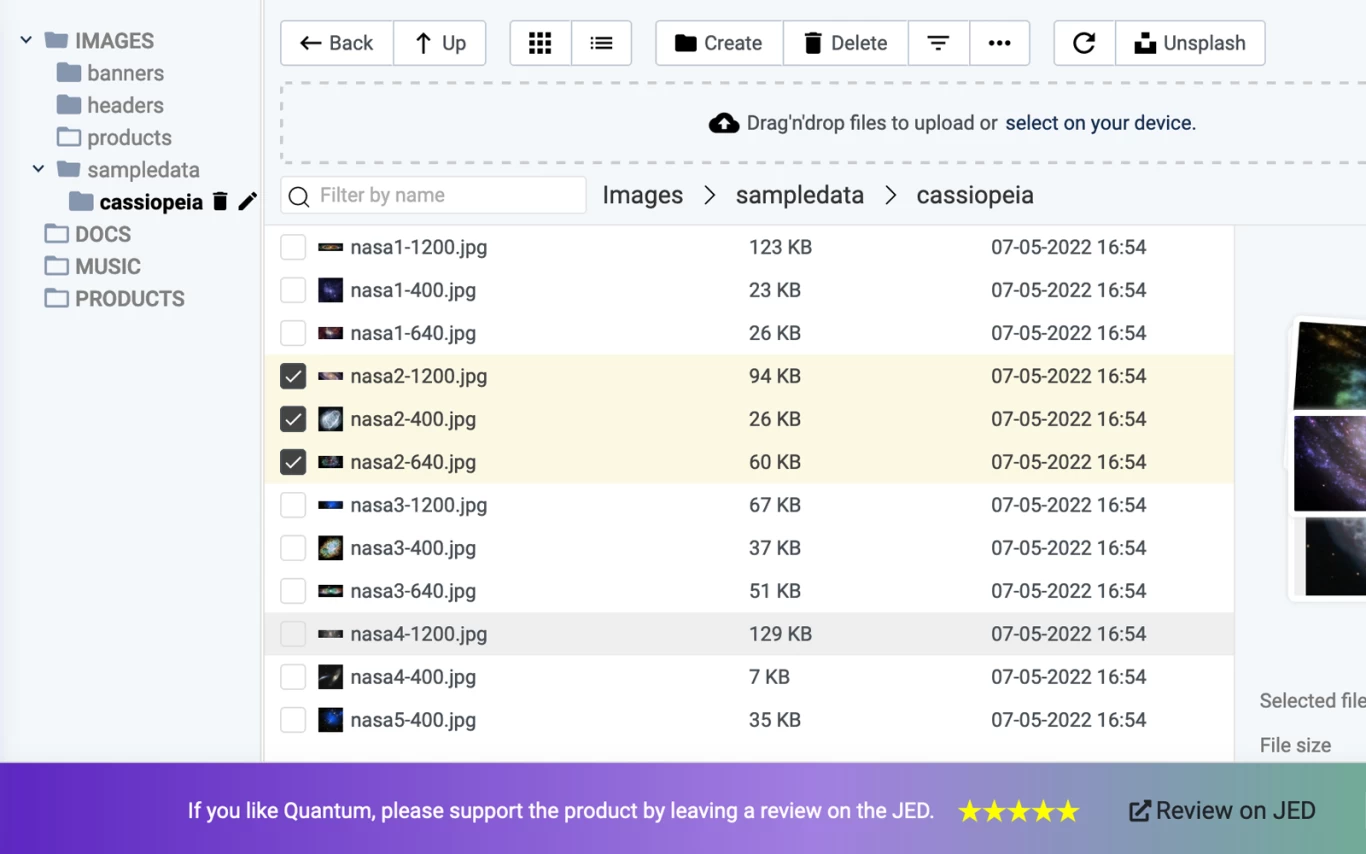
Отображение опции перетаскивания для пустой папки и сортировка в Медиа-менеджере
Возможность выбора макета в поле типа subform
Сортировка результатов умного поиска
Фильтрация пунктов меню по компоненту
Возможность указания атрибута showon для пользовательских полей (для админки)
Перестройка «дерева» после сохранения пункта меню
Счетчик символов для поля ввода
Установка Joomla через CLI
Поддержка avif, webp, heic и webp2 в поле списка изображений
Улучшенный ротуер для компонента тегов
Множественные улучшения в коде отображения элемента тега
На момент написания дайджеста на GitHub проекта уже доступна Joomla 5 alpha-3.
Когда выйдет стабильная версия Joomla 5?
Согласно roadmap проекта релиз Joomla 5 ожидается 17 октября 2023 года. Поддержка, исправление ошибок, в том числе безопасности Joomla 5 завершится 19 октября 2027 года.
Joomla 5: плагин обратной совместимости
Joomla 5 продолжает развитие Joomla 4 и, как уже неоднократно сообщалось ранее, обновление не будет являться болезненной миграцией.
Как известно, из кода Joomla постепенно исчезают устаревшие классы API. Многие из них «продержались» в ядре со времён Joomla 1.5. Отказ от них — это эволюция. Однако, удаление устаревших классов и методов будет вызывать ошибки в расширениях, которые разработчики вовремя не обновили.
Для обеспечения максимально гладкого перехода с Joomla 4 на Joomla 5 создан плагин обратной совместимости, который будет включён по умолчанию.
Это означает, что если Вы знаете, что Ваши расширения на сайте всё ещё используют устаревшие классы (например, JUri, JFactory, JInput, JHtml, JPlugin и т.д.), то при включённом плагине обратной совместимости этой ошибки возникать не должно. Если же Вы уверены, что расширения на Вашем сайте поддерживаются в актуальном состоянии и разработчик заявляет о совместимости с Joomla 5, то этот плагин можно выключить.
Разработчикам также следует помнить не только о самих классах, но и методах в них, часть из которых также может меняться со временем.
Плагин обратной совместимости уже появился в репозитории GitHub Joomla, включён в релиз Joomla 5.0.0-alpha3.
В августе 2022 года мы на канале Joomla-сообщества в Telegram писали о том, что на GitHub Joomla разгорелась дискуссия об эволюции Joomla, где среди прочих участники международного сообщества затрагивали и вопрос обратной совместимости. По итогу департамент Joomla, отвечающий за выпуск релизов, принял ряд решений, был опубликован скорректированный план выпуска релизов Joomla 4 и 5. Данный плагин (посмотреть на GitHub) также является одним из результатов упомянутого обсуждения.
Joomla-разработчикам: что будет с расширениями на Joomla 3 MVC в Joomla 5 и 6?
С 2012 года премия CMS Critic Awards отмечает выдающиеся достижения сообщества CMS, награждая разработчиков за их инновации и сервис. Каждый год мы определяем одного победителя в различных отраслевых категориях, таких как Best Cloud CMS, Best DXP, Best Headless CMS, и другие, и делимся результатами в средствах массовой информации.
В 2022 году Joomla стала:
Best Free CMS: Joomla!
Best Website Builder: YOOtheme
Joomla была номинирована в 6 категориях. Подобные рейтинги и награды оценивают технологичность, активность и консолидацию сообщества, складывающегося вокруг каждой CMS.
Joomla признана лучшей CMS в конкурсе 20i FOSS Awards
Мероприятие 20i FOSS Awards, организуемое хостинг компанией 20i, призвано помочь в популяризации программного обеспечения с открытым исходным кодом. В этом году определены победители конкурса, и Joomla снова признана лучшей CMS.
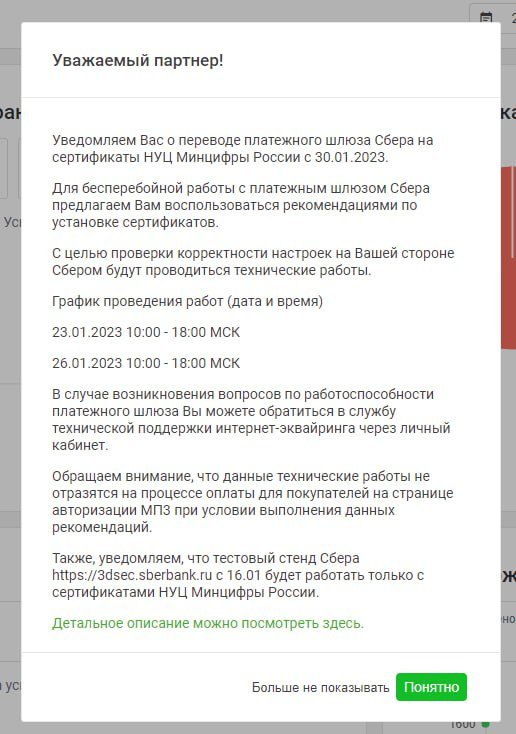
Интернет-магазины Joomla и эквайринг Сбербанка (НУЦ)
Многие, кто пользуется эквайрингом Сбербанка в интернет-магазинах видели сообщения о том, что Сбербанк переводит все свои сервисы на сертификаты НУЦ Минцифры России с 30.01.2023г. В связи с чем будут «отваливаться» оплаты на тех сайтах, где не установлены обновленные платежные плагины/аддоны.
Обратите внимание, что код плагинов скорее всего не будет работать на сайтах с Joomla 4, так как используются устаревшие для Joomla 4 методы.
Подробности для разработчиков. В частности, встречается метод JRequest::getVar, которого в Joomla 4 нет. Его стоит заменить на следующий код:
<?php // в самом начале файла use Joomla\CMS\Factory; // заменяем устаревший класс на актуальный Factory::getApplication()->getInput()->get('var_name'); // Например if (JRequest::getVar('method', '') != 'rbspayment') { return NULL; } // заменяем на if (Factory::getApplication()->getInput()->get('method') != 'rbspayment') { return NULL; }
JoomShopping
Вышел JoomShopping 5.1.3 и 5.2.0. В новых релизе продолжена работа над совместимостью с PHP 8, а также:
исправлен url перенаправления после активации пользователя.
исправлена ошибка скачивания файла для продажи.
добавлена настройка в истории заказа «включить комментарий».
Исправление ошибки, при которой отправлялось 2 письма при создании/обновлении статуса заказа.
Исправление ошибки mail function disabled.
Обновлён стиль звёздочек рейтинга товаров.
Добавлена поддержка разрешённых/запрещённых email-доменов Joomla.
Заполнение характеристик к товару при создании заказа админом.
Бесплатный плагин для автоматического регулярного обновления по расписанию цен и остатков товаров JoomShopping из CRM Битрикс 24. Предполагается, что Вы используете складской учёт Битрикс 24. Рекомендуется для работы с небольшим количеством товаров.
Что нового?
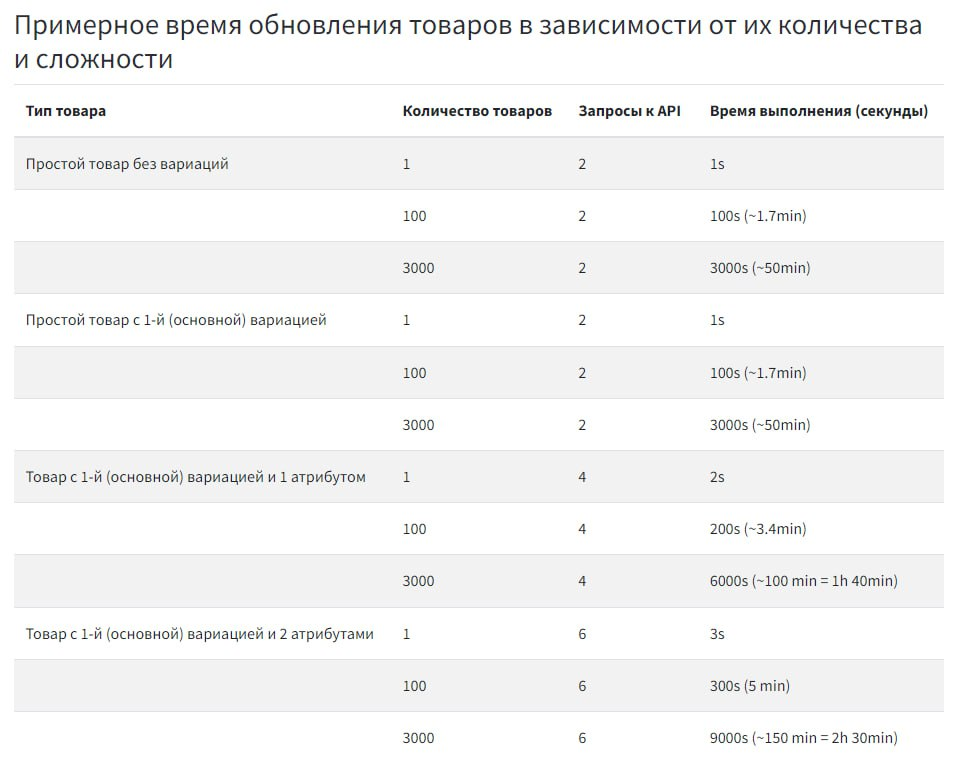
Битрикс24 предполагает лимит в 2 запроса в секунду при обращении к API. Если лимит превышен — запрос не выполняется, API возвращает ошибку о превышении лимита. В итоге часть товаров не получала обновленное значение цен и количества. Теперь скрипт «спит» 0,5 секунды после каждого выполненного запроса. Для обновления цены и количества требуется 2 запроса. Для каждого атрибута также требуется 2 запроса к API. Соответственно, обновление данных товара занимает теперь минимум 1 секунду, а также ещё по 1 секунде на каждый атрибут.
На картинке табличка, где посчитано примерное время выполнения обновления цен и остатков в зависимости от количества и сложности товаров.
Бесплатный плагин вставки модулей Joomla в позиции шаблона JoomShopping. Поддерживаются как позиции стандартного шаблона, так и возможность использовать свои позиции (если Вы разработчик шаблона).
Что нового? Добавлена возможность отображать позиции модулей Joomla:
в корзине,
на всех шагах оформления заказа:
заполнение адреса,
выбор способов оплаты,
выбор способов доставки,
предпросмотр заказа,
завершение заказа.
Плагин пока ещё поддерживает Joomla 3, но в ближайших версиях её поддержка будет убрана.
Минимальная версия Joomla — 4.2. Минимальная версия JoomSopping — 5.1. Расширения предоставляются на платной основе. После приобретения расширения, установка производится через установщик Nevigen, который Вы сможете скачать в вашем кабинете и установить на Ваш сайт. После установки инсталлятора, вам необходимо будет ввести лицензионный ключ, который Вы также можете найти в своем личном кабинете. Лицензионный ключ обеспечит доступ к обновлениям и поддержке.
WT JoomShopping Favorite v.2.0.0
Функционал избранных товаров, реализован с помощью cookie. В стандартной комплектации список желаний JoomShopping отображается только в карточке товара. В списке товаров нет. При использовании различных хаков для добавления кнопки списка пожеланий в вид категории товаров кнопка перенаправляет в карточку товара, в случае если у товара есть зависимые атрибуты (влияют на цену).
WT JoomShopping Favorites — это альтернативный список пожеланий (избранные товары) для JoomShopping, который решает эти проблемы.
Что нового?
Рефакторинг кода. Пакет расширений переписан согласно новым канонам Joomla 4. Это означает, что расширения должны без проблем работать на Joomla 5 и в дальнейшем на Joomla 6 (ожидается в 2025 году).
Отказ от jQuery. Javascript код теперь не требует использования библиотеки jQuery.
Совместимость PHP 8.1. Протестирована работоспособность расширений на PHP 8.1. Исправлены все замеченные ошибки, предупреждения и уведомления.
Начиная с версии 1.3.0 поддерживается только Joomla 4+.
Версия 2.0.1 — исправление отображения дублей товаров в случае, если товар находился в нескольких категориях. Модуль отображал дубли просмотренных товаров сообразно количеству назначенных ему категорий. Исправлено.
Пакет, состоящий из двух плагинов: контент-плагина и плагина кнопки редактора, позволяющие быстро и удобно вставлять товары JoomShopping в материалы, модули и везде, где работают контент-плагины. Макет default — это просто ссылка на товар. Если Вы измените категорию товара (например), то ссылки исправятся автоматически.
Контент-плагин поддерживает макеты вывода. Это значит, что Вы можете создать свой собственный макет вывода и представить более полную информацию о вставленном товаре: изображение, краткое описание, цену, количество просмотров, рейтинг, количество товара и т.д. Подробнее смотрите в файле plugins/content/wtjshoppingproductsanywhere/tmpl/default.php.
Чтобы создать свой макет вывода плагина — скопируйте файл default.php и переименуйте его. Внутри файла поместите Вашу HTML-вёрстку. Выбор макета появится во всплывающем окне выбора товара при редактировании материала.
v.2.0.0 Что нового?
Плагины переписаны с учётом структуры расширений Joomla 4.
Рефакторинг кода, переписан как JavaScript, так и PHP код.
Исправлена ошибка обработки нескольких шорткодов в тексте, из-за чего обрабатывалась лишь часть шорткодов.
Для Joomla 3 выпущена версия 1.1.0, включающая в себя исправление ошибки обработки шорткодов. Дальнейшая разработка плагина будет вестись только под Joomla 4.
Важно! Минимальная версия Joomla 4 — 4.3.0. Это связано с использованием namespaces для плагинов группы editors-xtd. В текущем виде комплект плагинов должен без проблем работать на всей линейке Joomla 4, а так же Joomla 5+.
Пакет, состоящий из модуля и плагина. Плагин записывает в cookie просмотренные посетителем товары, а модуль отображает их. В плагине настраивается время жизни cookie — сколько дней хранить в браузере пользователя информацию о просмотренных товарах.
Это бесплатный аналог аддона «Addon last visited products» от MAXXmarketing GmbH (разработчиков JoomShopping).
Что нового?
Пакет расширений адаптирован к новой файловой структуре Joomla 4. Это означает, что он будет работать и на Joomla 5.
Один из старейших компонентов для создания интернет-магазина 3 мая 2023г. получил новую версию. Заявлена совместимость с Joomla 4.3, PHP8.2 и MySQL 8. Исправлен ряд ошибок, связанных с постепенной адаптацией компонента к Joomla 4.
Недавно Virtuemart ввёл новую модель спонсирования проекта: для того, чтобы получить новую версию сразу после релиза нужно приобрести подписку. Так, сейчас бесплатно скачать можно версии до 4.0.12 включительно для Joomla 4 и 4.0.20 для Joomla 3.x. Однако, 4.0.20 для Joomla 4 доступна только владельцам подписки. Версия 4.0.12 вышла в декабре 2022 года.
Как сообщается на странице покупки подписки, member version не отличается от обычной версии. Это больше похоже на версию с ранним доступом, содержащую исправления ошибок, о которых сообщают пользователи, а также новые функции, оплачиваемые участниками. Любые изменения в файлах ядра рано или поздно используются и в стандартной версии, но пользователи без подписки будут получать их, видимо, с ощутимой задержкой.
Guru — известный компонент для продажи доступа к видео-курсам для Joomla.
WT Guru YooKassa платёжный плагин для компонента продажи видео-курсов
Сервис Юкасса (YooKassa) позволяет принимать платежи для юридических лиц, ИП и самозанятых. Данный бесплатный плагин добавляет возможность принимать оплату с помощью Юкасса за ваши видеокурсы.
Минимальная версия Joomla — 4. Плагин написан с учетом новой структуры Joomla 4 и будет работать и в Joomla 5.
Для работы плагина требуется PHP библиотека WT YooKassa library (о ней сказано в разделе Новости расширений дайджеста). Это официальная PHP-библиотека Юкасса для разработчиков, «обёрнутая» в расширение Joomla. Она автоматически устанавливается при установке плагина платёжного метода.
Вышла новая версия компонента Phoca Cart для создания Интернет-магазинов. Новая версия идет с рядом интересных функций.
Изюминкой релиза является добавление задач ИИ для товаров. Теперь можно применять искусственный интеллект для создания описаний товаров, длинных описаний, функций и мета-описаний. Эта фича обещает сэкономить время владельцев магазинов и сделать процесс создания описаний товаров более эффективным.
В Phoca Cart также добавлены новые переопределения шаблонов, в том числе внешний макет для поиска, списка пожеланий, сравнения, корзины и валютных модулей. Новые переопределения шаблонов предоставляют владельцам магазинов больше возможностей для настройки и позволяют более гибко кастомизировать внешний вид макетов.
Компонент имеет также множество других улучшений. Подробнее см. в анонсе.
No Boss Testimonials — компонент отзывов для Joomla 4
Компонент отзывов для Joomla 3 и Joomla 4. Нынче принято оставлять отзывы о компаниях на крупных сторонних сервисах, которые 1) берут на себя всю работу по модерации отзывов, 2) защите от спама, 3) де-юре являются независимыми и не заинтересованными лицами, а значит не будут публиковать только положительные или только отрицательные отзывы о компании. Но, несмотря на это нередко собственную форму для сбора отзывов и модули для их вывода требуют заказчики.
Данный компонент имеет 4 редакции, из которых младшая — бесплатная. В ней присутствует 4 макета вывода и отсутствуют:
форма отправки отзыва для пользователей сайта;
модерация отзывов;
функция вставки изображений/видео в отзывы с фронтенда. Для справки: стоимость платных версий от $17 до $24. Страница расширения на JED.
За это время вышло 6 релизов модуля (1.4.4 — 2.1.1). Модуль позволяет создавать наборы повторяемых сущностей на сайте, которые могут быть ссылками, картинками, текстом. табами, списком FAQ, слайдшоу и т.д. Есть условия для исключений показа элементов списка. Вы можете создавать собственные макеты вывода модуля, создавая таким образом почти всё, что угодно: от простого списка ссылок до стены фотографий на главную страницу или ссылки-теги для перелинковки категорий интернет-магазина. Модуль позволяет выводить изображения, адаптивные изображения, видео, адаптивные видео.
Скриншот параметром сущности модуля
Что нового?
Новый параметр «Использовать ссылку». Он позволяет включать или отключать настройки ссылки для элемента. Этот флаг можно использовать в Ваших макетах, создавая списки сущностей, где в одном списке чередуются кликабельные и не кликабельные элементы. Например, вывод простого списка, где часть элементов — простой текст, а часть является ссылкой. Или же макет простого слайдшоу, где первые элементы картинки, а последний — картинка-ссылка «смотреть все».
Новый тип ссылки — материал Joomla.Подходит для небольших каталогов услуг, реализованных на переопределениях материалов Joomla, сайтов-визиток и т.д.
Новый тип ссылки — файл. В список сущностей можно добавлять ссылки на файлы, выбирая их с помощью Медиа Менеджера Joomla. Добавить можно ссылки на изображения, аудио, видео или документы. Разрешенные типы файлов определяются общими настройками Joomla.
Мультиязычные сайты. Указание полного пути к poster и video файлу в макете bg-video. На мультиязычных сайтах для неосновных языков пути к файлам указывались с ошибками. Исправлено.
Модуль переписан по структуре Joomla 4. Минимальная версия Joomla 4.2. Это означает, что он будет работать и на Joomla 5.
Файловый менеджер Quantum Manager
Вышел релиз Quantum Manager 2.0.1. Это — maintenance релиз, который содержит важные фиксы и делает работу компонента более стабильной на PHP 8.1.
Искусственный интеллект ChatGPT в Joomla 4
Для Joomla появилось сразу несколько расширений, позволяющих внедрить ChatGPT в интерфейс CMS.
Плагин кнопки редактора ChatGPT
Бесплатный плагин, добавляющий кнопку вызова чата с GPT при редактировании контента.
Одна из самых известных и популярных видео-галерей для Joomla получила версию для Joomla 4. У компонента есть бесплатная и платная версии. Бесплатная позволяет создавать видео-галерею из файлов, загруженных на свой хостинг, создавать структуру категорий, загружать видео с фронт сайта, комментарии, вставлять код видео, имеет контент-плагин и т.д. Платная версия позволяет вставлять видео с Vimeo и Youtube, live stream потоки (HLS) , проигрывать вашу рекламу перед видео, вставлять плейлисты, отображать видео в слайдерах и модальных окнах.
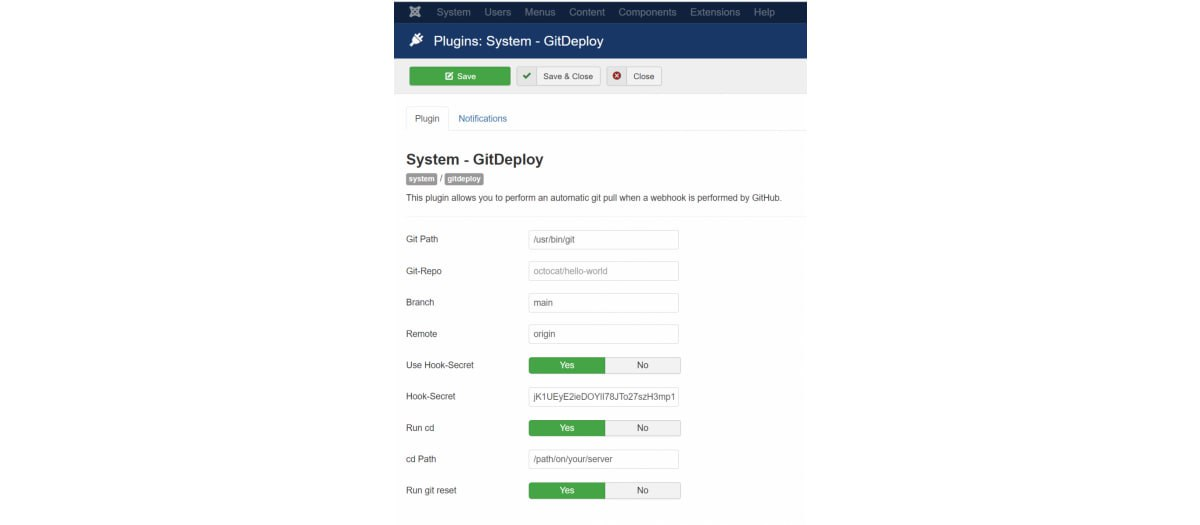
Плагин позволяет «слушать» вебхуки из GitHub и «накатывать» изменения в Joomla прямо из репозитория. При изменении файлов GitHub отправляет вам вебхук, плагин выполняет git pull, а также отправляет вам уведомление. Уведомления можно отправлять в:
Telegram
Glip
Slack
Mattermost
на e-mail
Плагин нужен больше для проектов, над которым работают одновременно несколько разработчиков и используют контроль версий.
Плагин кнопки редактора для вставки шорт-кодов, созданных с помощью плагина Revars. С помощью плагина Revars в Joomla можно создавать шорткоды-переменные (и не только), которые плагин может заменять по всему сайту. Это могут быть контактные данные (телефон, почта, адрес), js-скрипт карты для сайта, ИНН, название бренда и т.д. Для того, чтобы было удобно вставлять эти переменные в поле редактора создан этот плагин — плагин кнопки редактора.
Quick Menu — модуль панели администратора для Joomla 4
Демо модуля
После установки создайте и настройте модуль в менеджере модулей для панели администратора. Модуль выводит 2 столбца меню, один для задач контент-менеджмента, второй — для быстрого доступа к задачам администрирования сайта. Поддерживает настройки прав доступа Joomla (ACL). Только для Joomla 4.
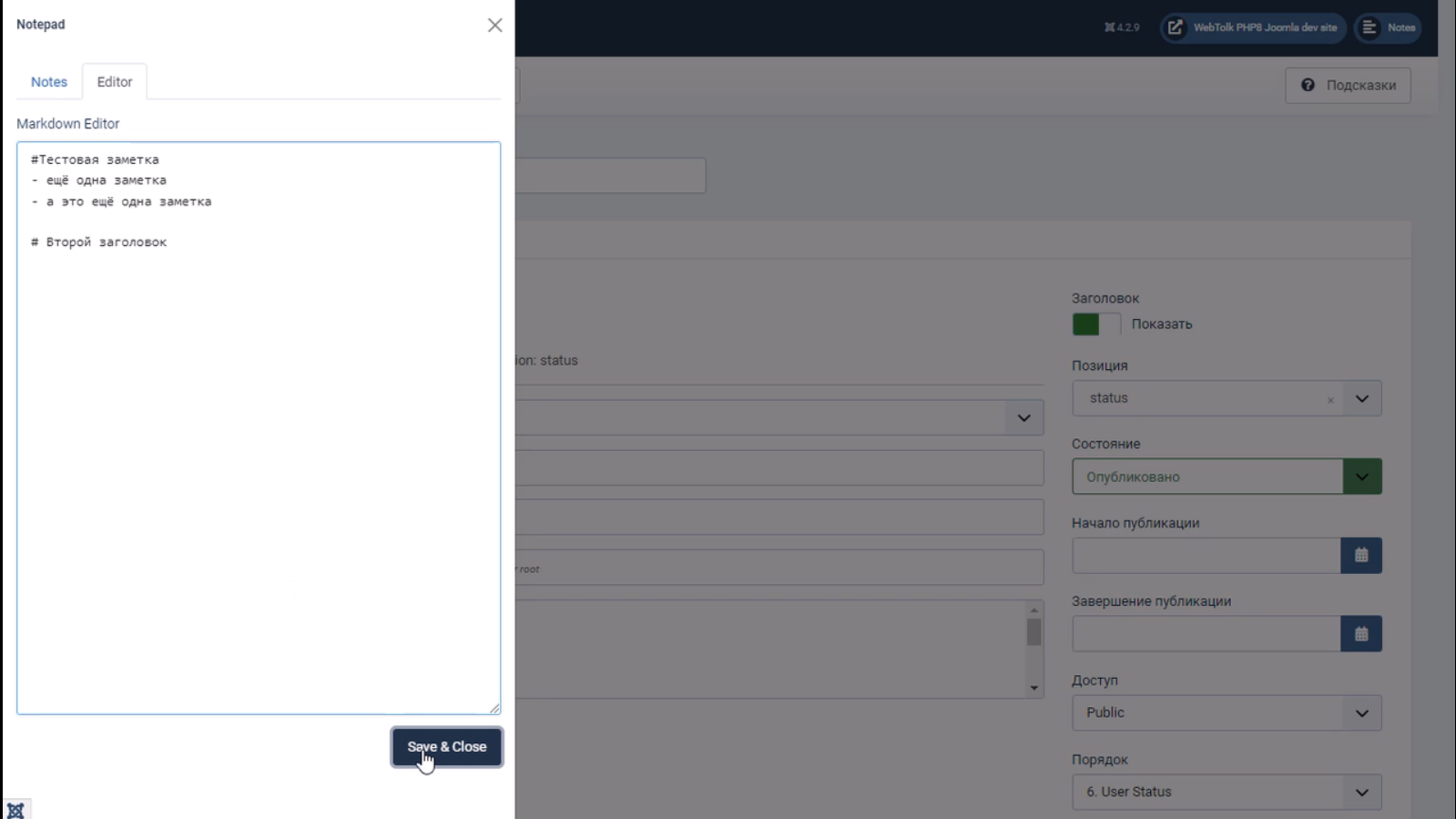
Модуль позволяет добавлять заметки в панели администратора и хранить их в текстовом файле. Заметка и поле редактора отображается в offcanvas. Для вывода кнопки быстрого доступа к заметкам модуль нужно опубликовать в позиции status. Редактор поддерживает markdown синтаксис. Файл заметок можно затем скачать.
Обратите внимание, что при сохранении страница обновляется. Убедитесь, что Ваши изменения на странице сохранены.
Joomla 4 представила концепцию плагинов-адаптеров для Media Manager, которые позволяют вам указывать хранилище для ваших медиафайлов за пределами папки images на вашем сайте.
Сама Joomla поставляется с одним адаптером под названием «Файловая система — Локальный каталог». Он реализует стандартное хранилище медиафайлов в файловой системе вашего сервера. По умолчанию он разрешает доступ только к папке images, но при необходимости его можно настроить для поддержки большего количества папок в корневом каталоге вашего сайта.
Преимущество плагинов-адаптеров для Media Manager в Joomla 4 заключается в том, что такой подход позволяет сторонним разработчикам, создавать дополнительные плагины-адаптеры для служб облачного хранения файлов.
Плагины файловой системы от Digital Peak — DP Media
Ранее на канале также сообщалось о комплекте плагинов файловой системы Joomla 4 от Digital Peak — DP Media (которые, кстати, тоже недавно обновились — в январе 2023). В комплект входит 12 плагинов, часть из которых — плагины файловой системы:
Amazon filesystem — по подписке.
Dropbox filesystem — по подписке.
Plugin Flickr — по подписке.
FTP filesystem — бесплатно. Позволяет подключать в Медиа менеджер удаленные FTP.
Google Drive filesystem — по подписке.
Joomla filesystem — по подписке. Позволяет подключать к файловой системе сайта другой сайт на Joomla 4.
Microsoft OneDrive filesystem — по подписке.
Permissions filesystem — бесплатно. Позволяет настроить доступ к папкам для различных групп юзеров.
Pexels filesystem — бесплатно.
Pixabay filesystem — бесплатно.
Smugmug filesystem — по подписке.
Unsplash filesystem — по подписке.
WebDAV filesystem — по подписке.
SW JProjects v.1.6.2 — обновление менеджера цифровых проектов для Joomla разработчиков
Компонент позволяет разработчикам сайтов на Joomla вести свой собственный сервер обновлений для своих расширений (шаблонов, модулей, плагинов etc), что позволяет доносить обновления сразу всем своим (и не только своим) клиентам.
Что нового?
Контрольная сумма файла в XML сервера обновлений. Добавлены контрольные суммы файла sha 256, sha348 и sha512 в xml-манифеста сервера обновлений. При обновлении расширения в Joomla 4 показывалось предупреждение о том, что не найдена контрольная сумма в сервере обновлений. Исправлено.
Патчи PHP 8. В панели администратора и фронтенде исправлены уведомления PHP 8
Не показывается кнопка скачать, если нет версии. Если проект не имел ни одной опубликованной версии — показывалась кнопка «скачать», что вело на страницу 404. Исправлено.
Плагин для автоматической генерации лицензионных ключей в менеджере цифровых проектов SW Projects при продаже расширений Joomla с помощью интернет-магазина JoomShopping. Также плагин добавляет информацию о сроках действия ключа и ссылку на скачивание в заказ JoomShopping.
Плагин нужен для Joomla-разработчиков, которые оказывают платные услуги по поддержке и обновлению своих расширений.
Что нового?
Теперь плагин поддерживает только Joomla 4.
Исправлены ошибки генерации ключей после покупки.
Если покупка совершена зарегистрированным пользователем — при генерации ключа добавляется его user id.
WT Typograph — плагин для исправления типографики текста для Joomla 4
Современные интернет-издания немало внимания уделяют качественной подготовке своих текстов к web-изданию. В тексте должен соблюдаться определенный code style, принятый на данном конкретном ресурсе. Правила оформления текста могут быть разные:
знаки длинного тире, вместо «минуса» или «дефиса»,
французские кавычки (ёлочки) вместо английских (как запятые),
значения дат не должны переноситься на следующую строку,
нужно убрать все лишние повторяющиеся пробелы и так далее. Обычно, этой работой в интернет-издании занимается корректор, иногда редактор. Однако, выполнение многих правил оформления текста можно автоматизировать и этой задаче служат типографы.
Для кого этот плагин?
Данный плагин для Joomla 4 пригодится всем изданиям, следящим за качеством оформления текстов на своих страницах: информационные, контентные сайты, сайты-новостники. Плагин работает с бесплатным сервисом Типограф. Во время тестирования сервис легко обрабатывал объёмы текста ~ 30 000 знаков. Как сам сервис, так и плагин — бесплатные.
Joomla! Downloader — скрипт загрузки Joomla прямо на сервер
PHP-скрипт для автоматической загрузки последней версии Joomla! непосредственно сервер на сервер без необходимости загружать его локально. Скрипт также извлекает ZIP-файл непосредственно на вашем сервере после его загрузки.
ProofReader — компонент отправки опечаток читателями администрации сайта
Расширение для Joomla позволяет посетителям сайта сообщать администратору об опечатках на сайте. Посетитель может выделить текст мышью и нажать комбинацию клавиш Ctrl+Enter, чтобы отправить сообщение администратору сайта. После этого отображается всплывающее окно, и пользователь может написать комментарий об опечатке. Отчет об опечатке будет доступен в панели администратора, а администратору будет отправлено уведомление по электронной почте.
Особенности:
Отчеты отправляются без перезагрузки текущей веб-страницы.
Отправляет уведомления по электронной почте администратору.
Поддерживает защиту от спама с помощью CAPTCHA Joomla.
Пользователь может оставить комментарий о найденной опечатке.
Вышла новая версия конструктора контента и веб-приложений Seblod. Заявлена поддержка PHP 8.0-8.2. Для обновления можно использовать стандартные аддоны экспорта-импорта или updater addon.
Seblod даёт широкие возможности для кастомизации Joomla как внутри, так и снаружи. Предоставляет функционал конструктора приложений и CCK, внедряет в Joomla типы контента и многое другое.
miniOrange Joomla SAML Single Sign-On (SSO) – SAML SSO аутентификация для Joomla 4
Технология единого входа (SSO) используется для объединения разных сайтов/порталов/web-приложений так, чтобы можно было использовать единую учетную запись везде, без повторной аутентификации. Пример — сервисы Яндекса, Гугла, Мейл.ру (ВК) и т.д. Это избавляет пользователя от необходимости входить в каждое приложение отдельно. Данное расширение также позволяет управлять входом в систему и обеспечивать SSO с помощью 48 провайдеров IdP, включая Windows sso, Worpress, Azure, Onelogin, Oracle, RSA Secure ID, Office 365, CA Identity, IBM, Magento, VMware и других. Или же с помощью любого провайдера IDP, совместимого с SAML.
Плагин miniOrange Joomla Single Sign on (SAML SSO) — это поставщик услуг SAML 2.0, который можно настроить для установления доверия между сайтом Joomla и поставщиком удостоверений, совместимым с SAML 2.0, для безопасной аутентификации пользователей на сайтах Joomla. Это позволяет вашим пользователям безопасно входить на сайт Joomla.
Плагин имеет бесплатную и платную версии. Уточните доступный функционал на странице расширения. Скачивание файла расширения идёт с серверов Amazone.
Плагин позволяет пользователям входить в ваши клиентские приложения, используя свои учетные данные учетной записи Joomla. Это позволяет вам использовать Joomla в качестве сервера / провайдера OAuth и предоставлять OAuth API для доступа к ресурсам. Основная цель этого плагина OAuth server / OAuth Provider — позволить пользователям выполнять единый вход (SSO), используя свои учетные данные Joomla, в различные приложения, поддерживающие протокол OAuth / OAuth 2.0.
Особенности:
Позволяет использовать Joomla в качестве вашего OAuth-сервера и получать доступ к OAuth API.
Поддержка нескольких OAuth-клиентов.
Поддержка всех типов grant — Authorization, Implicit, Client credential, Resource, Refresh token.
Включает все характеристики сервера OAuth2.0, в том числе интегрированный OpenID connect, встроенный сервер ресурсов, возможность создавать учетные данные клиента и привязывать их к определенному пользователю с помощью паролей приложений и так далее.
Поддержка JWT.
Поддержка веб-токенов OAuth 2.0 JSON.
Поддержка PKCE OAuth 2.0.
Маппинг атрибутов и ролей позволяет скрыть имена атрибутов, используемых для хранения данных в Joomla. Атрибут и роли могут быть просто сопоставлены и отправлены в качестве ответа. Также доступны и другие параметры.
Расширение бесплатное, поддерживает Joomla 3 и Joomla 4.
Плагин интеграции сервиса Sentry в Joomla 3 и Joomla 4. Sentry — сервис багтрекинга, позволяет оперативно выявлять ошибки сайтов, сервисов как в javascript, так и в PHP в режиме реального времени. Сервис необходим для проектов, где присутствуют интеграции со сторонними сервисами и могут вдруг не обновиться токены авторизации или ошибки в js крушат все формы для сбора заявок. С помощью Sentry возможно быстро узнать о проблеме и соответственно быстро её исправить.
На момент написания заметки сервис имеет бесплатный тариф «Developer», подробности на странице сервиса.
WT SEO Meta templates v.2.0.0 — плагин СЕО-шаблонов для Joomla
Обновление пакета плагинов для работы с СЕО-шаблонами в тегах <title> и meta-description. Плагин позволяет использовать формулы (шаблоны, маски) для тега title и meta-тега description, принимая данные (в том числе и сео-формулы) из дополнительных плагинов-провайдеров. Также обрабатываются страницы пагинации.
Список доступных плагинов-провайдеров:
Virtuemart
JoomShopping
My City Selector
Материалы и категории Joomla
Phoca Gallery
[NEW] Теги Joomla Некоторые плагины-провайдеры поддерживают работу с мультиязычностью, позволяют указывать разные СЕО формулы для разных категорий и т.д.
Что нового?
Добавлен плагин-провайдер для тегов Joomla. Он работает в списке тегов и в списке сущностей (материалов, контактов, данных из сторонних компонентов) по тегам. Также плагин работает на страницах пагинации. Добавляет СЕО-суффиксы вида «- стр. NNN» для уникализации страниц пагинации.
Плагины контента. Содержимое переменных вступительного текста обрабатывается предварительно плагинами контента.
Joomla 4 only. С версии 2.0.0 плагин поддерживает только Joomla 4.
Отладочная информация. Показ отладки для плагинов-провайдеров включается теперь в основном плагине. Пока что верно для плагинов v.2.0.0 и выше.
Рефакторинг. Обновлены до структуры Joomla 4 основной плагин и провайдер для материалов. Провайдер для тегов создан сразу по новой структуре. Это означает, что плагины будут работать и в Joomla 5+.
JBZoo — это надстройка над некогда популярном CCK Joomla Zoo, который позволял реализовать магазин на данном компоненте. Изначально надстройка была коммерческой, после того, как автор (Денис Сметанников) прекратил поддержку, он стал бесплатным.
Где-то раз в год мы пишем, что-то о JBZoo. На мой взгляд — это весьма самобытное явление в Joomla, дело в том, что коммерческие компоненты редко живут так долго, после того, как авторы от них отказываются. JBZoo развивается уже много лет силами сообщества.
Данное видео демонстрирует работу JBZoo на Joomla 4. И как говорят в сообществе, в скором времени они опубликуют публичную версию.
Это компонент, внедряющий всем известный искусственный интеллект ChatGPT в Joomla 3 и Joomla 4. Чат доступен как в бэкенде, так и во фронтенде в виде небольшой плавающей иконки, по нажатию на которую открывается интерфейс чата.
Возможности
На основе чата можно:
Получить план для новой статьи. Напишите описание продукта , предоставив только вводную информацию.
Получить текст новой статьи за считанные секунды с заголовком и мета-описанием. Сохраните этот текст как новую статью Joomla в выбранной Вами категории в один клик.
Переведите существующую статью на другой язык. Сохраните ее как новую статью, автоматически связанную с исходной. В один клик, с одного экрана с сохранением всего форматирования.
Напишите пост для Facebook или несколько рекомендуемых твитов для вашего сообщения в блоге или продукта. Делиться постами в соц.сетях можно прямо из интерфейса компонента.
Соберите ключевые слова, получите LSI или хэштеги, чтобы улучшить SEO Вашего проекта.
Или просто общайтесь напрямую с ИИ и копируйте/вставляйте вопросы, ответы или всю дискуссию одним щелчком мыши. ==== Хотя на данный момент практической альтернативы OpenAI API нет, компонент 4AI был разработан для поддержки других провайдеров AI API в будущем. ====== Обратите внимание, что вам НЕ нужен платный план ChatGPT для использования 4AI (но вам нужно будет платить за использование API). ===== Компонент поддерживает Joomla 3 и Joomla 4. Существует 3 версии:
2 платных ($69 / 1 год, 3 сайта и $179 / год, 200 сайтов)
4AI Community edition — бесплатный, без ограничений по количеству установок, но с ограничениями по функционалу.
Компонент всплывающих окон EngageBox 6: бесплатная версия
В майской рассылке греческого Joomla-разработчика Tassos Marinos сообщается о том, что его известный компонент EngageBox для создания всплывающих окон получил бесплатную, но ограниченную по функционалу версию.
Обновление официальной PHP библиотеки платёжного сервиса YooKassa (Юкасса), «обёрнутой» в пакет для использования в Joomla 4. Обновленная версия SDK. Поддержка PHP 8+.
Что нового?
Отказ от поддержки PHP меньше 8.
Изменена структура файлов.
Переработана логика работы с моделями.
Добавлено использование валидатора данных в моделях.
Массивы объектов заменены на объекты-коллекции При установке библиотеки производится проверка на минимальную версию PHP. Данная библиотека нужна в первую очередь для Joomla-разработчиков для использования в своих расширениях: платёжных плагинах, модулях, интеграциях и т.д., а также устанавливается в качестве необходимой зависимости для работы этих самых расширений.
Плагин пользовательского поля Radical Multi Field v.3.1.0
Долгожданное обновление плагина пользовательского поля Radical Multifield. Плагин получил совместимость с Joomla 4. Мультиполе в купе с возможностью создания пользовательских макетов вывода позволяет создавать повторяемые наборы сущностей там, где работают поля Joomla. Это может быть аудио-плеер, галерея изображений, видео, таблицы, прайс-лист и т.д.
Также мультиполе имеет интеграцию с файловым менеджером Quantum. Это позволяет использовать drag-n-drop загрузку, например, изображений прямо в материалах (контактах и т.д.), а также делать последующий ресайз изображений автоматически.
Что необычно: в Joomla-сообществе был объявлен сбор средств на выпуск обновления расширения и общими усилиями необходимая сумма была набрана.
WT Articles anywhere with fields v.2.0.0 — плагин вставки материалов с собственными макетами вывода
Контент-плагин Joomla, позволяющий вставлять информацию из материалов и пользовательских полей материала в любом месте, где работают контент-плагины с помощью шорт-кода вида {wt_article_wf article_id=XXXX tmpl=XXXX}. Для плагина возможно (и даже необходимо) создавать свои макеты вывода, которые Вы указываете в шорт-коде.
Что нового?
Структура плагина обновлена, с учётом требований Joomla 4. Это означает, что плагин будет работать и на Joomla 5.
Добавлен плагин кнопки редактора для более удобной вставки материалов и выбора макетов.
Добавлен новый макет вывода link, который представляет собой ссылку на материал с его названием. Если Вы измените название материала — оно автоматически изменится.
Минимальная версия — Joomla 4.3. Это связано с использованием namespaces для плагинов группы editors-xtd.
Статья «Как создать плагин для Joomla 4 для авторизации пользователя по email» (How to Create a Joomla 4 Plugin to Allow User Login with Email)
По умолчанию Joomla нужен логин для того, чтоб авторизовать пользователя. Однако, можно позволить ему (пользователю) авторизовываться с помощью e-mail и пароля. Для этого потребуется создать несложный плагин. В статье приводится пример кода.
Youtube видео: Как найти переопределение какого именно файла сделать? (How to Find the File You Want to Make a Joomla Layout Override For)
На канале Basic Joomla Tutorials относительно недавно вышло видео, в котором рассказывается как можно быстро найти и сделать переопределение файла макета, если Вам нужно изменить внешний вид вывода расширения Joomla.
Подборка видео для разработчиков о Joomla 4
Robbie Jackson на своём канале выложил 9 (на момент написания дайджеста) видео о разработке Joomla 4, в которых описываются общие концепции и подходы, а так же демонстрируются примеры кода. Также даются рекомендации по апргейду расширения до Joomla 4.
Плейлист на Youtube с 3 (из 4) видео о создании шаблона для Joomla 4. Видео на английском языке. В описаниях под видео есть полезные ссылки на образцы кода, инструкции по настройке рабочего окружения.
Работа с размерами изображений с помощью класса Uri в Joomla 4
Парадокс, конечно, но это возможно. Казалось бы, причем тут класс ядра для работы со строками url. Но именно он может помочь нам в Joomla 4. Статья о том, как автоматически определять размеры файлов изображений для атрибутов width и height с помощью ядра Joomla 4 и не грузить сервер.
Joomla 4.3: обучающие туры и другие новшества. Видео от Joomla Center.
Главным нововведением Joomla 4.3 являются так называемые Обучающие туры (guided tours), которые наглядно и пошагово демонстрируют процессы администрирования в Joomla 4. Вызвать обучающий тур по определённой области CMS можно из строки заголовка на нужной странице админки.
Joomla 4.3 – что нового. Обзор Алексея Хорошвеского.
Guided Tours – обучающие туры в Joomla. Обзор Виталия Wedal.
В Joomla 4.3 появилось интересное нововведение — Guided Tours или Обучающие туры. По сути, Guided Tours – подсказчики. Они пошагово показывают, куда надо нажать или что заполнить, чтобы реализовать какую-то опцию на сайте. Туры состоят из шагов, с помощью которых вы постепенно выбираете и заполняете все нужные поля и в конце вас поздравят с успешным созданием чего-то.
Создание плагинов с учётом новой структуры Joomla 4.
С момента выхода Joomla 4 прошло уже почти 2 года, поэтому слово «новой» будем понимать в контексте сравнения с Joomla 3. В Joomla 4 «под капотом» произошло немало изменений. Кодовая база движка постепенно отбрасывает legacy (старый код), встретившись с которым мы могли бы как на машине времени вернуться в середину 2000-х или начало 2010-х 😀
В данной статье собран необходимый минимум для того, чтобы обновить старый плагин до структуры Joomla 4. Ну, или написать с нуля новый.
Создание плагина кнопки редактора в Joomla 4
Статья о том, как удобно расширить пользовательские возможности при редактировании или создании контента в Joomla. Если Вы, например, захотите сделать подсчет СЕО-характеристик текста или внедрить ИИ помощник прямо в интерфейс Joomla, то эта статья расскажет как Вашему разработчику это сделать.
Так же в статье в целом показывается распределение логики между frontend и backend в Joomla, работа с ajax нативными средствами CMS.
Теги (Tags) в Joomla 4: зачем нужны и как использовать?
Гайд по компоненту «Теги» (Tags) в Joomla 4 («Метки» в Joomla 3): возможности, настройки, редактирование, типы пунктов меню и модули для тегов на сайте Joomla. Хороший мануал от обучающего центра Joomla Center.
2-я часть перевода огромной статьи, посвящённой тонкостям безопасности сайтов на Joomla. Статья Joomla’s New HTTP Headers Plugin For J4 из майского номера (2022) Joomla Community Magazine.
Перенос материалов из компонента K2 в стандартный компонент материалов Joomla
K2 — в целом неплохой компонент (был). Некоторое время он давал гораздо больше возможностей для отображения контента, чем стандартный компонент материалов Joomla. Однако, время не стоит на месте, и сейчас стандартный компонент не уступает в возможностях компоненту K2. Разработчики Joomla потрудились на славу, чего не скажешь о разработчиках компонента K2. Мало того, что долгое время не обновлялся функционал компонента, так они не подготовили обновление для перехода на 4 версию Joomla. На момент написания этой статьи прошло почти два года с выпуска Joomla 4, а обновления компонента K2 для совместимости с новой версией так и нет. Возможно, на тот момент, когда вы будете читать эти строки разработчики K2 что-то выкатят, но сейчас нет.
Этот текст — перевод статьи из нового портала документации для разработчиков Joomla, раздел «Основные концепции». Ранее уже был опубликован перевод раздела, описывающего принципы Dependency Injection Containers в Joomla 4.
В тексте даны примеры PHP-кода по работе с Joomla 4 REST API. Примеры даны как с использованием API Joomla (HttpFactory), так и для non-Joomla сайтов — на чистом cURL.
Материалы Джумла 4. Создание, управление и вывод на сайте.
Учебные материалы о работе по наполнению сайта на Joomla 4 от Алексея Хорошевского. Видео урок и его расшифровка пригодится тем, кто только-только начинает знакомиться с чудным миром Joomla
Muta — шаблон для панели администратора Joomla 4 в тёмных тонах
Бесплатный шаблон тёмной темы для админки Joomla 4. В целом это стандартный шаблон Atum, но с некоторыми изменениями.
Модульность
С момента появления дочерних шаблонов в Joomla 4 и Cassiopeia, и Atum (шаблоны по умолчанию) не соответствуют механизмам переопределения основных частей шаблонов. Шаблон Muta предлагает следующую концепцию: вы никогда не переопределяете точки входа шаблона ( index.php, component.php, error.php и т. д.), вместо этого каждая из записей является просто оболочкой нескольких JLayouts, поэтому, если вам нужны собственные значки, вы просто переопределяете конкретный макет для этого. Макеты — это фавиконы, ассеты, логотипы. Здесь шаблон следует философии модульности Unix: делай что-то одно и делай это хорошо!
Цветовые схемы
Это в основном светлая/темная тема. Шаблон сохраняет состояние в файле cookie и передает его в HTML в качестве атрибута documentElement (data-bs-theme , вероятно, Joomla будет использовать data-theme для работы с фреймворками, отличными от Bootstrap). Фактически в Joomla нужно сохранить состояние шаблона в базе данных для конкретного пользователя, но, возможно, также сохранить и файл cookie.
Зачем?
Этот шаблон был создан для того, чтобы разработчики могли протестировать свои собственные расширения и выяснить, какие изменения необходимо применить к их html/css/js для поддержки prefers-color-scheme. В целом, применение правильной переменной CSS — это все, что нужно. Но это зависит от вашего фактического html/css/js. JavaScript tinyMCE — очень хороший пример того, как работать с приложениями, визуализированными на стороне клиента.
Вышла новая версия популярного конструктора страниц YOOtheme Pro 4
Новая версия выводит динамический контент на новый уровень с такими функциями, такими как родительские источники, динамическое мультипликация и вложенные источники нескольких элементов. Все элементы шаблона также доработаны, чтобы сделать ваши сайты совместимыми с WCAG.
Что еще интересного появилось?
Поддержка динамики во вложенных макетах, строках и колонках.
Значительно улучшена семантическая разметка, теперь можно использовать теги <address>, <article>, <footer>, <header>, <hgroup>, <nav>, <section> в настройках элементов.
Кастомайзер получил иконку для быстрой прокрутки к нужной области редактирования.
Макет страницы в редакторе теперь не отображает выключенные элементы.
Макет статьи получил иконку для доступа к редактированию полей и прочих атрибутов материала.
Добавлена возможность быстрой трансформации элемента из одного вида в другой, например из слайдшоу в слайдер панели.
Для картинок теперь можно задать точку фокуса, обрезка будет происходит так, чтобы сохранить видимым главный акцент, например не отрезать людям головы.
Добавлен Blur фильтр для опции параллакса.
Макет колонок строки расширен до 6 колонок, раньше было доступно только 5 колонок.
Добавлена возможность использования отдельного SVG для Favicon.
В настройках темы теперь можно изменить степень сжатия для картинок по умолчанию.
Добавлена ленивая загрузка для видео с YouTube и Vimeo.
Добавлена поддержка YouTube Shorts.
Добавлена возможность ручной сортировки фильтра в элементах Grid и Gallery.
Новый релиз одного из самых популярных конструкторов страниц для Jooma.
Что нового?
переработанный редактор в админке, улучшения интерфейса;
улучшенный редактор с фронта;
улучшенный интерфейс боковой панели для более легкого доступа к аддонам, разделам и настройкам страницы;
внедрение библиотеки цветов;
переработаны функции «Цвет», «Типографика» и «Тень блока»;
функция копирования и вставки для аддонов с опциями «Вставить выше» и «Вставить ниже»;
функция сортировки в макетах при поиске;
Font Book, функция, позволяющая устанавливать свои шрифты и шрифты Google;
новый медиа-менеджер в админке;
сортировка сохраненных аддонов и разделов;
добавление или удаление аддонов в избранное;
добавлена поддержка переменных CSS в палитре цветов;
редактирование материалов Joomla прямо из редактора билдера;
возможность отката изменений для серии SP Page Builder 3.x для улучшения обратной совместимости и упрощения миграции с предыдущих версий;
обнаружены устаревшие структуры аддонов, добавлены уведомления, предлагающие пользователям обновиться до актуальной структуры аддонов.
Разное
Чат Joomla-сообщества в Mattermost
Международный чат Joomla-сообщества, в котором собрались представители из Европы и Азии. Среди них многие имена мы видим среди разработчиков ядра Joomla, членов департаментов Joomla, в качестве авторов статей в Joomla Community Magazine.
Для того, чтобы присоединиться, нужно иметь аккаунт на https://identity.joomla.org/ — центр идентификации Joomla. Вход в мессенджер происходит с помощью этого портала.
Mattermost — это мессенджер с открытым исходным кодом от команды GitLab
Сообщите об ошибках и недочетах официального сайта Joomla!
Вы можете помочь сделать официальный сайт проекта Joomla! лучше, сообщив о найденных багах, ошибках на GitHub. В списке указано 29 проектов. Оставьте issue на гитхабе, опишите возникающую проблему и помогите стать официальному сайту Joomla лучше.
JoomlaDay USA. Бесплатный повтор части выступлений.
В конце апреля 2023 в США состоялся JoomlaDay USA. Участники сообщества решили сделать повтор некоторых выступлений бесплатно в формате Zoom-стрима, о чём объявляли в чате Joomla-сообщества в Mattermost.
Joomla Day France 2023
Во Франции 16 и 17 июня 2023 года проходил Joomla Day France — конференция о Joomla для новичков и профессионалов. Такие конференции проходят по всему миру. Недавно проходили Joomla Day в США, Германии и Нидерландах.
Краткая программа мероприятий:
Смотрите в будущее с Joomla! 4 и 5 (Бенджамин Тренкл) — обзорный доклад.
4AI — ChatGPT в Joomla! (Янник Готье) — об использовании Open AI ChatGPT прямо в интерфейсе Joomla. Недавно в нашем канале JoomlaFeed был пост на эту тему — Сотрудничайте, чтобы добиться успеха: создание сайта Joomla в сотрудничестве с digital-агентствами (Жан-Шарль Антуан и Жиль Средники). Докладчики делятся опытом и практиками построения партнёрских отношений.
Balbooa / Gridbox — универсальный PageBuilder для электронной коммерции (Сирил Пуссен). Обзор Balbooa GridBox от создателя этого пейджбилдера.
Процессы (Workflows) (Бенджамин Тренкл). Обзор функционала workflows на примере материалов Joomla.
Возможности хостинг-панелей для администратора Joomla (Серж Биллон). В выступлении раскрываются секреты и особенности работы с популярными панелями сервера: cPanel, Plesk, OVH Manager и другими.
Создайте новый Netflix: управляйте базой данных фильмов в Flexicontent (Янник Бержес).
Эксперименты с веб-сервисами Joomla (REST API) (Марк Дешевр). Обзорный доклад о Joomla 4 REST API. Приводятся примеры обмена данными между Joomla 4 сайтами, импорта-экспорта материалов и т.д.
Yootheme 4 (Элисия Фолтен). Обзор шаблона и пейджбилдера.
Мастерская взаимопомощи: вопросы, ответы, обмен опытом, живое общение.
AFUJ и www.joomla.fr (Сирилл Пуссен) — рассказ о французской ассоциации Joomla, обсуждение стратегий развития ассоциации и французского Joomla-сообщества.
40 самородков для Joomla! (марк Дешевр). Подборка из 40 расширений Joomla (большая часть бесплатная), которая сделают вашу жизнь проще.
Обзор сайта города Сен-Леже-ан-Ивелин на Joomla 4 (Оливье Гильяр).
Сравнение решений для создания шаблонов: emplate Creator CK, Helix Ultimate, T4 от Joomlart, Cassiopeia и т.д. (Серж Биллон).
Разработка расширений на заказ: выгодное вложение для вашего агентства (Эрик Лэми). Обзор стратегии, преимуществ создания собственных расширений. Ответ на вопрос почему, несмотря на более высокие первоначальные инвестиции, чем универсальное решение, индивидуальное приложение может оказаться экономически выгодным в долгосрочной перспективе.
HikaShop (Паскаль Конро). Обзор возможностей французского компонента интернет-магазина Хикашоп.
Миграция с Joomla! 3 для Joomla! 4 (Михай Марти). Рассказ об опыте перехода с Joomla 3 на Joomla 4: какие инструменты помогут, на что нужно обратить внимание.
Joomla 4.3 и ее развитие (Оливье Бюссар по видео из Нью-Йорка).
PlanetHoster — Обзор хранилища N0C (Марк Дешевр и Серж Биллон).
Начало работы с Joomla! 4. Бесплатная презентация для старшеклассников (Сирилл Пуссен). Двухчасовая интерактивная презентация, дающая базовые представления о Joomla и открывающая двери в мир web-разработки.
Круглый стол. Вопросы и ответы.
Организатор конференции — Французская ассоциация Joomla. Спонсорами проведения выступают хостинговые компании, агентства по Joomla-разработке, среди которых Tassos, JoomlaCK, JoomShaper и другие.
Конференция проходит очно.
Joomla User Group (JUG)
В экосистеме Joomla существуют так называемые Joomla User Group. Это объединения пользователей и разработчиков Joomla самого разного уровня — от любителей до профессионалов. Группы проводят периодические встречи в оффлайне, онлайне или гибридные. На этих собраниях групп могут проводится мастер-классы, вебинары, обсуждения, поиск заказов и/или исполнителей. Группы обычно формируются по географическому и/или языковому критерию. В крупных городах может быть несколько групп. Наиболее активные участники JUG принимают непосредственное участие в организации Joomla Day и выступлениях. Обычно встречи в рамках JUG проводятся не менее 2-х раз в год. Для примера, JUG в Австралии проводят вебинары раз в 1-2 месяца. Более подробную информацию можно получить в FAQ по Joomla User Group. Также Вы можете организовать свою JUG в вашем регионе.
Ваш дизайн может стать новым дизайном для официального сайта Joomla!
Ваш дизайн может стать новым дизайном для официального сайта Joomla! Разве не было бы здорово, если бы у Joomla был внешний вид в едином узнаваемом стиле для всех тех сайтов, которые находятся под баннером Joomla, а также для тех, что были встроены в шаблон Joomla, которым пользуются люди? Что ж, теперь у вас есть шанс показать своё видение того, как стилистически собрать все ресурсы Joomla вместе!
Joomla был объявлен конкурс на разработку графики и дизайна для проекта Joomla — главной страницы официального сайта, лендинга и страницы загрузки. Подробнее в статье. На момент написания дайджеста результаты конкурса пока ещё не объявлены.





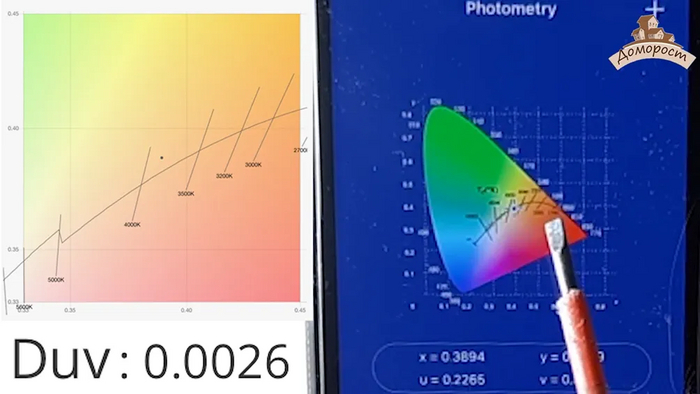
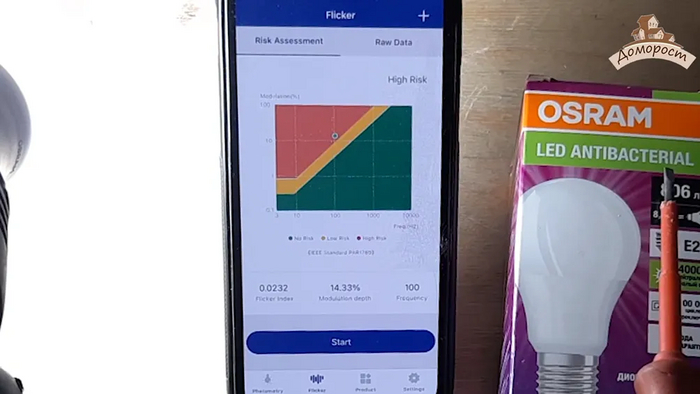



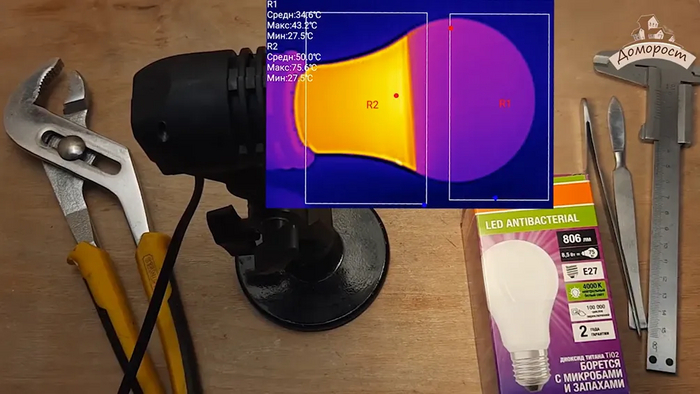








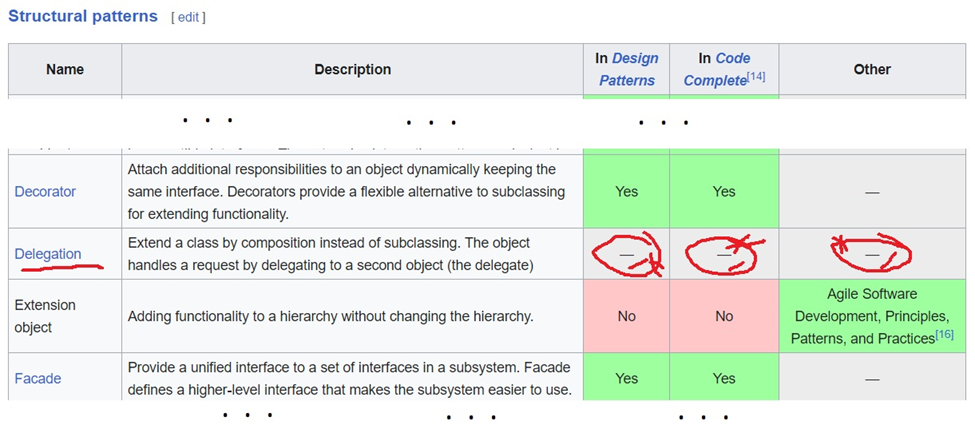





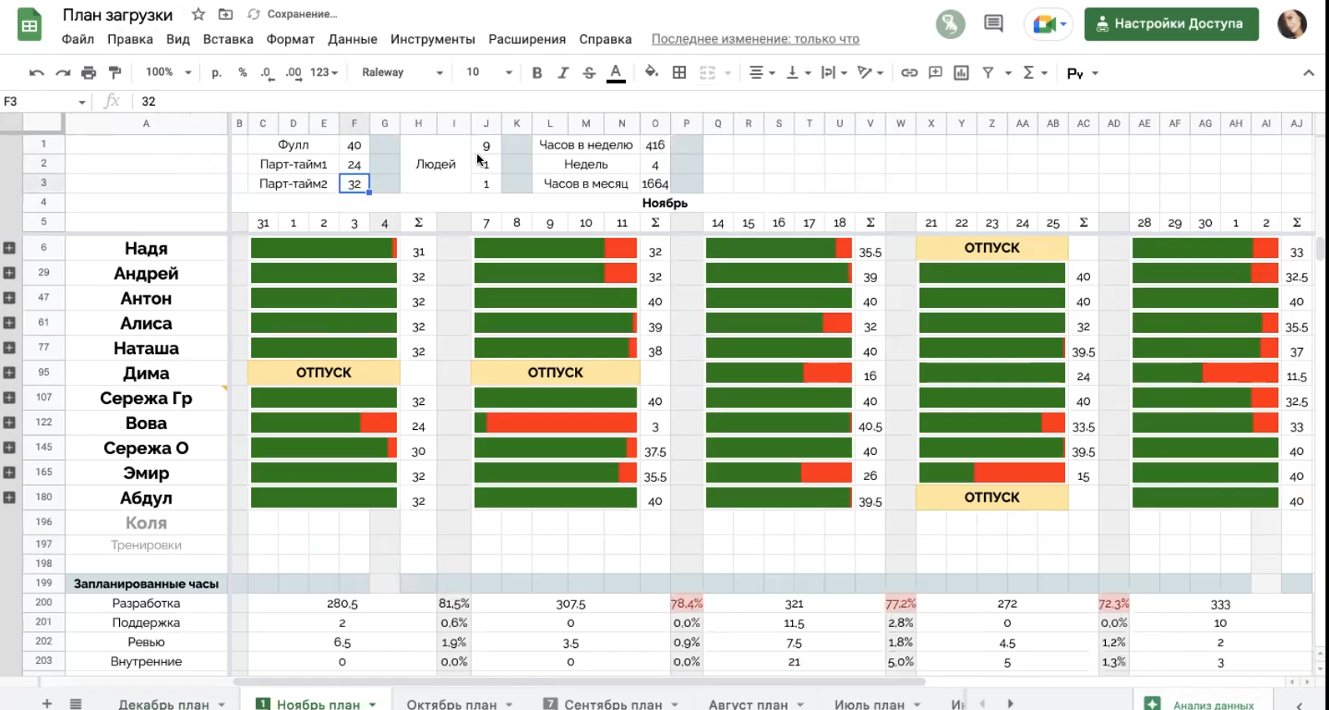
 запрашиваем у хоста сравнение конфигураций.
запрашиваем у хоста сравнение конфигураций. . Если проверка не проходит, хосту назначается статус «обрати внимание». Здесь же запускается дополнительная вторая проверка, которая срабатывает
. Если проверка не проходит, хосту назначается статус «обрати внимание». Здесь же запускается дополнительная вторая проверка, которая срабатывает  , где
, где период основной проверки, по умолчанию 5 секунд,
период основной проверки, по умолчанию 5 секунд,  — количество доп. проверок, умноженное на время задержки между попытками, по умолчанию 5 секунд и 5 проверок,
— количество доп. проверок, умноженное на время задержки между попытками, по умолчанию 5 секунд и 5 проверок, время на перенос каналов. Зависит от производительности хоста и сети, в среднем 10 сервисов в секунду, здесь считаем 10 сервисов.
время на перенос каналов. Зависит от производительности хоста и сети, в среднем 10 сервисов в секунду, здесь считаем 10 сервисов. — среднее время запуска сервиса, зависит от того, когда придёт ключевой кадр.
— среднее время запуска сервиса, зависит от того, когда придёт ключевой кадр.

 позволяют сократить время до максимум 19 секунд.
позволяют сократить время до максимум 19 секунд.